自然言語処理を用いたAmazonレビューの分類(BERT編)
本記事ではAmazonレビューを元に、それが高評価か低評価か判断するタスクを取り扱います。
使うモデルはNaive BayesとBERTで今回はBERTを取り上げます。
Naive Bayesはこの記事をご覧ください。
BERTとは
BERTは2018年にGoogleにより提案されたモデルです。
Attentionを用いたことにより深く分析できたり計算効率が良いという利点に加え、Pre-trainingとFine-tuningを用いた学習の手軽さから人気になっています。
Transformerについて
BERTではTransformerというモデルで提案されたTransformer Encoderと呼ばれるAttentionを用いたNNを用いています。
Transformerは超有名論文「Attention is all you need」で提案されたモデルです。
TransformerはSeq2seqと同じでEncoder‐Decoderモデルです。
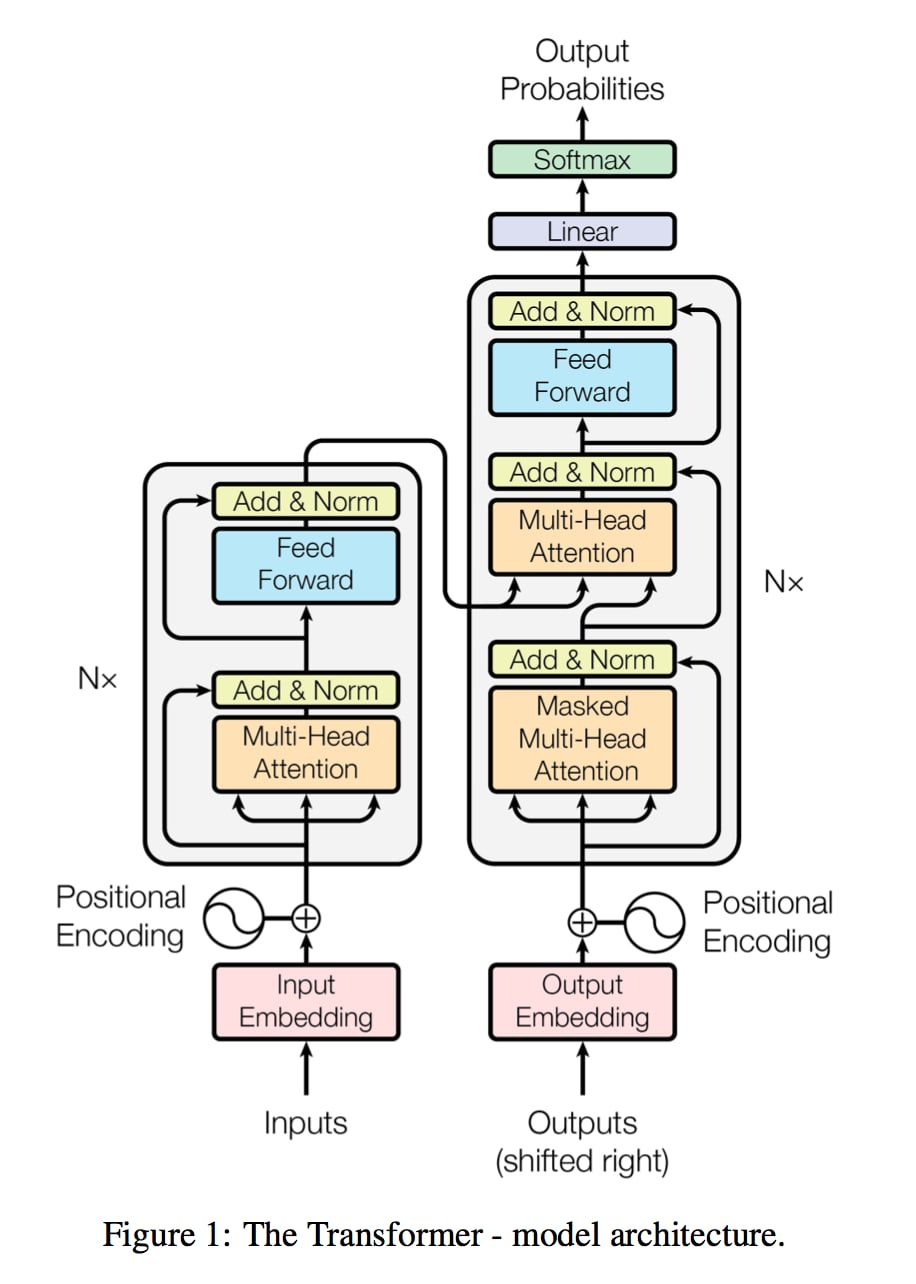
ENCODERでは意味を取り出しDECODERでは意味を日本語に直しています。
Attention層で構築することによりRNNなどのモデルと比べて「計算を高速化した上により正確な翻訳をすること」が可能になりました。
Transformerについて詳しく知りたい方はこちら。
BERTについて
Transformerには、文書分類のためのクラスBertForSequenceClassigicationがあり、次のような構造をしています。

推論時には、このモデルを通して、カテゴリごとの分類スコアを得ます。そして、分類スコアの最も高いラベルを予測値とすることで、文章分類を行うことができるというわけです。BERTは12層のTransformerレイヤーで構成されており、BertForSequenceClassificationでは、最終層の最初のトークン[CLS]に対応する出力を分類器に入力しています。分類器では入力に対して線形変換とtanh関数を用いて分類スコアを計算しています。また、ファインチューニングの時には出力とラベルの間の損失を最小化するようにパラメタの更新を行なっています。
前処理
僕の実行環境は次のとおりです。
- 実行環境
- Google Colaboratory (Pro +)
- Python
- 3.8.10
- janome
- 0.4.2
- Transformers
- 4.18.0
- fugashi
- 1.1.0
- ipadic
- 1.0.0
- pytorch_lightning
- 1.6.1
ここから入手できるものの中からcls-acl10-unprocessedを使います。
前処理済みのデータセットもあるのですが今回は勉強を兼ねて前処理からやります。
前処理のコードはこちらの本を参考にさせてもらいました。
コードを一応貼っておきますがNaive Bayes編とほぼ同じなので詳しい説明は省略します。
code
#トークナイザのロード
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
max_length = 128 #bertは最大512トークン
def get_tokenized_sentences_and_labels(file_name: str):
#データの読み込み
with open(file_name) as f:
data = f.read()
data = data.replace('\n', '').replace('\r', '')
reviews = re.findall(pattern=r'(.+?)',string=data) #ratingはあるのにtextがない感想を取り除く
dataset_for_loader = []
for item in reviews:
raiting = re.findall(pattern=r'(.+?)',string=item)
text = re.findall(pattern=r'',string=item)
text = '\n'.join(text)
encoding = tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True
)
raiting = int(float(raiting[0])) - 1 #5段階の評価を取得
label = 0 if raiting >= 3 else 1 #positive -> 0, negative -> 1
encoding['labels'] = label
encoding = {k: torch.tensor(v) for k, v in encoding.items()}
dataset_for_loader.append(encoding)
return dataset_for_loader
dataset_learn = get_tokenized_sentences_and_labels(config.input_path + 'train.review')
dataset_test = get_tokenized_sentences_and_labels(config.input_path + 'test.review')
div_index = int(len(dataset_learn) * 0.8)
dataset_train = dataset_learn[:div_index]
dataset_val = dataset_learn[div_index:]
dataloader_train = DataLoader(dataset_train, batch_size=32, shuffle=True)
dataloader_val = DataLoader(dataset_val, batch_size=256)
dataloader_test = DataLoader(dataset_test, batch_size=256)
学習
BERTはファインチューニングせずとも推論ができますが、一般にファインチューニングした方が精度が上がるので今回はファインチューニングした後に推論を行いました。興味がある方はファインチューニングせずにやってみて結果を比較してみると、面白いと思います。
学習のコードは次の書籍を参考にさせてもらいました。僕が初めて自然言語処理を勉強した時に読んだ本で、やや難易度は高いですが、とてもわかりやすくおすすめです。
まず、BertForSequenceClassificationのクラスを定義します。このクラスでは、ファインチューニングするBERTをロードし、学習とテストに関する関数を定義しています。
class BertForSequenceClassification_pl(pl.LightningModule):
def __init__(self, model_name, num_labels, lr):
# model_name: Transformersのモデルの名前
# num_labels: ラベルの数
# lr: 学習率
super().__init__()
# 引数のnum_labelsとlrを保存。
# 例えば、self.hparams.lrでlrにアクセスできる。
# チェックポイント作成時にも自動で保存される。
self.save_hyperparameters()
# BERTのロード
self.bert_sc = BertForSequenceClassification.from_pretrained(
model_name,
num_labels=num_labels
)
# 学習データのミニバッチ(`batch`)が与えられた時に損失を出力する関数を書く。
# batch_idxはミニバッチの番号であるが今回は使わない。
def training_step(self, batch, batch_idx):
output = self.bert_sc(**batch)
loss = output.loss
self.log('train_loss', loss) # 損失を'train_loss'の名前でログをとる。
return loss
# 検証データのミニバッチが与えられた時に、
# 検証データを評価する指標を計算する関数を書く。
def validation_step(self, batch, batch_idx):
output = self.bert_sc(**batch)
val_loss = output.loss
self.log('val_loss', val_loss) # 損失を'val_loss'の名前でログをとる。
# テストデータのミニバッチが与えられた時に、
# テストデータを評価する指標を計算する関数を書く。
def test_step(self, batch, batch_idx):
labels = batch.pop('labels') # バッチからラベルを取得
output = self.bert_sc(**batch)
labels_predicted = output.logits.argmax(-1)
num_correct = ( labels_predicted == labels ).sum().item()
accuracy = num_correct/labels.size(0) #精度
self.log('accuracy', accuracy) # 精度を'accuracy'の名前でログをとる。
# 学習に用いるオプティマイザを返す関数を書く。
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.hparams.lr)
次に、ファインチューニングの設定を行います。今回はPyTorch LightningのTrainerクラスを用いて学習をします。学習に必要なエポック数・チェックポイントなどを設定します。
# 学習時にモデルの重みを保存する条件を指定
checkpoint = pl.callbacks.ModelCheckpoint(
monitor='val_loss',
mode='min',
save_top_k=1,
save_weights_only=True,
dirpath='model/',
)
# 学習の方法を指定
trainer = pl.Trainer(
gpus=1,
max_epochs=10,
callbacks = [checkpoint]
)
この条件をもとにファインチューニングを行います。今回日本語の事前学習モデルはcl-tohoku/bert-base-japanese-whole-word-maskingを使いました。また学習率は1e-5としました。今回ハイパラのチューニングはしていないので、興味のある方は色々試してみてください。
# PyTorch Lightningモデルのロード
model = BertForSequenceClassification_pl(
'cl-tohoku/bert-base-japanese-whole-word-masking', num_labels=2, lr=1e-5
)
# ファインチューニングを行う
trainer.fit(model, dataloader_train, dataloader_val)
ファインチューニングを行ったモデルで予測を行いました。
test = trainer.test(dataloaders=dataloader_test)
print(f'Accuracy: {test[0]["accuracy"]:.2f}')
accuracyを確認してみると0.83であることがわかりました。混同行列は次のようになりました。

ポシティブネガティブ共にしっかりと予測できていることがわかります。
最後に分類に失敗したレビューをいくつか抽出してみました。
肯定的なレビューを否定的と誤判定した例を挙げます。
著者が産業再生機構での経験や ⻑いコンサル経験から到達した経営哲学がメインの本もう少し実際の再生現場での話も交えて欲しかった気もするがこれはこれで満足個人的に最も印象に残ったくだりを一つ以下は著者がバブル後の不景気に正社員の雇用を守るために 新卒採用の抑制と非正規雇用の増加で乗り切った日本企業への苦言である 『日本では多くの企業が, 「人は大事」といってきた. しかしそれは, 企業の中にいる人は大事, と言う意味だった. それがこの時, 明らかになった. 企業の外にいる人間は, ちっとも大事ではなかったのだ. 「人間尊重」などという崇高な理念で経営をしていたわけでは決してなかった. 』
「これはこれで満足」といった表現が曖昧であったり、引用部分が否定的な内容のためそれに引っ張られたのではないかと考えることができそうです。
否定的なレビューを肯定的と誤判定した例を挙げます。
バブルっぽい雰囲気の中ならそれほど違和感がないだろうけど,現時点では「何で今の時期に?」と思えるような株本.売りは軽薄さ.株式投資を会社の所有権の売買ではなくギャンブルと割り切って濃い絵柄の漫画で説明するという内容です. 軽薄ではあるけど,軽薄な内容をマトモな内容のように描いているのではなく軽薄さを強調しているあたりに妙な好感を覚えました.
これはラベル通り判別するのは難しいですね。
今回実装したコードはこちらにあります。共有用に書いていたものではないので汚いです。
PATHを書き換えると動かせると思います。
パラメータを変えるなどして遊んでみてください。
まとめ
いかがでしたか?BERTやはり強いですね。
今回はAmazonレビューでしたが他にも感情分析などにも使えるのでぜひ遊んでみてください。
またこの記事は、僕が所属している 「AI・機械学習を学ぶオンラインコミュニティAcademiX」 のリレー記事です。
AIについて深く学びたい方はぜひコミュニティに参加してください!
Discussion