世界基盤モデル「Cosmos」のAutoregressiveを動かしてみた
Cosmosとは
2025年1月6日,CES 2025の基調講演で,NVIDIAは,Cosmosを発表しました.
Cosmosは自動運転車やロボットなどのフィジカルAI開発を促進するために構築された最先端の生成世界基盤モデル(World Foundation Models; WFM)に加えて
- 高性能なビジュアルトークナイザ
- 有害なテキストや画像を軽減するように設計されたガードレール
- NVIDIA AI および CUDA® アクセラレーテッド データ処理パイプライン
から構成されています.
Cosmos Autoregressive
Cosmos自己回帰モデルは,事前学習されたWFMです.ビデオや画像入力からビデオシーケンスを予測して,高速に生成することができます.また,モデルは,NVIDIA Open Modelライセンス契約に基づき,商用利用が可能です.
Video2Worldモデルのアーキテクチャは次の図[1]のようになっています.

自己回帰Video2Worldモデルのアーキテクチャ
このモデルは、入力された動画を Cosmos-1.0-Tokenizer-CV8x8x8 のエンコーダーを通じて処理し,潜在表現を取得します。その後,これらの表現にガウスノイズを付加します.次に,これらの表現を 3Dパッチ化プロセス を使用して変換します.
潜在空間では,アーキテクチャは以下を繰り返すブロックを適用します:
- self-attention
- 入力テキストを統合するcross-attention
- フィードフォワード型MLP層
これらは、特定の時刻における適応型レイヤーノーマライゼーション(スケール,シフト,ゲートによる調整)によってモジュレーションされます.最後に、Cosmos-1.0-Tokenizer-CV8x8x8 のデコーダーが,潜在表現から最終的な動画出力を再構築します.詳しくは,こちらのスライドがまとまっているので,参考にしてください.
Cosmos 1.0では,次の4つのモデルが提供されています.
- Cosmos-1.0-Autoregressive-4B
- Cosmos-1.0-Autoregressive-5B-Video2World
- Cosmos-1.0-Autoregressive-12B
- Cosmos-1.0-Autoregressive-13B-Video2World
今回はCosmos-1.0-Autoregressive-4Bを動かしてみようと思います.このモデルでは,テキストの説明と動画(mp4)を入力すると,入力動画最初の9フレームに条件づけられた,24フレームの動画が出力されます.
Cosmos-1.0-Autoregressive-4Bを動かしてみる
筆者の環境は次のとおりです.
- Ubuntu 24.04 LTS
- CUDA 11.7
- NVIDIA RTX A6000
モデルはHugging Face上にあるものを使います.
まず,GitHubからCosmosをクローンしてきます
git clone https://github.com/NVIDIA/Cosmos.git
cd Cosmos
クローンができるとDockerfileがあると思うので,それをもとにDockerで環境構築します(ちなみに筆者はrootless Dockerで検証していますが,特に関係はないと思うので,触れません).
docker build -t cosmos .
次に,Dockerコンテナを起動して,アタッチします.
docker run -d --name cosmos_container --gpus all --ipc=host -it -v $(pwd):/workspace cosmos
docker attach cosmos_container
以降作業はすべてコンテナの中で行います.HFを使うので,まずログインしてください.
huggingface-cli login
次に,モデルをダウンロードします.
PYTHONPATH=$(pwd) python cosmos1/scripts/download_autoregressive.py --model_sizes 4B
chekpointsが結構大きいので,ダウンロードに時間がかかります.ストレージに余裕があることを確認してください.--checkpoint_dir <path/to/dir>を追加することで,ダウンロード先を指定できそうです(未検証).こんな感じのファイルがダウンロードできていたら成功です.tree checkpoints/とかで確認してください.
checkpointsディレクトリの構成
checkpoints/
├── Cosmos-1.0-Autoregressive-4B
│ ├── model.pt
│ └── config.json
├── Cosmos-1.0-Tokenizer-CV8x8x8
│ ├── decoder.jit
│ ├── encoder.jit
│ └── mean_std.pt
├── Cosmos-1.0-Tokenizer-DV8x16x16
│ ├── decoder.jit
│ └── encoder.jit
├── Cosmos-1.0-Diffusion-7B-Decoder-DV8x16x16ToCV8x8x8
│ ├── aux_vars.pt
│ └── model.pt
└── Cosmos-1.0-Guardrail
├── aegis/
├── blocklist/
├── face_blur_filter/
└── video_content_safety_filter/
これで環境構築は完了です.早速デモを動かしてみましょう.
CUDA_VISIBLE_DEVICES=0 PYTHONPATH=$(pwd) python cosmos1/models/autoregressive/inference/base.py \
--input_type=video \
--input_image_or_video_path=cosmos1/models/autoregressive/assets/v1p0/input.mp4 \
--video_save_name=Cosmos-1.0-Autoregressive-4B \
--ar_model_dir=Cosmos-1.0-Autoregressive-4B \
--top_p=0.8 \
--temperature=1.0
--video_save_nameにファイルが出力されます.そんなに時間はかかりませんが気長に待ちましょう.--top_pや--temperatureを変更することで,出力結果が変わります.--top_pはトークンの確率の上位何%を使うか,--temperatureは確率分布のソフトマックス温度です.また,--input_image_or_video_pathが入力ファイルなので,使ってみたい動画を指定して遊んでみましょう.入力動画は1024x640の解像度で,9フレーム以上ある必要があります.
適当にカメラフォルダにあった動画を入れてみました.

入力動画
出力結果はこんな感じです.
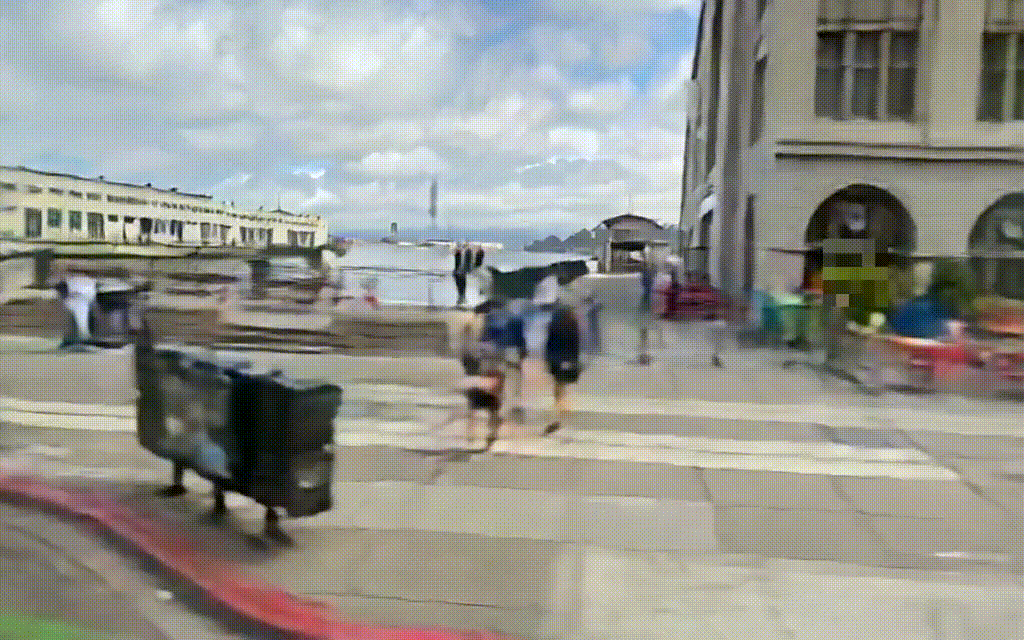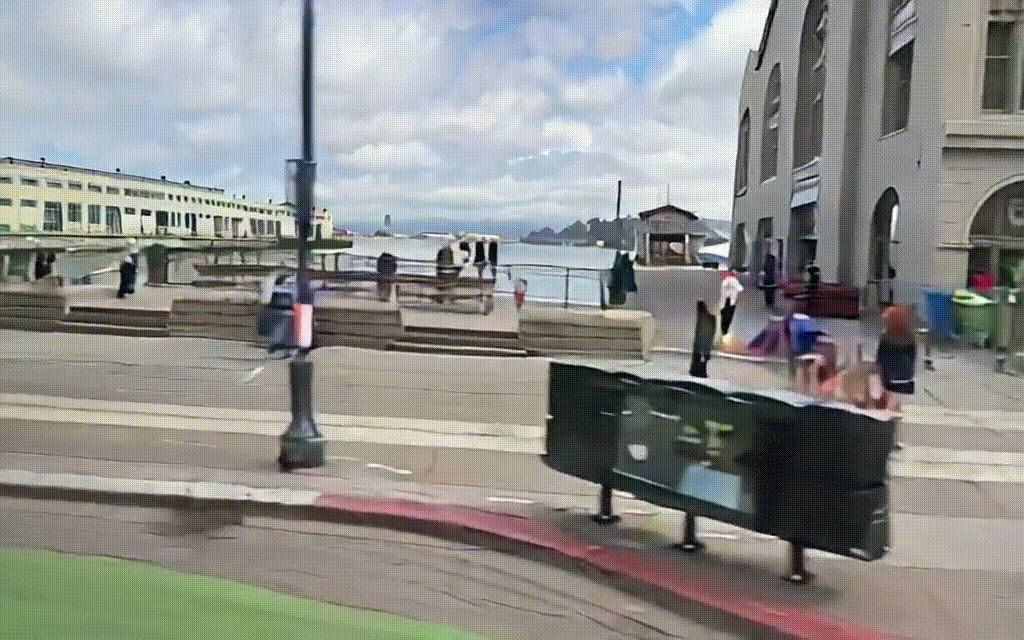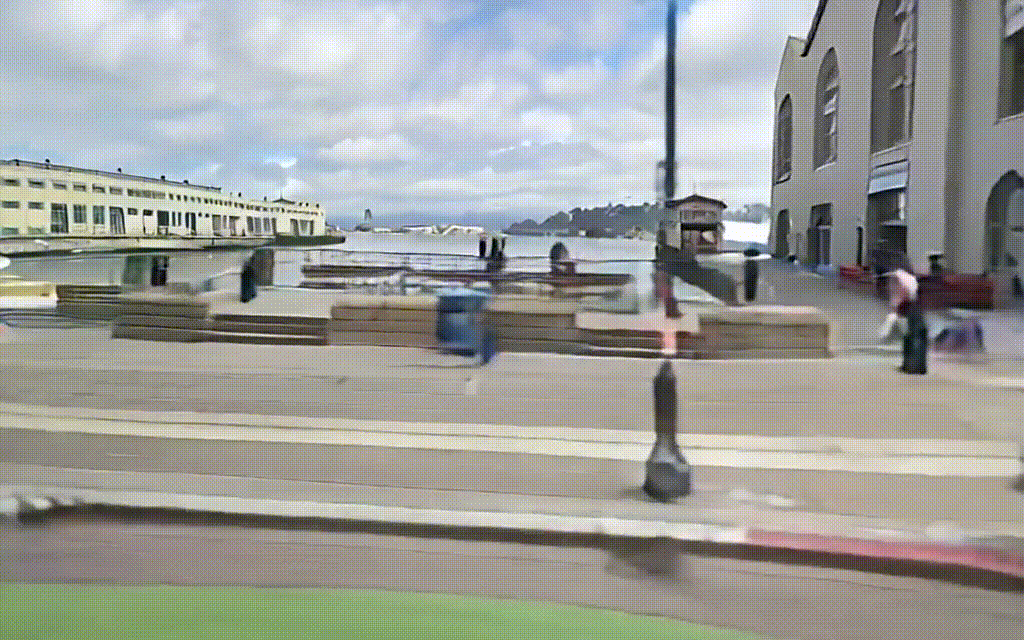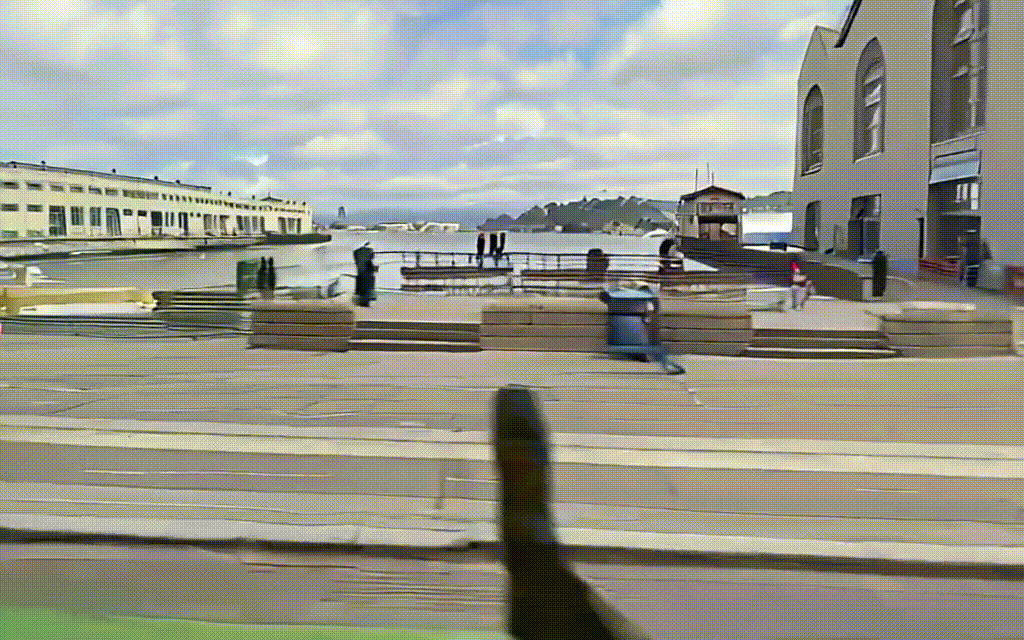
出力動画
粗さはあるもののGTと比較してみても,なかなかいい感じに出力されていると思います.
まとめ
今回はNVIDIAのCosmosを動かしてみました.本当は5Bや12Bのworld2vecも動かしてみたかったのですが,容量が大きすぎて断念しました.生成は良さそうではあるものの,物理法則を考慮していなかったりとネックな点はあるかなと思います.また,自己回帰以外にも拡散モデルもあるので,動かしてみようと思います.
-
Agarwal, Niket, et al. "Cosmos world foundation model platform for physical ai." arXiv preprint arXiv:2501.03575 (2025). ↩︎
Discussion