🪶
【Seaborn】よく使うグラフ5選【Python】
- 自分用の備忘録です
- matplotlibでもグラフは作成できますが、凝った分析をする際はseabornのほうがコードがシンプルかつおしゃれになることもあるので、情報共有
- 特にpairplotやheatmapはmatplotlibで自作するのはしんどいので、分析に重宝してます
0. iris_dataset
- 機械学習やプログラムの動作確認でよく使うiris_datasetの読み込み
- seabornのライブラリ内にも同梱されており、sns.load_dataset("iris")で読み込める
- pandasのDataFrame形式なので、pandasに慣れている人やseabornをプログラム内で使う場合はこっちを使うとよい
import seaborn as sns # seabornはsnsの略称をつけることが多い
import matplotlib.pyplot as plt
import numpy as np
# 0. iris
iris = sns.load_dataset("iris") # DataFrame形式で読み込める
print(iris) # 中身の確認
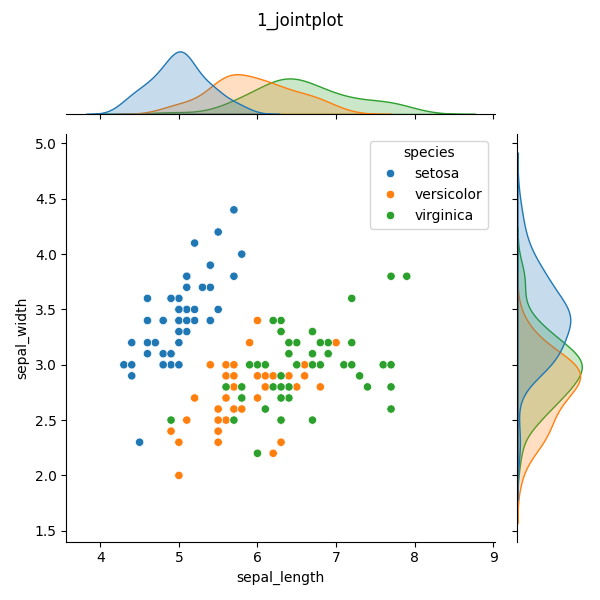
1. jointplot
- 散布図+分布の確認が同時にできるグラフ
- hueでDataFrameの列名(カテゴリ変数)を指定することで、グラフ内のmarkerや色を分けて表示してくれる
- 用途:2つの連続変数(x, y)とカテゴリ変数(hue)の違いの分析 など
- 下記のプログラムの例は、iris_dataset内のspecies(種類)による違いが、sepal_lengthとsepal_widthにあるか?を確認する際に使用している
# 1. jointplot
def example_jointplot():
sns.jointplot(data=iris, x="sepal_length", y="sepal_width", hue="species")
plt.suptitle("1_jointplot")
plt.tight_layout()
plt.savefig("1_jointplot.png")
example_jointplot()
2. pairplot
- DataFrameの各列の組み合わせ(カテゴリ変数以外)を散布図でまとめて表示する
- 列の数が増えると処理が重いのが難点
- 離散変数も散布図に表示することは可能だが、sampleが重なるケースが多いので、分析しやすいとはいえない
- 用途としては、変数間の相関を視覚的に確認したり、hueに指定した種類による分布の違いを確認する際に使用する
def example_pairplot():
sns.pairplot(iris, hue="species",
markers=["o", "s", "D"], corner=True)
plt.suptitle("2_pairplot")
plt.tight_layout()
plt.savefig("2_pairplot.png")
plt.clf()
example_pairplot()

3. swarmplot
- 列をカテゴリで分けて、分布を確認する際に用いる
- 散布図だと被ってしまう同じ値のサンプルデータを、少しずらして表示してくれるため、便利
- とはいえ表示個数には限界があるので、サンプル数が多い場合はviolinplotやboxplotにしたほうが良い
def example_swarmplot(dataset):
categories = ["hoge", "moge", "fuga"]
dataset["category"] = np.random.choice(categories, size=len(dataset))
ax1 = plt.subplot(title="swarmplot")
sns.swarmplot(dataset,
x="category", y="sepal_length", hue="species",
dodge=True, ax=ax1)
plt.grid()
plt.savefig("3_swarmplot.png")
plt.clf()
example_swarmplot(iris)

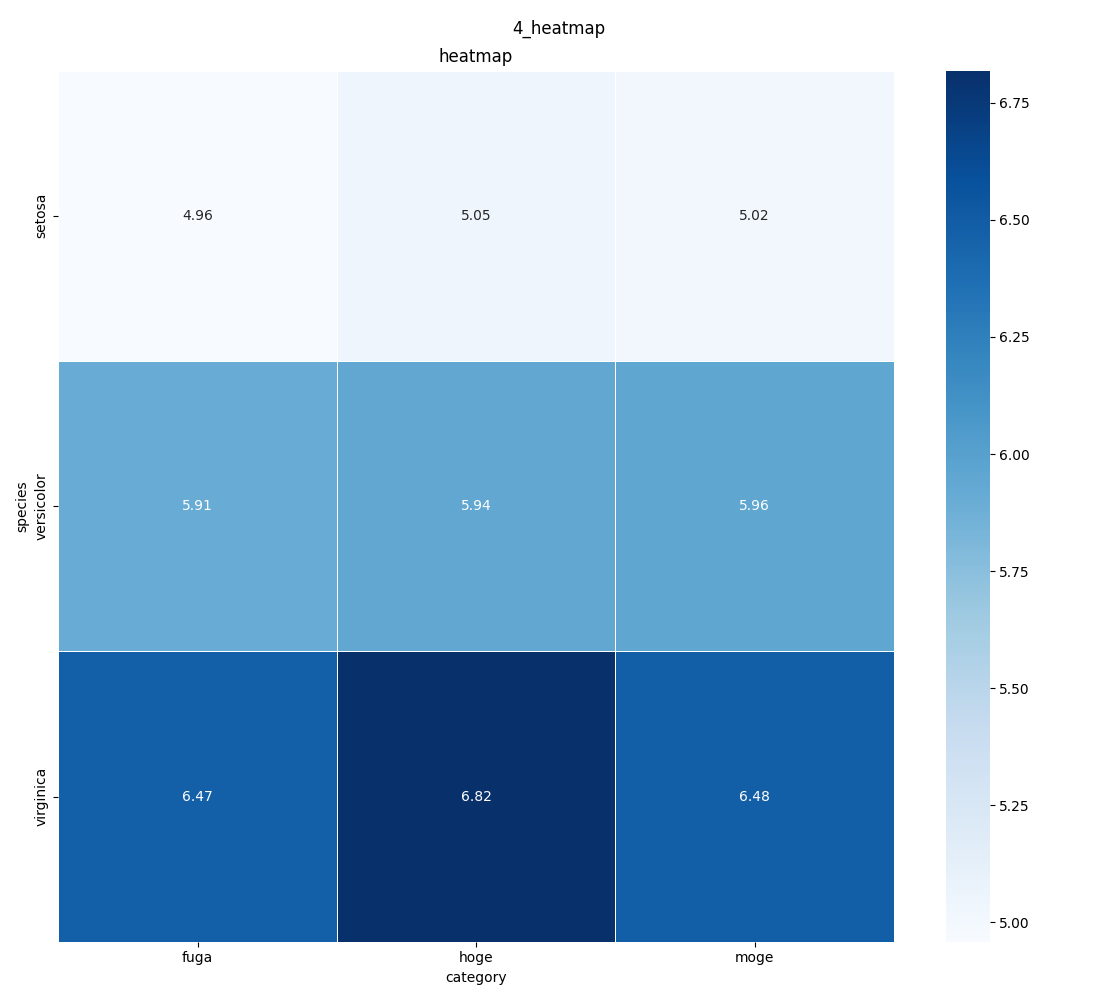
4. heatmap
- カテゴリ×カテゴリで連続値を表示する場合に有効
- pandasのpivot_tableを前処理に使うと簡単に作成できる
- その際はaggfuncで代表値を算出する必要がある(プログラム例ではmean(平均値)を算出)
- よく使う例として、機械学習のclassificationでの混同行列をグラフにしたり、GridSearchでハイパーパラメータごとの評価尺度を可視化したりする
def example_heatmap(dataset):
categories = ["hoge", "moge", "fuga"]
dataset["category"] = np.random.choice(categories, size=len(dataset))
ax1 = plt.subplot(title="heatmap")
pivoted = dataset.pivot_table(index="species", columns="category",
values="sepal_length", aggfunc="mean")
print(pivoted)
pivoted.to_csv("pivoted_table.csv")
sns.heatmap(pivoted, annot=True, fmt=".2f", linewidth=.5, cmap="Blues", ax=ax1)
plt.suptitle("4_heatmap")
plt.tight_layout()
plt.savefig("4_heatmap.png")
plt.clf()
example_heatmap(iris)
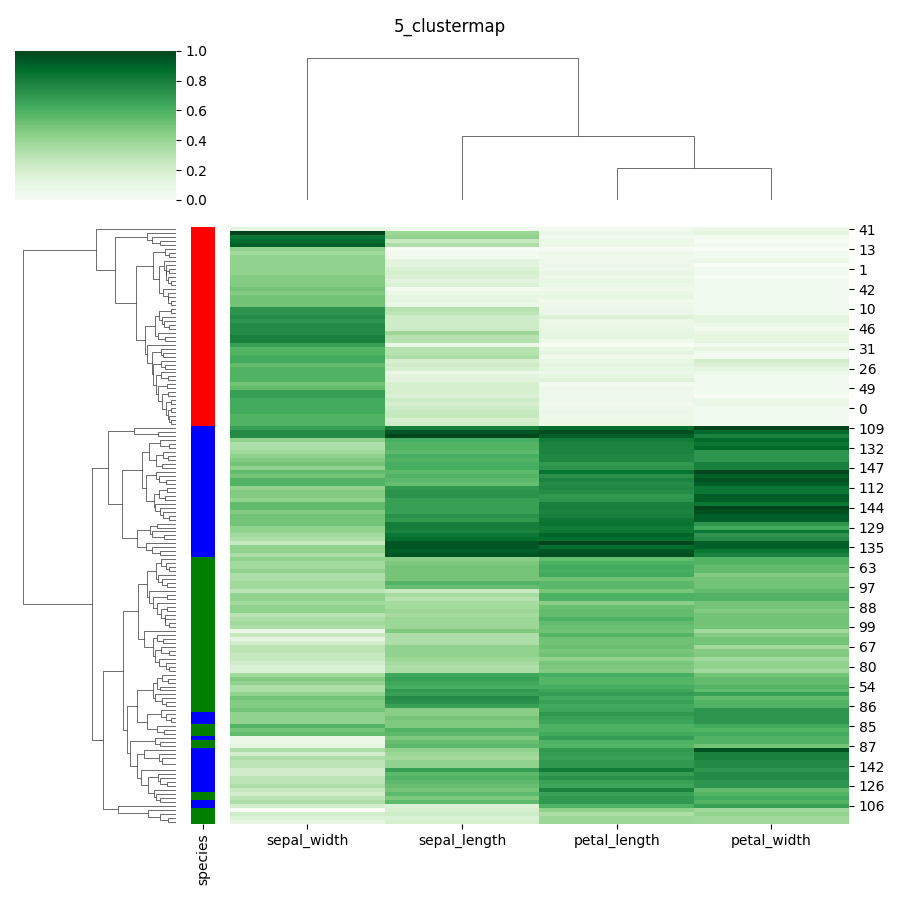
5. clustermap
- scipyが必要(別途pipでインストールしてください)
- 各列(連続値)をheatmapで可視化しつつ、クラスターを作成できる
- 個数が多くなると描画処理が重く見づらいため、あまり活用はしていない(できていない)
def example_clustermap(dataset):
# 要:scipy
species = dataset["species"].unique()
color_dict = {k:v for k, v in zip(species, ["red", "green", "blue"])}
plot_color = dataset["species"].replace(color_dict) # species毎に対応した色に置き換える
print(plot_color) # Seriesだと、plot
del dataset["species"] # 数値以外のカテゴリは列から削除しておく
sns.clustermap(dataset,
figsize=(9, 9), # 画像のサイズ指定
row_colors=plot_color, # 横に記載する色(Species)の指定(配列)
cmap="Greens", # 色の指定
standard_scale=1) # 1:列ごとに正規化, 0:行ごとに正規化
plt.suptitle("5_clustermap")
plt.tight_layout()
plt.savefig("5_clustermap.png")
plt.clf()
example_clustermap(iris)
おまけ:lineplot
- 折れ線グラフを描画するlineplotは、列ごとに時系列を表示してくれるので便利
- matplotlibの場合だと、何度も列ごとにplt.plotを呼ばないといけないので、それを1行で書けるのは楽
- 他に、マーカーを表示したり、95%信頼区間の値を色塗りで表現したりできる
https://seaborn.pydata.org/generated/seaborn.lineplot.html
import pandas as pd
def example_lineplot():
sns.set()
x = np.linspace(0, 2*np.pi, 1000)
data = pd.DataFrame({"sin": np.sin(x),
"cos": np.cos(x)})
sns.lineplot(data, )
plt.suptitle("ex_lineplot")
plt.tight_layout()
plt.savefig("ex_lineplot.png")
plt.clf()
example_lineplot()
まとめ
- seabornは、分析で活用できるおしゃれなグラフや複雑なグラフを簡単に描画できる
- matploltibで実装が面倒なグラフ(pairplotやheatmapなど)の作成の際に活用すれば、実装工数の削減が可能
- 細かいレイアウトにこだわるならmatplotlibに戻って実装することになる
Discussion