Modalでostris/ai-toolkitのFlux LoRA Trainingを試す
Modal
サーバレスGPUクラウド。$30 / monthの無料枠があるのでこれを有効に使いたい
ostris/ai-toolkit
diffusion modelのtrainer.
FLUX.1 Kontext や Wan I2V のtrainingもできる
Modalもostris/ai-toolkit もあまり経験がないが、まずはFlux.1 devのLora作成対応をする。
READMEの方法そのままだとfile upload時に通信が止まってしまってうまくいかなかったため
run_modal.py をコピーしてrun_modal_docker.pyを作成し、最新のSDKとリポジトリ内のDockerfileを利用する形へ修正した。
modal_train_lora_flux_24gb.yaml
/config/examples/modal/modal_train_lora_flux_24gb.yaml を /config にコピーしてdatasetsのpathなどを修正。
またDockerfileの WORKDIR にあわせて pathを /root -> /app へ変更が必要だった
# L5-L9 付近
---
job: extension
config:
# this name will be the folder and filename name
name: "my_first_flux_lora_v1" # 適宜修正
process:
- type: 'sd_trainer'
# root folder to save training sessions/samples/weights
training_folder: "/app/ai-toolkit/modal_output" # must match MOUNT_DIR from run_modal.py
# L24 付近
datasets:
# datasets are a folder of images. captions need to be txt files with the same name as the image
# for instance image2.jpg and image2.txt. Only jpg, jpeg, and png are supported currently
# images will automatically be resized and bucketed into the resolution specified
# on windows, escape back slashes with another backslash so
# "C:\\path\\to\\images\\folder"
# your dataset must be placed in /ai-toolkit and /root is for modal to find the dir:
- folder_path: "/app/ai-toolkit/input/images" # 任意のpathへ
run_modal_docker.py
Dockerfileとlocal_dirの /config , /input/images をマウント、huggingface-secretを利用する変更を加えた
こちらもDockerfileの WORKDIR にあわせて MOUNT_DIR を /root -> /app へ変更が必要だった。
'''
ostris/ai-toolkit on https://modal.com
Run training with the following command:
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml
'''
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
import sys
import modal
from dotenv import load_dotenv
# Load the .env file if it exists
load_dotenv()
sys.path.insert(0, "/app/ai-toolkit")
# must come before ANY torch or fastai imports
# import toolkit.cuda_malloc
# turn off diffusers telemetry until I can figure out how to make it opt-in
os.environ['DISABLE_TELEMETRY'] = 'YES'
# define the volume for storing model outputs, using "creating volumes lazily": https://modal.com/docs/guide/volumes
# you will find your model, samples and optimizer stored in: https://modal.com/storage/your-username/main/flux-lora-models
model_volume = modal.Volume.from_name("flux-lora-models", create_if_missing=True)
# modal_output, due to "cannot mount volume on non-empty path" requirement
MOUNT_DIR = "/app/ai-toolkit/modal_output" # modal_output, due to "cannot mount volume on non-empty path" requirement
# define modal app
image = modal.Image.from_dockerfile("docker/Dockerfile").add_local_dir("config", "/app/ai-toolkit/config").add_local_dir("input/images", '/app/ai-toolkit/input/images')
# mount for the entire ai-toolkit directory
# example: "/Users/username/ai-toolkit" is the local directory, "/root/ai-toolkit" is the remote directory
# code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit") # コメントアウト
# create the Modal app with the necessary mounts and volumes
# app = modal.App(name="flux-lora-training", image=image, mounts=[code_mount], volumes={MOUNT_DIR: model_volume})
app = modal.App(name="flux-lora-training", image=image, volumes={MOUNT_DIR: model_volume})
# Check if we have DEBUG_TOOLKIT in env
if os.environ.get("DEBUG_TOOLKIT", "0") == "1":
# Set torch to trace mode
import torch
torch.autograd.set_detect_anomaly(True)
import argparse
from toolkit.job import get_job
def print_end_message(jobs_completed, jobs_failed):
failure_string = f"{jobs_failed} failure{'' if jobs_failed == 1 else 's'}" if jobs_failed > 0 else ""
completed_string = f"{jobs_completed} completed job{'' if jobs_completed == 1 else 's'}"
print("")
print("========================================")
print("Result:")
if len(completed_string) > 0:
print(f" - {completed_string}")
if len(failure_string) > 0:
print(f" - {failure_string}")
print("========================================")
@app.function(
# request a GPU with at least 24GB VRAM
# more about modal GPU's: https://modal.com/docs/guide/gpu
gpu="A100", # gpu="H100"
# more about modal timeouts: https://modal.com/docs/guide/timeouts
timeout=7200, # 2 hours, increase or decrease if needed
secrets=[modal.Secret.from_name("huggingface-secret")] # 追記
)
def main(config_file_list_str: str, recover: bool = False, name: str = None):
# convert the config file list from a string to a list
config_file_list = config_file_list_str.split(",")
jobs_completed = 0
jobs_failed = 0
print(f"Running {len(config_file_list)} job{'' if len(config_file_list) == 1 else 's'}")
for config_file in config_file_list:
try:
job = get_job(config_file, name)
job.config['process'][0]['training_folder'] = MOUNT_DIR
os.makedirs(MOUNT_DIR, exist_ok=True)
print(f"Training outputs will be saved to: {MOUNT_DIR}")
# run the job
job.run()
# commit the volume after training
model_volume.commit()
job.cleanup()
jobs_completed += 1
except Exception as e:
print(f"Error running job: {e}")
jobs_failed += 1
if not recover:
print_end_message(jobs_completed, jobs_failed)
raise e
print_end_message(jobs_completed, jobs_failed)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# require at least one config file
parser.add_argument(
'config_file_list',
nargs='+',
type=str,
help='Name of config file (eg: person_v1 for config/person_v1.json/yaml), or full path if it is not in config folder, you can pass multiple config files and run them all sequentially'
)
# flag to continue if a job fails
parser.add_argument(
'-r', '--recover',
action='store_true',
help='Continue running additional jobs even if a job fails'
)
# optional name replacement for config file
parser.add_argument(
'-n', '--name',
type=str,
default=None,
help='Name to replace [name] tag in config file, useful for shared config file'
)
args = parser.parse_args()
# convert list of config files to a comma-separated string for Modal compatibility
config_file_list_str = ",".join(args.config_file_list)
main.call(config_file_list_str=config_file_list_str, recover=args.recover, name=args.name)
launch
modal run --detach run_modal_docker.py --config-file-list-str=/app/ai-toolkit/config/modal_train_lora_flux_24gb.yaml
logs

Storage

DL
modal volume get flux-lora-models my_first_flux_lora_v1/my_first_flux_lora_v1.safetensors
コストは設定によっても変わってくると思うがA100 1000Stepsで $2 くらいの体感
Modalにhuggingfaceの環境変数を設定
Flux.1-dev モデルへのアクセスをリクエストする必要があるのでhuggingfaceでtokenを作成する(Readで良さそう)

cliから追加できる
modal secret create huggingface-secret HF_TOKEN=your_token_here

Flux1-dev2pro
ベースモデルにFinetuneされたFlux1-dev2proを利用したい。
ローカルに FLUX.1-dev と Flux-Dev2Pro を落としてFLUX.1-dev/transformerを置き換えれば良さそう
Discordでのai-toolkit作者ostris氏の見解では、あまり結果が良くなかったので対応していないと言うことらしい。
WebUI
ai-toolkitにはNext.jsベースのAI Toolkit UIとGradio UIとの2つWebUIが存在する模様
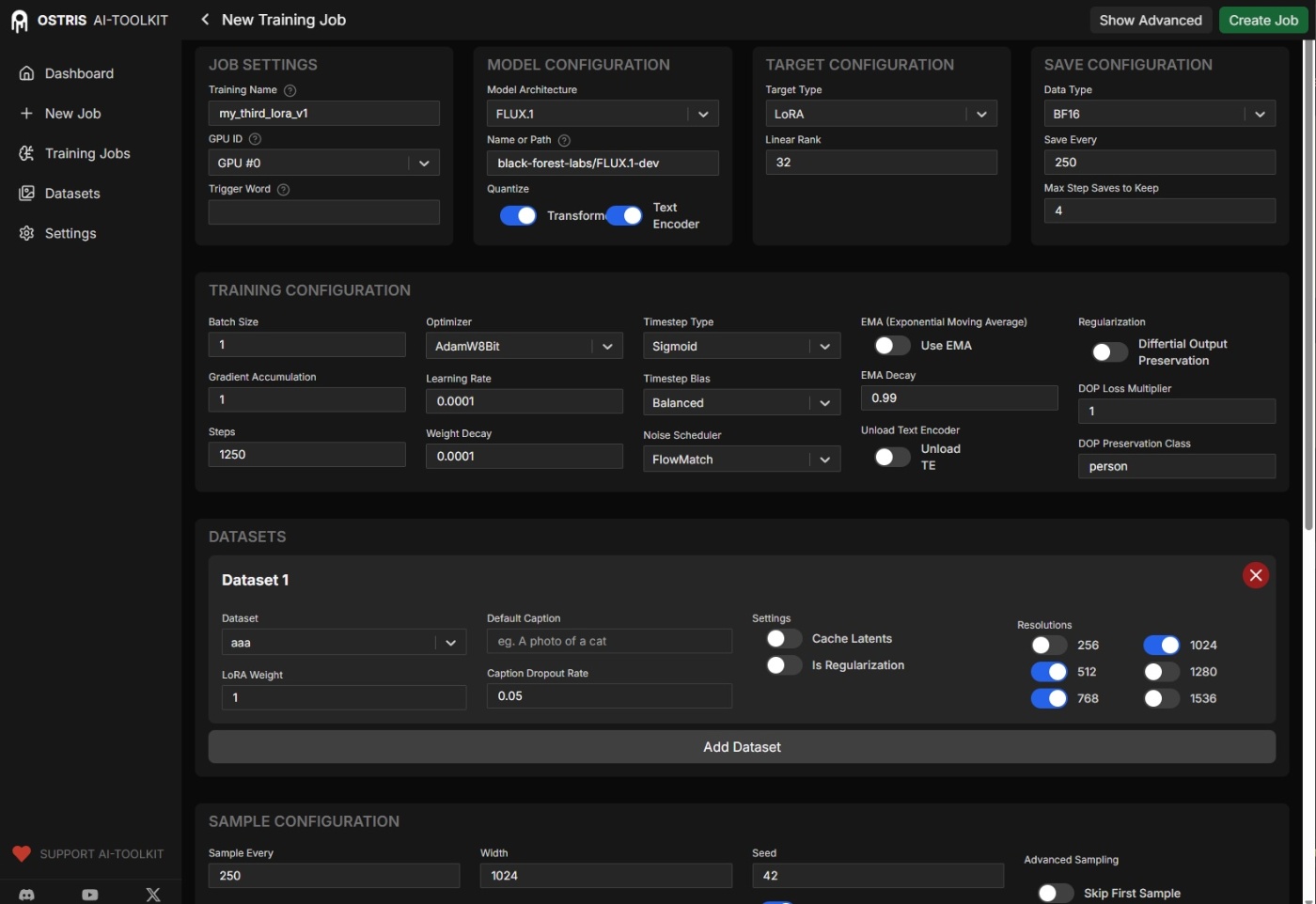
AI Toolkit UI
run_modal_docker.py
WebUIを表示してtrainingができるようにclaudeに依頼して修正
長いので折りたたみ
'''
ostris/ai-toolkit on https://modal.com
Run training with the following command:
modal run run_modal.py --config-file-list-str=/app/ai-toolkit/config/whatever_you_want.yml
'''
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
import sys
import modal
from dotenv import load_dotenv
# Load the .env file if it exists
load_dotenv()
sys.path.insert(0, "/app/ai-toolkit")
# must come before ANY torch or fastai imports
# import toolkit.cuda_malloc
# turn off diffusers telemetry until I can figure out how to make it opt-in
os.environ['DISABLE_TELEMETRY'] = 'YES'
# define the volume for storing model outputs, using "creating volumes lazily": https://modal.com/docs/guide/volumes
# you will find your model, samples and optimizer stored in: https://modal.com/storage/your-username/main/flux-lora-models
model_volume = modal.Volume.from_name("flux-lora-models", create_if_missing=True)
# modal_output, due to "cannot mount volume on non-empty path" requirement
MOUNT_DIR = "/app/ai-toolkit/modal_output" # Dockerfileのパスに合わせて変更
# define modal app
image = modal.Image.from_dockerfile("docker/Dockerfile").add_local_dir("config", "/app/ai-toolkit/config").add_local_dir("input/images", '/app/ai-toolkit/input/images')
# mount for the entire ai-toolkit directory
# example: "/Users/username/ai-toolkit" is the local directory, "/root/ai-toolkit" is the remote directory
# code_mount = modal.Mount.from_local_dir("D:/ai-toolkit", remote_path="/root/ai-toolkit")
# create the Modal app with the necessary mounts and volumes
# app = modal.App(name="flux-lora-training", image=image, mounts=[code_mount], volumes={MOUNT_DIR: model_volume})
app = modal.App(name="flux-lora-training", image=image, volumes={MOUNT_DIR: model_volume})
# Check if we have DEBUG_TOOLKIT in env
if os.environ.get("DEBUG_TOOLKIT", "0") == "1":
# Set torch to trace mode
import torch
torch.autograd.set_detect_anomaly(True)
import argparse
from toolkit.job import get_job
def print_end_message(jobs_completed, jobs_failed):
failure_string = f"{jobs_failed} failure{'' if jobs_failed == 1 else 's'}" if jobs_failed > 0 else ""
completed_string = f"{jobs_completed} completed job{'' if jobs_completed == 1 else 's'}"
print("")
print("========================================")
print("Result:")
if len(completed_string) > 0:
print(f" - {completed_string}")
if len(failure_string) > 0:
print(f" - {failure_string}")
print("========================================")
@app.function(
# request a GPU with at least 24GB VRAM
# more about modal GPU's: https://modal.com/docs/guide/gpu
gpu="A100", # gpu="H100"
# more about modal timeouts: https://modal.com/docs/guide/timeouts
timeout=7200, # 2 hours, increase or decrease if needed
secrets=[modal.Secret.from_name("huggingface-secret")]
)
def main(config_file_list_str: str, recover: bool = False, name: str = None):
# convert the config file list from a string to a list
config_file_list = str(config_file_list_str).split(",")
jobs_completed = 0
jobs_failed = 0
print(f"Running {len(config_file_list)} job{'' if len(config_file_list) == 1 else 's'}")
for config_file in config_file_list:
try:
job = get_job(config_file, name)
job.config['process'][0]['training_folder'] = MOUNT_DIR
os.makedirs(MOUNT_DIR, exist_ok=True)
print(f"Training outputs will be saved to: {MOUNT_DIR}")
# run the job
job.run()
# commit the volume after training
model_volume.commit()
job.cleanup()
jobs_completed += 1
except Exception as e:
print(f"Error running job: {e}")
jobs_failed += 1
if not recover:
print_end_message(jobs_completed, jobs_failed)
raise e
print_end_message(jobs_completed, jobs_failed)
# WebUIアクセス用の新しい関数を追加(GPU対応でトレーニング可能)
@app.function(
image=image,
gpu="A100",
cpu=4,
memory=32768, # 32GB
timeout=7200, # 2時間
volumes={MOUNT_DIR: model_volume},
secrets=[modal.Secret.from_name("huggingface-secret")]
)
def webui():
import subprocess
import time
import os
# Hugging Faceにログイン
try:
from huggingface_hub import login
hf_token = os.environ.get("HF_TOKEN")
if hf_token:
login(token=hf_token)
print("✅ Successfully logged in to Hugging Face")
else:
print("⚠️ No HF_TOKEN found")
except Exception as e:
print(f"⚠️ Failed to login to Hugging Face: {e}")
# AI-toolkit UIディレクトリに移動
os.chdir("/app/ai-toolkit/ui")
# トレーニング結果保存先を作成
os.makedirs(MOUNT_DIR, exist_ok=True)
# modal.forwardでポート8675を公開
with modal.forward(8675) as tunnel:
print(f"🌐 AI Toolkit WebUI is accessible at: {tunnel.url}")
print(f"🔧 Starting UI server...")
print(f"💾 Training outputs will be saved to: {MOUNT_DIR}")
# npm run startでWebUIを起動
env_vars = os.environ.copy()
if hf_token:
env_vars.update({
"HF_TOKEN": hf_token,
"HUGGINGFACE_HUB_TOKEN": hf_token,
"HF_API_TOKEN": hf_token
})
process = subprocess.Popen(
["npm", "run", "start"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
cwd="/app/ai-toolkit/ui",
env=env_vars # 環境変数を明示的に渡す
)
# サーバーが起動するまで待機
print("⏳ Waiting for server to start...")
time.sleep(30)
print(f"✅ WebUI should now be accessible at: {tunnel.url}")
print(f"🚀 You can now start training jobs from the WebUI!")
# 2時間維持(トレーニング時間を考慮)
try:
while process.poll() is None:
# プロセスのログを定期的に出力
try:
stdout_line = process.stdout.readline()
if stdout_line:
print(f"[WebUI] {stdout_line.decode().strip()}")
stderr_line = process.stderr.readline()
if stderr_line:
print(f"[WebUI ERROR] {stderr_line.decode().strip()}")
except:
pass
time.sleep(10)
# 定期的にボリュームをコミット
model_volume.commit()
except KeyboardInterrupt:
print("🛑 Shutting down WebUI...")
process.terminate()
finally:
# プロセス終了時の最終ログ
if process.poll() is not None:
stdout, stderr = process.communicate()
if stdout:
print(f"[WebUI Final STDOUT] {stdout.decode()}")
if stderr:
print(f"[WebUI Final STDERR] {stderr.decode()}")
# 最終コミット
model_volume.commit()
print("💾 Final volume commit completed")
if __name__ == "__main__":
# デフォルトでmain関数を実行
parser = argparse.ArgumentParser()
# require at least one config file
parser.add_argument(
'config_file_list',
nargs='+',
type=str,
help='Name of config file (eg: person_v1 for config/person_v1.json/yaml), or full path if it is not in config folder, you can pass multiple config files and run them all sequentially'
)
# flag to continue if a job fails
parser.add_argument(
'-r', '--recover',
action='store_true',
help='Continue running additional jobs even if a job fails'
)
# optional name replacement for config file
parser.add_argument(
'-n', '--name',
type=str,
default=None,
help='Name to replace [name] tag in config file, useful for shared config file'
)
# WebUIオプションを追加
parser.add_argument(
'--webui',
action='store_true',
help='Launch WebUI instead of training'
)
args = parser.parse_args()
if args.webui:
# WebUI起動
webui.remote()
else:
# 従来通りのトレーニング実行
config_file_list_str = ",".join(args.config_file_list)
main.remote(config_file_list_str=config_file_list_str, recover=args.recover, name=args.name)
launch
modal run run_modal_docker.py::webui

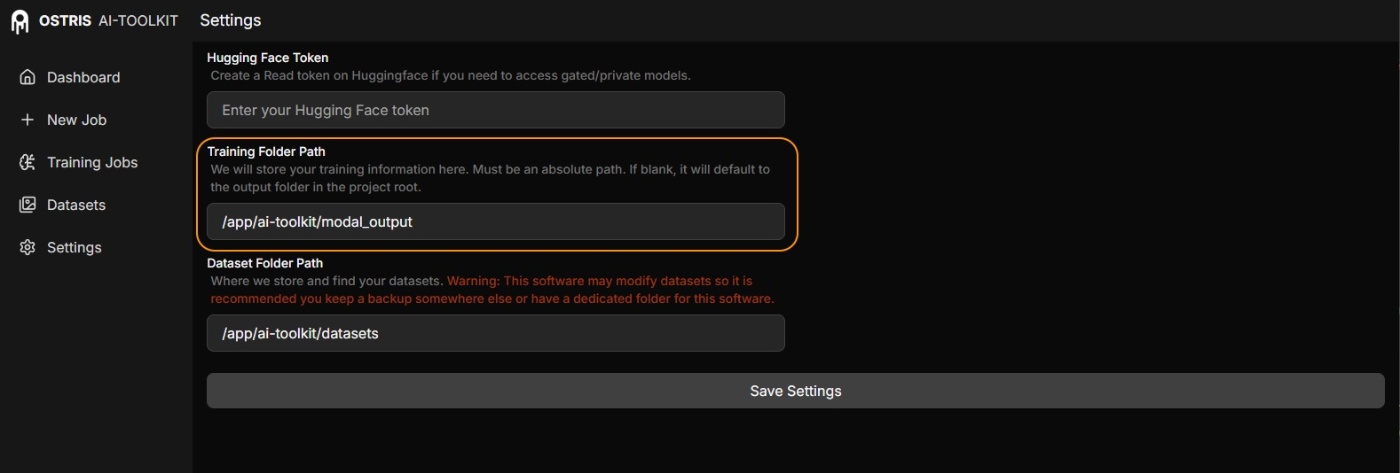
WebUIが立ちあがった後、outputのディレクトリをDockerfileと合わせて "/app/ai-toolkit/modal_output` へ変更するとModalのStorageと同期して保存ができる。
ただしtraining開始前に行う必要がありそう。

Gradio UI
Florence-2を利用したキャプション付けなどができる模様(未検証)
OSXからも動作確認
uv add modal python-dotenv oyaml
modal run run_modal_docker.py --webui