リモート関数を使用してRedashから自然言語でクエリする
RedashとBigQueryのリモート関数を活用し、自然言語でBigQueryのデータを抽出できるようにしました。
本文中のコード: https://github.com/hosimesi/code-for-techblogs/tree/main/redash_text_to_sql
本記事のアーキテクチャ

記事の趣旨
BIツール(Redash)から自然言語を入力すると、適切なSQLに変換し、必要なデータを取得するアプリケーションを作成します。昨今、非エンジニアであってもクエリを各場面が増えているように感じます。このようにデータアクセスが広がる一方で、SQL自体の習得にはまだ一定のハードルがあります。その流れを受けて、各DWHが自然言語でのデータ抽出インターフェースを提供し始めています。
- Bigquery
- Redshift
- Snowflake
しかし、DWHだけでなく、実際に利用しているRDBMSから情報を取得したい場合などはこれらの機能だけでは十分でないことがあります。また、DWHを操作するには適切な権限設定が必要で、メンバーがコンソールを自由に扱えないケースも考えられます。
そこで今回は、BIツールであるRedashから自然言語を用いて、BigQueryのデータを抽出できる仕組みを構築します。
事前知識
BIツールとは
BIツールは、蓄積された大量のデータを分析、可視化するためのソフトウェアです。代表的なBIツールには以下のようなものがあります
- Tableau
- Looker
- Redash
Redashは多くのデータベースとの接続やクエリの共有、ダッシュボードの作成が可能です。本記事では、このRedashを活用して自然言語からデータを取得する方法を試します。
Text to SQLとは
Text to SQLは、自然言語で書かれたテキストをSQLクエリに自動的に変換する技術です。これによりデータベースから必要な情報を取得するためのインターフェイスが増えることが期待でき、今もなお盛んに研究が行われています。
データとサービスアカウントの準備
データの準備
BigQueryには、誰でも利用できる一般公開データセットが用意されています。今回はその中から、Google Trendsのデータセットを使用します。このデータセットは、各国のGoogle検索結果のトレンドランキングをまとめたものです。
BigQueryのコンソールからクエリを実行する場合、以下のように記述できます。
select * from `bigquery-public-data.google_trends.top_terms`
where refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
ただ、一般的には自分たちのデータセットに作ったテーブルに対してクエリを投げることが多いと思うので、Google Trendsの1週間分のデータをコピーします。
まず、USのマルチリージョンにredash_nlpというデータセットを作成します。

その後テーブルを作成し、データをコピーします。
CREATE TABLE `aitech-good-s13187.redash_nlp.google_trends` AS
SELECT * FROM `bigquery-public-data.google_trends.top_terms` WHERE refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY);
サービスアカウントの準備
次に、RedashからBigQueryに接続するためのサービスアカウントを作成します。Google Cloudの「サービスアカウント」の画面から新規作成を行います。
その後、サービスアカウントに対してBigQueryへのクエリ実行に必要なロールを付与します。ジョブの実行が必要なため、以下のロールを付与します。
- BigQuery Job User
- BigQuery Data Viewer
- BigQuery Read Session User
- BigQuery Connection User
細かな権限管理も可能なので、本番環境で作成する際は慎重に設定してください。

設定が完了したら、そのサービスアカウントのキーをJSON形式でダウンロードします。

Redashの構築
Redashのセットアップ
次にローカルのDocker環境でRedashを立ち上げていきます。スコープをローカル環境でのセットアップに限定し、公式GitHubリポジトリとRedashセットアップ用のGitHubリポジトリを参考に、コンテナを起動していきます。
setup.shを使用すればサクッと構築可能ですが、今回は各ステップを一つずつ実行していきます。
※ Dockerはすでにインストール済みであることを前提としています。
-
PostgreSQLデータの永続化ディレクトリを作成
データの永続化を行うため、PostgreSQL用のデータディレクトリを作成します。$ mkdir postgres-data -
compose.yamlのダウンロード
こちらのリンクからcompose.yamlファイルをダウンロードします。このファイルは、Redashの各種サービスを定義したファイルです。compose.yamlx-redash-service: &redash-service image: redash/redash:latest depends_on: - postgres - redis env_file: .env restart: always services: server: <<: *redash-service command: server ports: - "5000:5000" environment: REDASH_WEB_WORKERS: 4 scheduler: <<: *redash-service command: scheduler depends_on: - server scheduled_worker: <<: *redash-service command: worker depends_on: - server environment: QUEUES: "scheduled_queries,schemas" WORKERS_COUNT: 1 adhoc_worker: <<: *redash-service command: worker depends_on: - server environment: QUEUES: "queries" WORKERS_COUNT: 2 redis: image: redis:7-alpine restart: unless-stopped postgres: image: pgautoupgrade/pgautoupgrade:latest env_file: .env volumes: - ./postgres-data:/var/lib/postgresql/data restart: unless-stopped nginx: image: redash/nginx:latest ports: - "80:80" depends_on: - server links: - server:redash restart: always worker: <<: *redash-service command: worker environment: QUEUES: "periodic,emails,default" WORKERS_COUNT: 1 -
データベースの初期化
Redashが使用するデータベースを初期化します。docker compose run --rm server create_db -
コンテナの起動
Docker Composeを使用して、Redashの各種サービスコンテナをビルド・起動します。docker compose up --build
Redashの設定
Redashに戻り、BigQueryにクエリを実行できるように設定を行います。
- Redashの画面で「Data Sources」を選択し、「New Data Source」をクリックします。

- 「BigQuery」を選択し、設定画面で必要な情報を入力します。
-
Project ID
- 自分のGoogle CloudプロジェクトIDを入力します。
-
JSON Key File
- 先ほどダウンロードしたサービスアカウントのJSONキーをアップロードします。
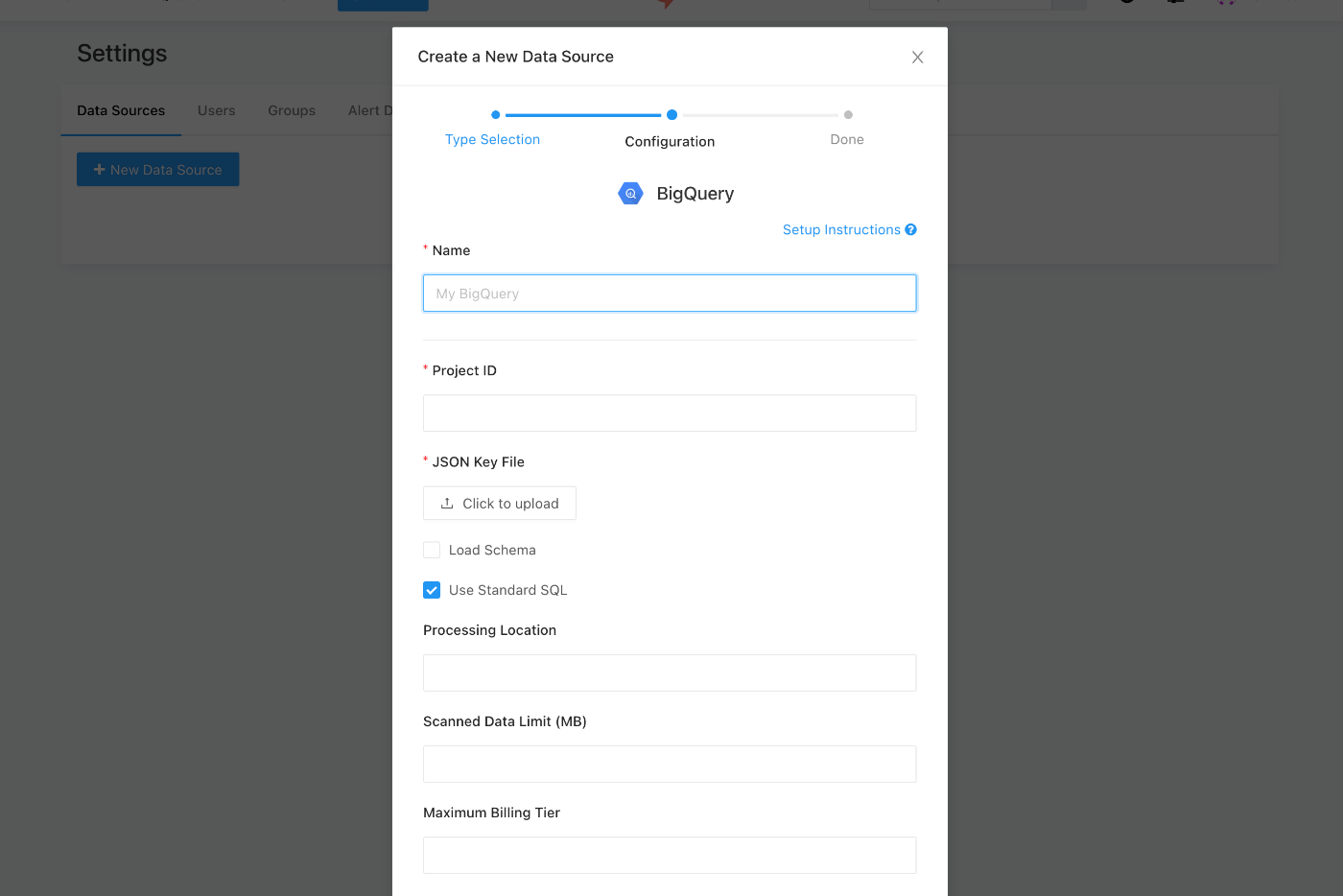
- 先ほどダウンロードしたサービスアカウントのJSONキーをアップロードします。
-
Project ID
- 入力が完了したら、「Test Connection」をクリックして、正常に接続できるか確認します。接続が成功したら、「Save」をクリックして設定を保存します。

これで、RedashからBigQueryへの接続設定は完了です。クエリエディタで先ほどのSQLを試しに実行し、データが取得できるか確認してください。
Redashから自然言語でクエリする
Cloud Run functionsの作成
今回は、BigQuery内にユーザー定義関数(UDF)を定義し、そこから外部のCloud Run functions上にデプロイしたGeminiを呼び出す構成を実装します。
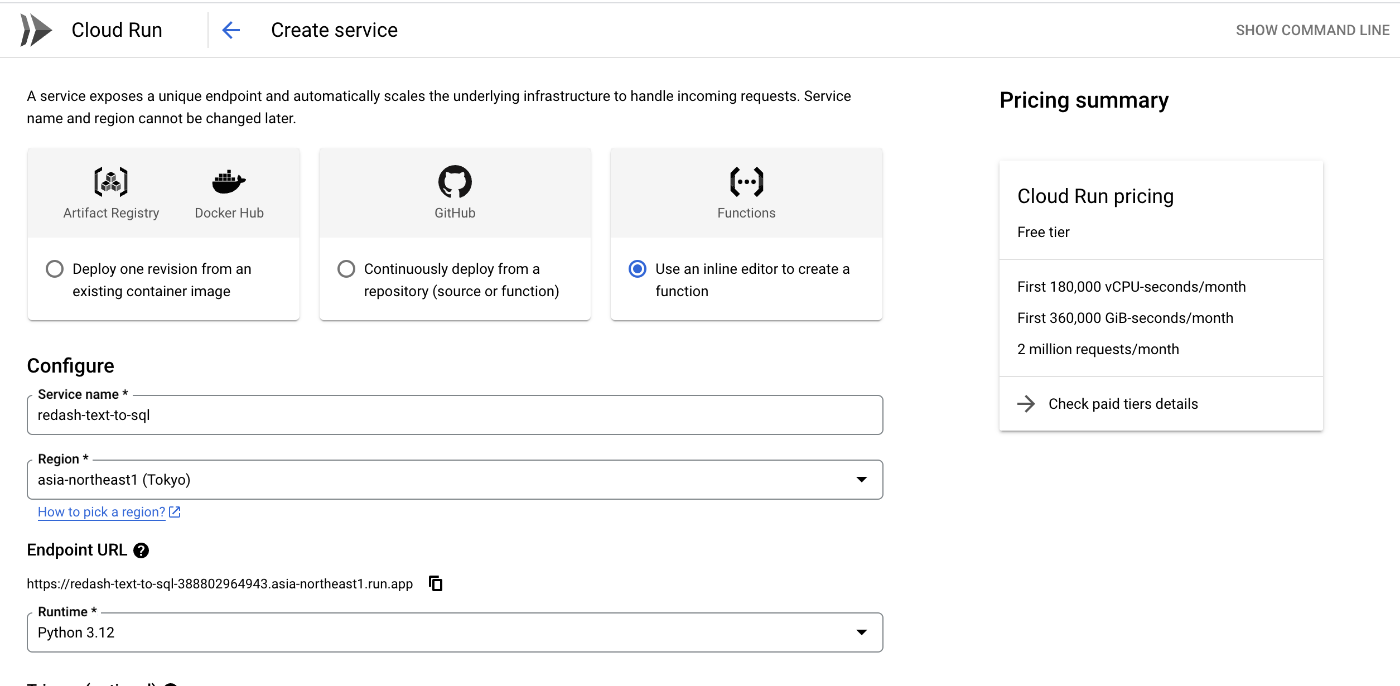
まず、Google Cloud コンソールから Cloud Run functions を作成します。
設定手順
-
サービス名の設定
- 適切なサービス名を指定します。
-
サービスアカウントの設定
- 関数が実行時に使用するサービスアカウントを指定します。シークレットマネージャーへのアクセスが必要となるため、このサービスアカウントには Secret Manager Secret Accessor ロールを付与します。
-
シークレットの登録
- GEMINIのAPIキーなど、必要なシークレットを登録します。
-
環境変数の設定
- 必要な環境変数を設定します。
- 必要な環境変数を設定します。
コードの記述
次に、Cloud Run functionsで実行するコードを記述します。
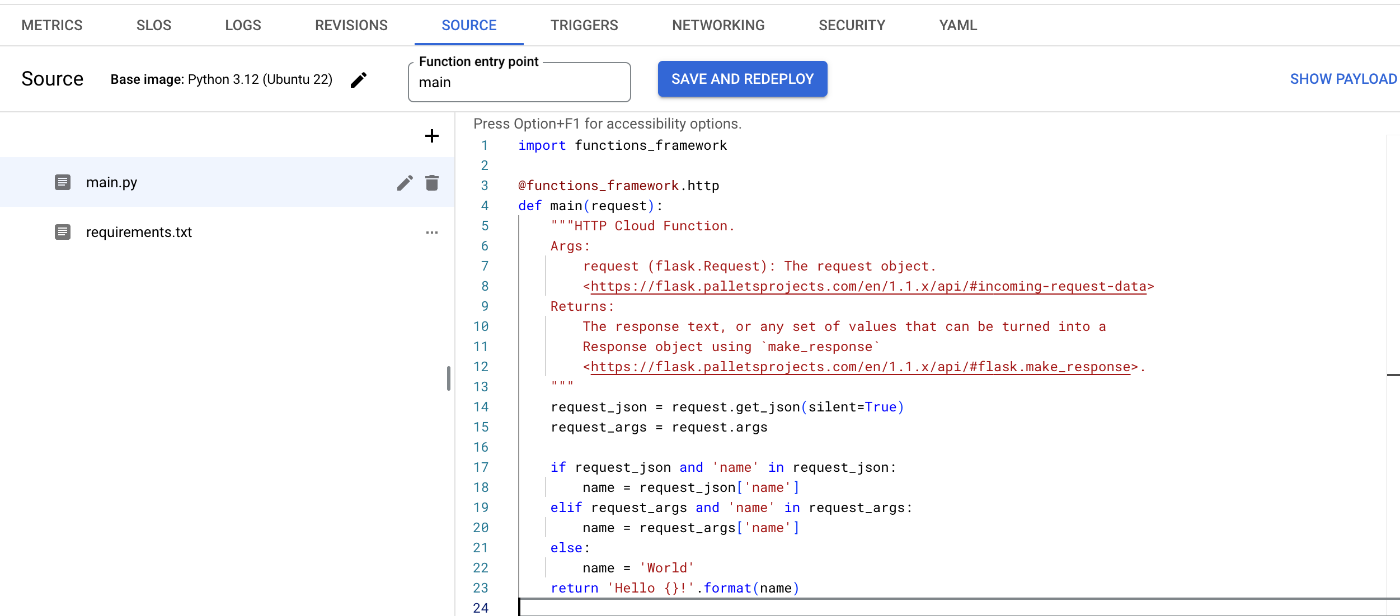
以下は、今回作成したコードの一例です。プロンプトは検証用のため、必要に応じて最適化してください。
import functions_framework
import os
import json
import google.generativeai as genai
# Gemini APIキーの取得
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
# Gemini APIキーの設定
genai.configure(api_key=GEMINI_API_KEY)
@functions_framework.http
def main(request):
"""
HTTP Cloud Function.
Args:
request (flask.Request): The request object.
https://flask.palletsprojects.com/en/1.1.x/api/#incoming-request-data
Returns:
The response text, or any set of values that can be turned into a
Response object using `make_response`
https://flask.palletsprojects.com/en/1.1.x/api/#flask.make_response
"""
# リクエストから質問を取得
request_json = request.get_json(silent=True)
request_args = request.args
request_json = request.get_json(silent=True)
if not request_json or 'calls' not in request_json:
return '不正なリクエストです。', 400
replies = []
for call in request_json['calls']:
# call は引数のリスト
if len(call) != 1:
replies.append({'errorMessage': '引数の数が正しくありません。'})
continue
question = call[0]
# GeminiのAPIキーが設定されているか確認
if not GEMINI_API_KEY:
return 'GeminiのAPIキーが設定されていません。', 500
# プロンプトの作成
prompt = f"""ユーザーからの自然言語の質問を理解し、適切なBigQueryのSQLクエリに変換してください。
出力はSQLのみで不要な出力は控えてください。出力されたSQLは実行可能な状態にしてください。
以下のテーブルがあります:
- テーブル名:`redash_nlp.google_trends`
- 内容:`bigquery-public-data.google_trends.top_terms`の直近7日間のデータが格納されています。
- 注意:ユーザーがGoogle Trendsのデータを参照したい場合は、このテーブルを使用してください。
以下の点に注意してください:
- コードブロック(```sqlや```)や改行記号(\nや\n )を含めず、純粋なSQLクエリのみを出力してください。
- 出力には説明やコメントを含めないでください。
質問: {question}
SQLクエリ:
"""
try:
model = genai.GenerativeModel("gemini-2.0-flash-exp")
response = model.generate_content(prompt)
generated_sql = response.text.strip()
if generated_sql.startswith('```'):
generated_sql = generated_sql.strip('```sql').strip('```').strip()
else:
generated_sql = generated_sql
if not generated_sql.lower().startswith(('select', 'with')):
# エラー時のレスポンスを修正
error_response = {
"replies": [
{
"errorMessage": "生成されたSQLがSELECT文ではありません。"
}
]
}
return json.dumps(error_response, ensure_ascii=False), 200, {'Content-Type': 'application/json'}
# 成功時のレスポンスを修正
success_response = {
"replies": [generated_sql]
}
return json.dumps(success_response, ensure_ascii=False), 200, {'Content-Type': 'application/json'}
except Exception as e:
# エラー時のレスポンスを修正
error_response = {
"replies": [
{
"errorMessage": f"エラーが発生しました: {str(e)}"
}
]
}
return json.dumps(error_response, ensure_ascii=False), 200, {'Content-Type': 'application/json'}
requirements.txt ファイルにも必要なライブラリを追加します。
google-generativeai==0.8.*
ローカル環境からリクエストを送信し、正常にレスポンスが返ってくることを確認できれば、Cloud Run functionsの設定は完了です。
curl -X POST \
-H "Content-Type: application/json" \
-d '{"question": "bigqueryの一般公開データのGoogle Trendから直近1日のデータを100件取ってきて欲しい"}' \
https://YOUR_FUNCTION_URL
{"generated_sql": "SELECT * FROM `bigquery-public-data.google_trends.top_terms` WHERE refresh_date = CURRENT_DATE() ORDER BY rank LIMIT 100"}
BigQueryでのリモート関数の設定
コネクションの作成
Cloud Run functionsをリモート関数として呼び出すため、BigQueryでコネクションを作成します。リモート関数を作成する前段階としてコネクションを設定します。BigQueryのコンソールから「Add」を選択し、「Connections to external data sources」を選択します。
その後、以下のように必要事項を入力してコネクションを作成します。
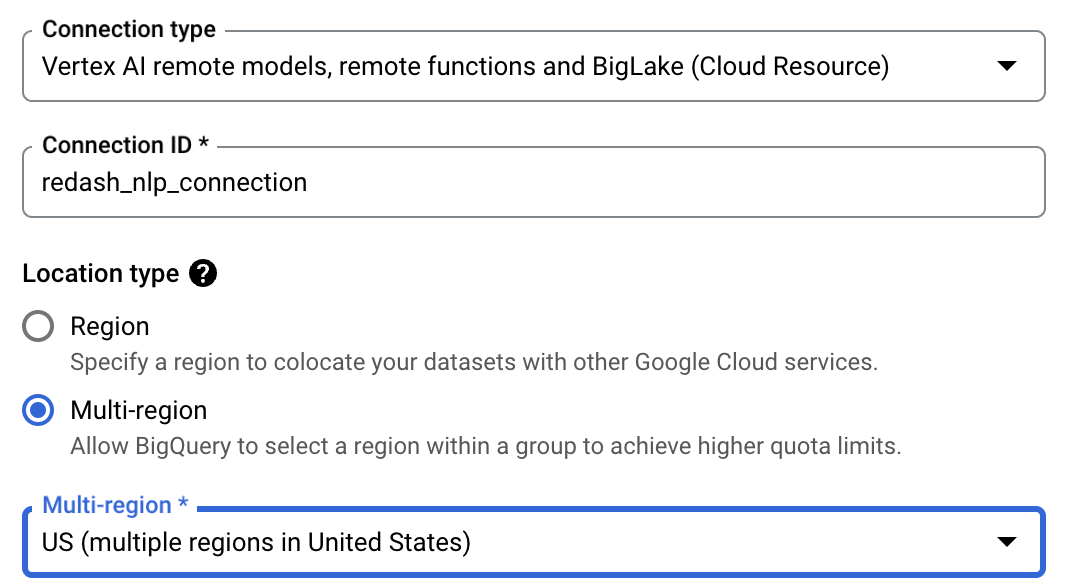
-
Connection ID: 任意のコネクションIDを指定します。例:
redash_nlp_connection
リモート関数の作成
コネクションが設定できたら、次にリモート関数を作成します。以下のSQLをBigQueryのクエリエディタで実行してリモート関数を作成します。
設定は以下の通り行います。
- Cloud Run Service URL: 先ほどデプロイしたCloud Run functionsのURLを指定します。
-
Location
- Cloud Run functionsをデプロイしたリージョンを選択します。
CREATE FUNCTION `your_project_id.redash_nlp.main`(question STRING) RETURNS STRING
REMOTE WITH CONNECTION `your_project_id.your_region.redash_nlp_connection`
OPTIONS (
endpoint = 'https://your-cloud-run-function-url'
);
自身の設定に合わせて書き換えてください。
プロシージャの作成
Redash側から簡単に呼び出せるようにプロシージャを作成しておきます。
CREATE OR REPLACE PROCEDURE redash_nlp.redash_nlp_procedure(query STRING)
BEGIN
DECLARE question STRING;
DECLARE sql_query STRING;
SET sql_query = `your_project_id.your_dataset_id.main`(query);
SELECT sql_query;
EXECUTE IMMEDIATE sql_query;
END;
Redashから呼び出す
Redashからプロシージャを呼び出します。下記のように結果が取れていれば成功です。
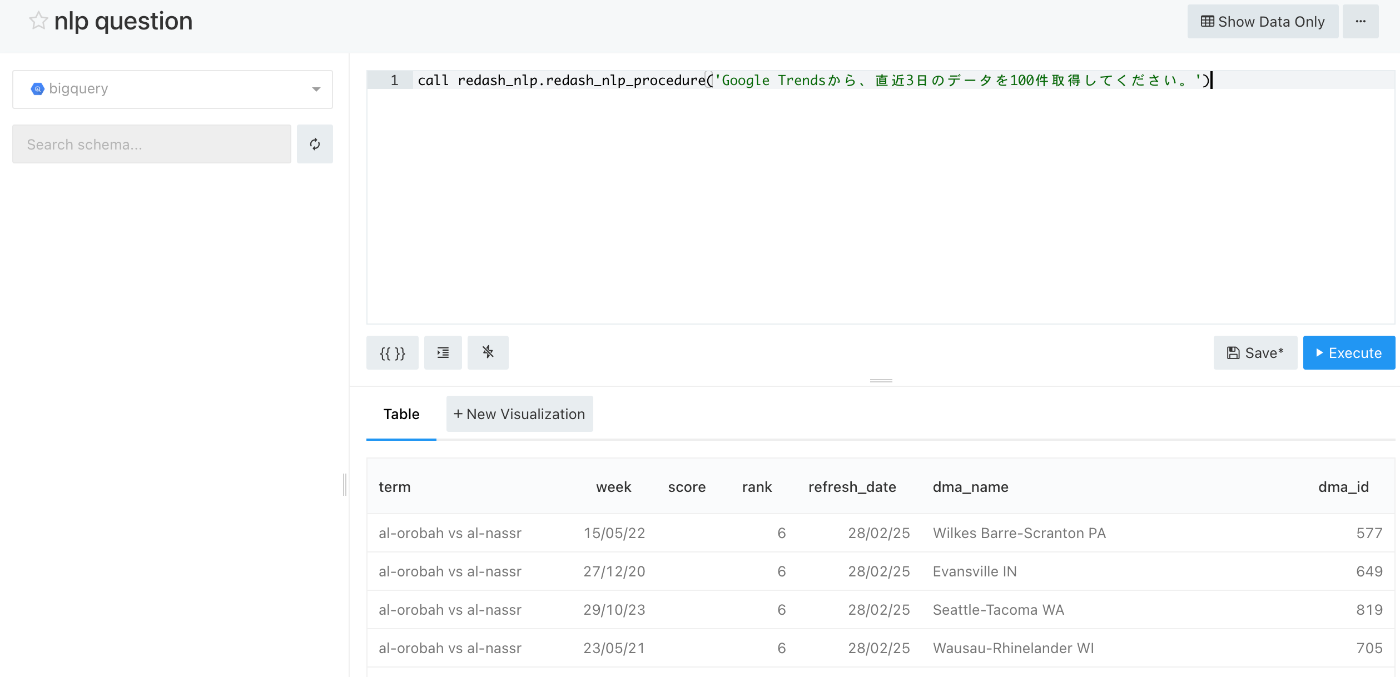
実際に生成されて実行されたSQLは下記でした。
SELECT * FROM `redash_nlp.google_trends` WHERE refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 3 DAY) LIMIT 100
まとめ
リモート関数とプロシージャを間に挟むことで、Redashから自然言語でBigQueryにクエリを投げることができるようになりました。
今回はCloud Run functionsはどこからでも叩ける設定にしていますが、本番利用する際は設定を変更してください。また、SQLインジェクションの可能性もあるので社内利用のみなど公開範囲を制限する必要があると思います。
参考
Discussion