Amazon Aurora MySQL と Amazon Redshift の zero-ETL 統合でフィルタリングを試してみた
公開プレビュー時に試していた Amazon Aurora MySQL と Redshift の zero-ETL 統合ですが、2023/11 に GA になった時点ではフィルタリングが実装されていませんでした。
その後 2024/3 になって、データベース(スキーマ)・テーブルレベルのフィルタリングがサポートされたので、試してみました。
(こちら ↓ で話した内容の詳細です)
従来の zero-ETL 統合の問題点
Aurora MySQL と Redshift の zero-ETL 統合についての説明は、公開プレビュー時の記事を参照してください。
通常の ETL では Extract(抽出)→ Transform(変換)→ Load(ロード)の順に処理して、データベース(Aurora)のデータをデータウェアハウス(Redshift)に連携します。
一方、zero-ETL では、データベースから Extract(抽出)した後は、データ列の型変換を除く Transform(変換)をせずにデータウェアハウスに Load(ロード)し、ユーザーが必要に応じてデータウェアハウス上でデータを変換・加工する流れになります(ETL よりも ELT に近いです)。
以前の zero-ETL では、Aurora から Redshift への変換をサポートしていない型(BLOBなど)を持つ列が Aurora クラスター内に 1 つでもあると、Redshift へのロードができませんでした。
データベース(スキーマ)・テーブルレベルのフィルタリングがサポートされたことにより、変換対象外の列を持つテーブルを連携対象から除外する形で Redshift へのロードができるようになりました。
また、Redshift にロードする必要のないデータベース(スキーマ)をまとめて除外できるようになりました。
試した内容
Aurora クラスターと Redshift Serverless のワークグループ・名前空間、そしてその間を連携する zero-ETL 統合を作成しました。
その際、除外フィルターを指定し、除外対象のテーブルが Redshift に連携されないことを確認しました。
さらに、今回のリリースではは実装されていない列フィルター の代用として、
- 除外したい列を含まない連携用テーブル
- 除外対象テーブルに行が追加されたときに、除外列以外を連携用テーブルにコピーする
INSERTトリガー
を作成して、Redshift への連携ができるのを確認しました。
Aurora クラスター作成
まずは Aurora クラスターを作成します。
クラスターパラメータグループ作成
最初にクラスターパラメータグループを作成します。内容は公開プレビュー時と変わりません。
-
aurora_enhanced_binlog:1 -
binlog_backup:0 -
binlog_format:ROW -
binlog_replication_globaldb:0 -
binlog_row_image:full -
binlog_row_metadata:full
パラメータをデフォルト値から変更

Aurora クラスター作成
こちらも基本的にはプレビュー時と同じですが、Aurora MySQL のバージョンは 3.05 以降に対応 となっています。IAM データベース認証は指定不要でした(もちろん指定しても問題はありません)。
- Aurora MySQL 3.06.0(MySQL 8.0.34 互換)
- 開発 / テスト用
- Credential は Self managed
- インスタンスは db.t4g.medium
- Aurora レプリカを作成しない
- パブリックアクセスなし
- DB サブネットグループと VPC セキュリティグループは MySQL クライアントからアクセス可能になっていれば OK
- DB クラスターのパラメータグループとして先ほど作成したものを指定
Aurora クラスター作成






Aurora クラスターの作成が完了するまでの間に Redshift Serverless ワークグループと名前空間の作成に進みます。
Redshift Serverless ワークグループ・名前空間作成
Aurora MySQL と Redshift の zero-ETL 統合はすでに GA になっているので、Redshift Serverless ワークグループと名前空間もプレビュー版ではなく通常のものを作成します。
ワークグループを作成
任意のワークグループ名を入れ、ベース容量(今回は最低の8)とセキュリティグループ(今回はデフォルト)を指定します。
Redshift ワークグループ作成

CloudShell でワークグループの大文字・小文字識別を有効にする
CloudShell を起動し、以下を実行します。
CloudShell から実行
aws redshift-serverless update-workgroup \
--workgroup-name zeroetl-workgroup \
--config-parameters parameterKey=enable_case_sensitive_identifier,parameterValue=true
名前空間を選択
任意の名前を入れ、デフォルトの IAM ロールを作成(設定)してそれを選択します(初期状態で別の IAM ロールが選択されていた場合は選択を外します)。
名前空間を選択



確認および作成
内容を確認後、作成します。
確認および作成


Aurora クラスターと Redshift ワークグループ・名前空間の作成完了を待ちます。
zero-ETL 統合作成
Aurora・Redshift のどちらからでも作成できますが、ここでは Aurora クラスターの画面から zero-ETL 統合を作成します。
zero-ETL 統合作成

統合識別子を指定
統合識別子として任意の名前を入れます。
統合識別子を入力

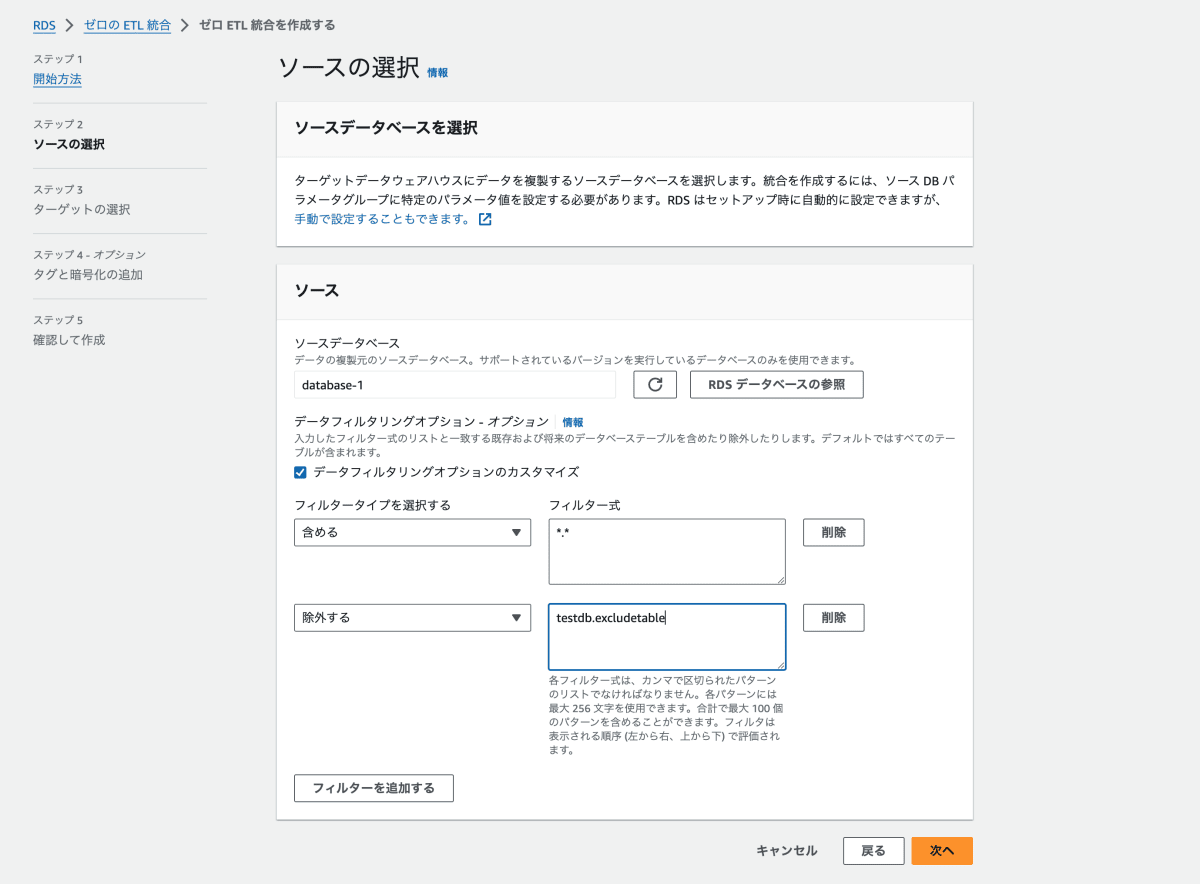
ソースデータベースとフィルタリングを指定
Aurora クラスター側から作成するとソースデータベースはすでに指定されているので、「データフィルタリングオプションのカスタマイズ」にチェックを入れてフィルタリングを指定 します。
- フィルタータイプ「含める」 : フィルター式「
*.*」 - フィルタータイプ「除外する」 : フィルター式「
testdb.excludetable」
この指定では、testdbスキーマのexcludetableテーブル以外を Aurora から Redshift に連携します。
フィルタリングを指定
ターゲット Redshift 名前空間を選択
先ほど作成した Redshift 名前空間を選択します。
Redshift を選択


リソースポリシーについては「修正をお願いする」にチェックを入れることで自動修正されます。
確認して作成
(タグと暗号化はデフォルトどおりで進めた後)確認して作成します。
タグと暗号化の追加

確認して作成


待ち時間にテストデータ投入
Aurora に 2 つのテーブルを作成しテストデータ投入します。
- データベース(スキーマ) :
testdb - Redshift に連携するテーブル :
includetable - Redshift に連携しないテーブル :
excludetable- Redshift に連携できない
BLOB列を含む
- Redshift に連携できない
テストデータ投入
mysql> CREATE DATABASE testdb;
Query OK, 1 row affected (0.00 sec)
mysql> USE testdb;
Database changed
mysql> CREATE TABLE includetable (id INT PRIMARY KEY AUTO_INCREMENT, val INT NOT NULL, str VARCHAR(100));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO includetable SET val = 100, str = 'abc';
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO includetable SET val = 110, str = 'xyz';
Query OK, 1 row affected (0.00 sec)
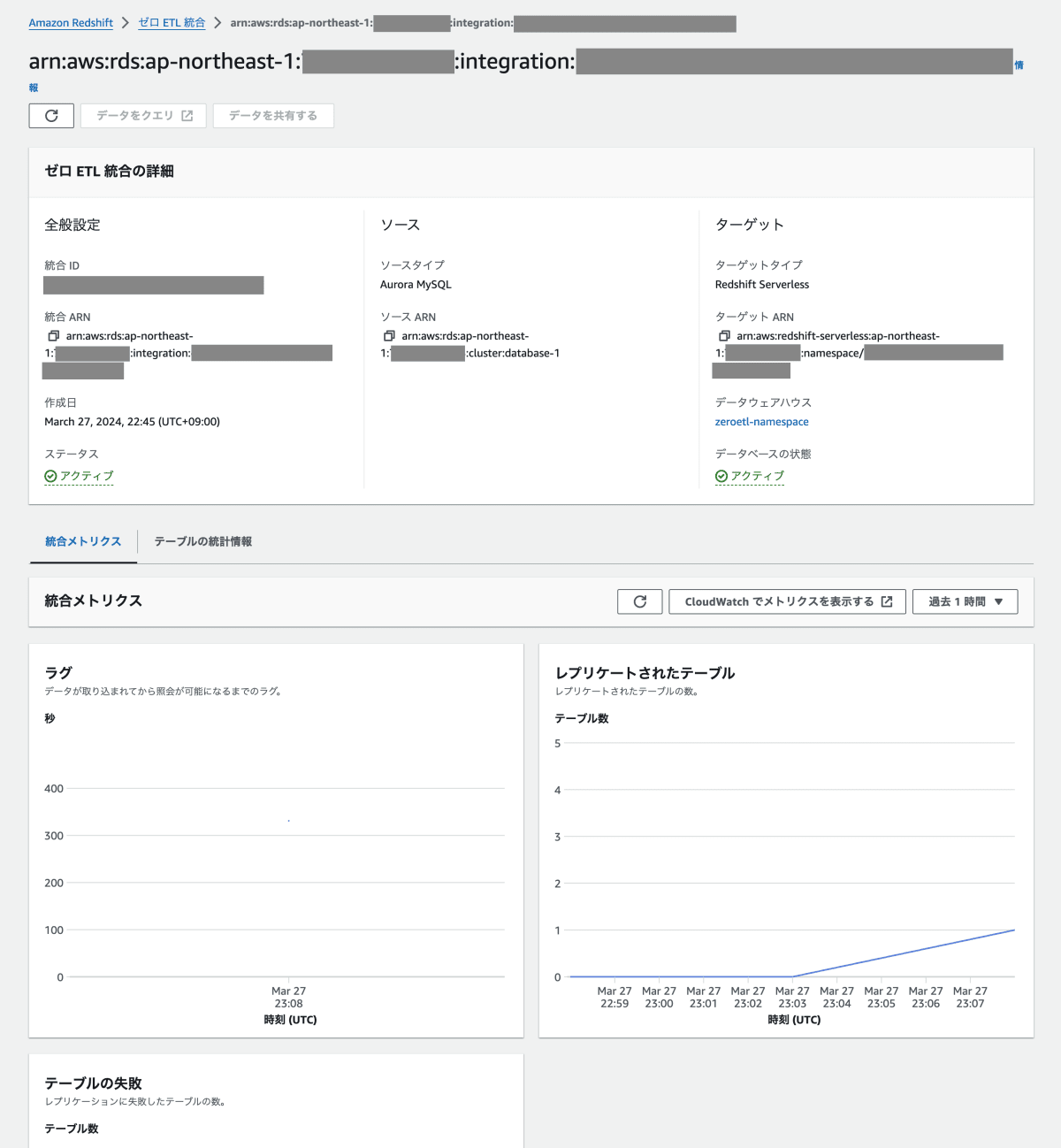
統合用のデータベースを作成
zero-ETL 統合の作成が完了したらステータスが「アクティブ」になります。
zero-ETL 統合作成完了

zero-ETL 統合のリンクをクリックすると「データベースの作成が必要です」と表示されているので、右上のボタンから統合用のデータベースを作成します。
統合用のデータベースを作成


任意のデータベース名を入れて作成します。
しばらく待つと統合用データベースが作成されて Redshift に Aurora のデータが連携(ロード)されます。
フィルタリング動作確認
Redshift にデータがロードされると、レプリケートされたテーブルが「1」になります。除外されたテーブルはカウントされません。
レプリケートされたテーブルを確認
Redshift query editor v2 でも確認してみます。
Redshift query editor v2 で連携データを確認

正しく連携されていますね。除外されたテーブルも存在しません。
連携用テーブル・トリガー作成
先に記したとおり、今回のフィルタリングには列フィルターがありません。そのため、連携用テーブルとトリガーを使った列フィルターの代用を試してみます。
テーブルを作成
まずは、先ほどの除外テーブル(excludetable)からBLOB列を除いた、連携用テーブル(includetable_from_exclude)を作成します。
連携用テーブルを作成
mysql> CREATE TABLE includetable_from_exclude (id INT PRIMARY KEY AUTO_INCREMENT, val INT NOT NULL, str VARCHAR(100));
Query OK, 0 rows affected (0.03 sec)
トリガーを作成
続いて、excludetableテーブルに行がINSERTされたときにincludetable_from_excludeテーブルにBLOB列を除いてコピーするためのトリガーを作成します。
トリガーを作成
mysql> CREATE TRIGGER ins_rec BEFORE INSERT ON excludetable
-> FOR EACH ROW INSERT INTO includetable_from_exclude VALUES(NEW.id, NEW.val, NEW.str);
Query OK, 0 rows affected (0.01 sec)
テストデータ投入
excludetableテーブルを一旦空にしたあとテストデータを投入し、includetable_from_excludeテーブル経由で Redshift に連携してみます。
確認用データを投入
mysql> TRUNCATE TABLE excludetable;
Query OK, 0 rows affected (0.04 sec)
mysql> INSERT INTO excludetable SET val = 1000, str = 'abcde', bin = RANDOM_BYTES(100);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO excludetable SET val = 1010, str = 'vwxyz', bin = RANDOM_BYTES(100);
Query OK, 1 row affected (0.00 sec)
特定の列(カラム)を除外したテーブルの連携確認
Redshift にはほぼ瞬時にデータがロードされます。
レプリケートされたテーブルを確認

レプリケートされたテーブルが「2」になりました。
Redshift query editor v2 でも確認してみます。
Redshift query editor v2 で連携データを確認

includetable_from_excludeテーブルも正しく連携されています。
まとめ
Aurora MySQL と Redshift の zero-ETL 統合にデータベース(スキーマ)・テーブルレベルのフィルタリングがサポートされたことで、これまで連携不可だったデータベースの連携が可能になりました。
今のところ列フィルターはできませんが、連携用テーブルとトリガーを使えば代用が可能です。
Discussion