Google Cloud Champion Innovators Advent Calendar 2024 の 12 日目の記事です。
はじめに
LLM が広く普及し、活用範囲が急速に拡大してきたことで、ツール連携機能を活用した AI エージェントを構築する機会も増えてきています。このような LLM とツールの連携により、チャットインターフェースから様々なシステムやサービスを制御・自動化できるようになりました。
しかし、AI エージェントの開発には2つの困りごとがあると感じています。1つ目は、複雑な指示を処理するために必要な高性能モデルの応答速度が遅い点、2つ目は複数のプロジェクトでツールを再利用する際の実装効率の問題です。
本記事では、これらに対する解決策の一例を紹介します。LLM から BigQuery を操作するユースケースにおいて、応答速度が遅い点については Gemini 2.0 Flash を利用して検証を高速化し、ツールの再利用については、MCP(Model Context Protocol)を活用してツール実装を効率化することを試みます。
Gemini 2.0 Flash とは
Gemini 2.0 Flash は、2024 年 12 月に発表された Gemini シリーズの最新モデルです。発表によると、これまでの Gemini 1.5 Flash と同様に高速でありながら、多くのベンチマークスコアで Gemini 1.5 Pro を上回っていることがわかります。また、マルチモーダル理解、複雑な指示の実行および計画、ツール連携機能が向上し、より優れたエージェント体験をサポートするとのことで、本記事でのユースケースにぴったりのモデルと考えられます。その他、画像生成や TTS にも今後対応予定との記述もあり、ますます期待が膨らみます。
- Introducing Gemini 2.0: our new AI model for the agentic era
- The next chapter of the Gemini era for developers
- Gemini 2.0 (experimental)
MCP とは
MCP は様々なツールやデータソースと LLM の間の標準プロトコルを提供する意図で開発されたもので、デバイスと周辺機器を接続する時の USB-C ポートのような役割を果たすと紹介されています(Model Context Protocol)。
また、すでに様々な記事でも言及されているように、ツール呼び出しのインターフェースを標準化するためにも使えるものです。
本記事で試すこと
ツール連携を試す時には、LangChain を利用することでモデルやパラメータを簡単に設定でき、ツール実装を比較的シンプルに記述することができます(Build an Agent)。
LangChain を用いる場合、各ツールの処理を個別の関数として記述する必要があります。これは、似たような処理であっても、開発者間で共有・再利用する際に手間がかかります。そこで、MCP を利用することによって、下記のアーキテクチャ図のように LLM-ツール間のインターフェースが共通化され、開発者間での共有がスムーズになり既存ツールの再利用が容易になると考えられます。
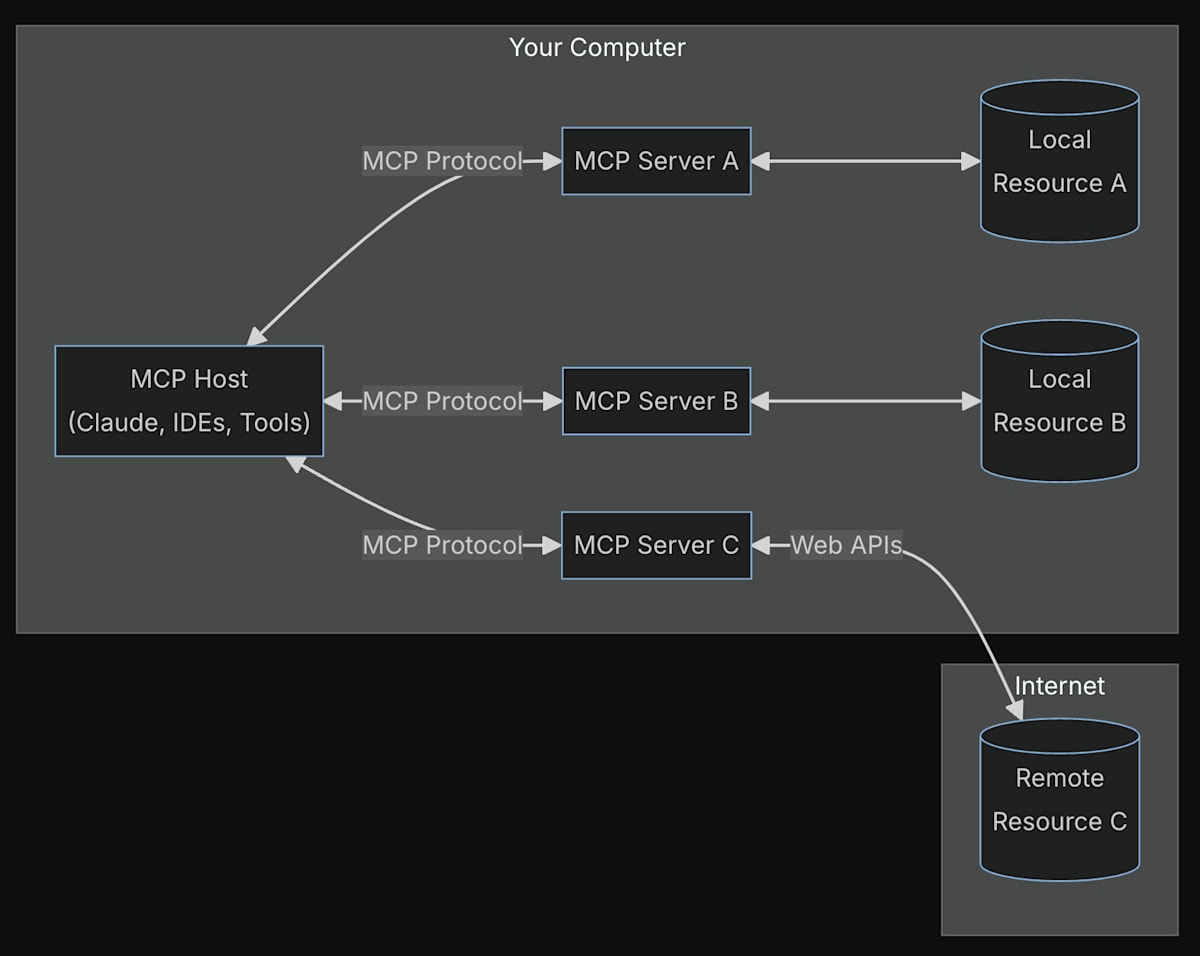
本記事では、ホスト側を LangChain を利用して実装しながら、ツール実装をさらにポータブルにするために、MCP サーバーの処理を API 化して分離します。これにより、ツールの再利用性が向上し(クラウド上に API を立てるetc.)、ホスト側とサーバー側で分離することで環境管理・クレデンシャル管理などをシンプルに保つことにつながります。このアーキテクチャは以下のようになります。
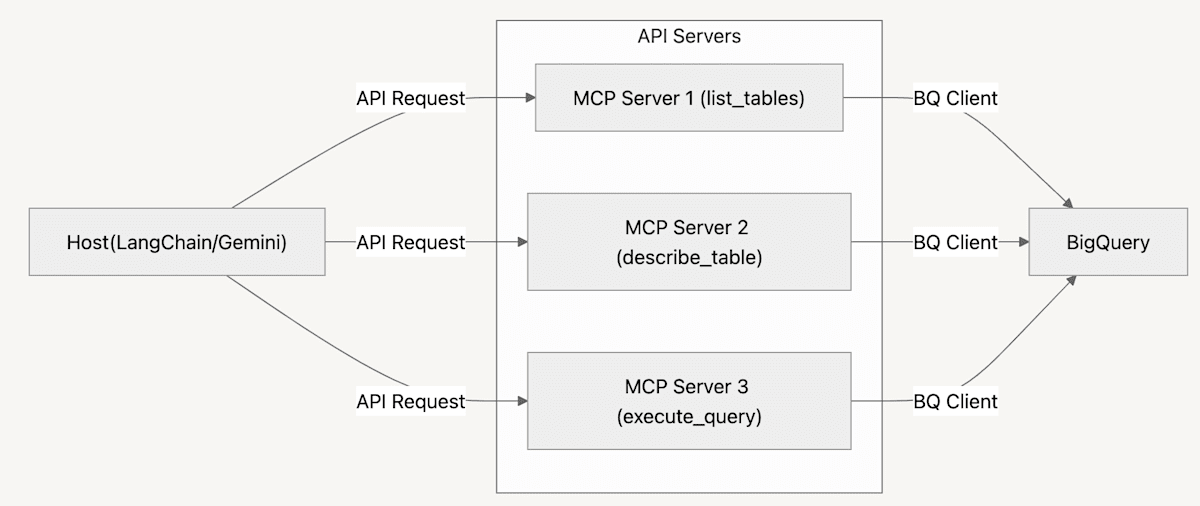
本記事で試したアーキテクチャ
実装例
ホスト側の実装
Host 側では、LangChain と Gemini を組み合わせ、MCP サーバーと連携する処理を実装しています。チャット UI としては、Streamlit を利用しています。
下記がチャットおよびエージェント部分の実装で、全体的に標準的な書き方かと思います。LangChain を用いると、モデルの指定部分のみを変更するだけで切り替えられるので、最新の Gemini 2.0 Flash を使う場合でも、llm = ChatVertexAI(model="gemini-2.0-flash-exp") と記述するだけで済みます。Vertex AI から利用するために ChatVertexAI を使っていますので Google Cloud の認証を通しておく必要があります(参考)。システムプロンプトは目的に応じてさらに詳しく記述する必要がありますが、ここでは簡易的な内容に留めておきます。
チャットおよびエージェント部分のコード
import streamlit as st
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.prompts import MessagesPlaceholder, ChatPromptTemplate
from langchain_core.messages import AIMessage, HumanMessage
from langchain_community.callbacks import StreamlitCallbackHandler
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
import vertexai
from langchain_google_vertexai import ChatVertexAI
from mcp_client.tools.manage_bigquery import list_tables, describe_table, execute_query
CUSTOM_SYSTEM_PROMPT = """
あなたは、ユーザーのリクエストに基づいて、ツールを用いて情報を取得してユーザーを支援するアシスタントです。
ユーザーのコメントから判断して、もし利用可能なツールがある場合は、
そのツールを使用して、取得内容をわかりやすい表現や出力形式にした上でユーザーに提供してください。
もし利用可能がない場合はその旨を伝えながら、自然に回答してください。
ユーザーが使用する言語で回答するようにしてください。
"""
def initialize():
st.header("Gemini-BigQuery Agent")
vertexai.init(project="hogetic-lab-datascience-test", location="us-central1")
return StreamlitChatMessageHistory(key="chat_messages")
def create_agent():
tools = [list_tables, describe_table, execute_query]
prompt = ChatPromptTemplate.from_messages([
("system", CUSTOM_SYSTEM_PROMPT),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
llm = ChatVertexAI(temperature=0, model="gemini-2.0-flash-exp")
agent = create_tool_calling_agent(llm, tools, prompt)
return AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
memory=None
)
def main():
chat_history = initialize()
agent = create_agent()
for chat in chat_history.messages:
st.chat_message(chat.type).write(chat.content)
if prompt := st.chat_input(placeholder="どんなテーブルがあるか教えてください"):
st.chat_message("user").write(prompt)
with st.chat_message("assistant"):
st_cb = StreamlitCallbackHandler(st.container(), expand_new_thoughts=True)
response = agent.invoke(
{"input": prompt, "chat_history": chat_history.messages},
{"callbacks": [st_cb]},
)
st.write(response["output"])
chat_history.add_messages(
[
HumanMessage(content=prompt),
AIMessage(content=response["output"]),
]
)
if __name__ == "__main__":
main()
次にツール連携部分のコードですが、@tool デコレータを付記した関数を通して行います。この関数は API エンドポイントから MCP サーバーと通信を行います。関数の処理は単純ですが、LLM がツールのコンテキストを正しく理解できるように、関数の description を明確に記述する必要があります。
ツール連携部分のコード
import requests
from langchain_core.tools import tool
from langchain_core.pydantic_v1 import BaseModel, Field
class BQListTablesRequest(BaseModel):
datasets_filter: list[str] = Field(
description="テーブル一覧を取得したいデータセット名。データセットを絞りたい場合に使用し、特に絞らない場合は空のリスト `[]` と指定してください。"
)
@tool(args_schema=BQListTablesRequest)
def list_tables(datasets_filter: list[str]) -> str:
"""
BigQueryのテーブル一覧を取得するためのツールです。
BigQueryを使った他ツールの実行に先立って、どのようなテーブルが存在するかを確認するために使用してください。
"{dataset_id}.{table_id}" という記述で、テーブル名の一覧が返されます。
"""
url = "http://mcpserver:8000/bigquery/list-tables/"
payload = {"datasets_filter": datasets_filter}
response = requests.get(url, json=payload)
response.raise_for_status()
return response.text
class BQDescribeTableRequest(BaseModel):
table_name: str = Field(description="説明を取得したいテーブルの名前")
@tool(args_schema=BQDescribeTableRequest)
def describe_table(table_name: str) -> str:
"""
BigQueryのテーブル情報を取得するためのツールです。
クエリの実行に先立って、テーブル情報を取得・確認するために使用してください。
テーブルのスキーマ情報が返されます。
"""
url = "http://mcpserver:8000/bigquery/describe-table/"
payload = {"table_name": table_name}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.text
class BQExecuteQueryRequest(BaseModel):
query: str = Field(description="実行したいクエリ")
@tool(args_schema=BQExecuteQueryRequest)
def execute_query(query: str) -> str:
"""
BigQuery でクエリを実行するためのツールです。
このツールの実行の前には必ずテーブル一覧やテーブル情報を取得・確認し、無駄なクエリ実行を避けてください。
クエリの実行結果は、行ごとに JSON を含む list 形式のデータが返されます。
"""
url = "http://mcpserver:8000/bigquery/execute-query/"
payload = {"query": query}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.text
LangChain によるエージェント実装については、ML_Bear 氏の書籍 などが詳しいのでぜひ参考にしてください。少し注意として、ここ最近はより柔軟なエージェント実装を行いたい場合に LangGraph も推奨されているようですので、必要に応じてその関連ドキュメントも参照ください。
- Build an Agent with AgentExecutor (Legacy)
- つくりながら学ぶ!生成AIアプリ&エージェント開発入門
- LangGraph
- How to migrate from legacy LangChain agents to LangGraph
サーバー側の実装
サーバー側では各ツールの処理の実態を含み、FastAPI を用いて API のエンドポイントを用意します。BigQuery へのアクセスは、今回は Awesome MCP Servers にまとめられていた MCP サーバーの1つである BigQuery MCP Server が使いやすそうだったため、こちらを若干変更した上で使用しました。エンドポイントとしては、BigQueryのテーブル一覧を取得する /bigquery/list-tables、テーブルのスキーマ情報を取得する /bigquery/describe-table、SQL クエリを実行する /bigquery/execute-query の3つを用意しています。
下記がエンドポイント部分のコードですが、MCP サーバーを呼ぶ処理は共通、エンドポイントごとにサーバー名や変数を切り替えるようになっています。
エンドポイント部分のコード
import asyncio
from typing import Any
from fastapi import APIRouter
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from app.schemas import BQListTablesRequest, BQDescribeTableRequest, BQExecuteQueryRequest
router = APIRouter()
async def async_request(name: str, server_command: str, server_script: str, req: Any = None):
server_params = StdioServerParameters(
command=server_command, args=server_script, env=None
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
result = await session.call_tool(
name=name,
arguments=req.dict() if req is not None else {},
)
return result.content[0].text
@router.get("/bigquery/list-tables")
def list_tables(req: BQListTablesRequest) -> str:
return asyncio.run(
async_request(
name="list-tables",
server_command="python",
server_script=["/src/app/bigquery_manager/server.py"],
req=req,
)
)
@router.post("/bigquery/describe-table")
def describe_table(req: BQDescribeTableRequest) -> str:
return asyncio.run(
async_request(
name="describe-table",
server_command="python",
server_script=["/src/app/bigquery_manager/server.py"],
req=req,
)
)
@router.post("/bigquery/execute-query")
def execute_query(req: BQExecuteQueryRequest) -> str:
return asyncio.run(
async_request(
name="execute-query",
server_command="python",
server_script=["/src/app/bigquery_manager/server.py"],
req=req,
)
)
MCP サーバー部分のコードは以下のようになります。前述の BigQuery MCP Server を活用したため実装の手間はほぼかかっていません。
MCP サーバー部分のコード
import os
from google.cloud import bigquery
import logging
import asyncio
from dotenv import load_dotenv
from mcp.server.models import InitializationOptions
import mcp.types as types
from mcp.server import NotificationOptions, Server
import mcp.server.stdio
from typing import Any
load_dotenv()
# Set up logging to both stdout and file
logger = logging.getLogger('mcp_bigquery_server')
handler_stdout = logging.StreamHandler()
handler_file = logging.FileHandler('/tmp/mcp_bigquery_server.log')
# Set format for both handlers
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler_stdout.setFormatter(formatter)
handler_file.setFormatter(formatter)
# Add both handlers to logger
logger.addHandler(handler_stdout)
logger.addHandler(handler_file)
# Set overall logging level
logger.setLevel(logging.DEBUG)
logger.info("Starting MCP BigQuery Server")
class BigQueryDatabase:
def __init__(self, project: str, location: str):
"""Initialize a BigQuery database client"""
if not project:
raise ValueError("Project is required")
if not location:
raise ValueError("Location is required")
self.client = bigquery.Client(project=project, location=location)
def execute_query(self, query: str, params: dict[str, Any] | None = None) -> list[dict[str, Any]]:
"""Execute a SQL query and return results as a list of dictionaries"""
logger.debug(f"Executing query: {query}")
try:
if params:
job = self.client.query(query, job_config=bigquery.QueryJobConfig(query_parameters=params))
else:
job = self.client.query(query)
results = job.result()
rows = [dict(row.items()) for row in results]
logger.debug(f"Query returned {len(rows)} rows")
return rows
except Exception as e:
logger.error(f"Database error executing query: {e}")
raise
def list_tables(self, datasets_filter: list[str] = None) -> list[str]:
"""List all tables in the BigQuery database"""
logger.debug("Listing all tables")
if datasets_filter:
datasets = [self.client.dataset(dataset) for dataset in datasets_filter]
else:
datasets = list(self.client.list_datasets())
logger.debug(f"Found {len(datasets)} datasets")
tables = []
for dataset in datasets:
dataset_tables = self.client.list_tables(dataset.dataset_id)
tables.extend([
f"{dataset.dataset_id}.{table.table_id}" for table in dataset_tables
])
logger.debug(f"Found {len(tables)} tables")
return tables
def describe_table(self, table_name: str) -> list[dict[str, Any]]:
"""Describe a table in the BigQuery database"""
logger.debug(f"Describing table: {table_name}")
parts = table_name.split(".")
if len(parts) != 2:
raise ValueError(f"Invalid table name: {table_name}")
dataset_id = parts[0]
table_id = parts[1]
query = f"""
SELECT ddl
FROM {dataset_id}.INFORMATION_SCHEMA.TABLES
WHERE table_name = @table_name;
"""
return self.execute_query(query, params=[
bigquery.ScalarQueryParameter("table_name", "STRING", table_id),
])
async def main(project: str, location: str):
logger.info(f"Starting BigQuery MCP Server with project: {project} and location: {location}")
#db = BigQueryDatabase(project, location, datasets_filter)
db = BigQueryDatabase(project, location)
server = Server("bigquery-manager")
# Register handlers
logger.debug("Registering handlers")
@server.list_tools()
async def handle_list_tools() -> list[types.Tool]:
"""List available tools"""
return [
types.Tool(
name="execute-query",
description="Execute a SELECT query on the BigQuery database",
inputSchema={
"type": "object",
"properties": {
"query": {"type": "string", "description": "SELECT SQL query to execute using BigQuery dialect"},
},
"required": ["query"],
},
),
types.Tool(
name="list-tables",
description="List all tables in the BigQuery database",
inputSchema={
"type": "object",
"properties": {},
},
),
types.Tool(
name="describe-table",
description="Get the schema information for a specific table",
inputSchema={
"type": "object",
"properties": {
"table_name": {"type": "string", "description": "Name of the table to describe (e.g. my_dataset.my_table)"},
},
"required": ["table_name"],
},
),
]
@server.call_tool()
async def handle_call_tool(
name: str, arguments: dict[str, Any] | None
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
"""Handle tool execution requests"""
logger.debug(f"Handling tool execution request: {name}")
try:
if name == "list-tables":
results = db.list_tables(arguments["datasets_filter"])
return [types.TextContent(type="text", text=str(results))]
elif name == "describe-table":
if not arguments or "table_name" not in arguments:
raise ValueError("Missing table_name argument")
results = db.describe_table(arguments["table_name"])
return [types.TextContent(type="text", text=str(results))]
if name == "execute-query":
results = db.execute_query(arguments["query"])
return [types.TextContent(type="text", text=str(results))]
else:
raise ValueError(f"Unknown tool: {name}")
except Exception as e:
return [types.TextContent(type="text", text=f"Error: {str(e)}")]
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
logger.info("Server running with stdio transport")
await server.run(
read_stream,
write_stream,
InitializationOptions(
server_name="bigquery",
server_version="0.2.0",
capabilities=server.get_capabilities(
notification_options=NotificationOptions(),
experimental_capabilities={},
),
),
)
if __name__ == "__main__":
asyncio.run(
main(
project=os.getenv("PROJECT_ID"), # project_id を指定する
location=os.getenv("LOCATION"), # location を指定する
)
)
利用例
エージェントの動作の様子が下記の画像になります(動画がサイズオーバーだったため画像になります)。サンプルデータとして、bigquery-public-data の google_trends データセット中のテーブルを、自分のプロジェクトの test_dataset データセットに置いて使用しています。システムプロンプトが簡易であるため改善の余地があったり出力結果も検証の余地がありますが、Gemini 2.0 Flash ならではの高速なレスポンスでサクサク進むのはかなり良い体感でした。また、これまで Gemini 1.5 Flash ではツール呼び出しが意図通りに動かないことがあったのですが、そういったことはなく意図通りに動作できています。
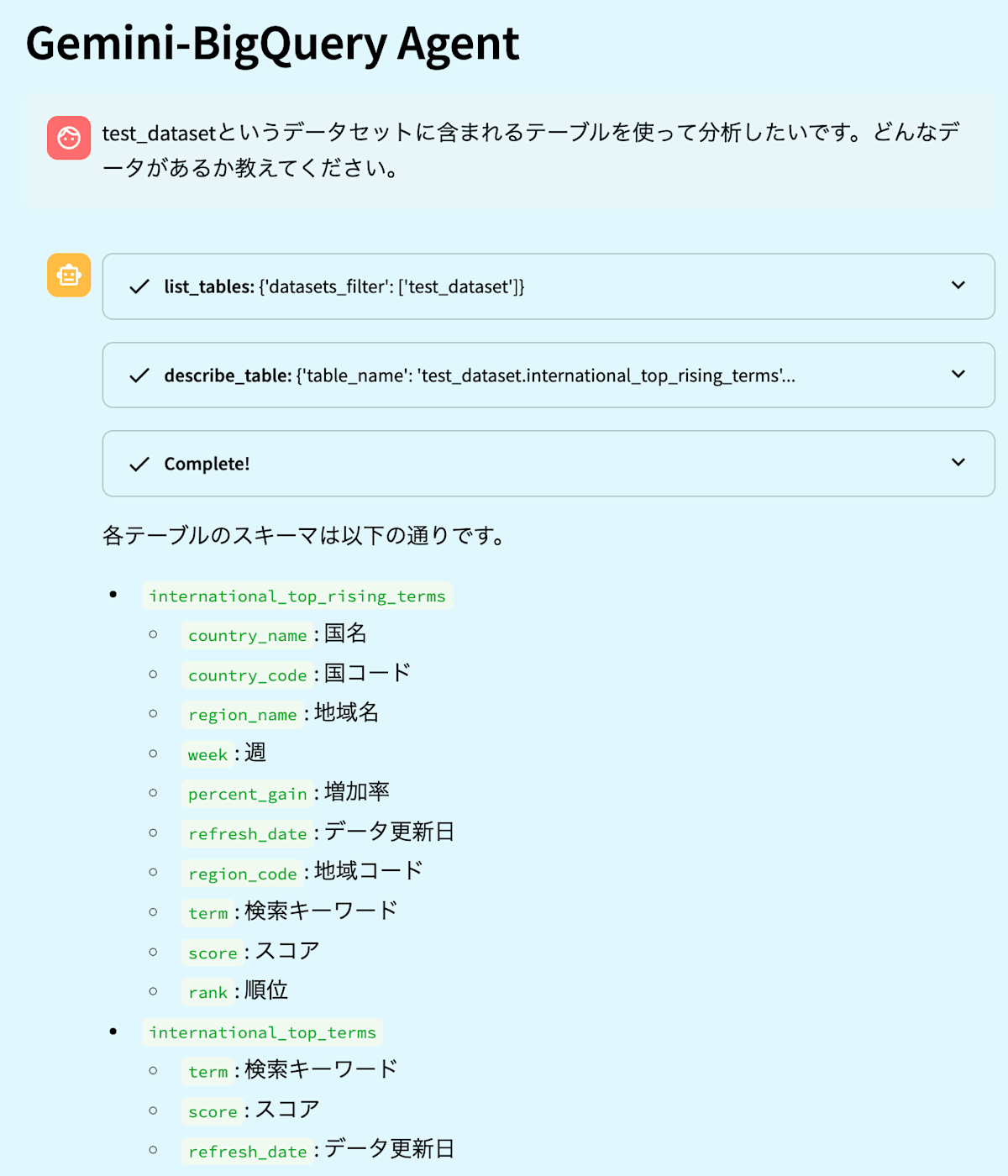
デモ画面1
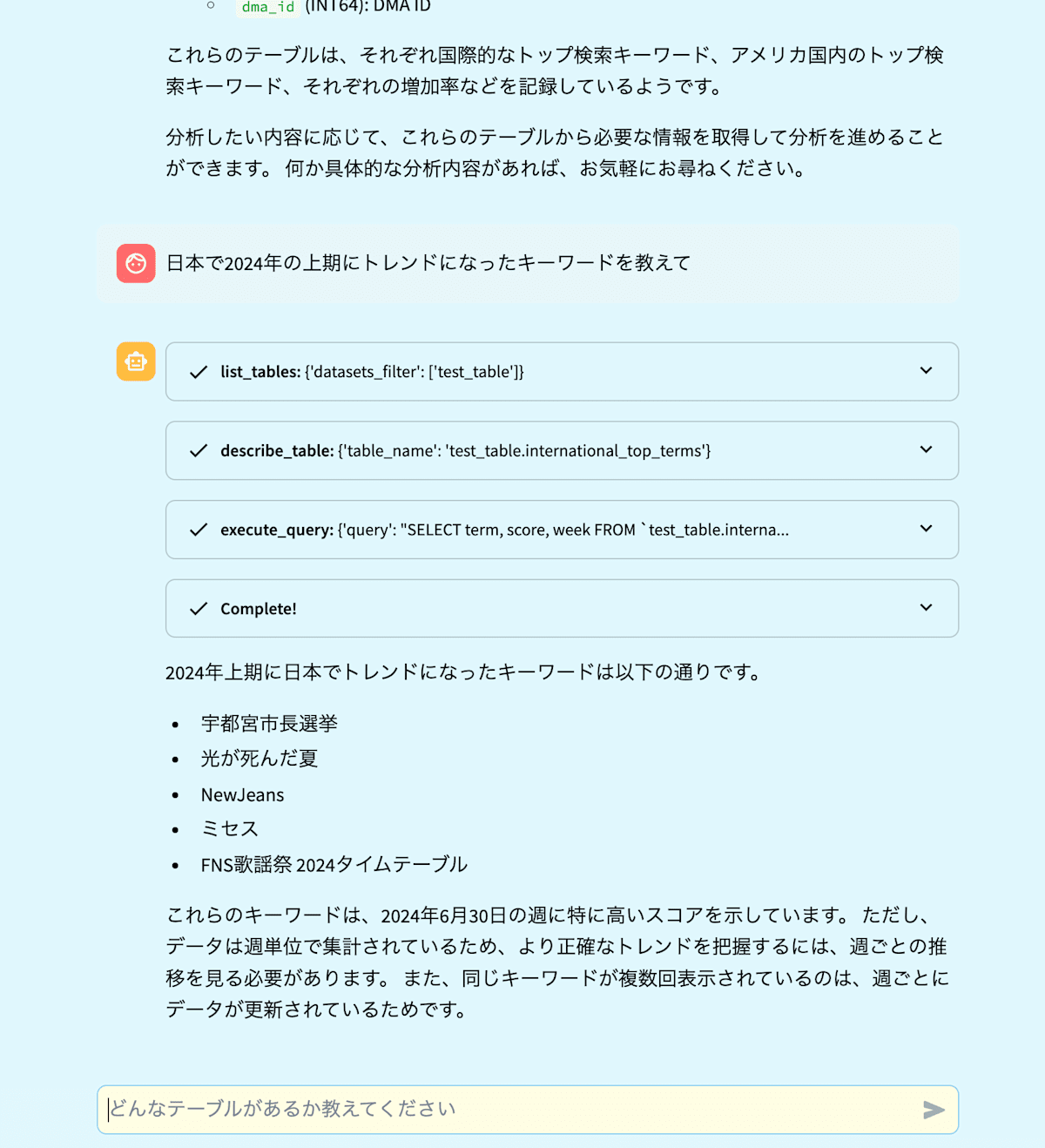
デモ画面2
まとめ
LLM から BigQuery を呼び出すユースケースについて、Gemini シリーズの最新モデルである Gemini 2.0 Flash および MCP を利用した実装例を紹介しました。Gemini 2.0 Flash の高速なレスポンスによりツール呼び出しを含む機能についても小気味よく検証を進められ、今後利用可能になる予定の画像生成や TTS も組合せてより多彩な応用が可能になると考えられます。また MCP によって、共有・転用をしやすいアーキテクチャが容易になるとともに、標準化の流れを活かした Awesome MCP Servers のようなツール実装の提供の場が増えることも期待されます。できることがさらに増えて楽しくなりますね!本記事が何かの役に立てば幸いです。

Discussion