🪶
【MLflow】よく使うサンプル(Sklearn)【Python】
0. 環境
- python : 3.13.5
- mlflow : 3.1.1
1. MLflowとは?
- MLflow(エムエルフロー)は、機械学習のライフサイクルを管理するためのオープンソース・プラットフォーム
- 機械学習プロジェクトを実験 → 再現 → デプロイ → 運用 まで一貫して扱えるようにする仕組みを提供している
以下の4つで構成されている
1. MLflow Tracking
- 実験管理ツール。
- 機械学習の実験(パラメータ、コード、環境、評価指標、成果物など)を記録・可視化。
- Web UIで「どの実験が一番精度が良かったか」などを簡単に比較できる。
2. MLflow Projects
- プロジェクトを「再現可能な形」で管理。
- コードと依存関係(conda環境やDockerイメージなど)を一緒に定義。
- 別の環境やチームメンバーでも同じ実験を再現できる。
3. MLflow Models
- 学習済みモデルを保存・管理する仕組み。
- TensorFlow、PyTorch、scikit-learn、XGBoostなど多様なフレームワークに対応。
- 1つの統一フォーマットで「保存」「読み込み」「デプロイ」が可能。
- 例:学習済みモデルをAPIサーバーとしてすぐにデプロイできる。
4. MLflow Registry
- モデルのバージョン管理・承認フロー。
- "Staging"(テスト環境)、"Production"(本番環境)といったライフサイクルを管理可能。
- チーム開発で「どのモデルが現在本番で使われているか」を明確にできる。
最近は生成AI系のpythonライブラリ(LangChainなど)にも対応してきている。
詳しくは公式ページ参照のこと。
2. サンプルコード(Sklearn, RandomForest)
- SklearnのRandomForestを使って、GridSearchする想定
- 今回GSするのは、n_estimatorsとmax_depthの2パラメータ
- Artifactsの登録は、一時的にフォルダを作成し、そこのフォルダを指定して一括登録してます
import tempfile
import mlflow
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
from warnings import simplefilter
simplefilter('ignore', UserWarning) # UserWarningを無視(signature関連)
# datasetの準備
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names, dtype="float16")
y = pd.Series(iris.target, dtype="int8")
# 学習用(train)とテスト用(test)にデータセットを分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# experimentの設定
mlflow.set_experiment("RandomForestExample")
# ここから評価試験
for n_estimators in [4, 8, 16]:
for max_depth in [4, 6, 8]:
run_name = f"n_estimators={n_estimators}_max_depth={max_depth}"
# 評価試験を実行
print(f"=== {run_name=} ===")
with mlflow.start_run(run_name=run_name):
# ハイパーパラメータ等の条件を記録
parameters_dict = {"n_estimators": n_estimators, "max_depth": max_depth}
mlflow.log_params(parameters_dict)
# datasetの記録
dataset = mlflow.data.from_pandas(X, name="iris")
mlflow.log_input(dataset, context="iris_dataset")
# モデルの定義(scikit-learn)
clf = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
clf.fit(X_train, y_train) # 学習
# signatureの定義
signature = mlflow.models.infer_signature(X_test, y_test)
# 学習後のmodelを記録
mlflow.sklearn.log_model(clf, name="model", input_example=X_test.iloc[:3], signature=signature)
# 評価値の算出
y_train_predicted = clf.predict(X_train)
train_accuracy = accuracy_score(y_train, y_train_predicted)
print(f"{train_accuracy=}")
y_test_predicted = clf.predict(X_test)
test_accuracy = accuracy_score(y_test, y_test_predicted)
print(f"{test_accuracy=}")
# 評価値の記録
metrics_dict = {"train_accuracy": train_accuracy, "test_accuracy": test_accuracy}
mlflow.log_metrics(metrics_dict)
# artifactの登録
with tempfile.TemporaryDirectory() as temp_dir:
train_report = classification_report(y_train, y_train_predicted)
with open(temp_dir+"/train_classification_report.txt", mode="w") as f:
f.write(train_report)
test_report = classification_report(y_test, y_test_predicted)
with open(temp_dir+"/test_classification_report.txt", mode="w") as f:
f.write(test_report)
# feature imporance(.csv)
feature_importance = pd.DataFrame({"feature_imporance": clf.feature_importances_}, index=X_train.columns)
feature_importance.to_csv(temp_dir+"/feature_imporances.csv")
# feature_importance(.png)
ax = feature_importance["feature_imporance"].plot.barh()
ax.set_title("feature imporances")
ax.figure.tight_layout()
ax.grid()
plt.savefig(temp_dir+"/feature_imporances.png")
plt.clf()
mlflow.log_artifacts(temp_dir, artifact_path="art") # folderにあるファイルをまとめてartifactsに登録
実行結果

3. ブラウザで立ち上げる
3.1 起動方法
mlflow ui

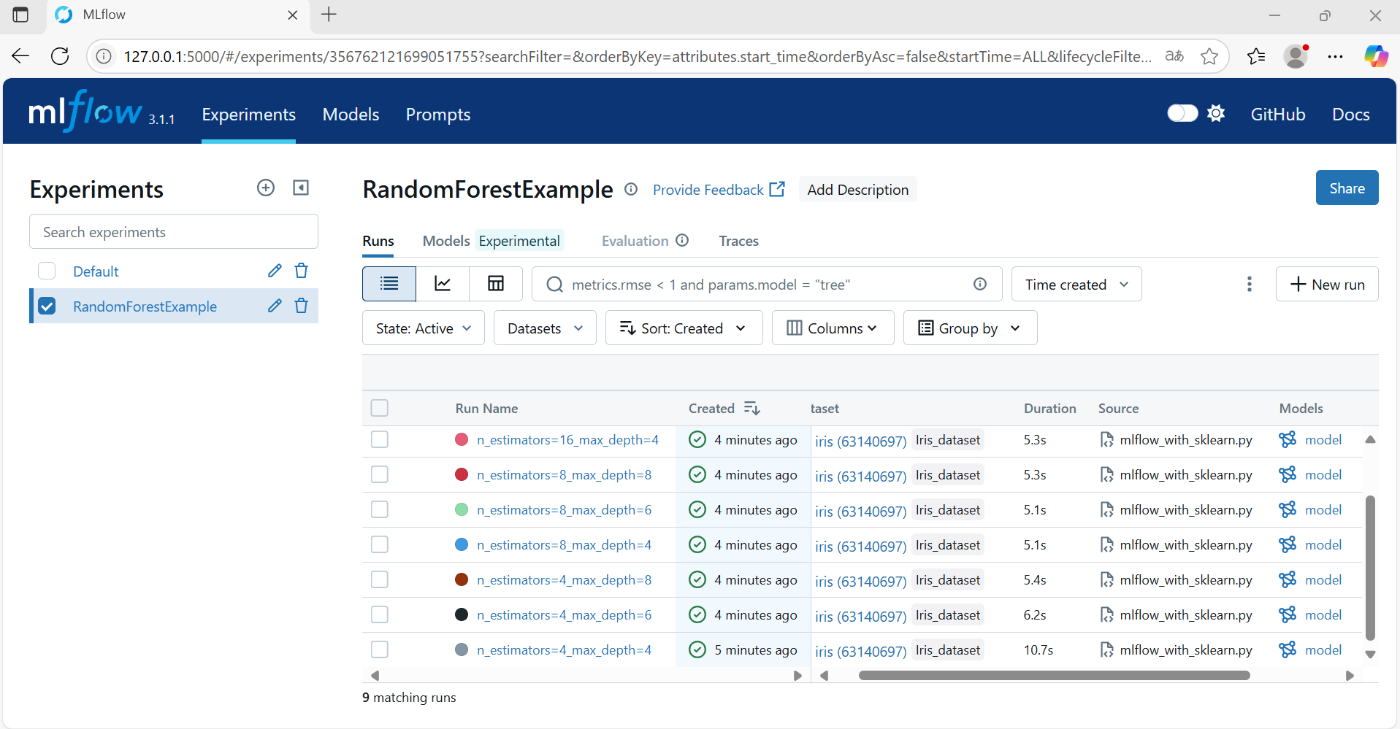
上記コマンドを実行した状態で、表示されたlocalhostにアクセスすると、以下の画面に移動する
(画像はmicrosorf Edgeのブラウザで起動した場合)
4. 使い方
4.1 Experiments
- mlflow.set_experiment() で設定したグループごとに、runが表示される
- Run Nameは、mlflow.start_run()のキーワード引数(run_name)で指定したものが表示される
- Createdには現在のステータスが表示されている
- 実行中:灰色
- 正常に完了:緑色
- プログラムがrunが正常に完了しなかった:赤色
- Datasetは、mlflow.log_inputで指定したデータセットが表示される
- modelには、mlflow.sklearn.log_modelで指定したモデルが表示される

ちなみに、datasetをクリックすると、データ数(行数)や要素数、各特徴量の名前と型が確認できる

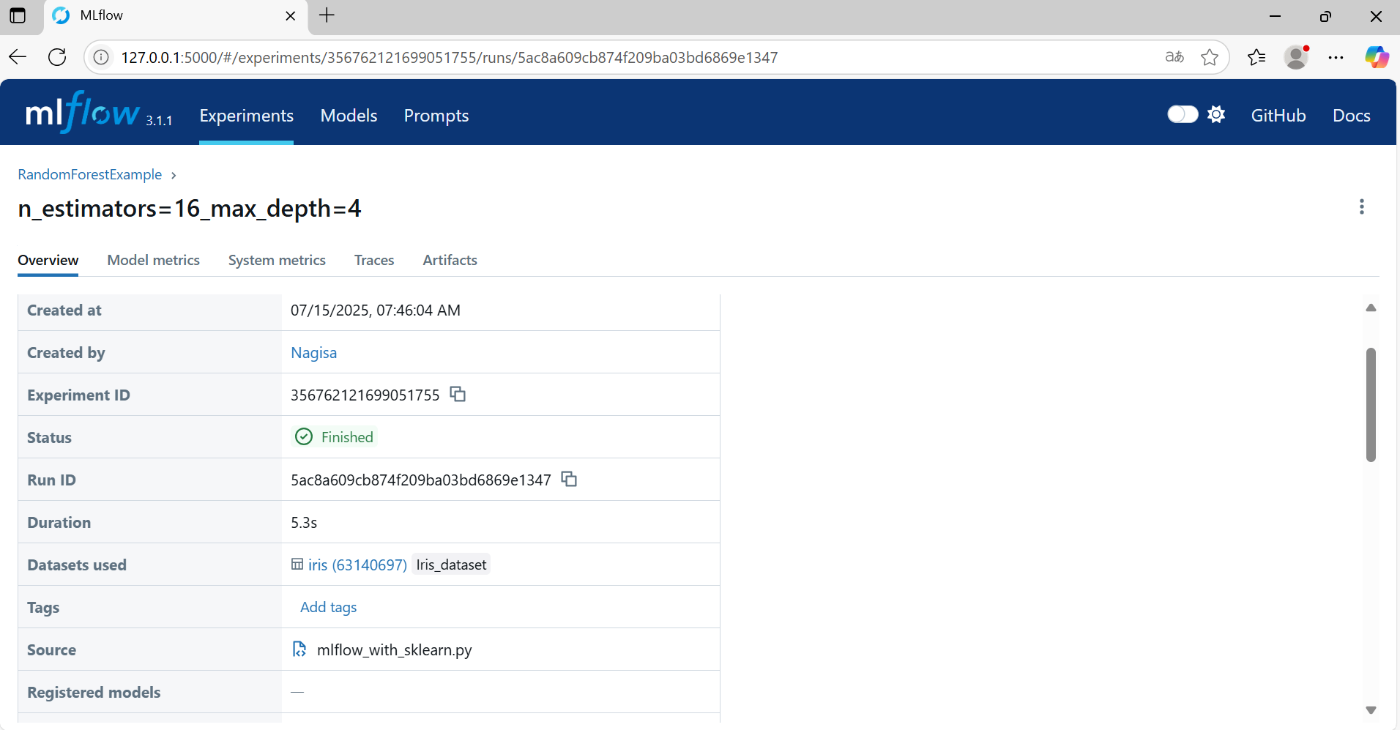
4.1.1 run Overview
下記のような情報が記録されている
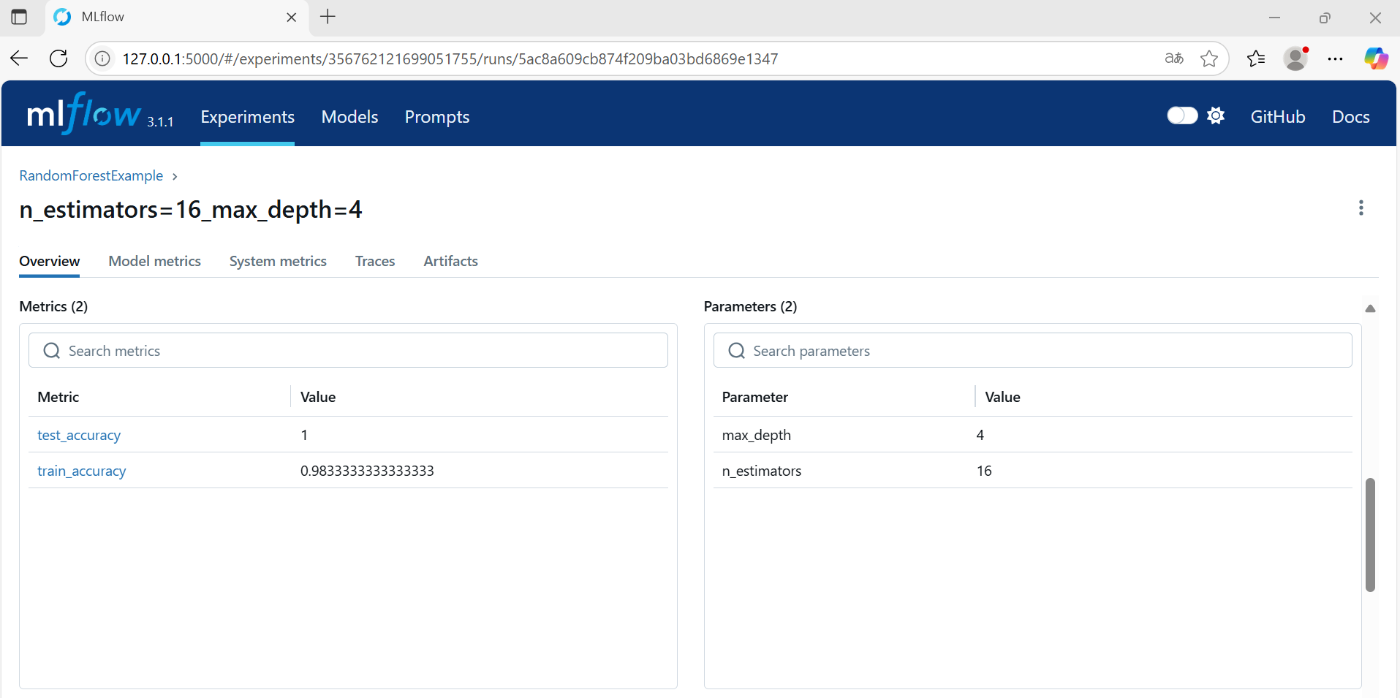
下にスクロールすると、Metrics(評価尺度)やParameters、model情報も表示されている
- Parametersは、mlflow.log_paramsで指定したパラメータが表示される
- Metricsには、mlflow.log_metricsで指定した評価値が表示される

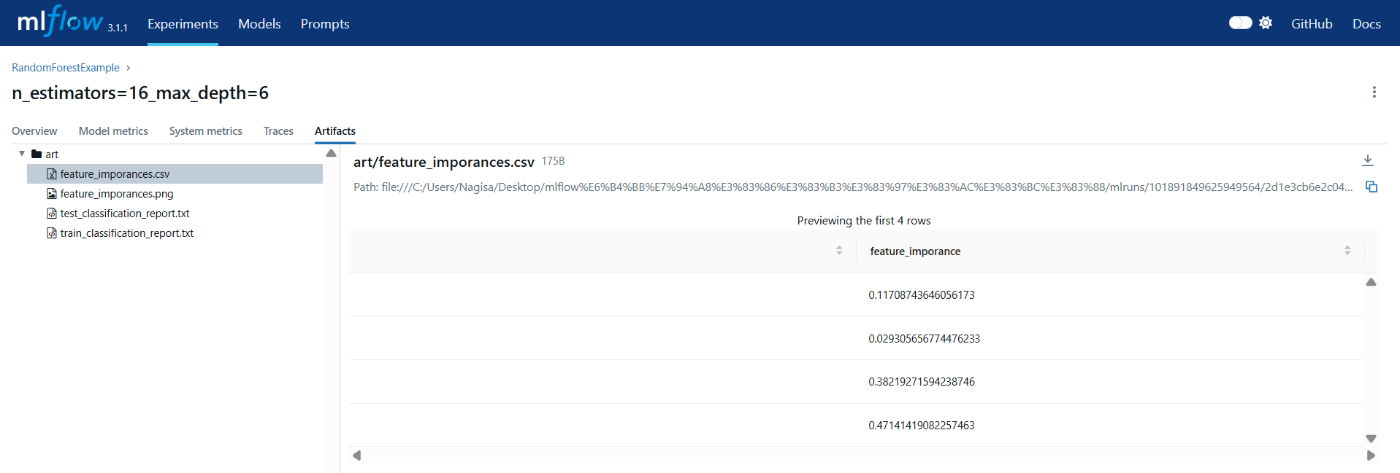
4.1.2 run Artifacts
Artifactsタブには、mlflow.log_artifactsで指定したフォルダ内のファイルを確認できる
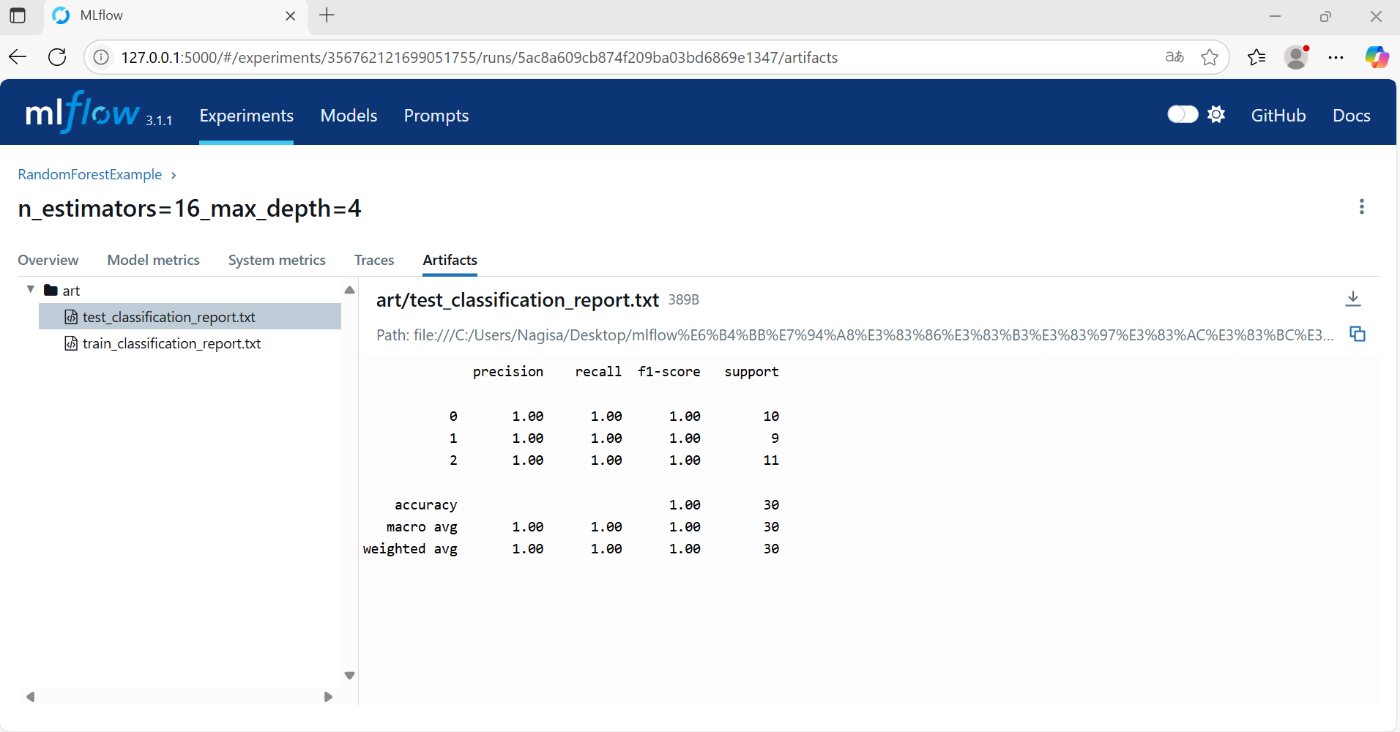
txtだけでなく、csvやpng等一部のファイルは、わかりやすく表示してくれる

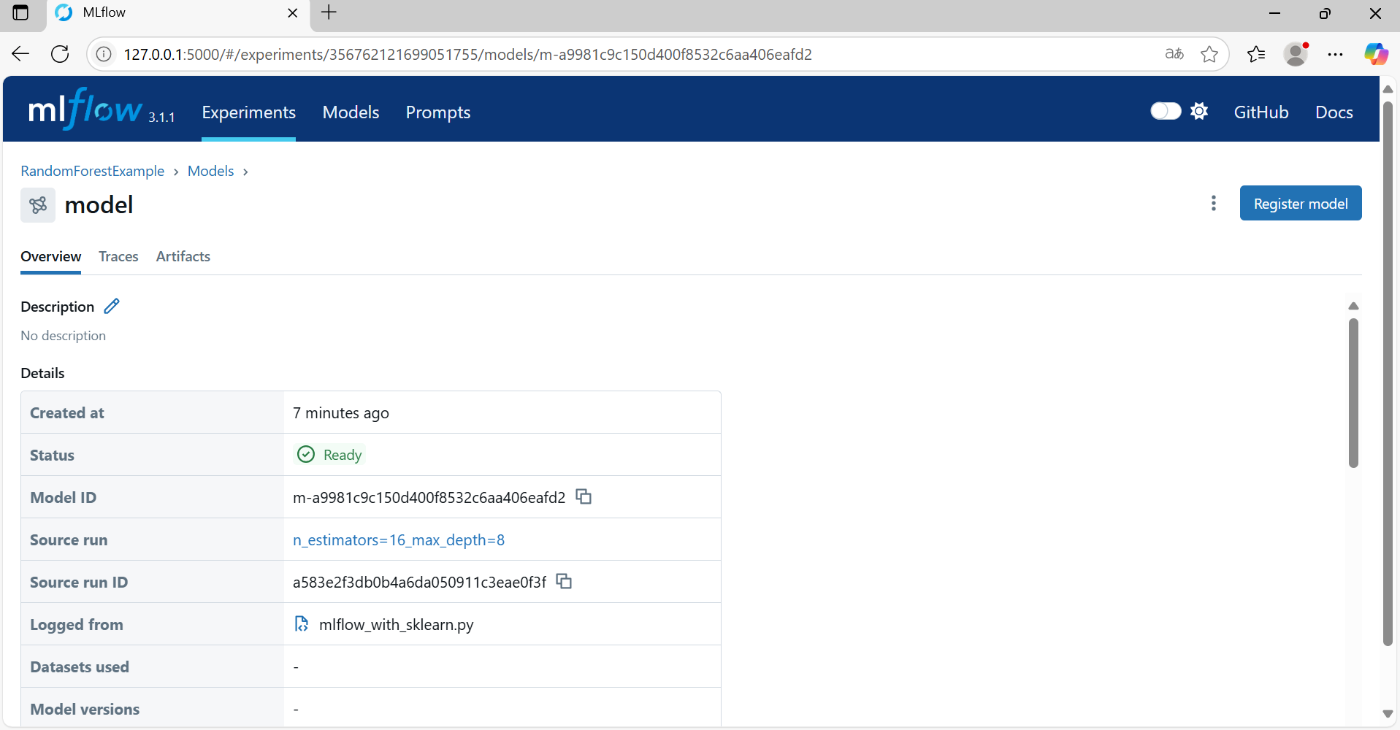
4.3 Model
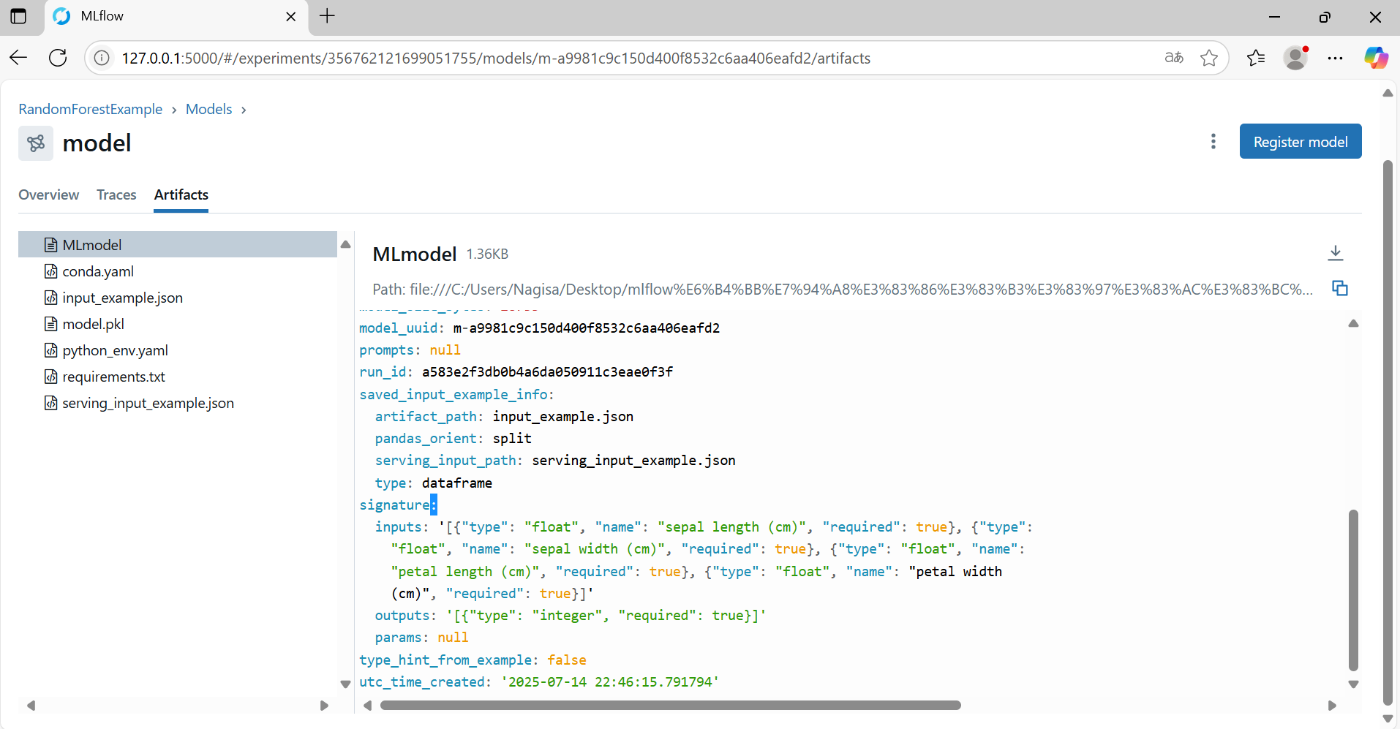
4.3.1 model - Artifacts
Experiment同様に、Artifactsのタブがあり、そこにモデルの情報等が記録されている
mlflow.sklearn.log_model の引数で指定したsignatureはここ(右メニューのMLmodelのファイル)に表示される
- signature: inputsには入力特徴量の名前(name)とデータ型(type)が表示される
- ここでの型はpythonのものではなく、mlflow側の独自の型分類のため、注意
- signature: outputsには、正解ラベルのデータ型(type)が表示される
まとめ・感想
- いままで独自で評価結果やパラメータの保存を行っていたので、こういうライブラリがあるのは助かるし、他の人にも評価結果の共有がしやすくなったと感じる
- mlrunsのフォルダ内にデータが格納されているので、そちらを確認すればmlflow uiでわざわざ立ち上げる必要もない気がする
- モデルのデプロイやload、tag付け等の機能もあるので、そちらも引き続き学んで活用できるようにしていきたい
Discussion