Argo EventsとArgo Workflowsを使った機械学習パイプラインをローカル環境で動かす
ローカルの開発環境で、GCSへのデータアップロードをトリガーにArgo Workflowsで動く機械学習パイプラインを構築しました。
今回は本番環境にGKEが構築されていることを前提に、できる限りローカルでの実装をそのままGKEに乗せれる構成にするためにKustomizeを用いて構築しました。
GitHub: https://github.com/hosimesi/code-for-techblogs/tree/main/local_argo_events_argo_workflows
システム構成図
直接GCSのイベント検知はできないため、以下のようにGCS -> Pubsub -> Argo Events -> Argo Workflowsで実行します。
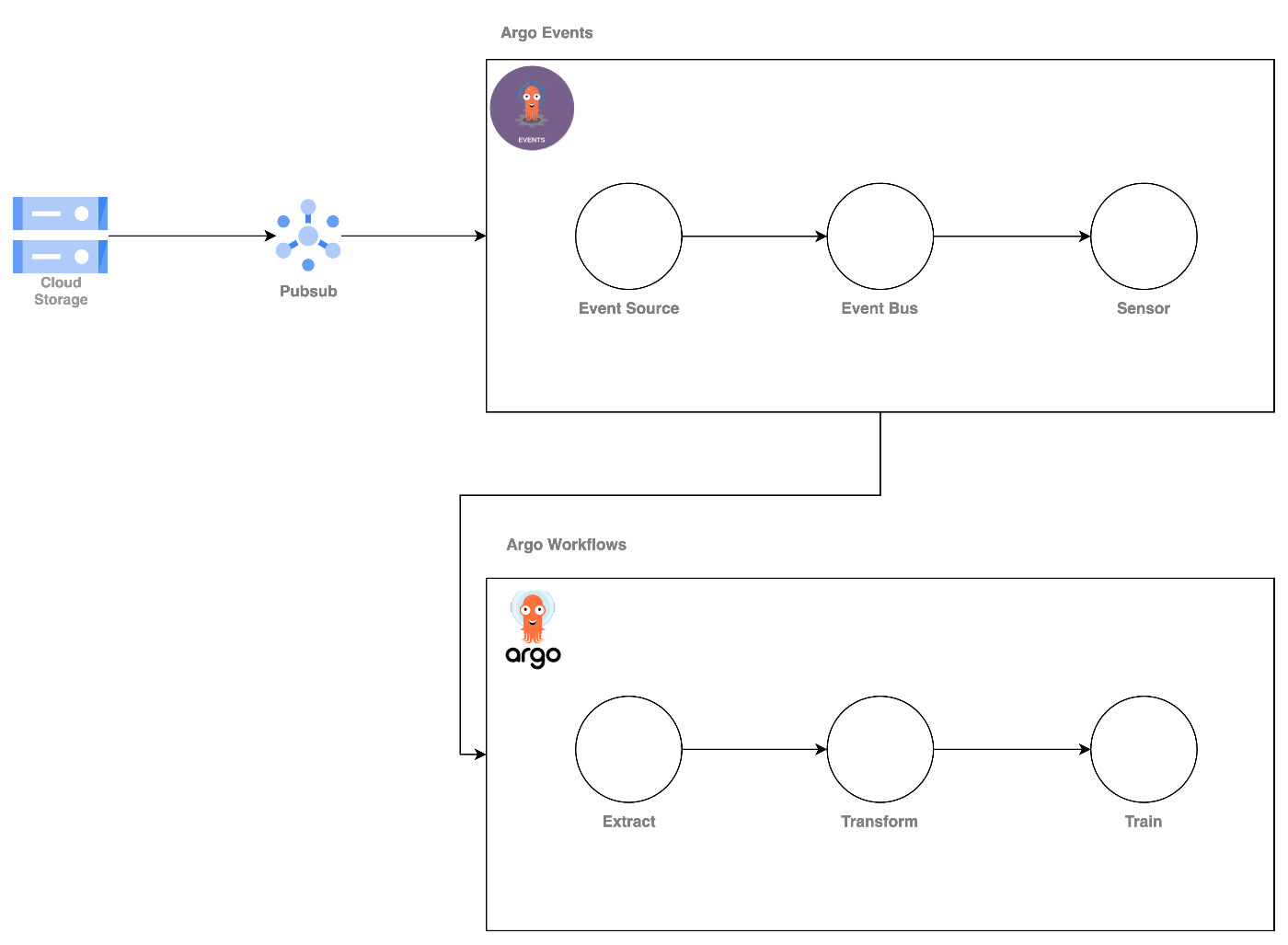
概要
ローカルでKubernetesを動かしたい場合とGKEなどのマネージドなKubernetesを動かしたい場合、環境差分が少し問題になります。(Service Accountベースの権限の付与や、Dockerからのイメージ取得時のシークレットの問題など)
その度にほとんど同じようなyamlファイルを書いてもいいですが、差分のみを記載できるKustomizeが便利です。
また、何かしらのイベントをトリガーにワークフローをキックしたい場合などはあると思います。(GCSに新規のデータが追加された際にそのデータを使ってモデルを再学習するなど)
今回はそのような要件を達成するため、Argo Eventsでイベント検知をし、Argo Workflowsでモデルを学習するような構成をローカルの開発環境で作成してみました。
GCSやサービスアカウントはGCP上にリソースをあらかじめ作成し、それを用いることにしました。
ディレクトリ構成
ワークフロー関連のディレクトリ構成は以下のようになっています。
.
├── argo-infra
│ ├── argo-events
│ │ ├── base
│ │ │ ├── install.yaml
│ │ │ ├── kustomization.yaml
│ │ │ └── namespace.yaml
│ │ └── overlays
│ │ └── local
│ │ └── kustomization.yaml
│ ├── argo-workflows
│ │ ├── base
│ │ │ ├── install.yaml
│ │ │ ├── kustomization.yaml
│ │ │ └── namespace.yaml
│ │ └── overlays
│ │ └── local
│ │ ├── deployment.yaml
│ │ └── kustomization.yaml
│ └── event-bus
│ ├── base
│ │ ├── install.yaml
│ │ └── kustomization.yaml
│ └── overlays
│ └── local
│ └── kustomization.yaml
└── workflows
├── base
│ ├── argo-events
│ │ ├── event-source.yaml
│ │ └── sensor.yaml
│ ├── binding.yaml
│ ├── kustomization.yaml
│ ├── role.yaml
│ └── serviceaccount.yaml
└── overlays
└── local
├── argo-events
│ └── event-source.yaml
├── argo-workflows
│ ├── extract.yaml
│ ├── train.yaml
│ ├── transform.yaml
│ └── workflow.yaml
├── kustomization.yaml
└── run-workflow.yaml
事前準備
コード上でFIXMEで書いてある部分は自身の環境に合わせて変更してください。
ローカルでのKubernetes
ローカルでKubernetesを動かすには色々選択肢はあります(kind, Minikube, Docker..)が、今回はkindを使用することにします。
まず、構築に必要なライブラリをインストールしていきます
- kindをインストールします
$ brew install kind
- kustomizeをインストールします
$ brew install kustomize
GCPリソースの作成
terraformを使用し、リソースを作成していきます。variable用のfileを作成します。
$ vim local_argo_events_argo_workflows/infra/local.tfvars
そして、ファイルの中身は自身の環境に合わせて以下のように設定します。
project = your-gcp-project-id
region = your-region
ここまで設定できたら、リソース作成していきます。
$ terraform init
$ terraform plan -var-file=local.tfvars
$ terraform apply -var-file=local.tfvars
エラーが出なければOKです。
kubernetes clusterの作成
kindでクラスターを作成していきます。
$ kind create cluster
nodeが動いていれば成功です。
$ kind get nodes

Argo関連のinstall
クラスターにArgo WorkflowsやArgo Events関連のリソースをインストールしていきます。Kustomizeでは、baseとoverlaysに分かれており、baseでは共通リソース、overlaysにはその環境特有のpatchを当てます。
Argo Eventsなどのインストールはhttps://raw.githubusercontent.com/argoproj/argo-events/stable/manifests/install.yamlなどから直接可能ですが、ここでは同一ファイルをローカルにinstall.yamlという名前で保存し、そこからインストールしています。
Argo Workflowsのbaseのyamlは以下のようになっています。
# argo-workflows/base/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- install.yaml
- namespace.yaml
Argo Workflowsのoverlayのyamlは以下のようになっています。
# argo-workflows/overlays/local/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
labels:
- includeSelectors: true
pairs:
env: local
resources:
- ../../base
patches:
- path: deployment.yaml
リソースのインストールをしていきます。
- Argo Eventsのインストール
$ kubectl kustomize ./argo-infra/argo-events/overlays/local | kubectl apply -f - - Argo Workflowsのインストール
$ kubectl kustomize ./argo-infra/argo-workflows/overlays/local | kubectl apply -f - - Argo Eventsのインストール
$ kubectl kustomize ./argo-infra/event-bus/overlays/local | kubectl apply -f
上記を実行すると、namespace: argoにArgo Workflows用のリソースが作成でき、namespace: argo-eventsにArgo Events用のリソースが作成できます。リソースが作成できていればOKです。


以下の通り、ポートフォワードするとUIを確認できます。
.PHONY: port-forward
port-forward:
kubectl -n $(ARGO_WORKFLOW_NAMESPACE) port-forward deployment/argo-server 2746:2746
secretの登録
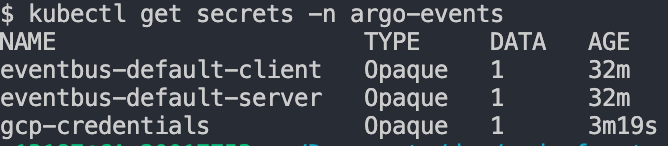
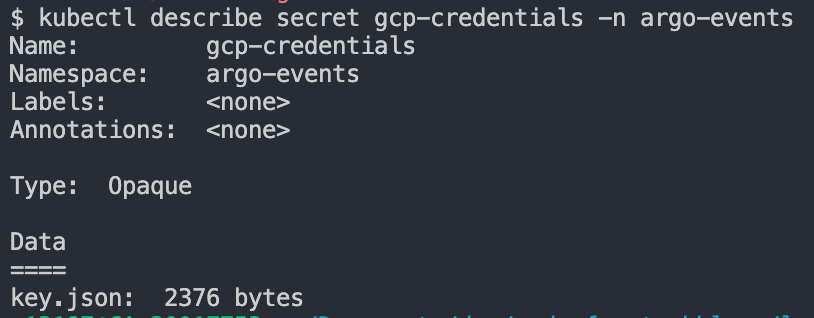
今のままだとローカルのワークフローからGCPリソースへのアクセス権限がありません。本番のGKE環境ではサービスアカウントを紐づけることでアクセスできるようになりますが、ローカルではサービスアカウントのkeyを作成して、KubernetesのSecretに登録してそれを用いてアクセスできるようにします。
TerraformですでにArgo Workflows用のService AccountとArgo Events用のService Accountを作成済みなので、それらのkeyを作成し、Secretに登録していきます。Makefileを使うと以下で作成できます。
# ARGO_WORKFLOWS_NAMESPACE=argo
# ARGO_EVENTS_NAMESPACE=argo-events
.PHONY: create-secret
create-secret:
gcloud iam service-accounts keys create --iam-account $(ARGO_WORKFLOWS_SERVICE_ACCOUNT_EMAIL) $(ARGO_WORKFLOWS_KEY)
gcloud iam service-accounts keys create --iam-account $(ARGO_EVENTS_SERVICE_ACCOUNT_EMAIL) $(ARGO_EVENTS_KEY)
kubectl create secret docker-registry $(DOCKER_CREDENTIAL_NAME) \
--docker-server=https://$(REGION)-docker.pkg.dev \
--docker-username=_json_key \
--docker-password="`cat $(ARGO_WORKFLOWS_KEY)`" \
--docker-email=<your-mail-address> \
--namespace=$(ARGO_WORKFLOW_NAMESPACE)
kubectl create secret generic $(GCP_CREDENTIAL_NAME) --from-file=key.json=$(ARGO_WORKFLOWS_KEY) --namespace=$(ARGO_WORKFLOWS_NAMESPACE)
kubectl create secret generic $(GCP_CREDENTIAL_NAME) --from-file=key.json=$(ARGO_EVENTS_KEY) --namespace=$(ARGO_EVENTS_NAMESPACE)
Secretが作成され、Sizeが0でなければ大丈夫です。
ワークフロー作成
学習ワークフローの構成
今回は簡単な機械学習パイプラインを作成します。ワークフローのステップは以下のようにします。
- extract step
- オリジナルデータをGCSから取得し、学習に使うデータを抽出してGCSに保存する。
- transform step
- 抽出したデータに対して、前処理を施してGCSに保存する。
- train step
- 前処理済みのデータを用いてモデルを学習し、学習済みモデルをGCSに保存する。
サンプルデータとしてKaggleのタイタニックデータを使いたいと思います。
データに対して前処理した後、ロジスティック回帰とLightGBMの2つのモデルを並列に学習したいと思います。
学習には以下の特徴量を使用しました。
CATEGORICAL_FEATURES = ["Sex", "Embarked", "Pclass"]
NUMERICAL_FEATURES = ["Age", "Fare", "SibSp", "Parch"]
Extract Step
Extract Stepでは元データから使用する特徴量のみ抽出し、train, valid, testに分割してそれぞれのcsvファイルを保存しています。
import argparse
import json
import logging
from pathlib import Path
import pandas as pd
from sklearn.model_selection import train_test_split
from src.schemas.schema import ExtractConfig, ExtractedConfig
from src.utils.consts import (
ARGO_GCS_BUCKET_NAME,
ARTIFACTS_DIR,
EXTRACTED_TEST_FILE_NAME,
EXTRACTED_TRAIN_FILE_NAME,
EXTRACTED_VALID_FILE_NAME,
ORIGINAL_FILE_NAME,
TRAIN_GCS_BUCKET_NAME,
)
from src.utils.gcp_controller import download_from_gcs, upload_to_gcs
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
def load_options() -> argparse.Namespace:
"""Parse argument options."""
description = """
This script is extract step.
"""
parser = argparse.ArgumentParser(description=description)
parser.add_argument(
"-c",
"--config",
type=ExtractConfig.parse_raw,
help="""
Configurations for extract step.
""",
)
return parser.parse_args()
def main() -> None:
logger.info("Extract step started.")
args = load_options()
config = args.config
logger.info(f"config: {config}")
gcs_path = config.name
# Load the data
download_from_gcs(ARGO_GCS_BUCKET_NAME, gcs_path, str(Path(ARTIFACTS_DIR, ORIGINAL_FILE_NAME)))
# Read the data
df = pd.read_csv(str(Path(ARTIFACTS_DIR, ORIGINAL_FILE_NAME)))
# Extract data
X = df.drop(["Survived", "PassengerId", "Cabin", "Name", "Ticket"], axis=1)
y = df["Survived"]
# divide the data into training, validation, and test data
X_train, X_valid_test, y_train, y_valid_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# divide the training data into training and validation data
X_valid, X_test, y_valid, y_test = train_test_split(
X_valid_test, y_valid_test, test_size=0.5, random_state=42, stratify=y_valid_test
)
X_train["target"] = y_train
extracted_train_df = X_train.copy()
logger.info(f"Extracted train shape: {extracted_train_df.shape}")
X_valid["target"] = y_valid
extracted_valid_df = X_valid.copy()
logger.info(f"Extracted valid shape: {extracted_valid_df.shape}")
X_test["target"] = y_test
extracted_test_df = X_test.copy()
logger.info(f"Extracted test shape: {extracted_test_df.shape}")
BASE_BLOB = "train_workflows"
# Save the data and upload to GCS
for extracted_df, file_name in zip(
[extracted_train_df, extracted_valid_df, extracted_test_df],
[EXTRACTED_TRAIN_FILE_NAME, EXTRACTED_VALID_FILE_NAME, EXTRACTED_TEST_FILE_NAME], strict=False,
):
extracted_df.to_csv(str(Path(ARTIFACTS_DIR, file_name)), index=False)
upload_to_gcs(TRAIN_GCS_BUCKET_NAME, str(Path(BASE_BLOB, file_name)), str(Path(ARTIFACTS_DIR, file_name)))
logger.info(f"Uploaded {file_name} to GCS.")
# Save the config
extracted_config = ExtractedConfig(
train_gcs_path=str(Path(BASE_BLOB, EXTRACTED_TRAIN_FILE_NAME)),
valid_gcs_path=str(Path(BASE_BLOB, EXTRACTED_VALID_FILE_NAME)),
test_gcs_path=str(Path(BASE_BLOB, EXTRACTED_TEST_FILE_NAME)),
)
# save artifact
with open(str(Path(ARTIFACTS_DIR, "extracted_config.json")), "w") as f:
json.dump(extracted_config.model_dump(), f, indent=4)
logger.info("Extract step task fineshed.")
if __name__ == "__main__":
main()
Trasform Step
Transform Stepでは欠損値補完や前処理をしています。カテゴリカル変数にはOrdinal Encoderを施し、数値データはStandard Scalerで標準化しています。
import argparse
import json
import logging
from pathlib import Path
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import FunctionTransformer, OrdinalEncoder, StandardScaler
from src.schemas.schema import ExtractedConfig, TransformedConfig
from src.utils.consts import (
ARTIFACTS_DIR,
CATEGORICAL_FEATURES,
EXTRACTED_TEST_FILE_NAME,
EXTRACTED_TRAIN_FILE_NAME,
EXTRACTED_VALID_FILE_NAME,
NUMERICAL_FEATURES,
TRAIN_GCS_BUCKET_NAME,
TRANSFORMED_TEST_FILE_NAME,
TRANSFORMED_TRAIN_FILE_NAME,
TRANSFORMED_VALID_FILE_NAME,
)
from src.utils.gcp_controller import download_from_gcs, upload_to_gcs
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
def load_options() -> argparse.Namespace:
"""Parse argument options."""
description = """
This script is transform step.
"""
parser = argparse.ArgumentParser(description=description)
parser.add_argument(
"-c",
"--config",
type=ExtractedConfig.parse_raw,
help="""
Configurations for transform step.
""",
)
return parser.parse_args()
def main() -> None:
logger.info("Transform step started.")
args = load_options()
config = args.config
logger.info(f"config: {config}")
# Load the data
download_from_gcs(TRAIN_GCS_BUCKET_NAME, config.train_gcs_path, str(Path(ARTIFACTS_DIR, EXTRACTED_TRAIN_FILE_NAME)))
download_from_gcs(TRAIN_GCS_BUCKET_NAME, config.valid_gcs_path, str(Path(ARTIFACTS_DIR, EXTRACTED_VALID_FILE_NAME)))
download_from_gcs(TRAIN_GCS_BUCKET_NAME, config.test_gcs_path, str(Path(ARTIFACTS_DIR, EXTRACTED_TEST_FILE_NAME)))
# Preprocessing for categorical columns
categorical_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")), # fill missing values with most frequent ones
("to_string", FunctionTransformer(lambda x: x.astype(str))), # convert to string
(
"encoder",
OrdinalEncoder(
handle_unknown="use_encoded_value",
unknown_value=-1,
),
), # encode to numerical values
]
)
# Preprocessing for numerical columns
numeric_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")), # fill missing values with median
("scaler", StandardScaler()), # standard scaling
]
)
# Define preprocessing
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, NUMERICAL_FEATURES),
("cat", categorical_transformer, CATEGORICAL_FEATURES),
]
)
BASE_BLOB = Path(config.train_gcs_path).parent
for extracted_file_name, transformed_file_name in zip(
[EXTRACTED_TRAIN_FILE_NAME, EXTRACTED_VALID_FILE_NAME, EXTRACTED_TEST_FILE_NAME],
[TRANSFORMED_TRAIN_FILE_NAME, TRANSFORMED_VALID_FILE_NAME, TRANSFORMED_TEST_FILE_NAME], strict=False,
):
extracted_df = pd.read_csv(str(Path(ARTIFACTS_DIR, extracted_file_name)))
logger.info(f"Loaded {extracted_file_name} shape: {extracted_df.shape}")
extracted_features = extracted_df.drop("target", axis=1)
extracted_target = extracted_df["target"]
if extracted_file_name == EXTRACTED_TRAIN_FILE_NAME:
transformed = preprocessor.fit_transform(extracted_features)
else:
transformed = preprocessor.transform(extracted_features)
transformed_df = pd.DataFrame(transformed, columns=extracted_features.columns)
transformed_df["target"] = extracted_target.copy()
transformed_df.to_csv(str(Path(ARTIFACTS_DIR, transformed_file_name)), index=False)
upload_to_gcs(
TRAIN_GCS_BUCKET_NAME, str(Path(BASE_BLOB, transformed_file_name)), str(Path(ARTIFACTS_DIR, transformed_file_name))
)
logger.info(f"Uploaded {transformed_file_name} to GCS.")
# Save the config
transformed_configs = []
for target_model_name in ("lr", "lgbm"):
transformed_configs.append(
TransformedConfig(
train_gcs_path=str(Path(BASE_BLOB, TRANSFORMED_TRAIN_FILE_NAME)),
valid_gcs_path=str(Path(BASE_BLOB, TRANSFORMED_VALID_FILE_NAME)),
test_gcs_path=str(Path(BASE_BLOB, TRANSFORMED_TEST_FILE_NAME)),
target_model_name=target_model_name,
).model_dump()
)
# save artifact
with open(str(Path(ARTIFACTS_DIR, "transformed_configs.json")), "w") as f:
json.dump(transformed_configs, f, indent=4)
logger.info("Transform step task fineshed.")
if __name__ == "__main__":
main()
Train Step
Train Stepでは実際にモデル(ロジスティック回帰とLightGBM)を並列で学習しています。また、学習済みモデルの精度評価も実施しています。(本来はステップを分けても良いと思います。)
import argparse
import logging
from pathlib import Path
import pandas as pd
from src.models.model import get_model_candidates
from src.schemas.schema import TransformedConfig
from src.services.evaluate import evaluate_model
from src.utils.consts import (
ARTIFACTS_DIR,
TRAIN_GCS_BUCKET_NAME,
TRANSFORMED_TEST_FILE_NAME,
TRANSFORMED_TRAIN_FILE_NAME,
TRANSFORMED_VALID_FILE_NAME,
)
from src.utils.gcp_controller import download_from_gcs, upload_to_gcs
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
def load_options() -> argparse.Namespace:
"""Parse argument options."""
description = """
This script is train step.
"""
parser = argparse.ArgumentParser(description=description)
parser.add_argument(
"-c",
"--config",
type=TransformedConfig.parse_raw,
help="""
Configurations for train step.
""",
)
return parser.parse_args()
def main() -> None:
logger.info("Train step started.")
args = load_options()
config = args.config
logger.info(f"config: {config}")
# Load the data
download_from_gcs(TRAIN_GCS_BUCKET_NAME, config.train_gcs_path, str(Path(ARTIFACTS_DIR, TRANSFORMED_TRAIN_FILE_NAME)))
download_from_gcs(TRAIN_GCS_BUCKET_NAME, config.valid_gcs_path, str(Path(ARTIFACTS_DIR, TRANSFORMED_VALID_FILE_NAME)))
download_from_gcs(TRAIN_GCS_BUCKET_NAME, config.test_gcs_path, str(Path(ARTIFACTS_DIR, TRANSFORMED_TEST_FILE_NAME)))
# Extract data
transformed_train_df = pd.read_csv(str(Path(ARTIFACTS_DIR, TRANSFORMED_TRAIN_FILE_NAME)))
transformed_valid_df = pd.read_csv(str(Path(ARTIFACTS_DIR, TRANSFORMED_VALID_FILE_NAME)))
transformed_test_df = pd.read_csv(str(Path(ARTIFACTS_DIR, TRANSFORMED_TEST_FILE_NAME)))
# Train the model
model = get_model_candidates(config.target_model_name)()
is_hyperparameter_tuning = False
if is_hyperparameter_tuning:
model._fit_with_valid(
transformed_train_df.drop("target", axis=1),
transformed_train_df["target"],
transformed_valid_df.drop("target", axis=1),
transformed_valid_df["target"],
)
else:
model.fit(transformed_train_df.drop("target", axis=1), transformed_train_df["target"])
y_pred = model.predict(transformed_test_df.drop("target", axis=1))
y_proba = model.predict_proba(transformed_test_df.drop("target", axis=1))
# Metrics
logloss, accuracy, precision, recall, auc = evaluate_model(y_pred, y_proba, transformed_test_df["target"])
logger.info(f"Validation logloss: {logloss}, accuracy: {accuracy}, precision: {precision}, recall: {recall}, auc: {auc}")
BASE_BLOB = Path(config.train_gcs_path).parent
# Save the model
model.save_model(str(Path(ARTIFACTS_DIR, f"{config.target_model_name}.pkl")))
upload_to_gcs(
TRAIN_GCS_BUCKET_NAME,
str(Path(BASE_BLOB, f"{config.target_model_name}.pkl")),
str(Path(ARTIFACTS_DIR, f"{config.target_model_name}.pkl")),
)
logger.info("Train step task fineshed.")
if __name__ == "__main__":
main()
ワークフローのデプロイ
まずはイメージをビルドし、Artifact Registryにプッシュします。argo-workflowsというレポジトリをすでに作成しているので、それを使用します。
.PHONY: build
build:
gcloud auth configure-docker asia-northeast1-docker.pkg.dev
docker buildx build --platform=linux/amd64 --target local -t $(ARTIFACT_REPOSITORY)/$(PROJECT_ID)/$(REPOSITORY_NAME)/$(IMAGE_NAME):$(SHORT_SHA) -f $(DOCKERFILE_REPOSITORY)/$(DOCKERFILE) .
docker tag $(ARTIFACT_REPOSITORY)/$(PROJECT_ID)/$(REPOSITORY_NAME)/$(IMAGE_NAME):$(SHORT_SHA) $(ARTIFACT_REPOSITORY)/$(PROJECT_ID)/$(REPOSITORY_NAME)/$(IMAGE_NAME):latest
.PHONY: push
push:
gcloud auth configure-docker asia-northeast1-docker.pkg.dev
docker push $(ARTIFACT_REPOSITORY)/$(PROJECT_ID)/$(REPOSITORY_NAME)/$(IMAGE_NAME):$(SHORT_SHA)
docker push $(ARTIFACT_REPOSITORY)/$(PROJECT_ID)/$(REPOSITORY_NAME)/$(IMAGE_NAME):latest
次に、Argo WorkflowsにWorkflowTemplateを登録していきます。
.PHONY: deploy
deploy:
kubectl kustomize ./workflows/overlays/local | kubectl apply -f -
今のままだとCloud StorageにアップロードされてもPub/Subに通知されないので、通知の設定をします。すでにargo-workflows-topicというトピックとargo-workflows-bucketというバケットが作成されているはずなので、それらを紐付けます。
.PHONY: notify
notify:
gsutil notification create -f json -t argo-workflows-topic gs://argo-workflows-bucket
# output
# Created notification config projects/_/buckets/argo-workflows-bucket/notificationConfigs/1
実行
手元からGCSにデータをアップロードしてみます。
$ gsutil cp original.csv gs://argo-workflows-bucket/test/original.csv
すると、以下の形式でargo-workflows-topicというPub/Subトピックにメッセージが送られます。
{
"kind":"storage#object",
"id":"test",
"selfLink":"test",
"name":"test/original.csv",
"bucket":"argo-workflows-bucket",
"generation":"1711281065202925",
"metageneration":"1",
"contentType":"text/csv",
"timeCreated":"2024-03-24T11:51:05.208Z",
"updated":"2024-03-24T11:51:05.208Z",
"storageClass":"STANDARD",
"timeStorageClassUpdated":"2024-03-24T11:51:05.208Z",
"size":"61194",
"md5Hash":"test",
"mediaLink":"test",
"contentLanguage":"en",
"crc32c":"test",
"etag":"etag"
}
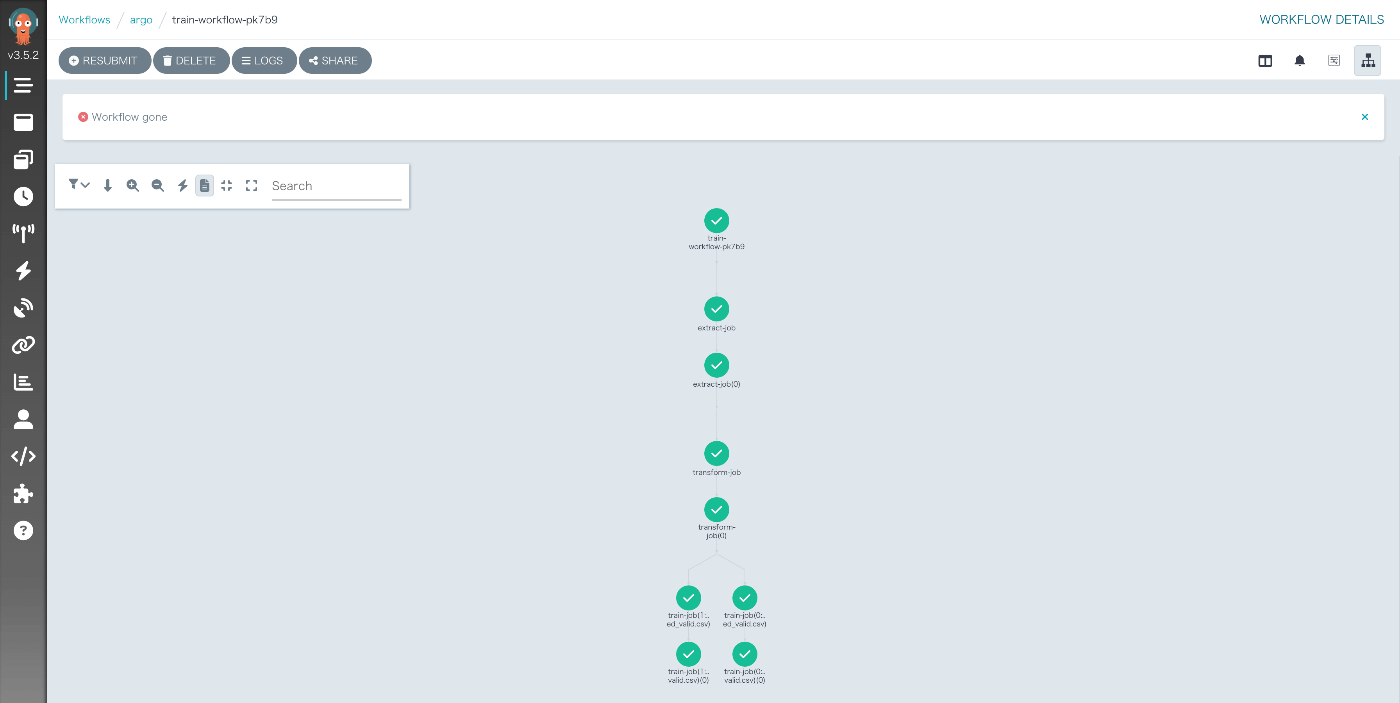
そして、Argo WorkflowsのUIに行くと、ワークフローが実行されていることが確認できます。
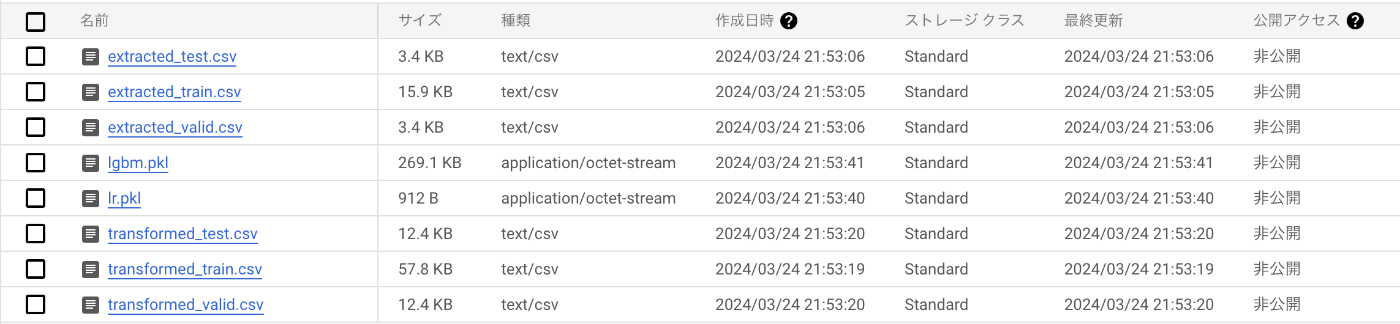
GCS上にも中間ファイルが作成されています。
最後に
ローカルでArgo EventsとArgo Workflowsを使って簡単な機械学習パイプラインを作成しました。実運用するにはまだまだやることはたくさんありますが、ローカルで動かすだけであればサクッと構築できそうです。
Discussion