GKEで構築するストリーミングレスポンス
この記事はMLOps Advent Calendar 2023への投稿記事です。
GKE上にエンドポイントを立て、Azure OpenAI APIからのレスポンスをストリーミングで返す実装を複数パターン試してみました。
本文中のコード: https://github.com/hosimesi/streaming-server
記事の趣旨
ChatGPTをはじめとする生成AIを使ったサービスが増えてきています。一方で、LLMからのレスポンスは一般的に遅く、ユーザ体験に影響します。
ユーザ体験向上のため、生成文を一括で返すのではなく、生成された文字から随時返却するストリーミングでは、一文字目が早く現れるため、ユーザ体験を向上させる可能性があります。本記事では、それらのストリーミングの実装を複数パターン試してみます。
これまでAWSを業務で扱っていましたが、最近GCPを触る機会が増えてきたので、GKE上でそれらのシステムを構築してみます。
※ ここでのストリーミングは数文字ずつ返却される処理を指しています。
※ FastAPIの細かい書き方、ロギング、認証などは本記事では扱いません。
本記事のゴール
簡易的なLLMとやり取りできるWebサービスを準備し、ブラウザからクエリを投げて結果が返ってくるまでを確認します。その際、それぞれの通信手段でサーバにリクエストを投げれるようにします。
作成するサービスの簡易構成図です。
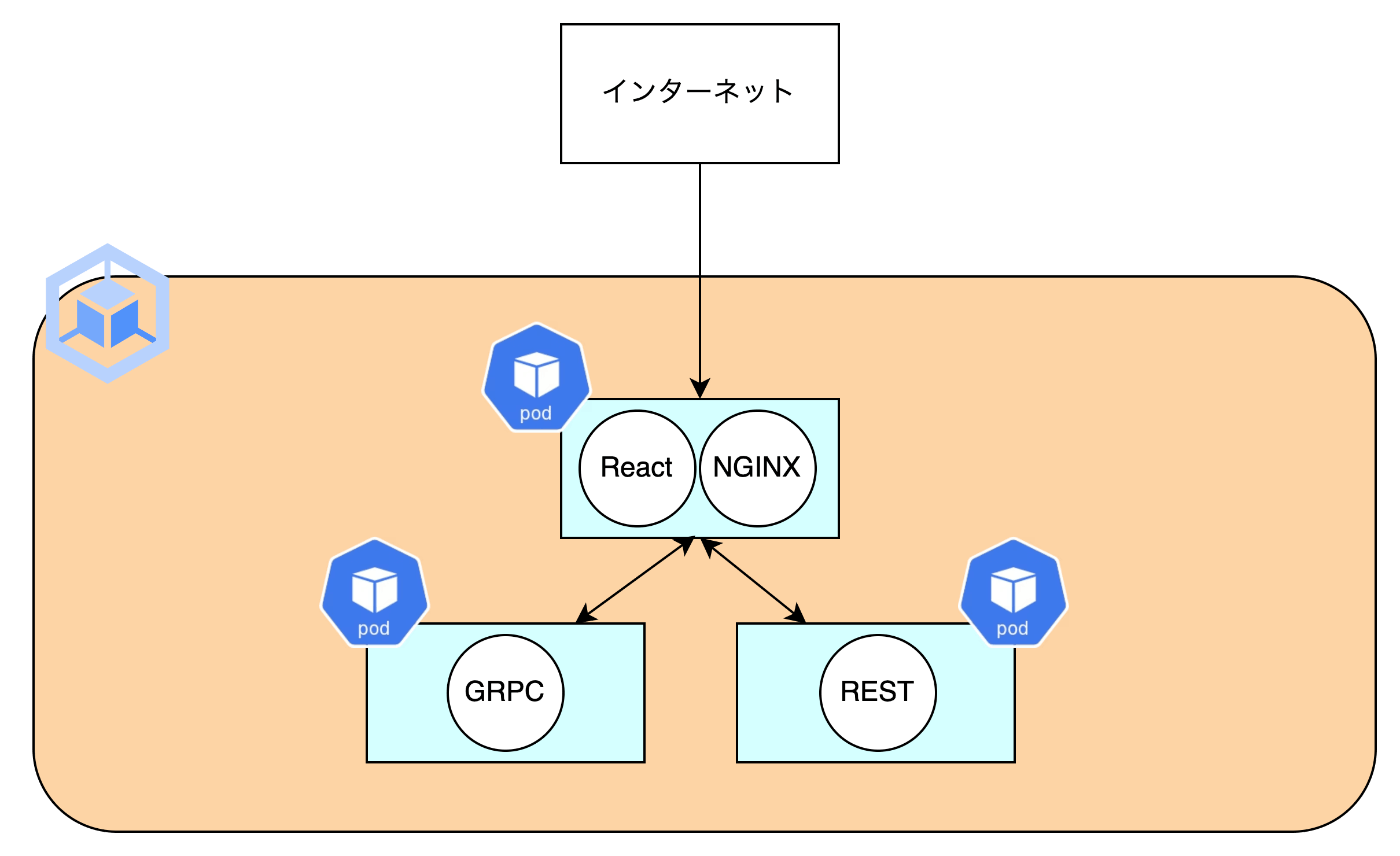
ストリーミングで文字を表示するために以下4つの実装を試してみます。
- gRPC
- WebSocket
- REST
- StreamingResponse
- EventSourceResponse
事前準備
Azure OpenAIの設定
OpenAIのAPIはOpenAI公式と、Azureがサポートしています。オプトインやセキュリティに軽微な差はあるものの、基本的にはほとんど同じインターフェイスを提供しています。
本記事では、Azure OpenAIのAPIを使いますが、お好みの方をお使いください。設定方法は以下の記事に詳しく書かれておりますので、本記事では割愛します。
Artifact Registryの作成
Docker Imageの登録先として、Artifact Registryを使用します。
まずは上記のURLから、GCPにログインします。
検索ウィンドウにArtifact Registryと入力し、Artifact Registryを選択します。
リポジトリを作成を押します。
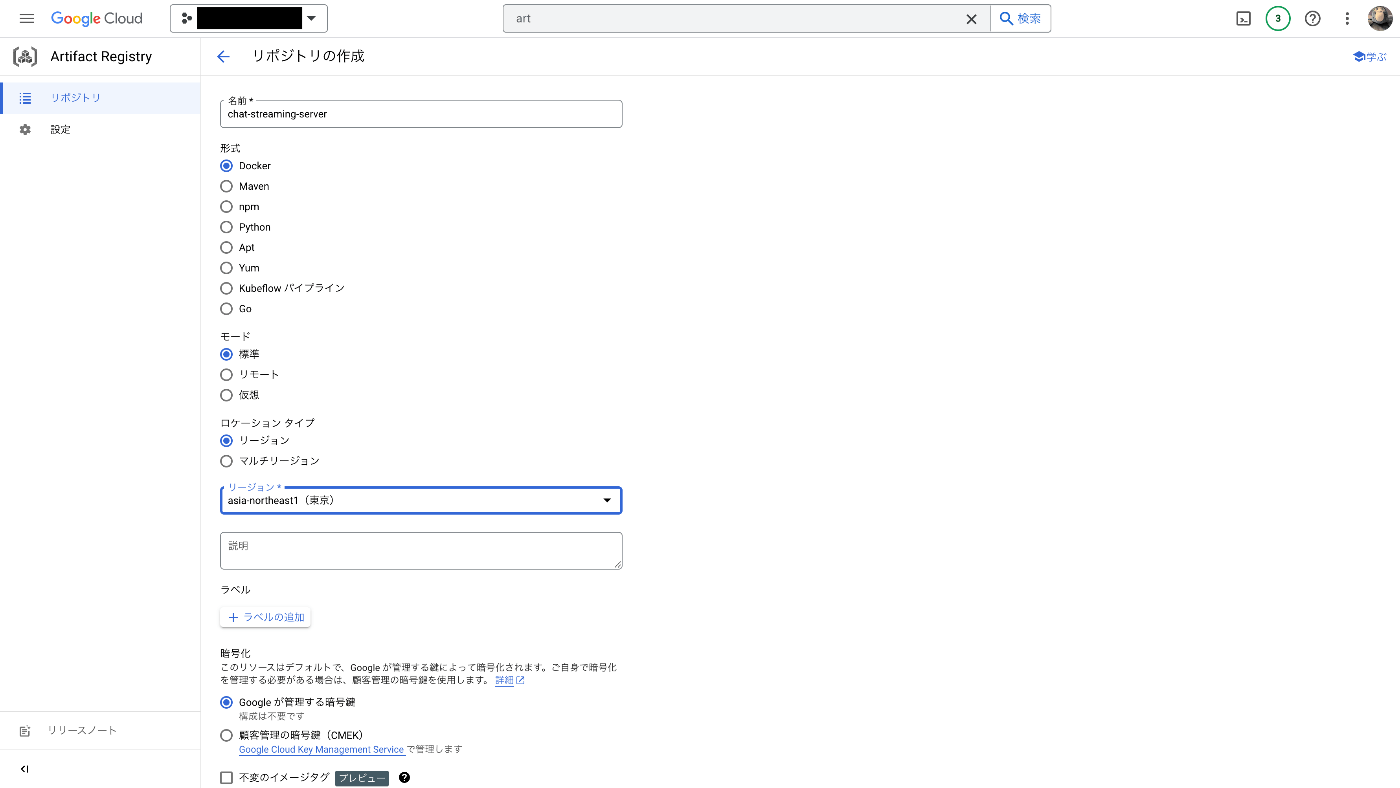
名前、リージョンなどの設定を行います。名前をchat-streaming-server、リージョンをasia-northeast1にします。
その他の設定はdefaultのままにし、作成を押すとリポジトリの作成は完了です。
CLIからでも設定可能です。
CLIでの設定
1. gcloudの認証
gcloud auth login
gcloud config configurations activate ${PROJECT}
2. Repositoryの作成
gcloud artifacts repositories create chat-streaming-server --location "asia-northeast1" --repository-format "docker"
GKEクラスタの作成
Kubernetesのクラスタを作成します。
本記事では、publicにAPIを公開するので、検証後すぐに削除します。

まずは上記のURLから、GCPにログインします。
GKEを使うので、サイドバーにあるKubernetes Engineを選択します。

クラスタ > 作成 を押し、クラスタを作成します。

次に、クラスタの名前、リージョンを設定します。今回は、asia-northeast1にAutopilotのクラスタを準備します。
※ Standardクラスタとの違いはこちらを参考にしてください。

ネットワーキングは変更せず、defaultの値のまま進みます。
一旦、外部アクセスを禁止したいので、限定公開クラスタで作成します。後ほど、フロントエンドサービスのみを外部に公開します。また、オートスケーリングの設定などはしません。
✅ 全てのサービスを外部アクセス可能にしたい場合、一般公開クラスタが使用できます。ただし、本番環境で使うときはdefaultネットワークを使用したり、パブリックサブネットにエンドポイントを作成せず、適切なネットワーク、プライベートサブネットへのエンドポイント配置などをしてください。
残りは全てdefault設定になります。
クラスタを作成を押すことでクラスタが作成されます。
これらの操作はCLIからでも可能です。
CLIでの設定
gcloud container --project "your_project" clusters create-auto "streaming-server" --region "asia-northeast1" --release-channel "regular" --enable-private-nodes --network "your/project/global/networks/default" --subnetwork "your/project/regions/asia-northeast1/subnetworks/default" --cluster-ipv4-cidr "/17"
※追加設定
限定公開クラスタを使っているため、プライベートなpodからインターネットに公開されているAPI(Azure OpenAIのAPI)は叩くことができません。外部アクセスできるように設定を追加していきます。
- プライベートサービスアクセスを有効化します。

- ルーターを作成します。

- NATを作成します。

以上の設定で、プライベートなpodから外部アクセスが可能になります。
画面の準備
サーバに直接curlでリクエストを投げてもいいですが、ここでは動作確認のため簡単な画面をReactで作ってみます。ここは本記事の本質ではないので、詳細はこちらでご確認ください。
構成としては、ReactとNGINXをサイドカーでたて、ルーティングしています。もう少しまとめられたら別記事で紹介したいと思います。サーバとgRPCで通信する必要があるため、リバースプロキシの準備など少し手順が必要です。

Serverの実装
Azure OpenAIにリクエストを投げる部分はどの処理でも共通になります。
※ AzureOpenAIに対するリクエストのパラメータはたくさんありますが、本質ではないため、仮置きです。具体的に気になる方はこちらを参考にして設定してください。
import asyncio
from functools import lru_cache
from openai import AzureOpenAI
from schemas.chat import ChatRequest
from utils.config import Settings
@lru_cache()
def get_settings():
return Settings()
class OpenAIService:
def __init__(self):
self.settings = get_settings()
self.client = AzureOpenAI(
api_version=self.settings.OPENAI_API_VERSION,
azure_endpoint=self.settings.OPENAI_API_BASE,
api_key=self.settings.OPENAI_API_KEY,
)
async def get_chat_streaming_response(self, chat_request: ChatRequest):
if not chat_request.stream:
raise Exception("Use get_chat_response for non-streaming responses")
for response in self.client.chat.completions.create(
model=self.settings.OPENAI_CHAT_ENGINE,
messages=[{"role": "user", "content": chat_request.prompt}],
temperature=chat_request.temperature,
seed=chat_request.seed,
max_tokens=chat_request.max_tokens,
stream=chat_request.stream,
):
if response.choices:
yield f"data: {response.choices[0].delta.content}\n\n"
await asyncio.sleep(0.1)
async def get_chat_event_source_response(self, chat_request: ChatRequest):
if not chat_request.stream:
raise Exception("Use get_chat_response for non-streaming responses")
for response in self.client.chat.completions.create(
model=self.settings.OPENAI_CHAT_ENGINE,
messages=[{"role": "user", "content": chat_request.prompt}],
temperature=chat_request.temperature,
seed=chat_request.seed,
max_tokens=chat_request.max_tokens,
stream=chat_request.stream,
):
if response.choices:
yield f"{response.choices[0].delta.content}\n\n"
await asyncio.sleep(0.1)
async def get_chat_response(self, prompt: str):
for response in self.client.chat.completions.create(
model=self.settings.OPENAI_CHAT_ENGINE,
messages=[{"role": "user", "content": prompt}],
temperature=1,
seed=42,
max_tokens=100,
stream=True,
):
if response.choices:
yield f"{response.choices[0].delta.content}\n\n"
await asyncio.sleep(0.1)
ここでは、AzureOpenAIへのクライアントになるクラスを作ります。
ここで、それぞれのメソッドは各エンドポイントから呼び出し、それぞれにあったようにレスポンスを整形しているだけであり、処理の内容自体は特に変わりません。
また、self.client.chat.completions.createはSSE(Server-Sent Events)で返ってくるため、各メソッド内でイテレータを回して、yieldで返しています。
gRPC
gRPCには4つの通信方式があります。
- Unary RPCs
- Server streaming RPCs
- Client streaming RPCs
- Bidirectional streaming RPCs
今回の用途ではクライアントからプロンプトを一回のリクエストで送り、サーバサイドから、ストリーミングでレスポンスを返したいため、Server streaming RPCsを採用します。
まずはprotoファイルを生成します。
streaming_server.proto
syntax = "proto3";
package stream;
service ResponseStreamingService {
rpc stream (UserRequest) returns (stream LlmResponse);
}
message UserRequest {
string prompt = 1;
}
message LlmResponse {
string llm_content = 1;
}
そして、gRPCサーバの実態はこのように書くことができます。
import asyncio
import logging
import grpc
from proto import streaming_server_pb2, streaming_server_pb2_grpc
from services.open_ai import OpenAIService
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def run(bind_address: str) -> None:
asyncio.run(_run(bind_address))
async def _run(bind_address: str) -> None:
logger.info(f"Starting server on {bind_address}")
server = grpc.aio.server()
streaming_server_pb2_grpc.add_ResponseStreamingServiceServicer_to_server(ServerStreamService(), server)
server.add_insecure_port(bind_address)
logger.info("Starting server")
await server.start()
await server.wait_for_termination()
class ServerStreamService(streaming_server_pb2_grpc.ResponseStreamingServiceServicer):
def __init__(self):
self.service = OpenAIService()
async def stream(self, request, context) -> streaming_server_pb2.LlmResponse:
response = self.service.get_chat_response(request.prompt)
async for chat in response:
yield streaming_server_pb2.LlmResponse(llm_content=f"Response {chat}")
await asyncio.sleep(0.1)
ここで、OpenAIServiceのget_chat_responseに返ってくる結果をasync forでループしてクライアントにストリーミングで流しています。
REST API
FastAPIで実装してみます。contentType=”text/event-stream” などを設定することで自前で実装できますが、標準で用意されているStreamingResponseを使用することにします。また、似たような実装のサードパーティ製(sse_starlette)のEventSourceResponseがあり、それらも試してみます。
これらはともにstarletteの派生系です。FastAPIはstarletteを内部的に使用しており、starlette内のStreamingResponseそのものです。一方で、EventSourceResponseはそれをSSE用にさらに派生化させたものです。
StreamingResponse
まず、リクエストを受け取る用のエンドポイントを立てます。
from fastapi import APIRouter, WebSocket
from fastapi.responses import StreamingResponse
from schemas.chat import ChatRequest
from services.open_ai import OpenAIService
from sse_starlette.sse import EventSourceResponse
router = APIRouter(
tags=["openai"],
dependencies=[],
responses={404: {"description": "Not found"}},
)
@router.post("/streaming/fastapi/")
async def fastapi(chat_request: ChatRequest):
service = OpenAIService()
return StreamingResponse(service.get_chat_streaming_response(chat_request), media_type="text/event-stream")
今回の実装では、get_chat_streaming_responseの結果をそのままStreamingResponseクラスに入れてそのまま返します。
ここで、SSEでは”data: ‘’”の形式で返す必要があるため、get_chat_streaming_response で整形しています。
EventSourceResponse
基本的にはStreamingResponseと同じです。まず、リクエストを受け取る用のエンドポイントを立てます。
from fastapi import APIRouter, WebSocket
from fastapi.responses import StreamingResponse
from schemas.chat import ChatRequest
from services.open_ai import OpenAIService
from sse_starlette.sse import EventSourceResponse
router = APIRouter(
tags=["openai"],
dependencies=[],
responses={404: {"description": "Not found"}},
)
@router.post("/streaming/starlette/")
async def stream(chat_request: ChatRequest):
service = OpenAIService()
return EventSourceResponse(service.get_chat_event_source_response(chat_request))
今回の実装では、get_chat_event_source_response の結果をそのままStreamingResponseクラスに入れてそのまま返します。
Event Source Responseでは返り値を”data: ‘’”の形式にせずとも、そのままEventSourceResponseクラスに入れると整形し、クライアントに返してくれるため、get_chat_event_source_responseでは特に何も整形する必要はありません。
WebSocket
こちらもFastAPIで実装してみます。tornadoやwebsockets、Djangoなどのライブラリでも実装可能ですが、簡単化のため、FastAPIで実装します。
これもRESTと同様にstarletteを元に動きます。
from fastapi import APIRouter, WebSocket
from fastapi.responses import StreamingResponse
from schemas.chat import ChatRequest
from services.open_ai import OpenAIService
from sse_starlette.sse import EventSourceResponse
router = APIRouter(
tags=["openai"],
dependencies=[],
responses={404: {"description": "Not found"}},
)
@router.websocket("/ws")
async def websockets(websocket: WebSocket):
service = OpenAIService()
await websocket.accept()
while True:
data = await websocket.receive_text()
async for response in service.get_chat_streaming_response(ChatRequest(prompt=data)):
await websocket.send_text(response)
RESTの時とは少し記法が異なります。websocketsではコネクションを貼り、get_chat_streaming_response の結果をそのままクライアントに返却します。
デプロイ
-
まずはk8sに関わるyamlファイルを書いていきます。
deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: frontend spec: replicas: 1 selector: matchLabels: app: frontend template: metadata: labels: app: frontend spec: dnsConfig: nameservers: - 10.96.0.10 options: - name: ndots value: "5" dnsPolicy: None containers: - name: frontend image: <your/frontend/image/uri> ports: - containerPort: 3000 env: - name: REACT_APP_REST_API_URL value: "<your/public/ip>/api/" - name: REACT_APP_GRPC_API_URL value: "<your/public/ip>/grpc/" - name: nginx image: <your/nginx/image/uri> ports: - containerPort: 80 --- apiVersion: apps/v1 kind: Deployment metadata: name: rest labels: app: rest spec: replicas: 1 selector: matchLabels: app: rest template: metadata: labels: app: rest spec: containers: - name: rest image: <your/rest/image/uri> ports: - containerPort: 5000 env: - name: OPENAI_API_BASE valueFrom: secretKeyRef: name: openai-secret key: OPENAI_API_BASE - name: OPENAI_API_KEY valueFrom: secretKeyRef: name: openai-secret key: OPENAI_API_KEY - name: OPENAI_API_VERSION valueFrom: secretKeyRef: name: openai-secret key: OPENAI_API_VERSION - name: OPENAI_CHAT_ENGINE valueFrom: secretKeyRef: name: openai-secret key: OPENAI_CHAT_ENGINE --- apiVersion: apps/v1 kind: Deployment metadata: name: grpc labels: app: grpc spec: replicas: 1 selector: matchLabels: app: grpc template: metadata: labels: app: grpc spec: containers: - name: grpc image: <your/grpc/image/uri> ports: - containerPort: 50051 env: - name: OPENAI_API_BASE valueFrom: secretKeyRef: name: openai-secret key: OPENAI_API_BASE - name: OPENAI_API_KEY valueFrom: secretKeyRef: name: openai-secret key: OPENAI_API_KEY - name: OPENAI_API_VERSION valueFrom: secretKeyRef: name: openai-secret key: OPENAI_API_VERSION - name: OPENAI_CHAT_ENGINE valueFrom: secretKeyRef: name: openai-secret key: OPENAI_CHAT_ENGINE --- apiVersion: apps/v1 kind: Deployment metadata: name: grpc-web-envoy spec: replicas: 1 selector: matchLabels: app: grpc-web-envoy template: metadata: labels: app: grpc-web-envoy spec: containers: - name: grpc-web-envoy image: <your/envoy/image/uri> ports: - containerPort: 9000 volumeMounts: - name: envoy-config mountPath: /etc/envoy volumes: - name: envoy-config configMap: name: envoy-configservice.yaml
apiVersion: v1 kind: Service metadata: name: frontend-service spec: selector: app: frontend ports: - protocol: TCP port: 80 targetPort: 80 type: LoadBalancer --- apiVersion: v1 kind: Service metadata: name: rest-service spec: selector: app: rest ports: - protocol: TCP port: 5000 targetPort: 5000 --- apiVersion: v1 kind: Service metadata: name: grpc-service spec: selector: app: grpc ports: - protocol: TCP port: 50051 targetPort: 50051 --- apiVersion: v1 kind: Service metadata: name: envoy-service spec: selector: app: grpc-web-envoy ports: - protocol: TCP port: 9000 targetPort: 9000 -
まずはsecretの設定を行います。必要になるOPENAI_SECRET_KEYなどを登録していきます。localに以下の形式の.envファイルを用意し、secretを登録していきます。
# .env OPENAI_API_VERSION=xxxxx OPENAI_API_BASE=xxxxx OPENAI_API_KEY=xxxxx OPENAI_CHAT_ENGINE=xxxxxkubectl create secret generic --save-config openai-secret --from-env-file .env -
Artifact Registryの登録をします。それぞれのコンテナで同様の処理をしてください。
gcloud auth configure-docker asia-northeast1-docker.pkg.dev docker build -t $(ARTIFACT_REPOSITORY)/$(PROJECT_ID)/$(REPOSITORY_NAME)/$(API_IMAGE_NAME):$(SHORT_SHA) -f $(DOCKERFILE_REPOSITORY)/$(DOCKERFILE_API) . docker push $(ARTIFACT_REPOSITORY)/$(PROJECT_ID)/$(REPOSITORY_NAME)/$(API_IMAGE_NAME):$(SHORT_SHA) -
configMapを登録します。
kubectl create configmap envoy-config --from-file=envoy.yaml=envoy/envoy.yaml -
GKEにデプロイしていきます。
kubectl apply -f k8s/deployment.yaml kubectl apply -f k8s/service.yaml kubectl apply -f k8s/ingress.yaml
これで、デプロイは完了です。以下のコマンドを入力し、frontend-serviceのEXTERNAL-IPからブラウザで確認できます。
kubectl get services
結果

画面は稚拙ですが、4パターンの実装をすることができました。(fpsの問題で分かりにくいかもです🙇)
また、ブラウザからpythonのgRPCサーバにリクエストを投げる際、grpc-webやconnect が必要になります。また、grpc-webの場合、リバースプロキシとして動作するenvoyなどが必要になるため、注意してください。
※ 現在の実装では以前の会話履歴や、コンテキストを考慮できていないので、この辺りも充実させていきたいです。また、どこからでも&誰でもアクセスできるので、セキュリティ面も充実させていきたいです。
Discussion