


はじめに
Hogetic Lab でデータエンジニアをしている大橋と申します。
データ基盤の構築や運用を進める中で、中間集計や機械学習モデルの実行など、様々な事情からバッチ処理が必要になるケースが多くあります。
データエンジニアの間では、バッチ処理用のワークフローエンジンとして、Airflow が世界的にデファクトスタンダードとなっていますが、システムの構成が複雑で、マネージドサービスを利用してもある程度のインフラコストが必要です。
そのため、ミッションクリティカルでない場合、つまりバッチ処理が停止または失敗した場合に翌日に再実行すれば問題ないようなケースでは、弊社では構成がシンプルでコストも抑えられる Digdag を多用しています。
しかし、近年 Digdag のリリースが年に1度となり、開発が落ち着いてきたため、最新のワークフローエンジンの動向を調査することにしました。
ワークフローエンジンはプラグイン形式で外部サービスと連携可能です。その中でも、kestra は公式ページによると 490 以上のプラグインを持ち、最近注目の ChatGPT などのLLMとも標準で連携できるため、試してみました。
kestra の Github リポジトリ
kestra 公式ページ
動作確認
環境準備
今回はテスト環境のため、docker compose を利用して構築しました。
環境は以下の通り簡単に立ち上がります。
git clone git@github.com:kestra-io/kestra.git
cd kestra
docker compose up -d
docker compose のファイルを見ていただくとわかりますが、サーバーとデータストアから構成されているため、本番運用を意識した構成をとるのもそこまで難しくないかと思います。
テストワークフローの実行
デフォルトでテスト用のワークフローが存在しているため、はじめにそれを試して行きたいと思います。
ワークフローの定義は Yaml フォーマットで定義する形式になっています。
これは、普段自分が利用している Digdag と同じため読みやすいと感じました。また、非エンジニアでもとっつきやすいのではないかと思いました。
id: hello_world
namespace: tutorial
description: Hello World
inputs:
- id: user
type: STRING
defaults: Rick Astley
tasks:
- id: first_task
type: io.kestra.plugin.core.debug.Return
format: thrilled
- id: second_task
type: io.kestra.plugin.scripts.shell.Commands
commands:
- sleep 0.42
- echo '::{"outputs":{"returned_data":"mydata"}}::'
- id: hello_world
type: io.kestra.plugin.core.log.Log
message: |
Welcome to Kestra, {{ inputs.user }}!
We are {{ outputs.first_task.value}} to have You here!
triggers:
- id: daily
type: io.kestra.plugin.core.trigger.Schedule
disabled: true
cron: "0 9 * * *"
スケジュール実行
まず、スケジュール実行を試して見ます。
スケジュール実行は triggers という設定箇所で設定します。
デフォルトの状態では disabled になっているため、項目を削除してスケジュール実行を有効にし、実行したいタイミングを cron に設定します。
今回は、日本時間の夜 8 時に実行されるように設定を修正しました。
triggers:
- id: daily
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 11 * * *"
無事に設定した時間にワークフローが実行されることが確認できます。
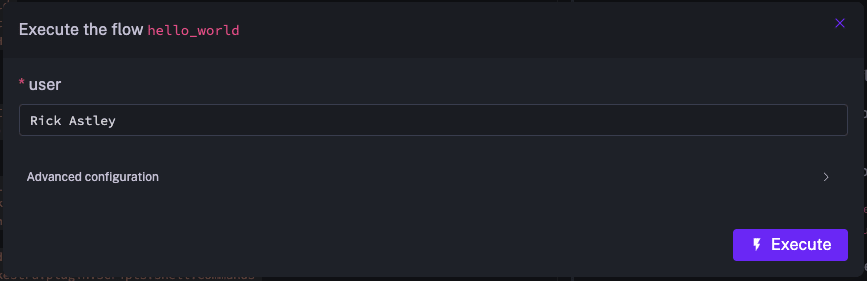
即時実行
次に手動での即時実行も試して見ます。
Yaml のなかに inputs という項目があり、手動でのアドホック実行時にパラメータを与えてスケジュール実行時とは動作を変更することができるようです。
この機能はパイプライン修正時のテスト実行でデータの書き込み先をテスト用のテーブルに変更したりなど、ワークフローの設計により様々な使い方ができそうだと感じました。
バックフィル
その他にもデータ基盤の運用を実施していると、バッチ処理の集計などの誤りが見つかった場合には過去のデータを含めて再集計が必要になることがあります。
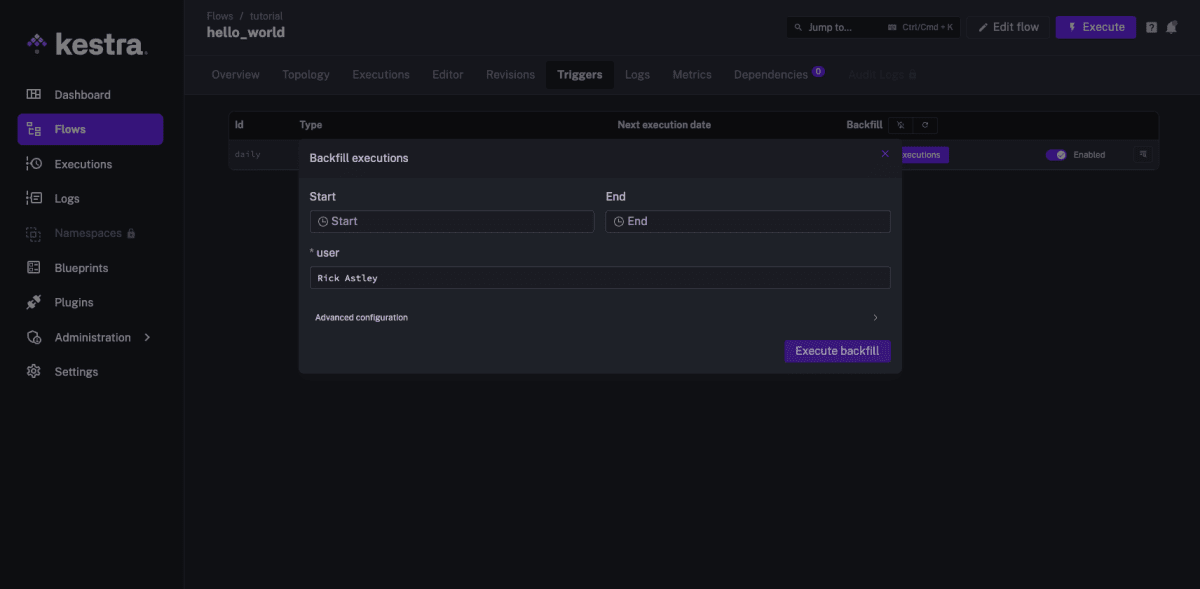
そういったケースで過去の日付のバッチ処理を実行することをバックフィルと呼ぶのですが、バックフィルのやり方についても確かめてみました。
バックフィルを実施したいワークフローの Triggers タブに Backfill executions というボタンがあり、 Web UI 上から日付を指定して実行することができました。
その他の実行方式について
その他にも、kestra では Pub/Sub などのイベントをトリガーに実行したり、API 経由でワークフローを実行することもできます。
そのため、kestra をバッチ処理の実行基盤としてその他のシステムからワークフローを呼び出すことも用意に実行できそうです。
LLM 連携について
次に本題の LLM との連携を試して見たいと思います。
近年ではデータ基盤に保存されたデータから LLM を利用して示唆出しを実施するケースも増えてきています。
そこで、弊社でもデータ基盤として利用している BigQuery のデータと OpenAI の ChatGPT を連携させるワークフローを作成してみたいと思います。
今回作成するワークフローで利用する kestra のプラグインのドキュメントは以下になります。
これらを利用して、BigQuery に保存したプロンプトをそのまま実行するワークフローを作成してみたいと思います。
実際のユースケースでは BigQuery から取得したデータをプロンプトに埋め込んで実行することになると思ますが。
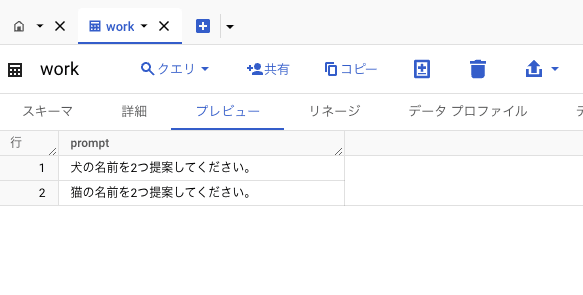
しかし、今回は簡単のために BigQuery のテーブルにプロンプトを保存しておき、それらを読み込んで順番に実行するワークフローを作成してみたいと思います。
事前に以下の様なテーブルを作成しておきました。
次に、BigQuery のデータを取得してそのデータを別のワークフローの入力値とする親ワークフローを作成します。
このワークフローは以下のような動作をします。
-
id:query_bqのタスクで BigQuery からプロンプトを取得します。取得したデータはstore: trueを設定されていることでoutputsというデータ保存領域に保持されるようになります。 - 1 で保存した
ouputsのデータを 1 行ずつllm_flowというワークフローに渡して実行します。
id: my_ai_test
namespace: test
labels:
env: dev
tasks:
- id: query_bq
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
SELECT prompt FROM test_ohashi_us.work
store: true
- id: each_llm_flow
type: io.kestra.plugin.core.flow.ForEachItem
items: "{{ outputs.query_bq.uri }}"
flowId: llm_flow
namespace: test
inputs:
string_input: "{{ read(taskrun.items) }}"
triggers:
- id: daily
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 9 * * *"
最後に親ワークフローで起動する llm_flow という文字列入力の引数を受け取って ChatGPT にプロンプトを実行するワークフローを作成します。
このワークフローでは以下のような動作をします。
-
id:completionのタスクで ChatGPT にプロンプトを実行します。 - 1 の結果をログに出力します。
id: llm_flow
namespace: test
labels:
env: dev
project: myproject
inputs:
- id: string_input
type: STRING
defaults: '{prompt:"日本の首都を教えて下さい。"}'
tasks:
- id: completion
type: io.kestra.plugin.openai.ChatCompletion
apiKey: "ChatGPT の API キーを記載"
model: gpt-3.5-turbo-0613
prompt: '{{ inputs.string_input | replace({"{":"","prompt":"","}":"","\"":""})}}'
- id: print_response
type: io.kestra.plugin.core.log.Log
message: "{{outputs.completion.choices[0].message.content}}"
上記をそれぞれ保存します。
そして、ワークフローを実行した結果が以下になります。
今回はログに結果を出力していますが、出力先をワークフローの中で制御することでいろいろなことに利用できそうです。

結論
プラグインが充実していてセットアップした状態でデータを OpenAI などの LLM と連携できるなど、モダンな機能が充実しており更に調査したいと思えました。
最近では Dify などのツールも登場しており、ローコードで LLM アプリケーションを作成することが出来るようになってきています。
一方で、バッチ処理の中でデータを LLM と連携するケースやデータ加工などを含むケースにおいてはスクリプトの組み込みや分岐などを簡単に処理できるワークフローエンジンを利用することがメリットになる場合もありそうに感じました。
そういった意味でも、kestra は今後も注目して動向を追っていきたいと思います。

Discussion