はじめに
Google の AI、Gemini 2.0 には 3D Spatial Understanding という機能があります。
これは、入力した画像内のオブジェクトの三次元的な位置を推定して座標、サイズ、回転を出力するというものです。
Gemini AI Studio の Starter Apps -> Spatial Understanding -> 3d bounding boxes から試すことが出来ます。
調査した2025年2月時点で Experimental(実験的) 機能となっており、精度は出ないとの事ですが
実際どの程度のものなのか試してみた記事になります。
検証方法
Unity で シーンを作成し、その画像から Gemini AI Studio で三次元座標を出力、
出力された座標と対象のオブジェクトの座標にどれだけ差が出るかを Unity 上で確認する。
Gemini AI Studio で出力された座標とUnity座標への変換は以下のように実施。
Gemini AI Studio の出力:
x_center, y_center, z_center, x_size, y_size, z_size, roll, pitch, yaw
Unity座標への変換:
前提:バウンディングボックスはカメラの子オブジェクト
1.center の (y,z) を入れ替えて transform.localPosition にセット
2.size の (y,z) を入れ替えて transform.localScale にセット
3.回転
3-1. (roll, pitch, yaw) をそれぞれ Rx, Ry, Rz の回転行列に変換。
3-2. (R_x * R_y) * R_z してEuler合成行列を作る。
3-3. X 軸に対して +90° 回す行列を掛ける。
3-4. 回転行列をQuaternionに変換する。
3-5. transform.localRotation にセット。
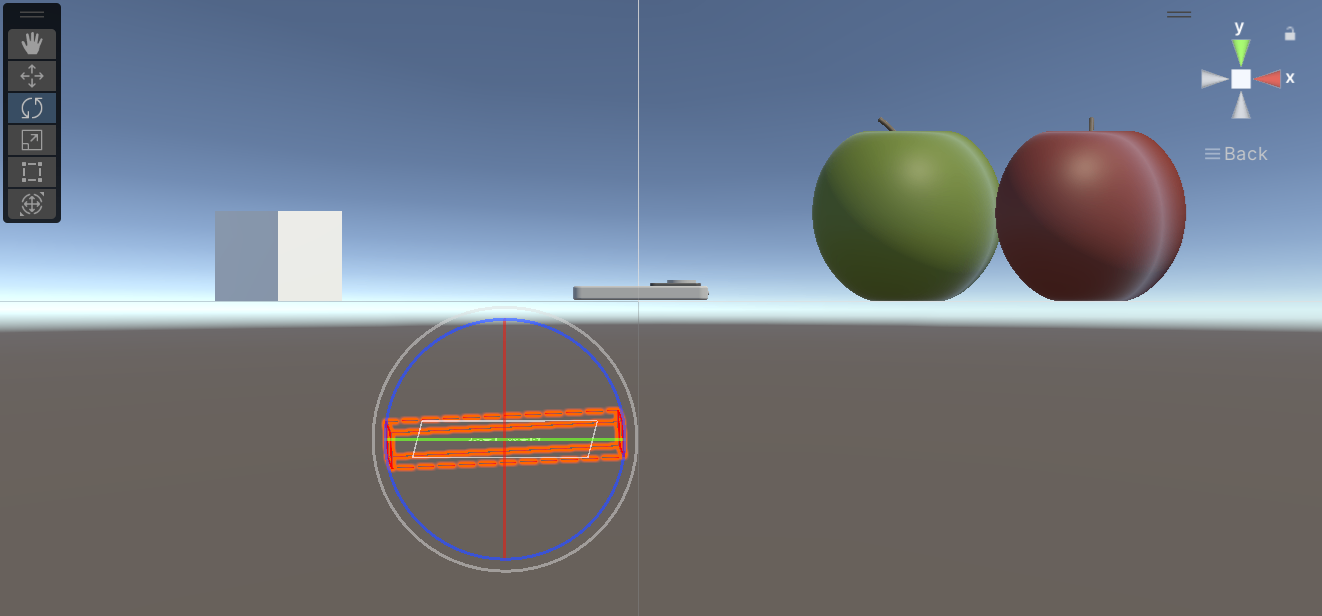
結果
- 平面で捉えたときは合っているように見えても、奥行きにかなり誤差が生じる傾向がありました。
今回の試した範囲では、オブジェクトの中心から出力された座標の中心まで
平均13cm程度誤差が発生していました。
| AI Studio 上の表示 | Unity上の表示 | Unity で横から見た図 |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
おわりに
やはり単眼画像から奥行きの推定が難しいようなので、
深度センサーを併用するなどして奥行き情報を足すのが良さそうだと思いました。

株式会社ホロラボの技術に関するブログ集です。 ホロラボは「フィジカルとデジタルをつなげ、新たな世界を創造する」をミッションに、XRや空間コンピューティングを軸にした価値を提供する企業です。 お問い合わせは👉のURLよりお願いします! hololab.co.jp/#contact
Discussion