はじめに
こんにちは、株式会社ホロラボの杉浦です。
Apple Vision ProではEnterprise APIを利用することで一般にはアクセスできない機能のいくつかにアクセスできるようになります。その一つとして、メインカメラの映像を取得できるようになりました。Enterprise APIについての詳細は以下の記事を参照してください。
また、昨今のAIサービスは画像とテキストを入力して認識結果を返すことができるようになっています。たとえば、「この画像には何が映っていますか?」というテキストと画像を一緒に与えると、画像に何が映っているかAIが画像を認識して答えてくれます。
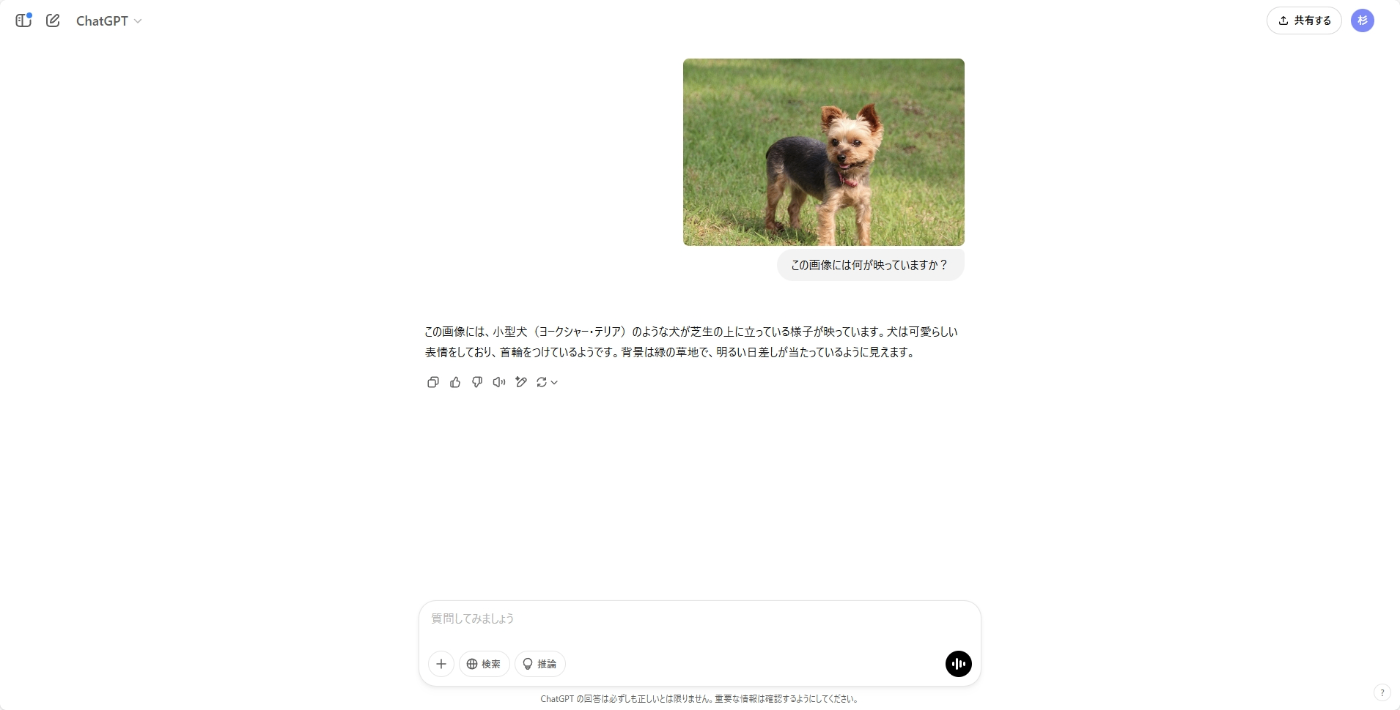
ChatGPTによる画像認識
これらの技術を組み合わせ、Apple Vision Proのメインカメラから取得した画像をAIで画像認識するアプリを試作しました。この記事では、試作の際に得られた知見を共有します。

試作アプリのイメージ
技術要素
試作アプリを構成するそれぞれの技術はドキュメントや解説記事が揃っているため難しくありません。ここでは簡単に概要を紹介するに留めておきます。
カメラ映像の取得
Enterprise APIを利用してApple Vision Proのメインカメラの映像を取得する方法は以下の記事で解説されています。この画像をJPEGで圧縮、Base64でエンコードした文字列をJSONに埋め込んでHTTPリクエストをAIサービスに送信します。
AIによる画像認識
画像認識ができるAIサービスとしてOpenAI APIを利用しました。OpenAIのモデルのうちいくつかのモデル(o1P、gpt-4o、gpt-4o-mini、gpt-4-turbo)が画像の入力に対応しているようです。ここでは比較的安価なgpt-4o-miniを利用しました。
試作アプリ
試作アプリの問題と改善
出来上がった試作アプリをデバイスにインストールして実機で動かしたとき、いくつかの問題に気が付きました。
ユーザーインターフェース
最初のユーザーインターフェースはこのようになっていました。ウィンドウにカメラ映像が表示され、その下にテキストプロンプトの入力欄と送信ボタンがあるようなデザインです。送信ボタンを押すと即座にカメラ画像とテキストがAIサービスに送られ、少し待つとAIによる画像認識の結果が表示されます。試作なのでテキトーなものでいいだろうと考えていました。

最初のユーザーインターフェース
ヘッドセットタイプのXRデバイスの開発経験が豊富な方はお気付きかもしれません。実はシミュレーターで動かしたときはなんの問題もありませんが、デバイスで動かしたときには問題があります。ホロラボの中では大変珍しいXRデバイスの開発経験がほぼ0の私は実際に実機を被るまで気が付きませんでした。
Apple Vision Proではボタンを押すときにボタンの位置を手指で押すかボタンの位置に視点を合わせて手指をタップすることで操作をします。
-
手指でボタンを押すときにカメラ映像に手指や腕が映ってしまう
ボタンを手指で押すと確かに動作します。しかし、ボタンを押した瞬間の画像にはユーザーが意図しない手指が映ってしまうのです。また、ボタンを押すときには自然と目線がそちらに向いてしまいカメラが意図した対象から外れやすいという問題もあります。 -
視点を合わせて手指をタップしてボタンを押すとカメラ視野が対象から外れやすい
ボタンに視線を合わせて手指をタップする、これも確かに動作します。こちらであればボタンを押した瞬間の画像にユーザーが意図しないものは映らないでしょう。しかし、ボタンに視線を合わせる必要があるので、これもカメラが意図した対象から外れてしまうという問題があります。
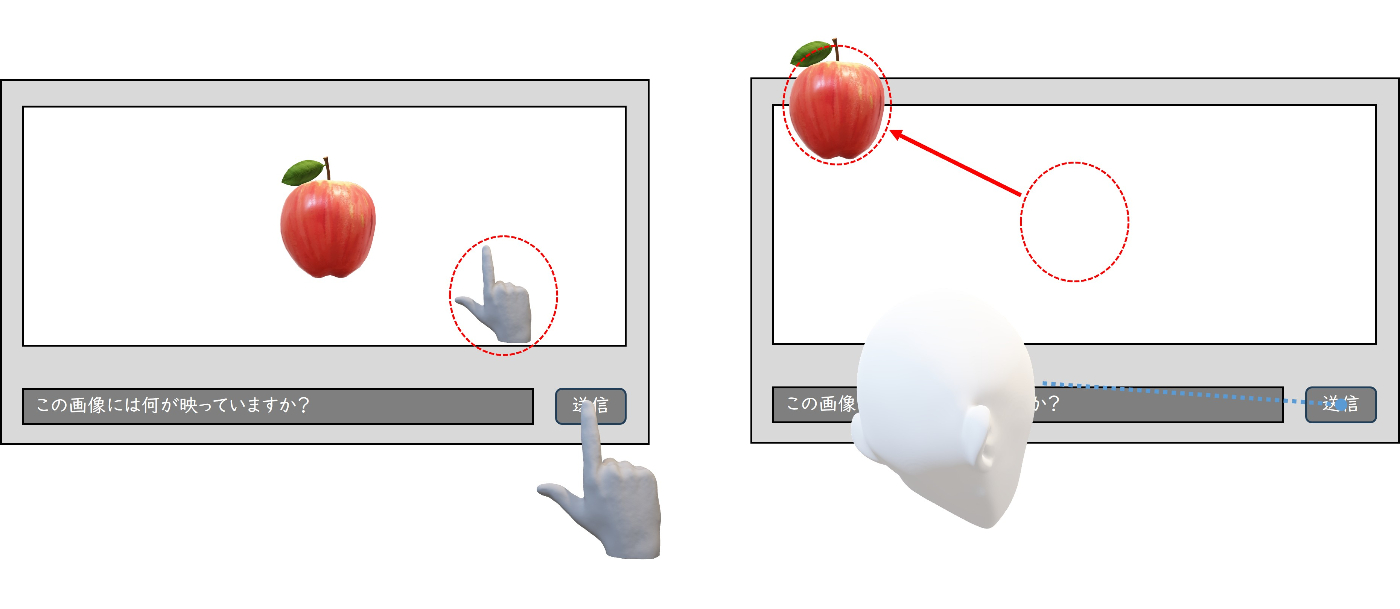
ユーザーインターフェースの問題点
この問題を改善するにはいくつかの方法が考えられます。
-
ボタンを押してからカウントダウンを挟む
ボタンを押した瞬間のカメラ画像ではなく、ボタンを押してから数秒のカウントダウン挟んだ後のカメラ画像を使って画像認識します。これによりカメラ画像にユーザーが意図しない手指が映ってしまうことはないでしょう。 -
カメラ映像を表示している部分を表示兼ボタンにしてしまう
カメラ映像の表示とボタンの場所が離れていると視点の移動が発生します。カメラ映像の表示とボタンを同じ場所に配置することで、カメラが意図した対象に向いた状態でボタンを押すことができます。

ユーザーインターフェースの改善案
テキストプロンプト
テキストプロンプトの入力欄に仮想キーボードで質問を毎回入力するのは大変です。そこでデフォルトのテキストプロンプトを入力しておくようにしました。試作アプリには想定ユーザーが定まっていなかったので「この画像には何が映っていますか?」というシンプルで汎用的な質問にしました。
AIの利用経験が豊富な方はもうお気付きかもしれません。このテキストプロンプトには問題があります。これも私は実際に試作アプリを動かしてみるまで気が付きませんでした。
「この画像には何が映っていますか?」という質問は対象が明確なようで曖昧なのです。だいたいのユーザーは暗黙的に画像の中で視線の先とか中央の辺りなどを想定するのではないでしょうか?
机の上にりんごとコーヒーカップが載っている画像に対して「この画像には何が映っていますか?」という質問をします。AIは「机の上にりんごがあります。その左側にはコーヒーカップがあります。背景には…」のように机の上だけでなく背景などユーザーが意図しない対象についても答えてしまうでしょう。

テキストプロンプトの問題点
この問題を改善するにはいくつかの方法が考えられます。
-
画像をクリップする
対象が中心に映るように画像をクリップする。たとえば、画像全体を使うのではなく画像中央の範囲を切り出して使ったり、画像からオブジェクト検出して検出したオブジェクトのバウンディングボックスの範囲の画像を使うなどが考えられる。 -
テキストプロンプトを工夫する
対象を絞ったプロンプトにする。たとえば、「この画像には何が映っていますか?」のように画像全体について尋ねるプロンプトではなく、「この画像の中央付近には何が映っていますか?」や「この画像で手に持っている物はなんですか?」など対象となる範囲を絞って尋ねるプロンプトを使うなどがが考えられる。
テキストプロンプトの工夫は手軽にできて実装に手を加えずに問題を解決できる場合があるので、まずはこちらを検討してみるといいでしょう。
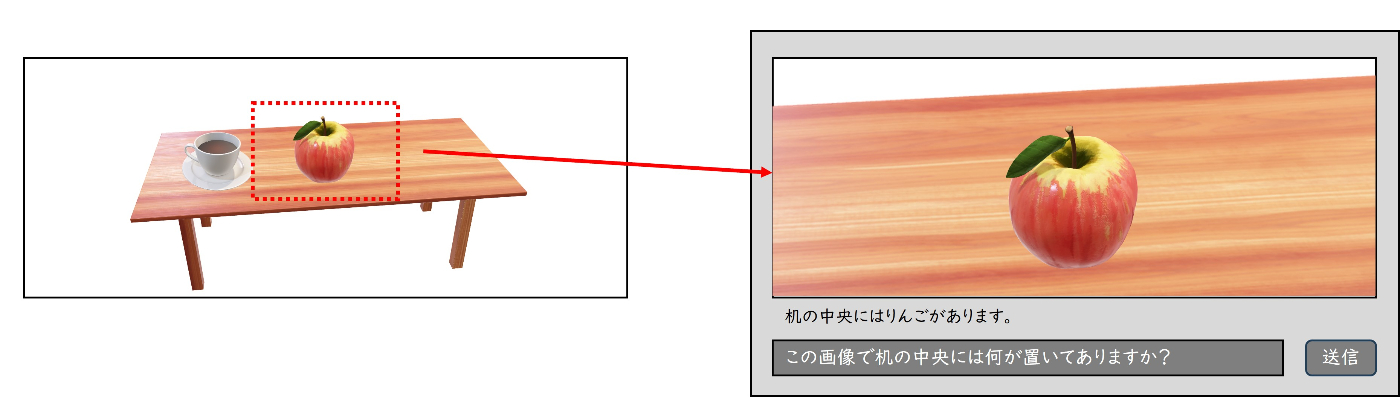
画像をクリップする改善案

テキストプロンプトを工夫する改善案
まとめ
Apple Vision ProのメインカメラアクセスとAIによる画像認識を組み合わせて目の前に何があるのか教えてもらうアプリを試作、得られた知見を共有しました。このような機能を組み込むときはユーザーインターフェースやテキストプロンプトに気を配ると良いアプリになると思います。
また、XRデバイスの開発経験が乏しい初心者の私にとって、ユーザーインターフェースの問題に気が付いたときには「なるほどたしかに」と新鮮な感覚が得られ勉強になったと同時に、XRデバイスの開発経験が豊富な同僚たちはこういった使い勝手にも配慮しながら日々開発しているんだなと大変感心しました。
ホロラボは「Apple Consultants Network」のメンバーとして認定を取得し、Apple Vision Proに対応したアプリケーションやサービス提供のみならず、visionOSを搭載するApple Vision Proを顧客業務環境に広く導入するための支援を行っています。ホームページではApple Vision Proでどのようなことができるかショーケースで紹介していますので是非ご覧ください。
また、ホロラボのメンバーがApple Vison Pro のアプリ開発入門書籍を執筆しました。初心者の私はこれを読んで試作アプリの開発に取り組むことができました。超おすすめです!

株式会社ホロラボの技術に関するブログ集です。 ホロラボは「フィジカルとデジタルをつなげ、新たな世界を創造する」をミッションに、XRや空間コンピューティングを軸にした価値を提供する企業です。 お問い合わせは👉のURLよりお願いします! hololab.co.jp/#contact
Discussion