🦅
【python】雑に始める並列処理(multiprocessing)
雑なメモ書きです(後でもう少しまとめます)
1. はじめに
- multiprocessingは、pythonにて並列処理を実装するための標準ライブラリ
- threadingやasyncと比較して、高速化の恩恵が大きい
- 実行する関数自体が独立であり、内部で並列処理が行われていないかは、注意しておく必要がある
multiprocessing --- プロセスベースの並列処理
multiprocess, threading, asyncの違い・使い分けについては、下記の記事が分かりやすいです。
1.1 PCのスペックなど
- OS : Windows11 Home

2. 実際に動かしてみる
- Python 3.12.5
2.1 基本のパターン
以下のパターン、超基本
- 引数:1変数
- 返値:1変数
プログラム例
from multiprocessing import Pool, cpu_count
def function_A(x):
"""
1つの引数 で 1つの変数 を返す場合
"""
print("function_A : ", x)
return x**2
if __name__ == "__main__":
"""
標準ライブラリmultiprocessingを使用して、並列化を試すサンプル
"""
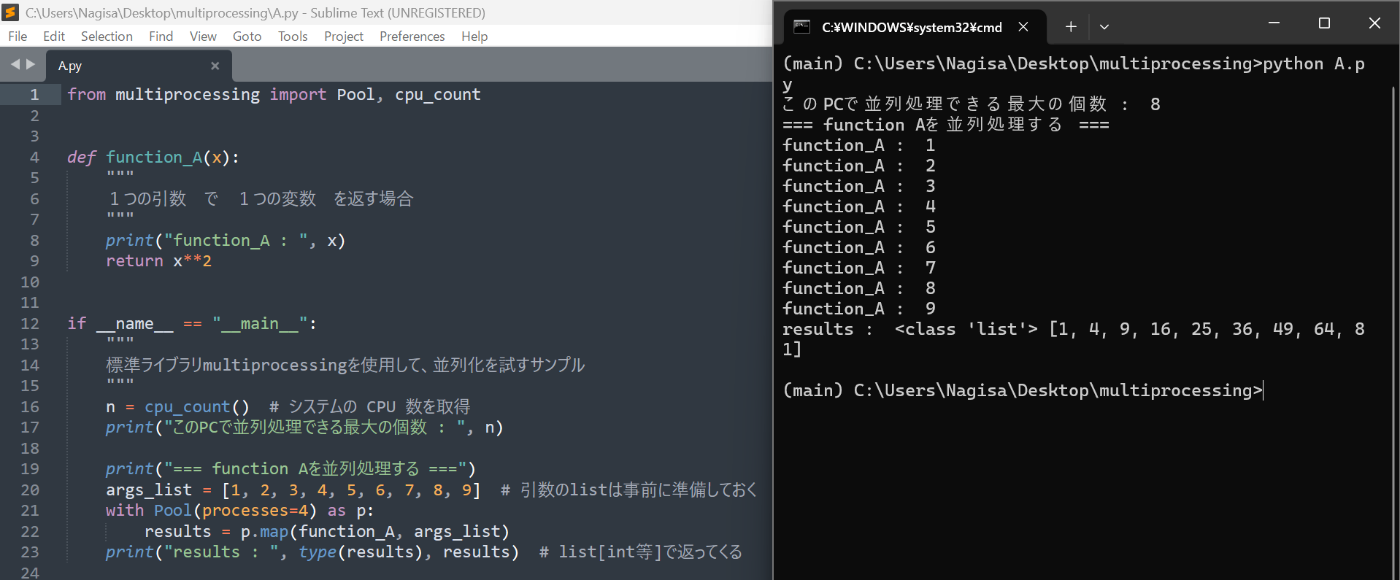
n = cpu_count() # システムの CPU 数を取得
print("このPCで並列処理できる最大の個数 : ", n)
print("=== function Aを並列処理する ===")
args_list = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 引数のlistは事前に準備しておく
with Pool(processes=4) as p:
results = p.map(function_A, args_list)
print("results : ", type(results), results) # list[int等]で返ってくる
出力
2.2 返値が複数ある関数の場合
以下のパターン、これもよくある
- 引数:1変数
- 返値:複数の変数
プログラム例
from multiprocessing import Pool, cpu_count
def function_B(x):
"""
1つの引数 で 複数の変数 を返す場合
"""
print("function_B : ", x)
return x**2, x**3
if __name__ == "__main__":
"""
標準ライブラリmultiprocessingを使用して、並列化を試すサンプル
"""
n = cpu_count() # システムの CPU 数を取得
print("このPCで並列処理できる最大の個数 : ", n)
print("=== function Bを並列処理する ===")
args_list = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 引数のlistは事前に準備しておく
with Pool(n) as p:
results = p.map(function_B, args_list)
print("results : ", type(results), results) # list[tuple]で返ってくる
出力
p.mapの返り値であるlistの中身(要素)が、tupleになります

2.2 複数の引数を渡す場合(tuple)
この場合、p.statmapを使ってもよいが、statmapの存在を知らない人だと挙動が理解しずらい
チームのレベルに合わせて、可読性重視で愚直に実装したほうが良い場合もあるかと思います
プログラム例
from multiprocessing import Pool, cpu_count
def function_C(tuple_):
"""
複数の引数を与えたい場合(tupleで1変数にする)
"""
print("function_C : ", tuple_)
x, y, z = tuple_ # tupeの要素を分解する
return x+y+z
if __name__ == "__main__":
"""
標準ライブラリmultiprocessingを使用して、並列化を試すサンプル
"""
n = cpu_count() # システムの CPU 数を取得
print("このPCで並列処理できる最大の個数 : ", n)
print("=== function Cを並列処理する ===")
args_tuple_list = [ (x, y, z) for x, y, z in zip(range(10), range(1, 11), range(2, 21, 2))] # listの要素をtupleにする
with Pool(n) as p:
results = p.map(function_C, args_tuple_list) # tuple自体は1変数扱いなので渡せる
print("results : ", type(results), results)
出力

2.4 複数の引数を渡す場合(dict)
プログラム例
from multiprocessing import Pool, cpu_count
def function_D(dict_):
"""
複数の引数を与えたい場合(dictで1変数にする)
"""
print("function_D : ", dict_)
x = dict_["x"]
y = dict_["y"]
z = dict_["z"]
return x*y*z
if __name__ == "__main__":
"""
標準ライブラリmultiprocessingを使用して、並列化を試すサンプル
"""
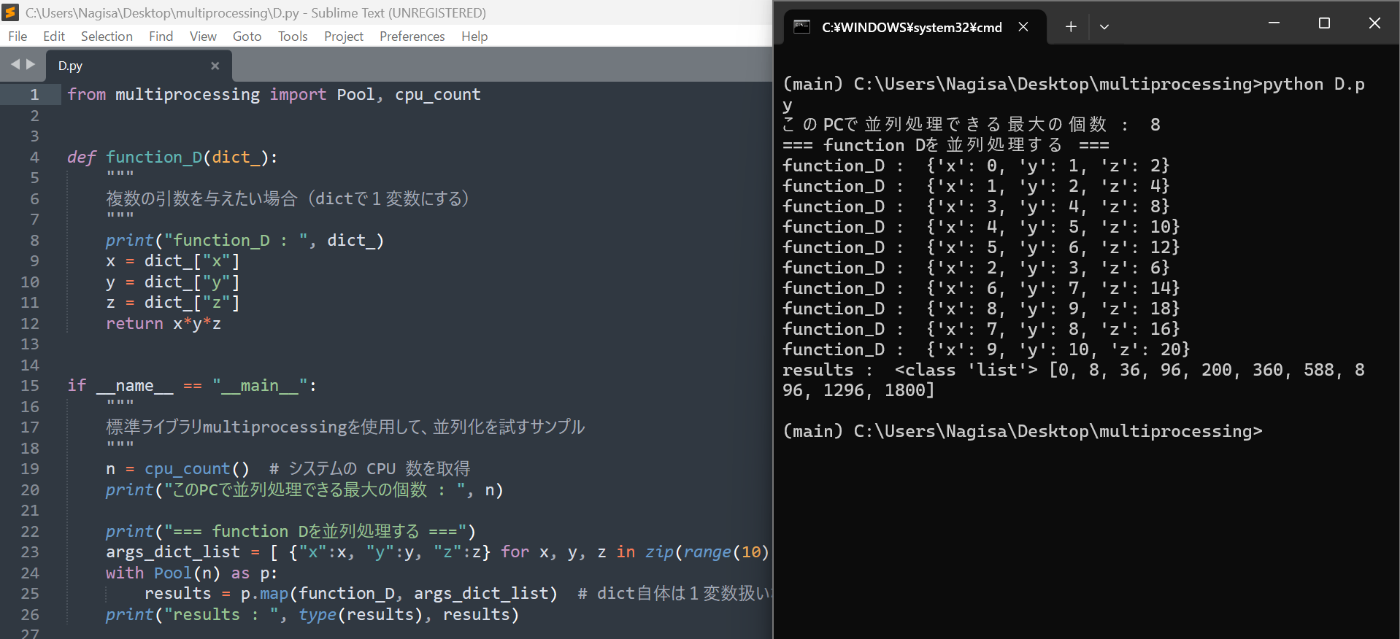
n = cpu_count() # システムの CPU 数を取得
print("このPCで並列処理できる最大の個数 : ", n)
print("=== function Dを並列処理する ===")
args_dict_list = [ {"x":x, "y":y, "z":z} for x, y, z in zip(range(10), range(1, 11), range(2, 21, 2))] # listの要素をdictにする
with Pool(n) as p:
results = p.map(function_D, args_dict_list) # dict自体は1変数扱いなので渡せる
print("results : ", type(results), results)
2.5 キーワード引数のある関数
他のライブラリの関数等を使う場合、wrapper関数を作って、wrapper関数経由で呼び出すとよいです
プログラム例
from multiprocessing import Pool, cpu_count
def function_E(a, b=0, c=2):
"""
キーワード引数が必要な場合(既存関数を使う)
"""
print("function_E : ", a, b, c)
return f"{a=}, {b=}, {c=}"
def wrapper_for_E(args):
"""
function_Eに与える引数を分割するラッパー
return function_E(a=args["a"], b=args["b"], c=args["c"])
とキーワード引数を明記したほうが、可読性は高いかも?
"""
return function_E(**args) # **argsで、dictのkeyを引数の変数名、valueを値として関数を実行できる
if __name__ == "__main__":
"""
標準ライブラリmultiprocessingを使用して、並列化を試すサンプル
"""
n = cpu_count() # システムの CPU 数を取得
print("このPCで並列処理できる最大の個数 : ", n)
print("=== function Eを並列処理する ===")
keyargs_dict_list = [ {"a":a, "b":b, "c":c} for a, b, c in zip(range(10), range(1, 11), range(2, 21, 2))] # listの要素をdictにする
with Pool(n) as p:
results = p.map(wrapper_for_E, keyargs_dict_list) # wrapper_for_Eを呼び出す
print("results : ", type(results), results)
# おまけ(statmap)
# print("=== (別実装)function Eを並列処理する ===")
# with Pool(n) as p:
# results = p.starmap(function_E, args_tuple_list) # starmapなら直接関数を実行できる
# print("results : ", type(results), results)
出力

3. (検証)具体事例での速度比較
せっかくなので、並列処理の事例を紹介しておきます
3.1 概要
- csvファイルのセンサデータ等から、特徴量を個別に計算する
- 各処理は独立である(他の処理に影響を与えない)
3.2 プログラム
逐次処理 と 並列処理 をそれぞれ行い、処理時間を計測し表示するプログラムを作成
依存ライブラリは以下の通り
- pandas : 2.3.0
- numpy : 2.3.0
長いので折り畳み
from multiprocessing import Pool, cpu_count
from pathlib import Path
from time import perf_counter
import numpy as np
import pandas as pd
def make_csv():
"""
適当なcsvファイルを作成する関数
"""
output_folder = Path('./input/')
output_folder.mkdir(exist_ok=True) # 出力先フォルダを作成
feature_name_list = ["A", "B", "C"] # DataFrameの列名を定義
size = (100000, len(feature_name_list)) # 生成する配列の大きさ
for i in range(100):
print(i)
df_tmp = pd.DataFrame(np.random.random(size),
columns=feature_name_list)
df_tmp.to_csv(output_folder/"{:04d}.csv".format(i))
def calc_features(csv_path):
"""
引数のcsvファイルを読み込んで、特徴量を計算する関数
"""
print(f"=== {csv_path} ===")
input_data = pd.read_csv(csv_path, index_col=0)
# 移動平均を計算
features = input_data.rolling(7).mean() # 直近7件で移動平均を計算
# print(features) # デバッグ用
# features.to_csv(path.stem+"_features.csv") # 保存
if __name__ == "__main__":
"""
実際の使用例
"""
# make_csv() # 初回のみ実行 617MBくらい生成されるので注意!
# 以下、本題
input_folder_path = Path('./input/')
args_list = [ p for p in input_folder_path.glob("*.csv")]
# 1.逐次処理
print("=== 1.逐次処理 ===")
start = perf_counter() # 開始時刻の取得
for path in args_list:
calc_features(path) # 通常通り
end = perf_counter() # 開始時刻の取得
single_elapsed_time = end - start # 処理時間を産出
# 2.並列処理
print("\n=== 2.並列処理 ===")
start = perf_counter() # 開始時刻の取得
with Pool(processes=cpu_count()) as p:
p.map(calc_features, args_list) # 並列処理
end = perf_counter() # 開始時刻の取得
parallel_elapsed_time = end - start # 処理時間を産出
# 結果を表示
print("1.逐次処理 : {}秒".format(round(single_elapsed_time, 4)))
print("2.並列処理 : {}秒".format(round(parallel_elapsed_time, 4)))
3.3 計測結果
毎回、多少処理時間が変わりますが、およそ3倍くらい高速になりました
- 逐次処理 : 15.4149秒
- 並列処理 : 5.3584秒
逐次処理
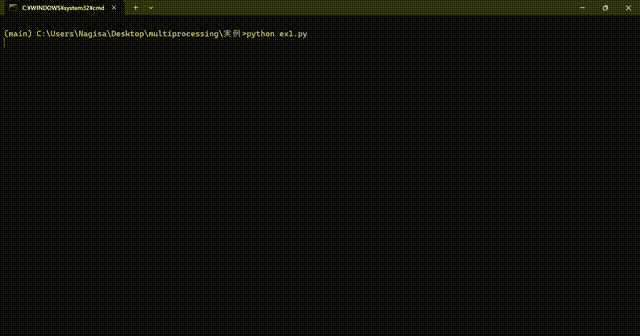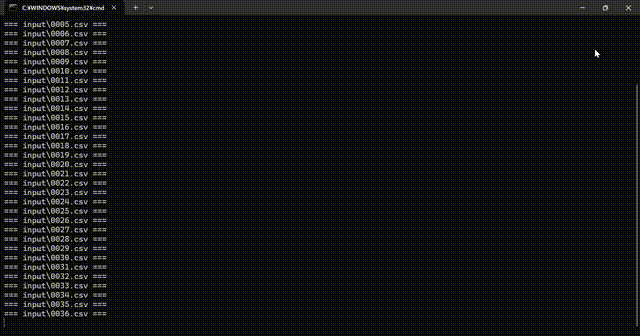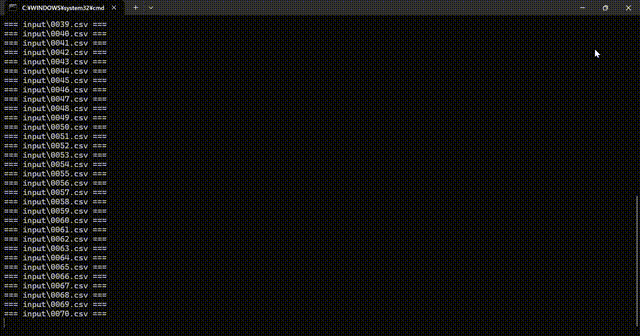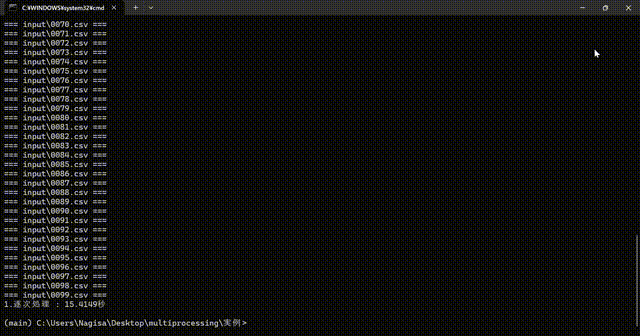
並列処理
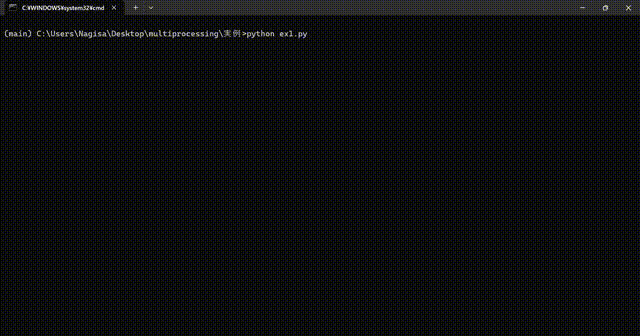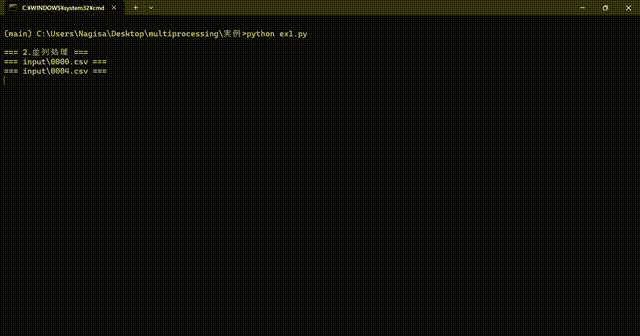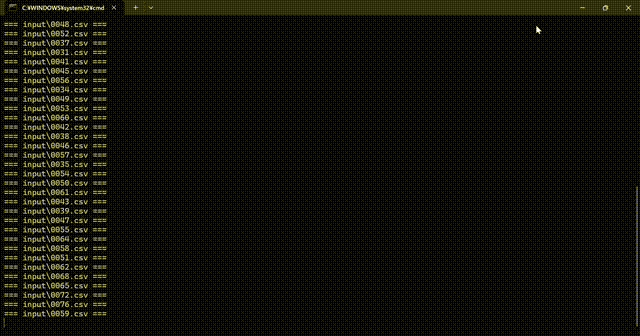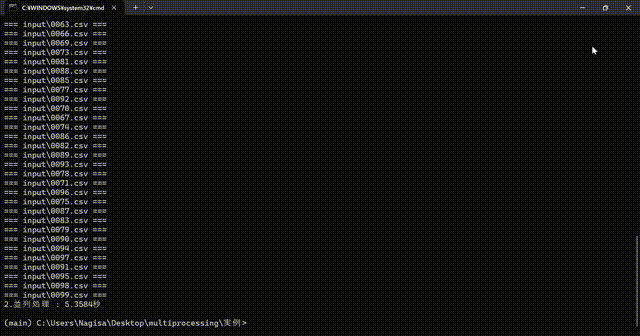
また、並列処理中は、CPUの使用率が100%に張り付きます
(これに快感&安心感を覚える人は、処理効率化の素質があると思います!!)

4. まとめ
- 「並列処理」と聞くと難しそうだが、pythonの場合3行くらいの変更でかなり高速化が見込める
- 機械学習の特徴量計算など、時間のかかる処理は並列化を前提に作成するとよい
- 外部APIからのレスポンス待ちなどはasync、ある程度リアルタイム性が必要で別々のタスクを行いたい場合はthreadingと使い分けをしよう
Discussion