Scratch 3.0 でパーサとインタプリタを作ってみよう
Scratch で自作言語を実装したいと思ったことはありませんか?
私はあります。小学生の頃からずっと Scratch で自作言語を夢見てきました。ですが当時の私にとってそれらのアルゴリズムはあまりに難しく実装に四苦八苦しているうちにScratchで開発することを諦めてしまいました。
あれこれしているうちに気づいたら大学生になっていたので、改めて Scratch でそれらのアルゴリズムを実装しリベンジしようと思い、この記事を書くことにしました。
当時の私と同じように夢を見ている Scratcher にこの記事が届けば幸いです。
はじめに
Scratch はブロックを組み合わせてコードを書く、ビジュアルプログラミング言語です。視覚的にコードを書けることから小学生から大人まで楽しくプログラミングをすることができます。
また2Dゲームや3Dゲーム、ニューラルネットワーク[1]、BrainFu*k[2]などを実装できることが知られています(?)
この記事では Scratch を用いて簡単なパーサとインタプリタを作り、簡単な式を評価できるようにしていきます。
完成イメージ
式を入力すると...

計算結果が表示されます。

Scratch の基本
Scratch を触ったことがいない方も居ると思うのでハンズオン形式で紹介します。
まずScratchのエディターを開きます。
エディターの大雑把な構成は以下のとおりです。
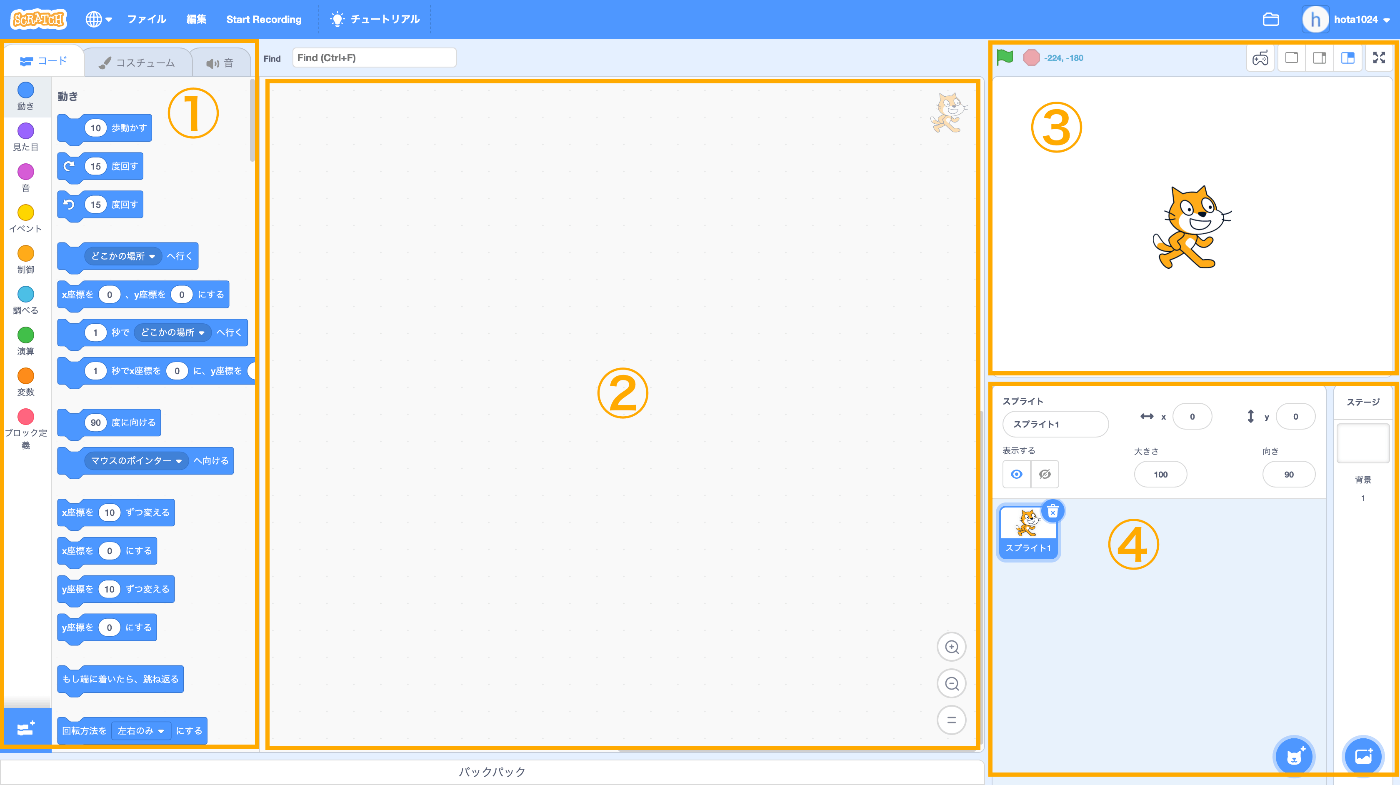
- ブロックパレット
- コードエリア
- ステージ
- スプライト
基本的に「①ブロックパレット」から「②コードエリアにブロック」をドラッグアンドドロップすることで「③ステージのオブジェクト(スプライト)」をプログラミングすることができます。
「④スプライト」ではスプライト一覧や詳細の確認・追加・削除などの操作ができます。
デフォルトでは猫の見た目をした「スプライト1」が用意されています。かわいいね。
試しにブロックパレットの一番上にある「(10)歩動かす」をコードエリアにドラッグアンドドロップで置いてみましょう。
置いたブロックをクリックすると、そのブロックを実行することができます。
今置いたブロックをクリックすると猫が右に少し進むと思います。

(見やすく残像をつけています。)
実行するたびにブロックをクリックするのも変なので、ステージの左上にある旗がクリックされたら実行されるようにしてみましょう。
ブロックパレットの「イベント」のタブをクリックし「旗が押されたとき」を先程のブロックの上にくっつけましょう。

この状態でステージの旗を押すと先ほどと同じように実行されると思います。

今回はスプライトを動かしたりはしないので、せっかく追加したブロックですが「(10)歩動かす」は削除してしまいましょう。ブロックをコードパレットにドラッグアンドドロップすることで削除することができます。

Scratch の変数/リストについて
Scratch には変数とリスト(配列)があります。
コードパレットの「変数」のタブで、変数とリストの作成・削除が出来ます。

Scratch の型
Scratch の値には以下のような型が存在します。
- 文字列
-
hello, world,にゃーん
-
- 数値
-
123,3.14,1e10
-
- 真偽値
-
trueorfalse
-
「〇〇型のリスト」や構造体などが無いので注意が必要です。
変数
デフォルトでは「変数」という名前の変数が用意されています。分かりやすいね。
「角が丸いブロック」は「値」を意味していて演算ブロックなどで使うことが出来ます。またクリックするとその値を見ることが出来ます。

チェックボックスが左に付いているブロックは、チェックを入れることでステージに値を表示することが出来ます。


変数に対する主な操作は2種類用意されています。
上から順に
- 「値の取得(
a角丸のブロック)」 - 「代入(
a = b)」 - 「加算して代入(
a += b)」
です。

リスト
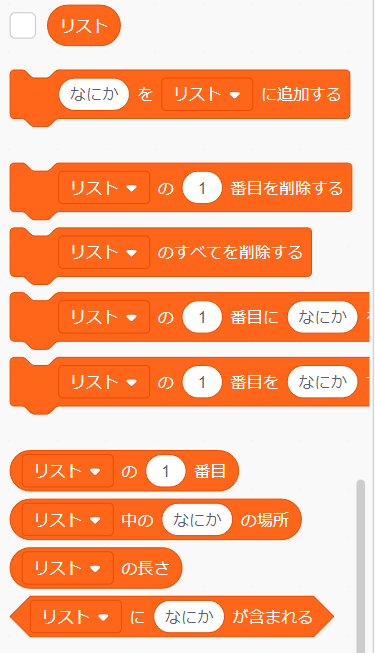
「リスト」は何故かデフォルトでは用意されてないので、スクショで解説します。
- 「要素を
,で区切った文字列の取得」 - 「要素の追加」
- 「
i番目の要素の削除(iは1始まり)」 - 「すべての要素の削除(初期化)」
- 「
i番目に要素を挿入」 - 「
i番目の要素を変更(a[i] = b)」 - 「
i番目の要素を取得(a[i])」 - 「要素の検索(
a.findIndex(b))」 - 「リストの長さ(
a.length)」 - 「要素が含まれるか(
a.includes(b))」
変数と同じようにチェックボックスを入れると、そのリストをステージに表示させることが出来ます。

式を評価する
例えば (12 + 34) * 5 という式をプログラムから見ると "(12 + 34) * 5" という文字列になります。
しかし式を文字列のまま評価しようとすると複雑な処理になってしまいます。
そこで文字列よりも式もっと扱いやすい形式に変換する必要があります。
今回は文字列から 「トークン列」 に変換し、さらにトークン列から 「抽象構文木(AST)」 へと変換した上で評価を行います。

またこれらの形式へ変換し評価するのに必要なプログラムは以下の通りです。
- 字句解析器(文字列からトークン列を生成する)
- 構文解析器(トークン列から抽象構文木(AST)を生成する)
- 評価器(抽象構文木を走査し評価(実行)を行う)
字句解析
最初は「文字列」から「トークン列」を生成する「字句解析」を行います。またこの処理を行うプログラムのことを**「字句解析器(Lexer)」**と言います。
トークン
「トークン」とは数値や記号を分類しやすくしたデータ構造です。
今回はトークンに「種類」と「値」を持たせることにします。
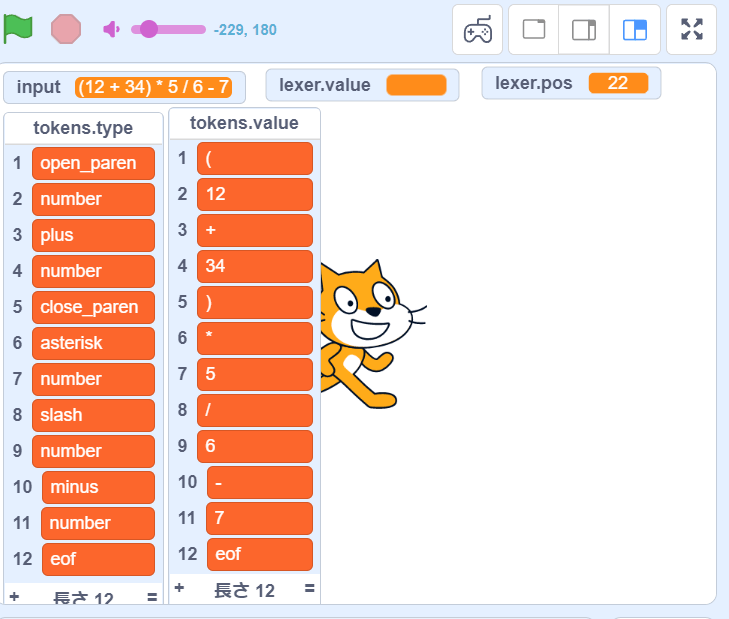
(12 + 34) * 5 を字句解析すると以下の図のようになります。上が変換前の文字列で下が変換後のトークン列を表します。
各トークンの上部が「種類」で下部が「値」になります。
数値は「種類」が number で示され「値」にはその数値が入ります。
+(plus) や *(asterisk) などの記号についても同じで、「値」はその記号の文字を示します。

対応するトークン
今回は以下のトークンに対応します。
| 種類 | 値 | 説明 |
|---|---|---|
number |
数値 |
1 や 23 のような符号無し整数 |
plus |
+ |
プラス記号(足し算に対応) |
minus |
- |
マイナス記号(引き算に対応) |
asterisk |
* |
アスタリスク記号(掛け算に対応) |
slash |
/ |
スラッシュ記号(割り算に対応) |
open_paren |
( |
括弧記号 |
close_paren |
( |
括弧閉じ記号 |
eof |
eof |
トークン列の終了を表す |
まずは式の文字列を表す変数を作成しましょう。
「変数」タブの「変数を作る」をクリックしましょう。

「新しい変数名」に「input」と入力して「OK」をクリックしましょう。

すると「input」変数が作成されます。

試しに「input」に 123 という簡単な式を入れてみましょう。
ブロックをクリックするか旗をクリックして実行しましょう。
ちゃんと式が代入されていることがわかります。

次にトークン列のデータ構造を作成していきます。
Scratch の型 で説明した通り Scratch には構造体が無いどころか2次元配列も作ることが出来ません。そこでリストを複数個組み合わせることで擬似的に構造体の配列を表現します。
リストも変数と同じように作ることが出来ます。
同じ「変数」タブにある「リストを作る」をクリックしましょう。

以下の2個のリストを作成してください。
-
tokens.type- 種類を表すリスト
-
tokens.value- 値を表すリスト

このように種類は tokens.type に 値は tokens.value に追加することでトークン列を表現します。

これは再現しなくても大丈夫です。
字句解析を始める前にトークン列が空になっている必要があります。
先程のプログラムの下に「[リスト]のすべてを削除する」ブロックを2種類分、追加してください。

字句解析器
字句解析器のプログラムを作成していきましょう。
字句解析器には以下の変数が必要なので作成しておきましょう。
-
lexer.pos- 現在見ている文字列上の位置
-
lexer.value- トークンの値を構成するための変数
まず字句解析器の最初の状態は以下のようになります。Scratch の添字は基本的に 1 始まりですので、文字列上での位置を表す lexer.pos が 1 になっているのに注意してください。
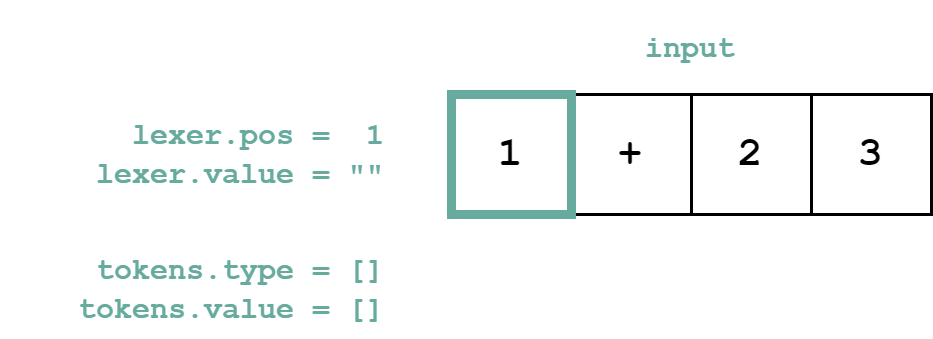
字句解析器の基本的な処理は lexer.pos 番目の文字を見てそれを lexer.value に保存し、その文字に応じてトークンを生成することです。
例えば先程の図の続きでいうと lexer.pos は 1 を示しているので input の 1 番目の文字を見ます。lexer.value には "1" が入ります。

次に文字の種類を見ます。"1" は数字なので数字トークンを追加する準備に入ります。

この場合は "1" の次に数字は来てないので1桁の数字トークンとして追加すれば良さそうです。

次は lexer.pos が 2 なので2番目の文字を見ます。2番目の文字は + なので、そのまま plus トークンを生成してトークン列に追加します。

次も同じように現在の文字を見ます。また数字が現れました。今度は "2" です。

"2" の次にも更に "3" という数字が来ているので複数桁の数字をトークンとして追加する必要が出てきました。lexer.value の末尾に "3" を追加します。これで lexer.value が "23" になりました。lexer.pos を進めて次の処理に移ります。

先ほどと同じように次の文字を見ます。また数字が来ていたら lexer.value に付け足していきますが、今回は文字列の末尾に到達してしまっているため number トークンを追加します。

最後に lexer.pos が文字列の長さよりも大きくなってしまったので処理は終わりです。最後にトークン列の終了を表す eof トークンを追加しておきます。

では実装していきましょう。
まず lexer.pos と lexer.value を初期化する必要があります。
lexer.pos は 0 で初期化します。
「[変数]を()にする」ブロックを2つ先程のブロックの下にくっつけてそれぞれ初期化を行います。
lexer.value は最初は空にしたいので 0 をクリックし選択した後 Back Space で消して空の値にしましょう(この場合の値はおそらく0文字の文字列型)。

次に字句解析を行うためのループを作成します。「制御」タブから「ずっと」ブロックを追加してください。
このブロックは文字通り中のブロックをずっと繰り返してくれます。

lexer.pos の初期値は 0 ですが Scratch は 1 始まりなので最初に 1 を加算してあげましょう。
これでループ毎に lexer.pos が 1 進むようになりました。
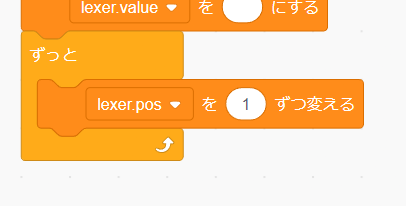
次に lexer.value に input の lexer.pos 番目が示す文字を代入してあげましょう。
「演算」の「()の()番目の文字」ブロックを使うことで、実装できます。

数字の字句解析を行う前に lexer.value が空の場合、つまりこれ以上 input に処理すべき文字が無い場合に字句解析を終了するプログラムを作ります。
条件分岐には「制御」タブの「もし<>なら」というブロックを使います。
文字通り「<>」に入る条件式の結果が「真(0以外の数字もしくは文字列の "true")」なら中のブロックを実行します。また「<>」にはその形のブロックしかはめることが出来ません。この形は条件式を表していて「演算」や「調べる」にそれらに対応したブロックがあります。

lexer.value が空かどうか確かめるために「演算」の「<() = ()>」を使用します。見た目通り左辺と右辺が等しければ "true" そうでなければ "false" を返すブロックです。
この場合では左辺に lexer.value 右辺を空に指定します。空に指定するには lexer.value の初期化の時と同じように値をクリックし Back Space を押せば大丈夫です。
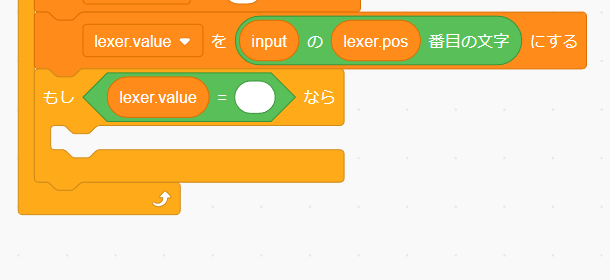
字句解析を終了するときにトークン列に eof を追加するプログラムを作ります。
トークン列に追加するときは必ず tokens.type と tokens.value 両方にそれぞれのデータを追加する必要があります。この場合は両方とも eof を追加すれば大丈夫です(対応するトークン)。

このまま実行してしまうとループを抜ける処理が無いため「無限ループ」になってしまいます。eof を追加した後に処理を終了するプログラムを追加しましょう。
「制御」の「[すべてを止める]」ブロックを追加します。文字通り現在実行しているすべてのプログラムを止めるブロックです。
ただすべてのプログラムを止めてしまうと、止まってほしくないプログラムまで止めてしまうので ▼ をクリックして「[このスクリプトを止める]」に変更しましょう。
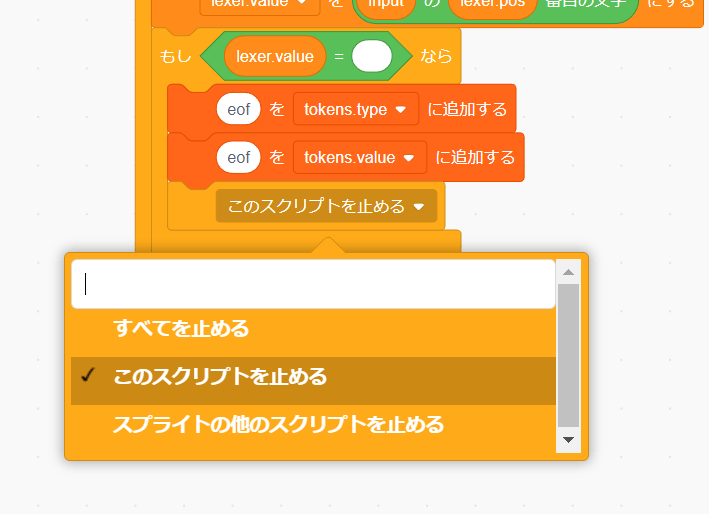
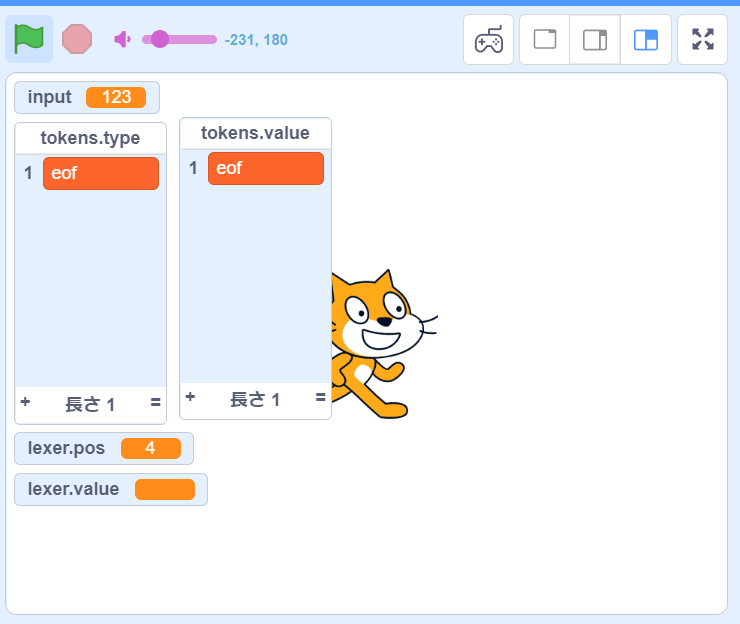
この状態で実行するとちゃんと eof トークンが追加されていることが分かります。
では数字を字句解析するプログラムを作っていきましょう。まずは lexer.value が数字かどうかを確かめる必要があります。
lexer.value が 0123456789 のいずれかの文字であれば数字と判断できそうです。
「演算」の「()に()が含まれる」ブロックを使います。このブロックは最初の文字列に次の文字列が含まれていれば "true" そうでなければ "false" を返します。
今回は最初の文字列に 0123456789 次の文字列に lexer.value を指定します。
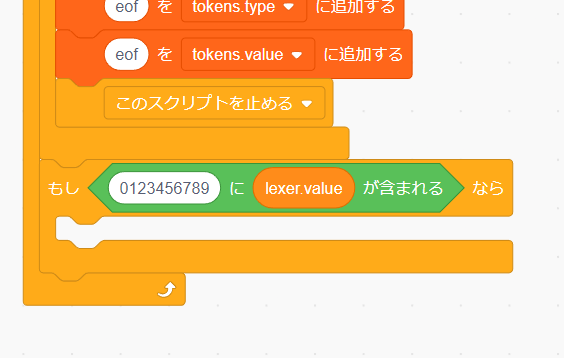
数字を発見したら、次の文字を見て数字なら lexer.value の後ろに追加していく...という処理を繰り返します。
今回は条件を伴う繰り返しなので「制御」の「<>まで繰り返す」ブロックを使います。このブロックは条件式が偽の間だけ中のプログラムを実行し続けます(while ではなく until なことに注意)。

「次の文字が数字である間繰り返す」ことになるので「<次の文字が数字ではない>まで繰り返す」条件式を作ります。
「演算」の「<>ではない」を使うと値とは逆の真偽値を取得することが出来ます。これを組み合わせて以下のような条件式を作ってください。

「次の文字が数字」かどうかを調べるために「演算」の「() + ()」を使います。見た目通り左辺と右辺の和を返すブロックです。ここまでに出てきたブロックを組み合わせて以下の条件式を作ってください。
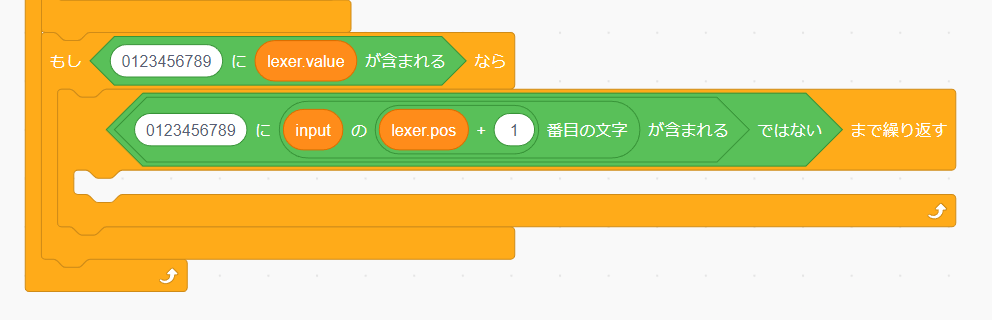
この繰り返しの中では lexer.pos を 1 進めて lexer.value に次の数字を付け足す処理を行う必要があります。
「付け足す」と言うのは数値の加算ではなく「文字列の連結」という意味です。
「演算」の「()と()」を使うことで文字列の連結を行うことが出来ます。
左側には lexer.value 右側には「(input) の (lexer.pos) 番目」を入れます。そしてその結果を lexer.value に代入することで数字を付け足すことが出来ます。

繰り返しから抜けたら number トークンを追加する処理を行います。
eof トークンと同じ要領でリストに要素を追加します。今度は tokens.type には number を tokens.value には tokens.value を指定します。

これで数字の字句解析は完成!と言いたいところですが、このまま実行すると無限ループに入ってしまうバグがあります。
次のスクショの通り、実は「<()に()が含まれる>」には厄介な仕様があります。スクショの右側の値は空に指定しています。これは "0123456789" という文字列に空の文字列 "" が含まれている(trueである)ことを示しています。この空の文字列は lexer.pos + 1 が input の最後に到達した瞬間から現れます(Scratch の値やリストは範囲外にアクセスしようとすると空文字を返す仕様があるため)。

このバグを修正するために条件式を少し変えます。
具体的には次のような条件式にします。
「<<次の文字が数字ではない>または<次の文字が空文字>>」
「演算」の「<<>または<>>」をブロックを使って以下のように条件式を変更しましょう。
一度「<>まで繰り返す」の条件式を何もない場所に退避させてからブロックを組み立てるとやりやすいです。

ガッチャンコするのを忘れずに。

実行すると正常に number トークンが追加されていることが分かります。

ここまでのプログラムの全体像はこんな感じです。

次に記号の字句解析を行います。記号は数字とは違い1文字だけなので簡単に実装することが出来ます。
例えば + 記号なら以下のとおりです。

試しに input を 12+3 のようにして実行してみましょう。

ちゃんと plus トークンが追加されています。

ここまでで3種類のトークンに字句解析するプログラムを作りました。残りは -*/() の5種類を実装すれば完成です。
このまま実装を続けても良いのですが、ここで少しリファクタリングをしてみましょう。
まずトークンを追加するたびに tokens.type と tokens.value に要素を追加する処理をしています。しかもそれが3箇所もあるので、これは関数化した方が良さそうです。
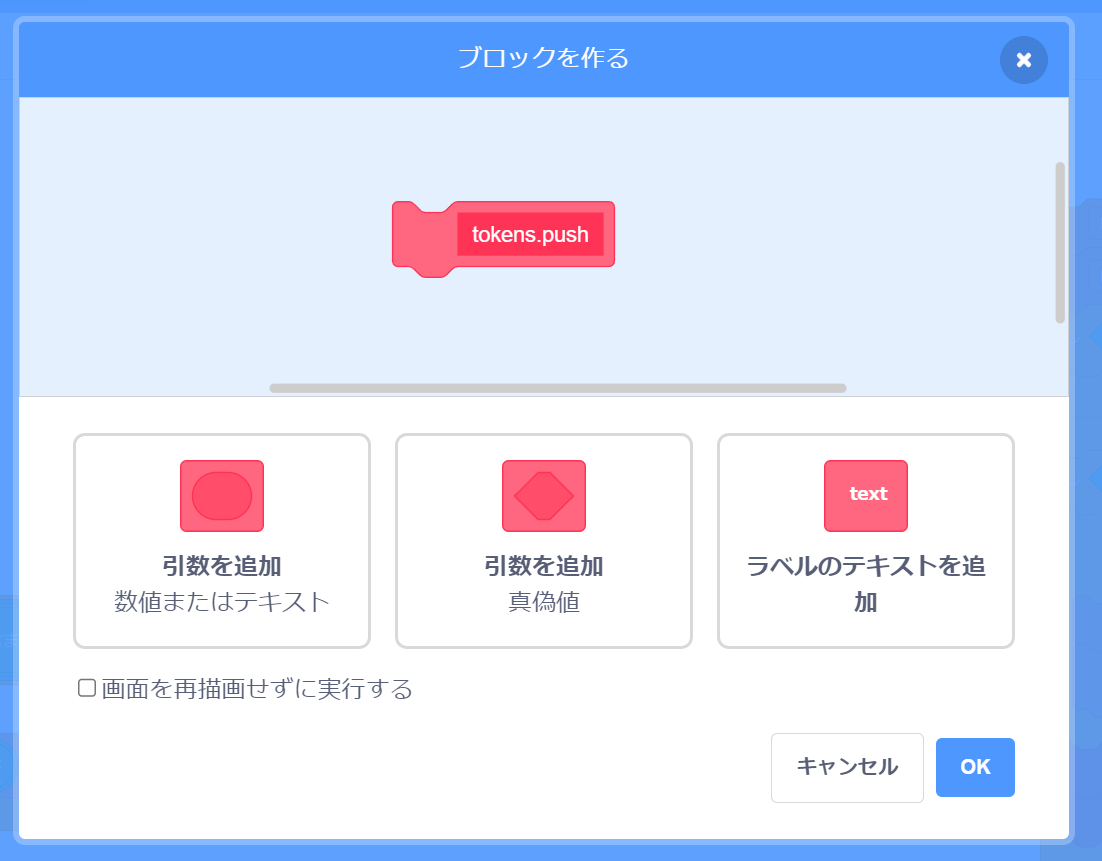
「ブロック定義」タブの「ブロックを作る」をクリックしてください。

すると関数を作るためのダイアログが表示されます。
ブロック名を tokens.push にしましょう。
次に「引数を追加」をクリックして引数を追加します。引数の名前は type にしましょう。
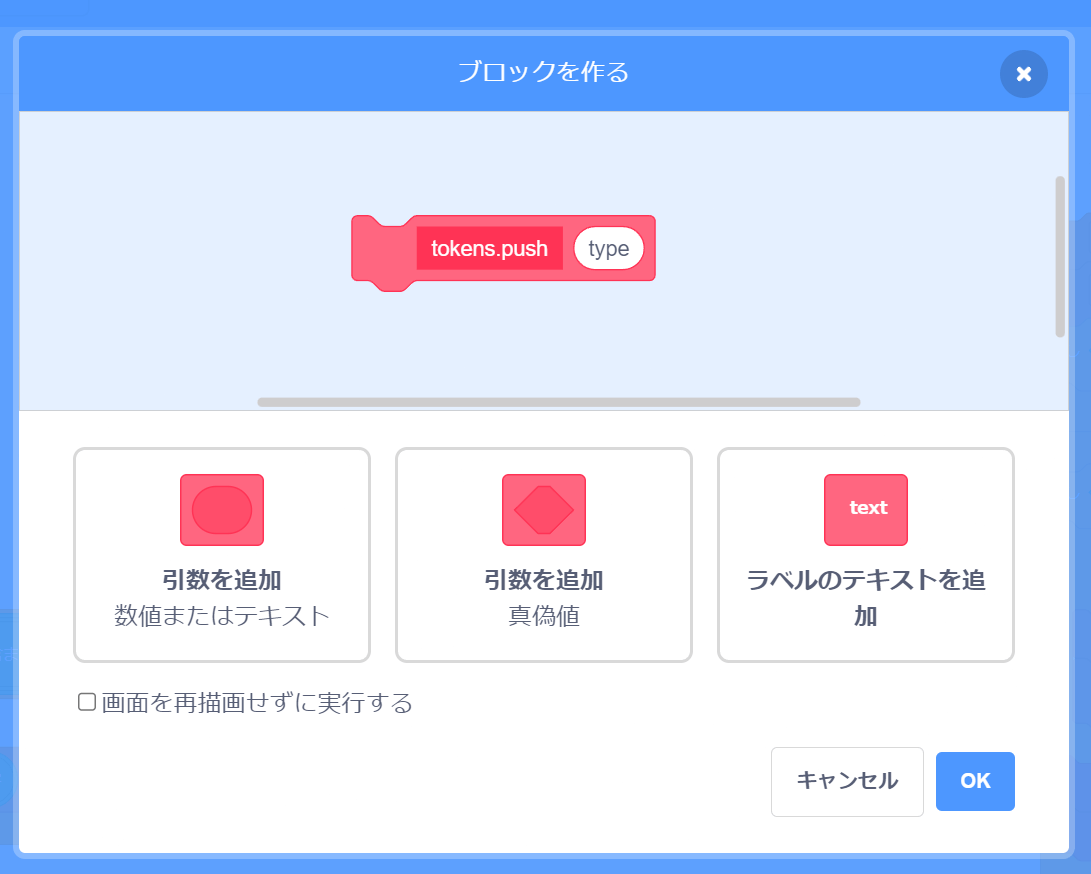
最後にもう1つ引数を追加して名前を value にします。

「OK」をクリックすると関数が作成されます。
「ブロックパレット」には関数を呼び出すブロックが追加され「コードエリア」には関数の本体が作成されます。

この関数は与えられた type と value をそれぞれ tokens.type と tokens.value に追加する処理を行います。
このように「定義」の引数をドラッグアンドドロップすることで値として利用することが出来ます。

関数は「ブロック定義」からそのブロックを追加し、引数を指定することで他のブロックと同じように使用することが出来ます。

早速作ったブロックを使ってプログラムを置き換えましょう。
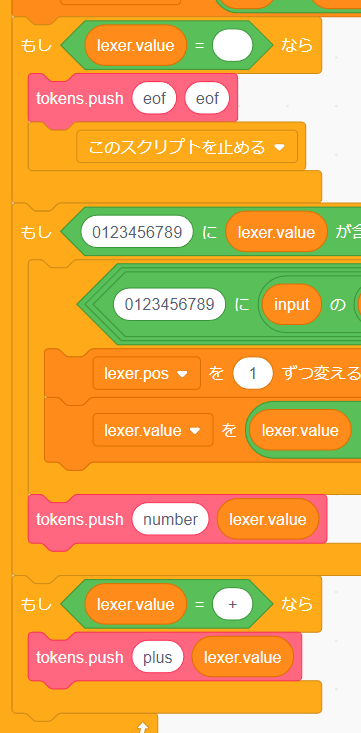
では他の記号もサクッと実装してしまいましょう。

input を変えてちゃんとプログラムが動作するか確かめましょう。
ステージ上の変数やリストはドラッグアンドドロップすることで移動させることが出来ます。またリストは「長さ」の右にあるリサイズアイコンをドラッグすることで大きさを変えれます。
最後にここまで実装した字句解析器のプログラムを関数化しておきましょう。
「ブロック定義」から「ブロックを作る」をクリックし tokenize という名前を入力して「OK」をクリックしましょう。

字句解析器のプログラムは「input を () にする」ブロックより下のブロックなので、下のブロックをドラッグして tokenize に移動させましょう。

ドラッグして移動↓

このままだと tokenize は実行されないので、呼び出す処理も追加しておきましょう。

お疲れ様です。これで字句解析器の実装は終わりです🎉
構文解析
ここまでで「式の文字列」から「トークン列」を生成できるようになりました。
次は「トークン列」から「抽象構文木」を生成する 「構文解析器」 の実装を行います。
抽象構文木
抽象構文木とは構文を木構造のデータで表現したものです。英語では Abstract Syntax Tree で表記され、頭文字をとって 「AST」 と表現されることが多いです。
例えば 1 + 2 を AST で表すと以下の図のようになります。
bin(add) と書かれた矩形は足し算を表しています。bin とは binary expression の略で 二項演算 を意味しています。また二項演算には 演算子(計算の種類) があります。bin(add) からは2個の矩形に線が伸びていて、それぞれ number(1) と number(2) が書かれています。

またこれらの矩形で示されるものは 「ノード」 や 「ASTノード」 と呼ばれます。
ノードは add のように別のノードを「子」として持つものや number(x) のように「子」を持たない 「末端ノード」 があります。

次にこの図を見てみましょう。
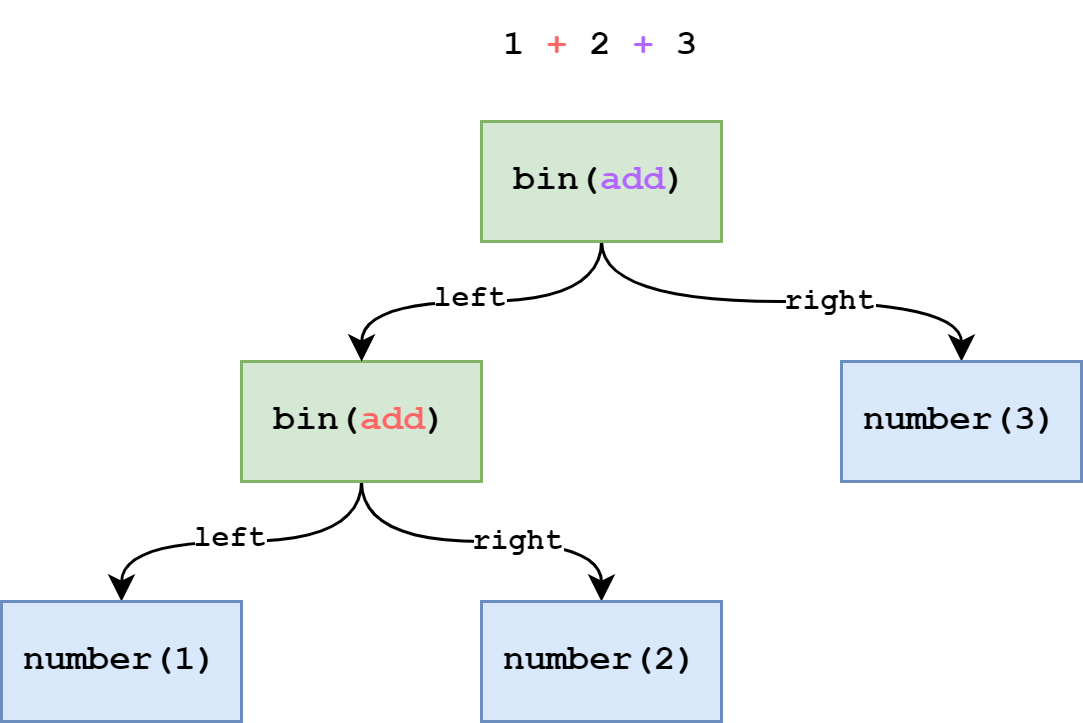
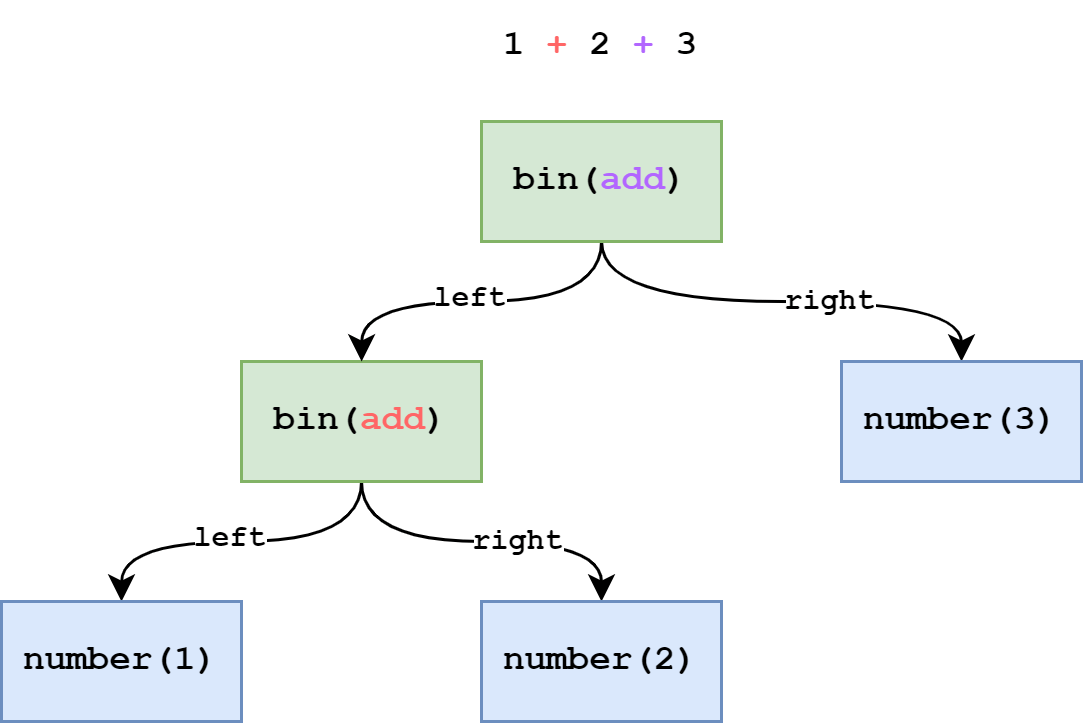
今度は 1 + 2 + 3 を AST で示した図です。
注目すべきは一番上の add ノードが 2 + 3 の + に対応していることです。
これは 一番左下から式が開始されている ことを表します。言い換えると式を評価する順番が左下から右下ということです。
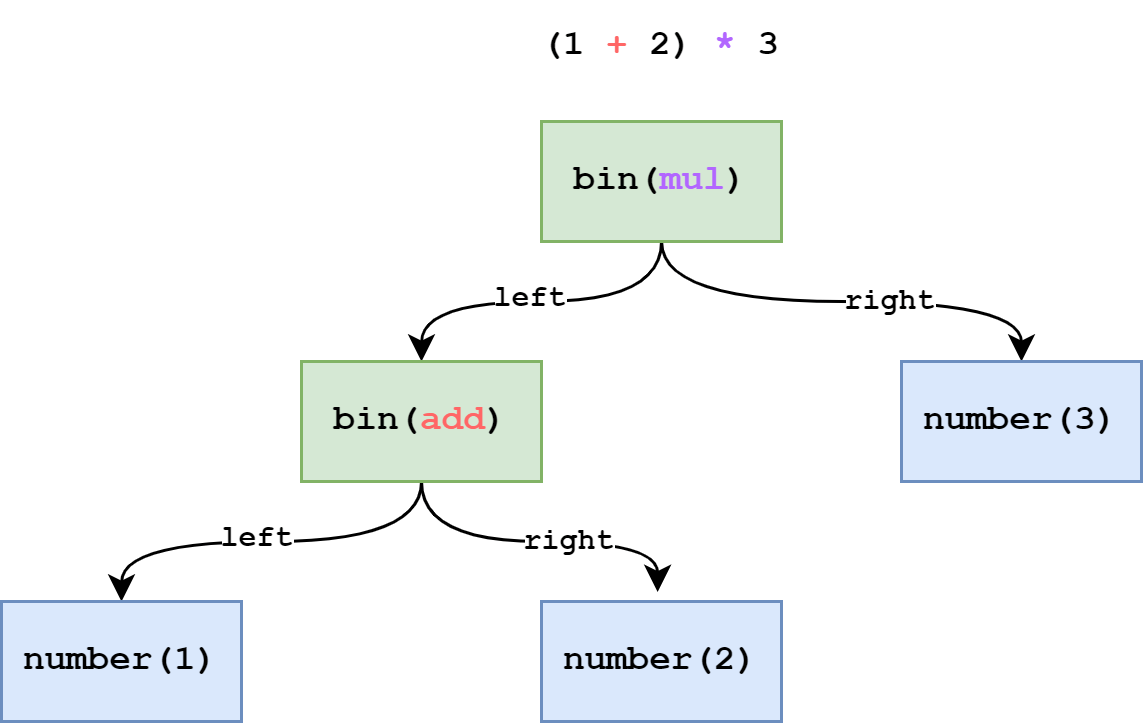
では 1 + 2 * 3 はどうでしょう?小学校で習った通り「足し算」と「掛け算」では「掛け算」の方が優先度が高いため AST は以下の図のようになります。bin(mul) は掛け算を表しています。この図では 1 を評価した後、2 * 3 を評価して最後に足し算を行うようになっています。

先程「足し算」と「掛け算」では「掛け算」の方が優先度が高いと説明しました。この優先度は () で式を囲むことで変えることが出来ます。
例えば (1 + 2) * 3 という式を AST で示すと以下の図のようになります。これで掛け算より先に足し算を行うことが出来ます。
ではノードを表すデータを作っていきましょう。
ノードはトークンと同じように自身がどの種類のノードであるのかを表す type を持ちます。
今回は以下のノードを実装します。
種類(type) |
説明 |
|---|---|
bin |
二項演算を表します。 |
number |
数値を表します。 |
しかしノードは type によって持つデータが違うためデータ構造を少し工夫しなければ行けません。
具体的には以下の通りです。
type = bin
| データ名 | 値 |
|---|---|
op |
演算子(add or sub or mul or div) |
left |
左辺のノード |
right |
右辺のノード |
type = number
| データ名 | 値 |
|---|---|
number |
数値 |
これを Scratch で表現するために次のようなリストを用意します。
| リスト名 | 値 | 説明 |
|---|---|---|
nodes.type |
bin or number
|
ノードの種類を表す。 |
nodes.op |
add or sub or mul or div
|
nodes.type = bin の場合の演算子を表す(左から順に「足し算」「引き算」「掛け算」「割り算」を表す) |
nodes.left |
数値 |
nodes.type = bin の場合の左辺のノードのインデックス |
nodes.right |
数値 |
nodes.type = bin の場合の右辺のノードのインデックス |
nodes.number |
数値 |
nodes.type = number の場合の数値 |
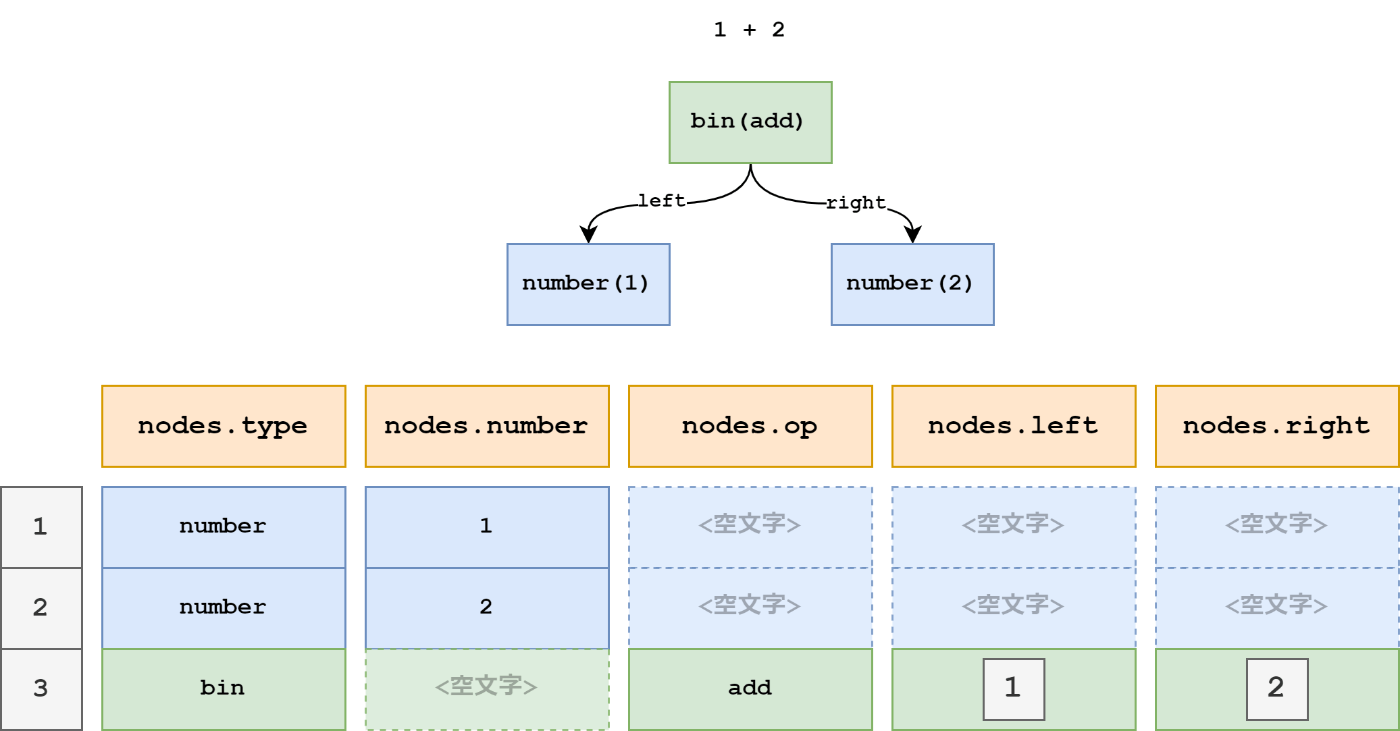
ノードを処理する際は nodes.type によって処理を切り替えることで対応します。またノードを追加する際はこれらすべてのリストに要素を追加する必要があります。使わない要素に関しては 空文字を要素として追加する ことにします。
そして1つポイントがあります。それは nodes.left や nodes.right といった 「他のノードを参照する」値はそのノードへのインデックスを保持 することです。
Scratch のリストは入れ子構造にすることが出来ないため、1次元上に子要素を配置する必要があります。そのため1次元上の子要素の位置(インデックス)を変わりに値として保持します。
図示すると以下のようになります。
では早速リストを作りましょう。以下の5個のリストを作ります。
nodes.typenodes.opnodes.leftnodes.rightnodes.number

次にノードを追加するための関数を作ります。
「ブロック定義」から「ブロックを作る」をクリックしましょう。
ノードは5個のフィールドを持つので5つ引数を追加することになりますが、それではどの引数がどのフィールドに対応しているか少しわかりにくいです。
Scratch の定義ブロック(関数)は引数と引数の間に「テキスト」を追加することが出来ます。
まずはブロックの名前を nodes.push(type= にしましょう。

引数を追加し、名前を type にします。

次に「ラベルのテキストを追加」をクリックし op= を入力します。

引数を追加し名前を op にします。

同じ要領で left right number も追加していきます。
number まで追加できたら最後にもう一度テキストを追加し ) を入力します。出来たら「OK」をクリックしましょう。

これでどの引数がどのフィールドに対応しているか分かりやすくなりました。
関数の本体を作りましょう。
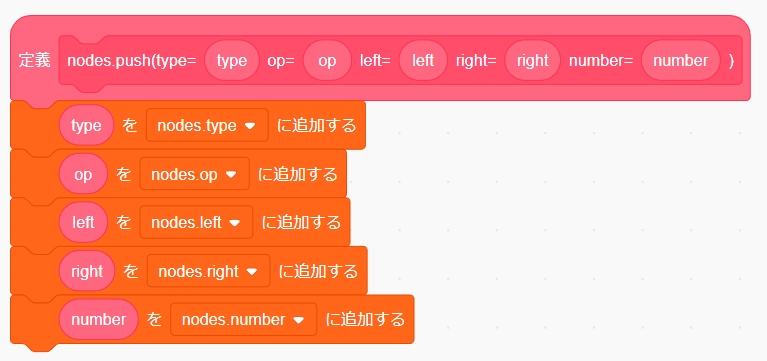
これでノードの準備は完了です。
構文解析器
構文解析器は「トークン列」から「AST」を生成するプログラムです。構文解析器は 「パーサ」 と表現されることが多いです。今回は構文解析の手法として
パーサを作るには、まずASTをどのような順番で生成するかを決める **「ルール」を作らなければ行けません。
下の図は先程も出てきた 1 + 2 * 3 の AST です。これを見れば分かる通りパーサは「足し算」からASTを作成しています。その次に「掛け算」そして一番最後に処理しているのは number ノードです。このように優先度が上がるに連れ処理は後から行われることになります。

次に 1 + 2 + 3 の AST を確認してみましょう。この式は足し算のみで構成されており、足し算同士の優先度は同じです。このような場合パーサは足し算が続く限り、左辺を足し算のASTで入れ替えながら処理を行います。その証拠に一番上のノードは一番最後の足し算を示しており、その左辺はその前の足し算を示しています。

このようにパーサは優先度の低いルールが優先度の高いルールを呼び出しながら AST を構成していきます。またパーサの処理によって AST を構成することを「パースする」と言います。
今回は以下のルールを実装していきます。
| ルール名 | 説明 | 次に呼ぶルール |
|---|---|---|
add_and_sub |
「足し算」と「引き算」をパースします。 | mul_and_div |
mul_an _div |
「掛け算」と「引き算」をパースします。 | atom |
atom |
number もしくは () の中のパースをします。 |
() があれば add_and_sub
|
重要なのは以下のポイントです。
-
add_and_subが一番最初に実行されること - ルールはルール名通りのノードだけではなく、その次に呼ぶルールが生成するノードも扱うこと
-
atomは()を見つけたら、その中身をadd_and_subルールで処理すること- こうすることで
mul_and_divより後にadd_and_subを実行し計算時の優先度を上げることができる。
- こうすることで
LLパーサは以下の変数が必要なので作成しておきましょう。
| 変数名 | 説明 |
|---|---|
parser.pos |
現在見ているトークン列上の位置 |
parser.peek.type |
parser.pos + 1 番目の tokens.type
|
parser.peek.value |
parser.pos + 1 番目の tokens.value
|

この parser.peek.type は現在見ているトークンの更に1つ先のトークンの種類を保持します。
各ルールはこの parser.peek.type を見てノードを生成したり別のルールを呼び出します。
parser.peek.value は atom ルールで parser.peek.type が number トークンだった場合に number ノードを生成するのに利用します。
次に構文解析を開始する関数を作ります。
「ブロックを作る」をクリックし名前を parse にして「OK」をクリックしましょう。

まずノードの各リストの初期化を行います。

次に parser.pos の初期化を行います。
ここで parser.pos を 1 で初期化してしまうと parser.peek.type は示すのは2番目のトークンを示すことになってしまいます。なので parser.pos の初期値は 0 とします。

parser.peek.type と parser.peek.value は parser.pos の値によって変わるので、これらを更新する関数を先に作ってしまいましょう。
「ブロックを作る」で parser.update_peek という名前の関数を作ります。

tokens.type と tokens.value から1つ先のトークンの情報を代入する処理を作りましょう。
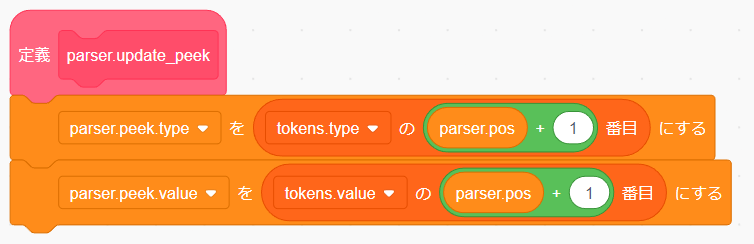
parser.pos の初期化の後に parser.update.peek を呼び出してあげましょう。

各ルールは再帰的に他のルールを呼ぶ場合があるので関数で実装していきます。
「ブロックを作る」で以下の関数を作成してください。
parse.add_and_subparse.mul_and_divparse.atom

パーサで一番最初に実行されるのは add_and_sub なので parse 関数で parse.add_and_sub を呼び出してあげましょう。

次は parse.add_and_sub の実装を...と言いたいところですが、今回は先に parse.atom から作っていきます。そちらのほうが実行しながら動作を確認できるからです。
そのために一時的に parse.add_and_sub で parse.mul_and_div をそのまま呼び出してあげましょう。また parse.mul_and_div はそのまま parse.atom を呼び出してあげます。
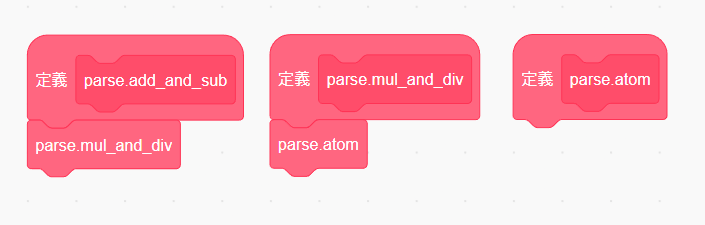
atom ルールは number トークンをパースし number ノードを生成するのと () があれば add_and_sub ルールを呼び出すのでした。先に number ノードのパースを実装しましょう。
まずは parser.peek.type が number かどうかを確かめましょう。

次に number ノードを追加するプログラムを追加します。number ノードの値は parser.peek.value で取得することが出来ます。

これで number をパースできるようになりました。
実際に実行して確かめれるようにしてみましょう。input の値を適当な数字に変更して tokenize の呼び出しの下に parse の呼び出しも追加します。

実行するとちゃんとパースされていることが分かります。

実はルールにはもう1つ重大な義務があります。それはパースを行ったら parser.pos を 1 進めることです。そうしないとパーサは永遠に同じ場所をパースし続けて無限ループになってしまいます。 parser.pos を進めるということは parser.peek.type と parser.peek.value も変わるということです。
これも関数にしてしまいましょう。
「ブロックを作る」で parser.next という関数を作ってください。

parser.next は parser.pos を 1 進めて parser.update_peek を呼び出して変数の更新を行います。

では早速、ノードを追加した後に parser.next を呼び出してあげましょう。

次に () の処理を...と行きたいところですが、このまま条件分岐を下にくっつけてしまうと次のような文法が成立してしまいます。
123(12)
これは式としては許容したくないので number のパースが終わったら atom ルールの処理を終了させるプログラムを書きます。
parse.next の下に「制御」タブの「すべてを止める」を追加し「このスクリプトを止める」に変更します。これで正常な文法のみが処理されるようになりました。

では () の処理を作っていきます。まず parser.peek.type が括弧を表す open_paren であるかを確かめます。
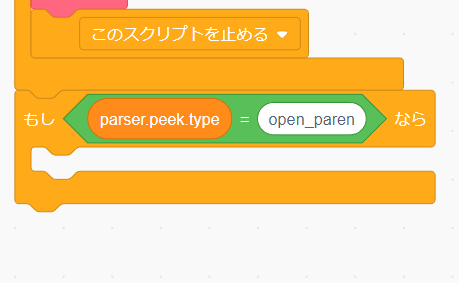
open_paren が見つかったら parser.next で次のトークンに進めて parse.add_and_sub を呼び出します。

add_and_sub の処理が終わったら parser.peek.type は閉じ括弧を表す close_paren であるかを確かめます。

もし close_paren がちゃんとあれば parser.next を呼んで atom ルールの処理を終了します。
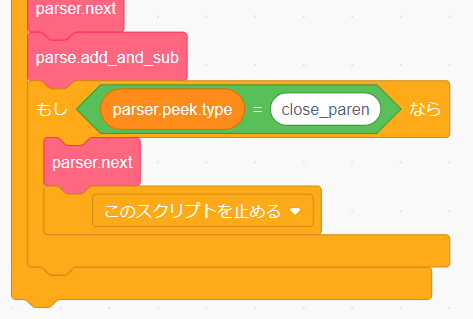
ではもし close_paren が無かったらどうしましょうか...?それはつまり以下の式があった場合にどのような処理を行えばいいか?ということです。
(1 + 2
括弧閉じが無い構文の式を認めるわけにはいきません。これは無効な構文としてエラーを出すべきです。
幸いなことに私達には言葉を表示してくれる猫がいます。エラーが発生したらこの猫にそのエラー内容を教えてもらえるようにしましょう。
まずエラーを発生させる関数を作ります。
名前は error で message という引数を受け取るようにしましょう。

猫に文字を表示してもらうには「見た目」タブの「()と言う」を使います。そのまま 「(message) と言う」というふうにプログラムを組みましょう。

次に「制御」タブの「<>まで待つ」を追加します。このブロックは <> の条件式が "true" になるまでプログラムを停止することが出来ます。今回は <> の中身が空なので常に "false" となり永遠にプログラムを停止させることが出来ます。これでエラーを発生させる関数は完成です。

早速この関数を使ってエラーを発生させましょう。先程の close_paren を確認する条件分岐は close_paren が無かった場合は条件分岐の後ろのプログラムを実行するので、そこで error
を呼び出します。

さて、実はもう1つエラーを発生させるべき場所があります。それは open_paren を確認する条件分岐の後です。atom ルールでは number と () のみを処理するのでそれ以外のトークンがあった場合は予期しないトークンとしてエラーを発生させる必要があります。
以下のように error の呼び出しを追加しましょう。今度は「演算」の「()と()」を使ってどのトークンを受け取ったのかも一緒に表示するようにしています。
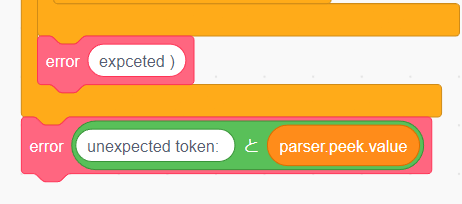
試しに input に + だけを入力して実行してみましょう。ちゃんとエラーが発生しました。

次に (123 だけを input に入力してみます。ちゃんとエラーが発生しました。

(123) も試してみましょう。これは正常な式なのでエラーは発生しません!最高!

ちなみに (((((123))))) のようなネストした () もパースできるようになっています。数字だけなので結果も number ノードのみですが...
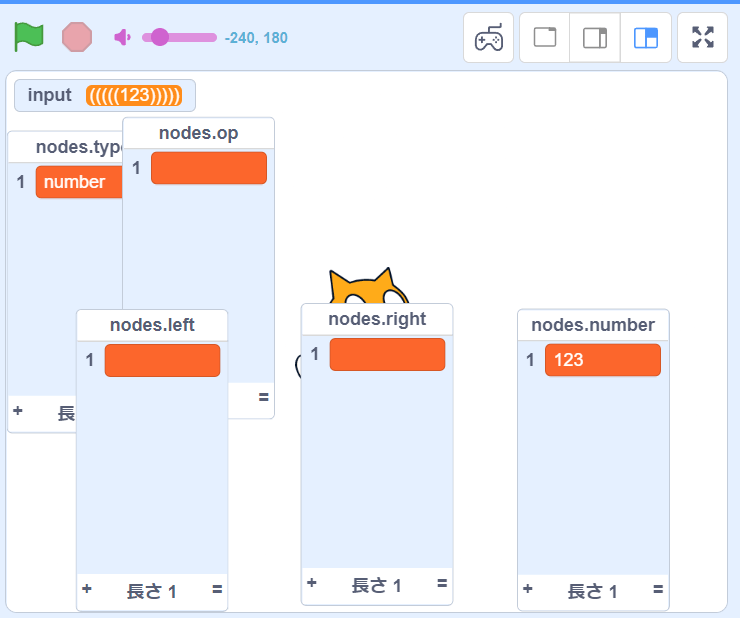
atom ルールの実装は以上で終わりです。
やっと parse.add_and_sub の実装を始めれる...わけではありません...
先程、足し算のパースについて以下のように説明をしました。
次に 1 + 2 + 3 の AST を確認してみましょう。この式は足し算のみで構成されており、足し算同士の優先度は同じです。このような場合パーサは足し算が続く限り、左辺を足し算のASTで入れ替えながら処理を行います。その証拠に一番上のノードは一番最後の足し算を示しており、その左辺はその前の足し算を示しています。
実はここにとても大きな罠が潜んでいます。問題は「足し算が続く限り、左辺を足し算のASTで入れ替えながら処理」という部分です。これは言い換えると常に左辺のノードのインデックスを保持した状態で次のパースを行わなければいけないということです。次のパースというのはもちろん () によってまた自分自身が呼び出される可能性があります。
これだけを聞くとさほど問題には感じませんが、実は問題なのです。
それは「Scratch の関数にはローカル変数が無い」ことです。厳密には引数がありますが、引数の値を自由に操作することはできません。
これはつまり普通の変数で左辺を保持しても () などで自分自身がまた呼び出されてしまった場合に保持している左辺のデータが上書きされてしまうということです。

これを塞ぐには別々の左辺の保存場所を用意してあげることです。

幸い Scratch にはリストがあるので、これをローカル変数のスタックのように使うことが出来ます。

イメージ図
add_and_sub は二項演算のパースを行うため左辺以外にも「演算子」を保持する必要があります。よって以下の2つのリストを作成しましょう。
-
parser.bin.left- 左辺のノードのインデックス
-
parser.bin.op- 足し算なら
add - 引き算なら
sub
- 足し算なら

またこれらのリストの初期化の処理を parse 関数の nodes.number リストの初期化の後に追加します。

次にこれらのリストに対する操作を関数化していきます。
操作は次のとおりです。
parser.bin.pushparser.bin.popparser.bin.loadparser.bin.store
1つずつ作りながら解説していきます。
まずは parser.bin.push 関数を作りましょう。
この関数は parser.bin.left と parser.bin.op に空の要素を追加します。parse.add_and_sub はこの関数をはじめに呼ぶことで左辺と演算子の保存先を確保します。

次に parser.bin.pop を作ります。
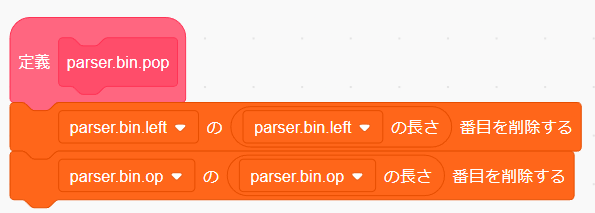
この関数は parser.bin.left と parser.bin.op のそれぞれの末尾の要素を削除します。parse.add_and_sub は処理を終了した際にこの関数を呼び出して左辺と演算子の保存先を開放します。
リストの末尾の要素を削除するには「そのリストの長さ」番目を削除します。
つぎに parser.bin.load 関数を作ります。
この関数は parser.bin.left と parser.bin.op の末尾の要素をそれぞれ変数に読み込む処理を行います。この関数があることで parse.add_and_sub 内でリストの操作をしなくても左辺と演算子にアクセスできるようになります。
処理を実装する前に読み込み先の変数を用意する必要があります。以下の変数を作成してください。
parser.bin.leftparser.bin.op

処理は以下のとおりです。リストの末尾の要素を取得する際は「そのリストの長さ」番目を指定すれば大丈夫です。

最後に parser.bin.store 関数を作ります。
この関数は先程作成した変数の parser.bin.left と parser.bin.op でそれぞれのリストの末尾の要素を置き換える処理を行います。要するにデータの更新です。今までと同じ要領で以下のようにプログラムを追加します。

今度こそは parse.add_and_sub の実装を始めます!
まず先程作った parser.bin.push を最初に呼び出してあげましょう。parse.mul_and_div の前に追加しましょう。

さて、最初の左辺は parse.mul_and_div の呼び出しでノードリストの末尾に追加されているはずです。
今回は二項演算の左辺と右辺はそれぞれのノードのインデックスを保持するのでしたね。
なので parser.bin.left に ([nodes.type]の長さ) を代入して parser.bin.store を呼び出せば最初の左辺の保存はできそうです。
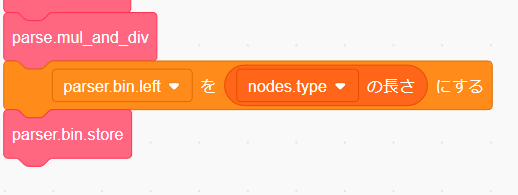
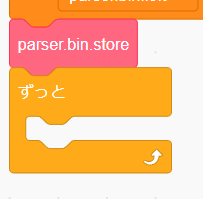
parser.add_and_sub は「足し算」と「引き算」が続く限り処理を繰り返すので、ループを作る必要があります。
「制御」の「ずっと」を追加しましょう。
次に parser.peek.type が足し算を表す plus もしくは引き算を表す minus なのかどうかを確かめます。
「制御」から「もし<>なら {} でなければ {}」をループの中に入れましょう。
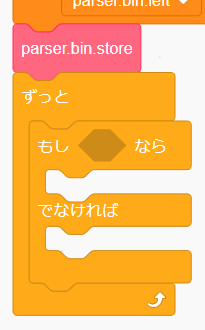
条件式を作ります。

先に「足し算」と「引き算」両方とも見つからなかったときの処理を作ります。それはつまり add_and_sub ルールの終了を表します。なので parser.bin.pop を呼んでデータを開放し、ループを終了させます。

もし「足し算」か「引き算」のどちらかが見つかったらまず条件分岐を使い演算子を保存します。
最初に「足し算」の場合の処理を作ります。

演算子は parser.bin.op に保存します。「足し算」の場合は add を保存します。

同じ要領で「引き算」の場合も sub を保存します。

これだけだと変数に保存されるだけで、実態のリストには反映されないので parser.bin.store を呼んで反映させます。

これで演算子のパースが出来たので parser.next を呼び出し次のパースの準備をします。

add_and_sub は右辺も mul_and_div ルールを呼び出して処理します。parse.mul_and_div を呼び出す処理を追加しましょう。

これで左辺と右辺が揃ったのでいよいよノードの追加を行います。
まず parser.bin.load を呼び出して左辺と演算子を取得します。

nodes.push の type 引数に bin を指定し、op と left には先程取得した parser.bin.op と parser.bin.left を指定して、right には parse.mul_and_div で追加されたノードのインデックス(リストの長さ)を指定します。

最後に追加したノードを左辺として保存します。parser.bin.left に今追加したノードのインデックスを代入し parser.bin.store で反映させます。

早速 input に 1 + 2 + 3 を入力して実行してみましょう。
実行してもリストだと何がなんだか分かりづらいですね。一応 nodes.left と nodes.right はそれぞれ対応するノードへのインデックスを示しているはずです。
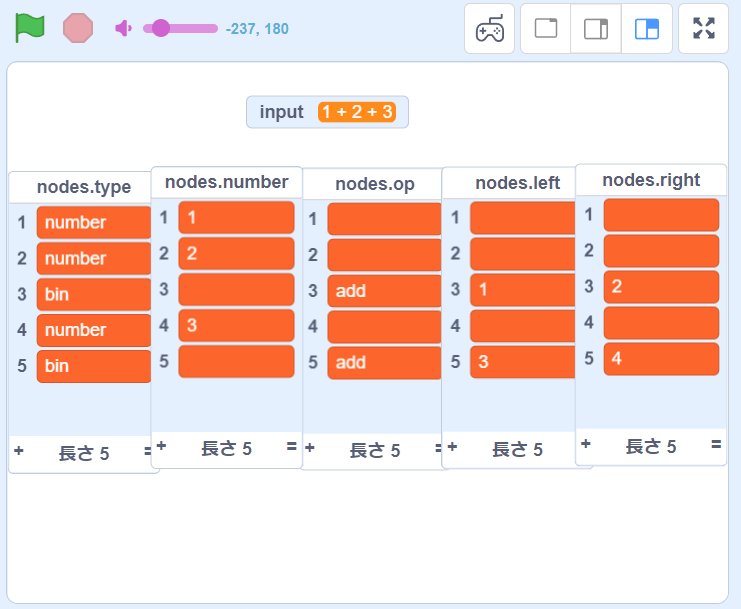
分かりやすく図にするとこんな感じです。灰色の四角がインデックスを示しています。

次は parser.mul_and_div の実装をします。といってもほとんど parse.add_and_sub の処理と変わらないので Scratch の「複製機能」を使って実装していきます。
一度 parse.mul_and_div についている parse.atom を外して近くに退避させましょう。

parse.add_and_sub の一番上にある parser.bin.push を右クリックして「複製」をクリックしましょう。
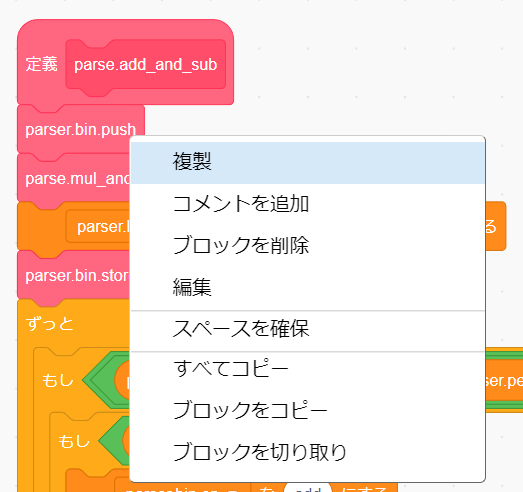
複製したブロックを parse.mul_and_div にくっつけましょう。

まずは parse.mul_and_div を呼び出している箇所を parse.atom を呼び出すように修正します。途中のブロックを変えたいときは、その下のブロックを一時的に退避させてから交換を行いましょう。
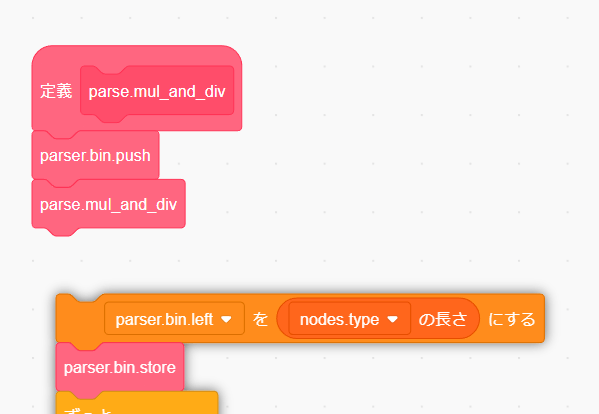
parse.atom に交換しましょう。

交換できたら退避させていたブロックを戻しましょう。
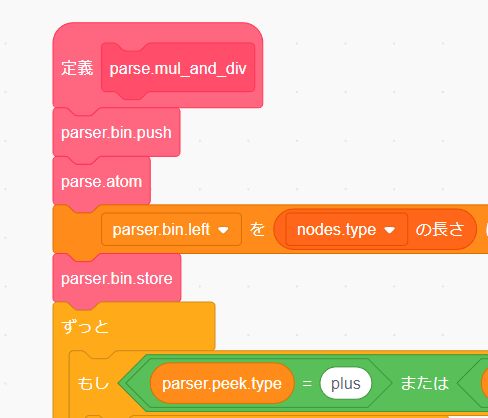
同じ要領で parser.next の次に呼んでいる parse.mul_and_div も ブロックパレットから parse.atom に交換します。

次に演算子のパースの修正を行います。
parse.mul_and_div は「掛け算」と「割り算」を処理します。
まずすべての条件式の plus は asterisk に minus はすべて slash にしましょう。
つぎに parse.bin.op の代入部分を add は mul に sub は div にしましょう。
最終的には以下の画像のようになります。
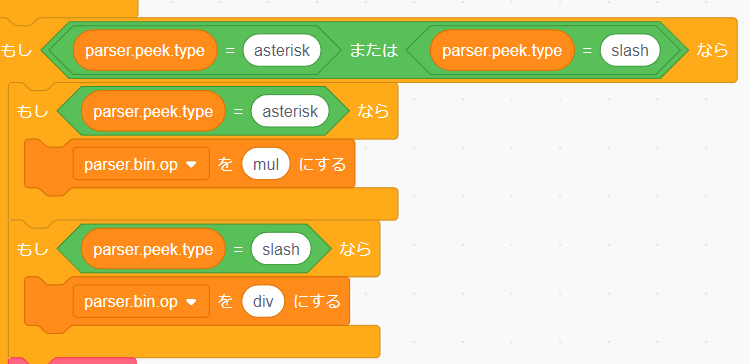
お疲れ様です!これで構文解析器は完成です!
試しに input に 1 + 2 * 3 を入力して実行してみましょう。

図にするとこのようになっています。ちゃんと掛け算が先に計算される AST になっています。

(1 + 2) * 3 も試してみましょう。

図にするとこんな感じです。ちゃんと () が優先されていますね。

評価
ここまででただの式の文字列から AST という複雑な構造のデータを生成することが出来ました。
今度はいよいよこの AST を使って計算をする処理をプログラムしていきます。
評価器
評価器は AST を一番上から順に走査して、実際に式を評価するプログラムです。
AST を走査して評価するとは何でしょうか。例として 1 + 2 + 3 の AST について考えてみましょう。
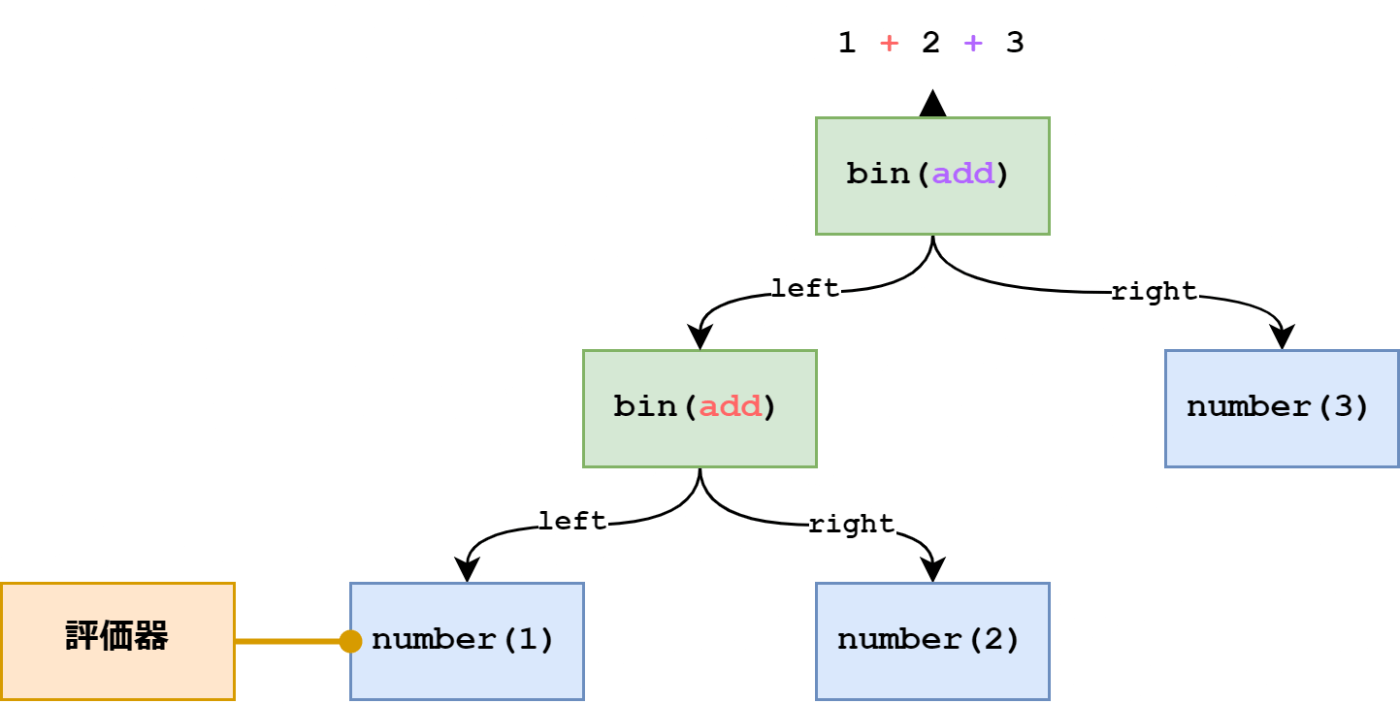
まず評価器は一番上のノードを評価します。この場合は bin ノードなので二項演算として評価します。二項演算を評価するには左辺と右辺を先に評価する必要があります。

まずは左辺を評価しましょう。また bin ノードが出てきました。

更に左辺を評価しましょう。今度は末端ノードである number が出てきました。
number ノードが出てきたらその値を予め用意しておいた計算スタックに追加します。

次は右辺の評価に入ります。右辺も number ノードなのでそのまま値を計算スタックに追加します。
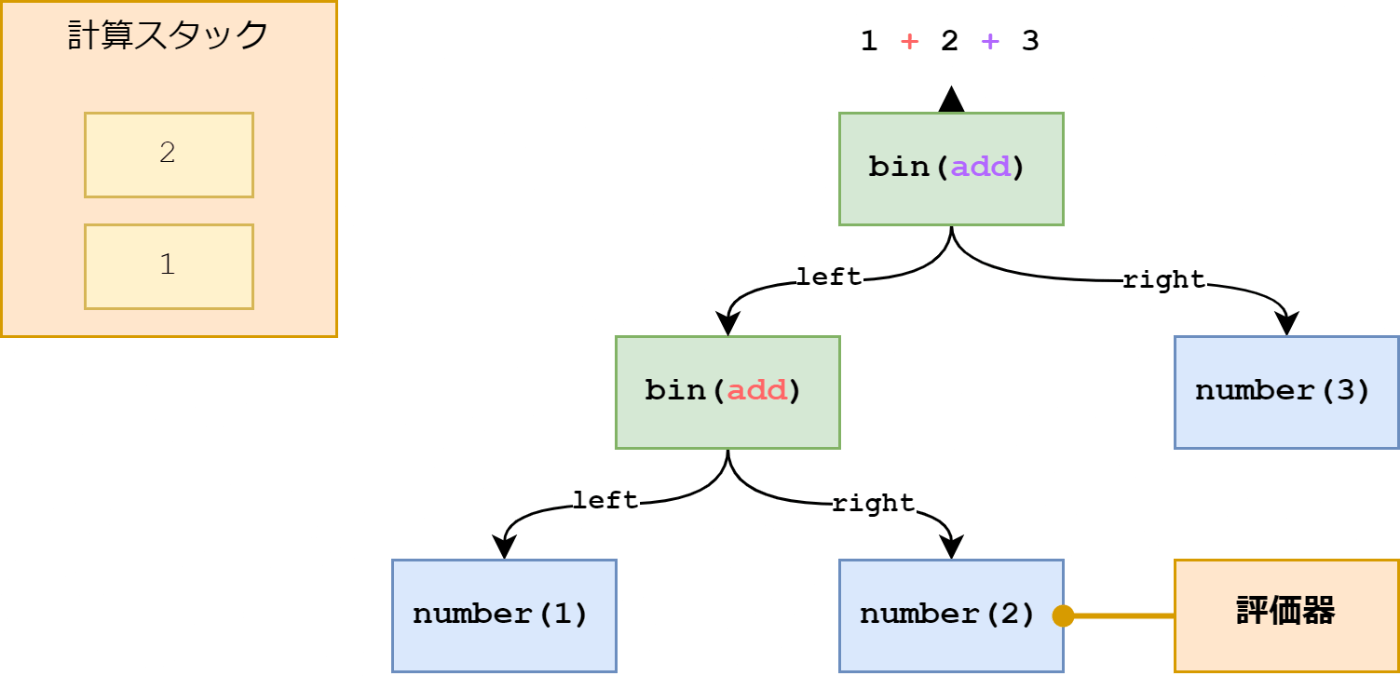
これでようやく二項演算の評価の準備が出来ました。

演算子は add なので計算スタックに積まれた値で足し算をします。このときに使用した値は削除します。
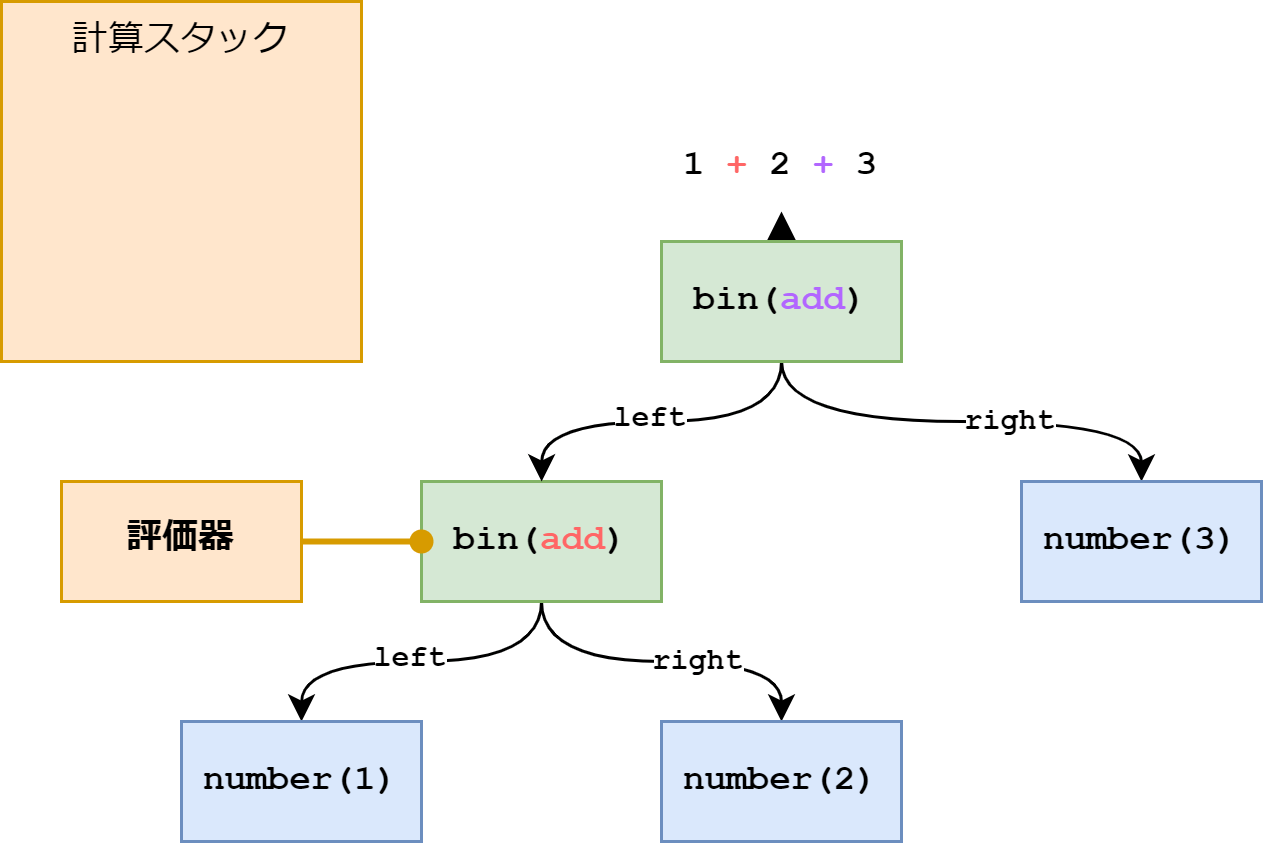
代わりに足し算の結果を計算スタックに追加します。

ようやく一番最初のノードに戻ってきました。残るは最後の右辺だけです。

最後の右辺は number ノードなので値をそのまま計算スタックに追加します。
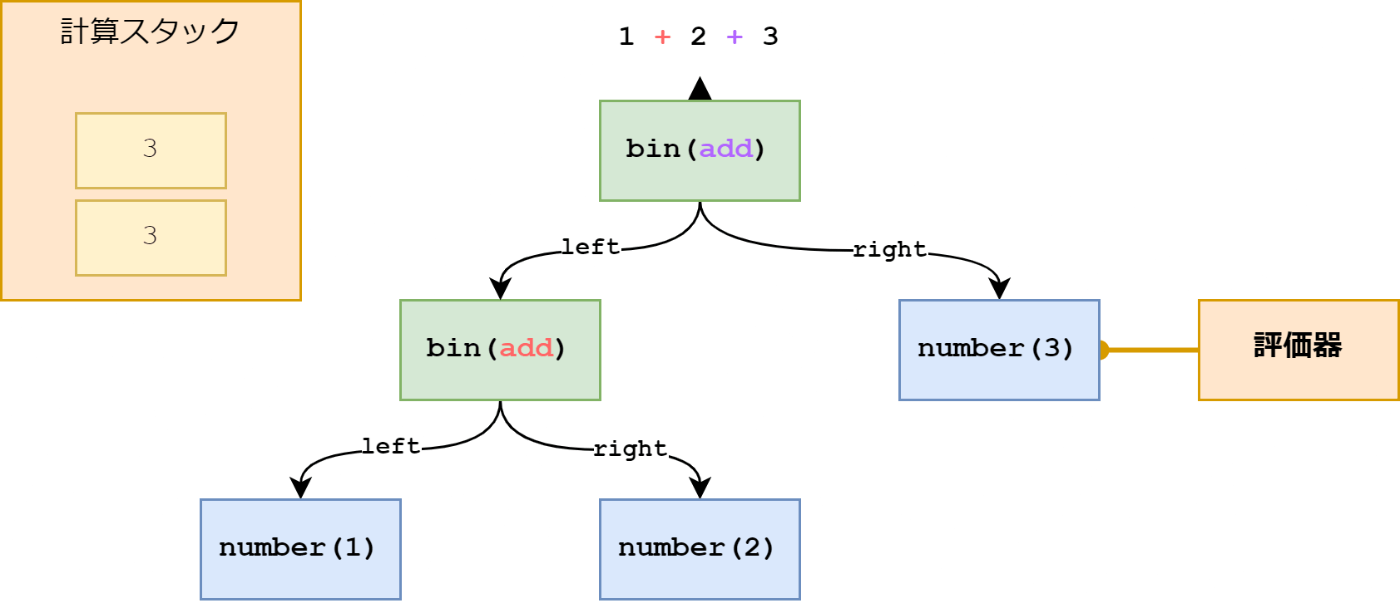
最後の二項演算も add なので足し算を行います。
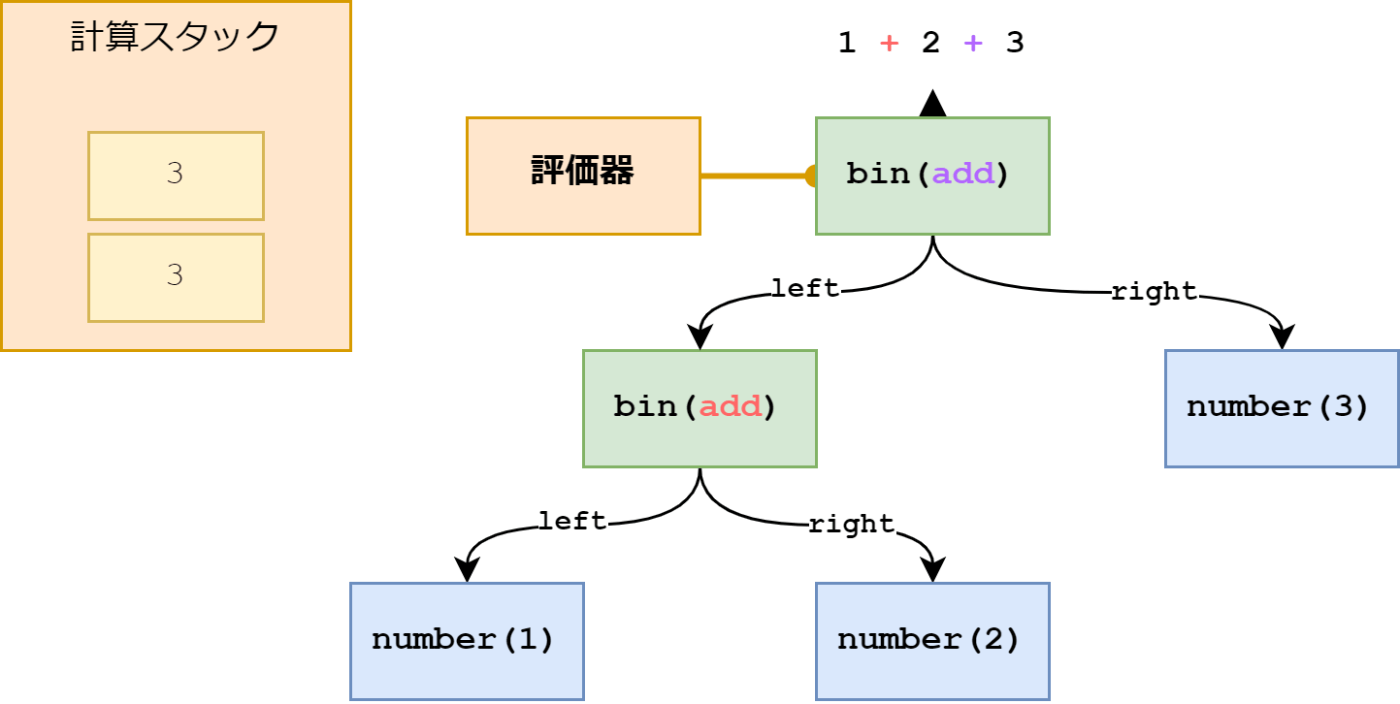
先ほどと同様に計算スタックを処理し、結果をスタックに追加します。
これでようやく AST の評価が終わりました。計算スタックに残っている値がその式の結果です。
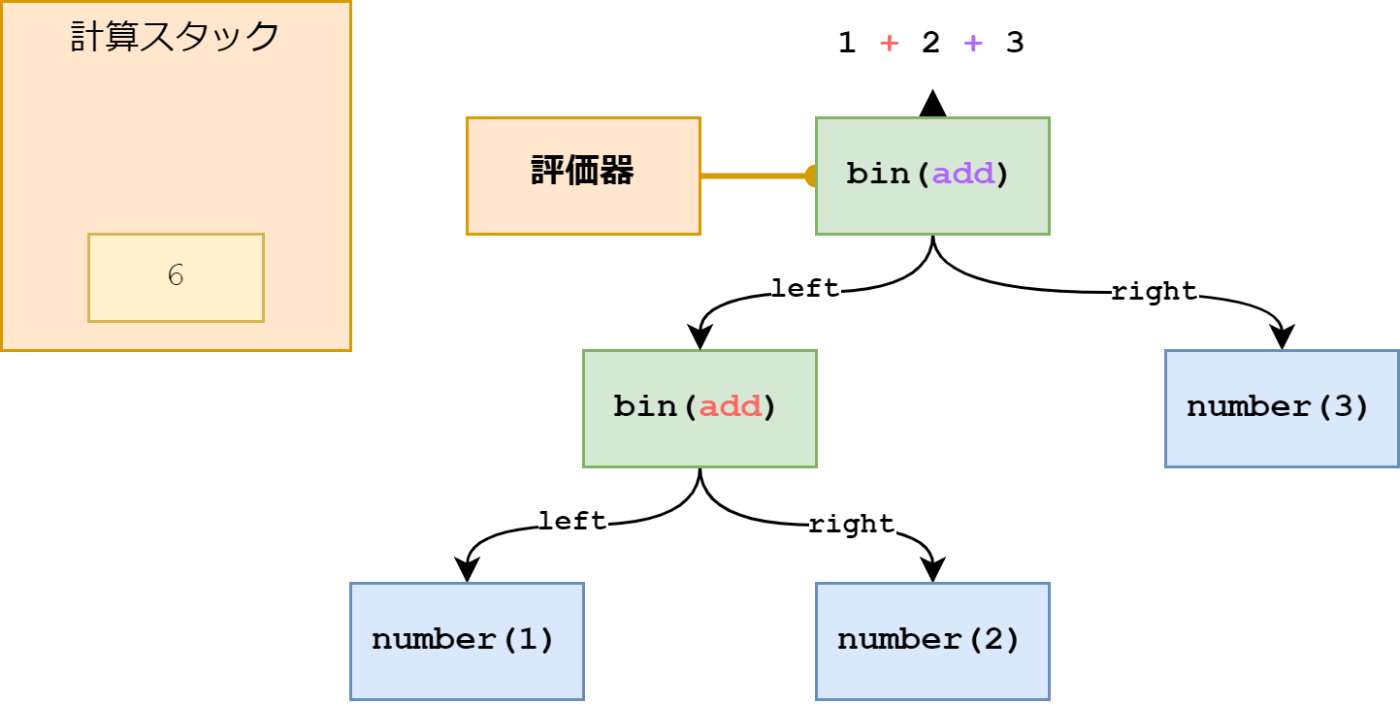
このように AST を一番上から順に走査することで評価するプログラムを Tree-walk Interpreter と言います。
では早速関数を作っていきましょう。
関数名は eval にしましょう。
また parse を呼び出した後に eval を呼び出すように追加します。

次に計算スタックを表すリストを作成します。
名前は interp.stack としておきましょう。

eval を実行したときに interp.stack を初期化するコードを追加します。

次に指定したノードを評価する関数を作ります。
名前は eval.node として node という名前の引数を受け取るようにしましょう。

評価器は一番上のノードから実行していくのでしたね。一番上のノードとはノードのリストの末尾にあるノードのことを示します。よって eval.node の引数に一番最後のノードのインデックスを渡すことで評価を始めることが出来ます。
以下のように eval.node を呼び出すプログラムを追加しましょう。

では eval.node 関数の中身を実装していきます。
まずノードの type を確認して number ノードなら値をそのまま計算スタックに追加します。
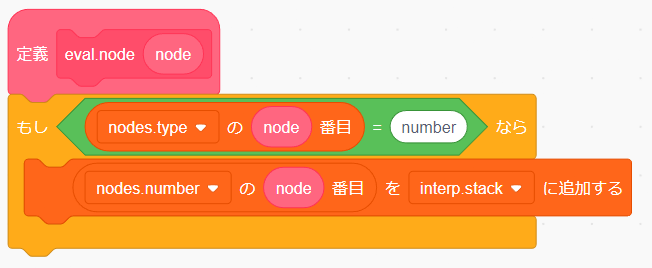
これだけで number ノードの評価をすることが出来るようになりました。試しに input に ((123)) のような演算のない式を入力して実行してみましょう。ちゃんと計算スタックに結果が表示されるはずです。

次に二項演算も実装します。
先ほどと同じようにノードの type を確認するプログラムを追加します。
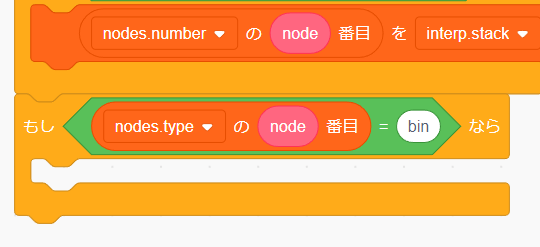
次に左辺と右辺の評価を eval.node を呼び出して行います。これで計算スタックには左辺と右辺の評価済みの値が追加されました。

次に左辺と右辺の値を演算子によって計算し、計算スタックに追加します。
その前にこのままだと左辺と右辺にアクセスする際にリストを使わなければいけないので、少し複雑になってしまいます。そのため以下の3つの変数を作りましょう。
-
interp.bin.left- スタック上の左辺の値
-
interp.bin.right- スタック上の右辺の値
-
interp.bin.result- 二項演算の結果
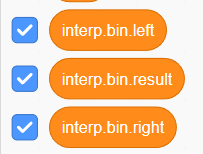
まず interp.bin.left と interp.bin.right にスタックの値を代入してあげます。
左辺から先に計算しているので interp.bin.left にはスタックの一番うしろから1つ前の値を代入することに注意してください。
右辺は左辺の次に計算しているためスタックの一番うしろの値をそのまま代入します。

次に演算子によって演算を行う条件分岐を作っていきます。
まずは足し算を作りましょう。そのまま nodes.op から演算子を取ることが出来ます。今回は足し算なので add であることを確認します。

実際の演算処理はとてもシンプルです。interp.bin.result に (interp.bin.left) + (interp.bin.right) の結果を代入するだけです。

同じ要領で以下の演算子も実装しましょう。
- 引き算 -
sub - 掛け算 -
mul - 割り算 -
div
最終的にはこうなります。

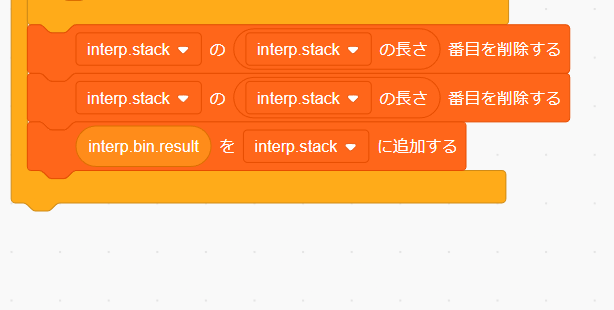
次に左辺と右辺のスタックを削除する必要があります。これは interp.stack の一番最後を2回削除すれば大丈夫です。

左辺と右辺のスタックを削除したら演算結果を計算スタックに追加しましょう。interp.bin.result を interp.stack に追加するプログラムを書けば大丈夫です。
これで評価器は完成です!
ただこのままだと毎回 input 変数に式を代入して...と自由度が低いので少し改造します。
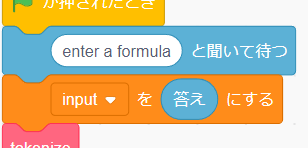
まず「調べる」タブから「()と聞いて待つ」を [input] を () にする の前に追加しましょう。

追加したブロックの () の中の文字列をを enter a formula にしましょう。
」というブロックを「[input] を () にする」の () に入れましょう。こうすることで実行時に毎回 input に代入する式を猫が聞いてくれるようになりました。
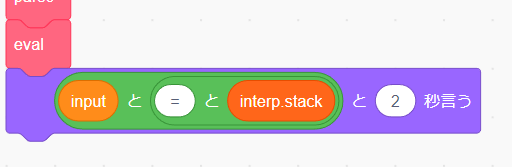
次に「見た目」タブから「()と(2)秒言う」を eval の後に追加しましょう。「演算」の「()と()」を2つ組み合わせて「(input) = (interp.stack)」と猫に喋らせるようにしましょう。
最後にこの一連のブロックを「制御」の「ずっと」で囲んで完成です。

これでプログラムはすべて完成です!実行して好きな式を入れたら Enter キーを押すと「字句解析」「構文解析」「評価」が走って結果が表示されるはずです!

Discussion