Open8
LeanStoreに入門
LeanStore
- many-core CPUs & NVMe SSDs に最適化された OLTP ストレージエンジン
- 現在は研究用のプロトタイプ
参考
The Evolution of LeanStore をざっと読む
1 Introduction
- In-Memory DBMS はアカデミックでは盛り上がっているが、real-world での採用は限られている
- いまだ disk-based が支配的
- DRAM の価格は 2012 年以降下がっておらず、persistent memory もトラディショナルな storage を replace できてない
- Flash は安くなっており、NVMe は速い
- In-Memory/Disk-Based なシステムは最新の SSDs を活かすことが出来てない
- 例: PostgreSQL では NVMe SSDs 上のワークロードでは CPU-bound
- LeanStore は out-of-memory のデータを in-memory システムに近いパフォーマンスで扱うことを達成するために始まったプロジェクト
- modern な in-memory 最適化と traditional な DBMS 技術を組み合わせ
- この論文は LeanStore システム全体の概要を説明
2 Related Work
- 過去10年、flash-optimized database system に関する研究は少なかった
- ほとんどは main-memory, persistent memory に関するもの
- VoltDB, Hekaton, HANA, HyPer, Silo
- Umbra は例外
- flash-optimized な OSS ストレージエンジンとしてはWiredTiger, RocksDBがある
- 8章で比較実験
WiredTiger
- B-Tree node の表現が on-disk と in-memory で分かれている
- LeanStore は同じ表現
- in-memory nodes
- 動的に割り当てられ、fixed-size page 上にはホストされない
- prefix 圧縮
- on-disk nodes(block)
- snappy アルゴリズムで圧縮
- index 操作
- swizzling されていないノードにヒットするまで virtual memory pointers を辿る
- ヒットしたらファイルを読み込み、in-memory nodes を構築
- leaf のキーを更新すると、node のキーごとの skip list に新しいエントリを挿入
- swizzling されていないノードにヒットするまで virtual memory pointers を辿る
- node がフルになり evict する時にはノード内のすべての更新をマージして disk image を作成
- LeanStore は node を in-place で更新、in-memory node を serialization オーバーヘッドなくそのまま書き込み
- index の同期には lock-free アルゴリズムを使う
- スレッドが有効なポインタを辿っていることを確認するために、アクセスする前に node のポインタを hazard list にプッシュ
- memory reclamation や eviction から除外
- 対して、LeanStore は optimistic lock-coupling を使うが、WiredTiger の hazard pointer 方式よりも memory flush が1回少なく済む
- スレッドが有効なポインタを辿っていることを確認するために、アクセスする前に node のポインタを hazard list にプッシュ
RocksDB
- LSM データ構造
- 書き込みとスペースの増幅を減らす
- LeanStore は B-trees を選択することで読み込みに最適化しているが、書き込み増幅を下げ、スペース効率を上げる設計をしている
- LSM の最初のレイヤーの MemTable はメモリ上の存在し、書き込み操作を吸収
- 設定されたサイズに達すると、immutable な Sorted String Table(SSTable)に flush
- 以前は single-writer しかサポートしていなかったが、新しいバージョンでは複数の書き込みが可能
- ただ、skip-pased な実装に限定
- 対して、LeanStore は optimistic lock-coupling で many-core でスケールするようにゼロから構築
- SSTブロックをキャッシュするために、third-party のアロケータ(jemalloc)を利用して buffer pool を管理
3 LeanStore System Overview
- Functionality and System Overview
- 基本的な key value 操作(insert/update/delete, point/range lookup)とトランザクションセマンティクス(begin, commit, rollback)をサポートするストレージエンジン
- C++ インターフェースを通じて embeddable ライブラリとして公開
- B-tree
- 主なデータ構造は B+-tree
- key value は opaque なバイト列で、データの変換と解釈はアプリケーション側で実施
- ART や HOT のような純粋な in-memory データ構造ほど高速ではないが、合理的なパフォーマンス
- LSM-trees を追加のオプションとして提供することは可能で、プロトタイプを進めている
- Synchronization Primitives
- 汎用的で使いやすい syncronization framework を実装(5章で説明)
- Buffer Manager
- LeanStore の最初の論文で in-memory システムに対して少ないオーバーヘッドでバッファ管理を実装できることを実証
- アイディア
- pointer swizzling
- lightweight replacement strategy
- pointer swizzling によってキャッシュされたページに直接アクセスできる
- swizzling されたページへのアクセスは page replacement アルゴリズムのオーバーヘッドを発生させない
- 6章で説明
- Snapshot Isolation and MVCC
- MVCC 実装により SI をサポート
- state-of-the-art な out-of-memory MVCC の OLTP 性能は長時間実行される OLAP クエリが存在すると崩壊するので、その解決策を提案
- (1) 効率的な細かい粒度の GC を可能にする out-of-memory commit protocol
- (2) 論理的に削除されたタプルが邪魔にならないように移動する補助データ構造
- (3) adaptive version ストレージスキーム
- Logging
- WAL は通常 centralized なデータ構造であるため multi-core スケーラビリティを妨げる
- LeanStore ではスレッドごとに1つの WAL を使用し、RFA(Remote Flush Avoidance)という軽量なページベースの追跡機構によって正しさを保証する解決策を提案
- 7 章で追加の改良を説明
4 B+-Tree

- クラシカルな slotted page レイアウトをベースにして、最適化
- Node Layout
- ページの先頭の slot にはページの末尾に格納されている key/payload の offset と length を含む
- Fence Keys and Prefix Compression
- Fence keys すべての node に格納され、prefix compression の実装を単純化
- Fence keys は不変で、node の初期化時(split or merge)に決定
- node に格納される可能性のある key の exclusive lower, inclusive upper をそれぞれ決定
- 新しい B-tree が作成された時は特別な値 -∞, ∞ が設定される
- Speeding Up Binary Search with Heads
- basic な slotted page レイアウトだと binary search での比較の度にポインタを再参照する必要があるキャッシュミスにつながる
- Graefe and Larson が提案した “poor man normalized keys” を採用
- 各 key slot に key の prefix 4 バイトを格納することで比較に利用できるようにする
- key はデフォルトで文字列として格納され、比較には lexicographical order を使う
- little-endian システムでは byte swap 操作を用いてシリアル化された文字列表現でソート順を維持
- slot にある key の prefix が同値だった場合に完全な key を使って比較
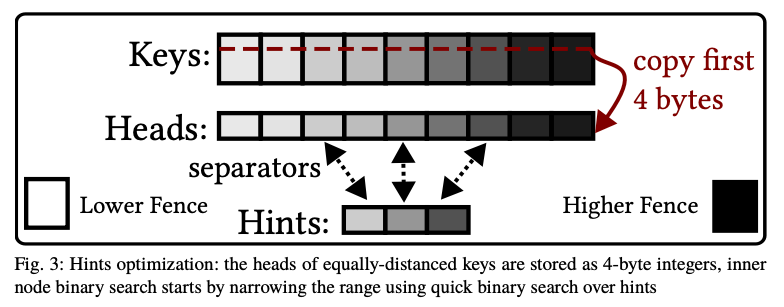
- Avoiding Binary Search with Hints
- binary search を高速化するために、hint 最適化を実装
- 全範囲の binary search をせず、hint 上のキャッシュ効率的な search を使用して範囲を縮小することに try
- hints は一定のエントリ数を持つ密な配列に格納(ここではサイズ 16 を使用)
- hints に格納する key 間の距離は一定(distance = #slots ÷ (#hints+1))
- hints には key 全体ではなく最初の 4 バイトだけを格納
- →すべての hints は1行のキャッシュに収まるので素早く binary search して探している key の候補範囲を絞れる
- hints を更新するオーバーヘッドはごくわずか
- Contention Split and XMerge
- tries のようなデータ構造とは異なり、同じ keys のセットでも異なる B-tree 構造になる可能性がある
- この observation を利用して、Contension Split と XMerge の最適化を用いて B-tree 構造を動的かつ adaptive に最適化
- Contension Split
- node がフルでない場合でも node を分割することで不要な latch 競合を削減
- XMerge
- X 個の隣接 node を X-1 個の node にマージすることで node の fill factor を増加させる
5 Practical and Scalable Synchronization
5.1 Optimistic Lock Coupling and Buffer Management in C++
- optimistic latching により sort page 読み出しにおける不要な競合を解除
- オリジナルの実装は single atomic version counter と spin lock 実装に依存
- 上記の単純な設計は DB が扱うワークロードを処理するのに十分な堅牢性がない
- Reverse CPU priority, unfairness などは spin locks の anomaries の例
- Hybrid Latches
- 最新の LeanStore の設計では、OS サポート付きの hybrid latch を使用
- オリジナルの optimistic mode の他に pessimistic shared, exclusive mode を使用
- バージョンカウンタのための std::stomic<uint64_t> と std::shared_mutex を使用
- 各操作に最適な mode を使用し、実装を簡素化できる
- 例: スキャン
- long page 読み取りには pessimistic shared mode を使用
- 以前は page をスキャンする際に concurrent な変更が restart を引き起こす可能性があった
- leaf node の short 読み取りと inner node トラバーサルに対しては最初に optimistic latch を試み、ロックされている場合は pesimistic shared mode に fallback
- page の変更操作(insert/update/delete)は exclusive mode で latch
- 例: スキャン
- Page Guard
- バッファ管理と異なる latch mode の複雑さを解消するために Page Guards を使用して、実装を抽象化
- RAII で、Guard オブジェクトがスコープ外に出たら unlatch
5.2 Implementing Restart in C++
- optimistic latch 実装と、子ページの1つをストレージから読み込んでいる間に親ページの latch を保持しないことにより、データ構造操作を restart 可能にする必要がある
- トランザクション全体を最後に restart させる可能性のある optimistic concurrency control(OCC)とは異なり、低レベルの optimistic latching では index 操作をどの時点からでも restart できる
- 以下で restart のための C/C++ のオプションと、読みやすさとスケーラブルな restart 実装を可能にする JumpMU について説明
Goto and Labels
- goto は同じ stack frame(C++ では同じ関数呼び出し)内でのみ機能
- ストレージエンジンのような複数のコンポーネントにおいて goto で戻りつつ結果を通知するのは面倒
C++ Exceptions
- 数段の stack level をジャンプすることができ、stack を自動的に unwind できる
- ただ、標準的な Exception 実装は many-core に対してスケールしない
- GCC, LLVM では Exception がスローされる度に global lock を取得するため
- global lock を回避することが出来ても CPU コストは依然として高い
- Exception を処理する landing pad を探し、stack を巻き戻す処理に 10K instructions 必要
- exclusive lock を取得していた場合、その間確保されたままになる
- Exception を処理する landing pad を探し、stack を巻き戻す処理に 10K instructions 必要
Long Jump in C
- C の standard library は複数レベルの stack をまたいで設定したチェックポイントに制御フローを戻す機構がある
- setjmp & longjmp
- ただ C++ が自動的に行う stack の巻き戻しは longjmp では起こらないため、リソースリークやその他の問題を起こす可能性がある
JumpMU: Long Jump with Manual Stack Unwinding
- C の longjmp だけでは不可能なすべての destructor を手動で呼び出すことで C++ の安全なバリアントを提供
- JumpMU は longjmp 呼び出しの直前に setjmp 以降に stack 上に性的に生成されたすべてのオブジェクトを destruct
- 効率的に実現するためにコンパイル時とランタイムで作業を分担
6 Buffer Manager
- 最初の論文からの変更点について説明
- 簡素化とスケーラビリティ向上のための変更
6.1 Memory Reclamation is Unnecessary
- オリジナルの設計では epoch-based の memory reclamation を実装
- 保守が煩雑であるだけでなく、robustness にも欠けていた
- 1つの遅いスレッドが current global epoch の進行を妨げて evict を妨げる可能性があった
- memory reclamation は不要だとわかりコードを削除
- 1)buffer frame の atomic version counter のアドレスをリセット・変更しない、2)buffer に割り当てられたメモリを解放しない、とすることでシステムを簡素化
6.2 Page Replacement
Lightweight Replacement Strategy Without a Cooling Stage
- LeanEvict はアクセスされたページの hot set を追跡する代わりに、未使用ページの cold set をバックグラウンドで特定
- 不必要に複雑な cooling stage を使用しており、競合に脆弱だった
- 本論文では Second Chance replacement strategy に置き換えることを提案
- hot path にオーバーヘッドを追加せず、LeanEvict と同じバックグランド方式で動作
- 以下 LeanStore での Second Chance の実装について説明
Swizzling-Based Second Chance Implementation.
- free ページが必要になる度に 64 個のランダムな buffer frame を選び、ステータスをロード
- buffer frame をイテレートして処理
-
- buffer frame を指す親の swip の最上位ビットをセット
-
- buffer frame のステータスを cool に変更
- すでに cool だったページは dirty であれば disk に書き戻し、そうでなければ即座に evict
-
- cool な swip な virtual memory pointer を保持するが、pointer には cool であることをマークするタグが付けられる
- cold ページにアクセスした場合タグは unset されて、buffer frame のステータスは hot に戻される
No Parent Pointers with Top Down Tree Traversals
- ページを evict するために親 node 内のページへの virtual memory pointer をページ識別子で置き換えることで unswizzle
- evict したい各 node の親 node を取得できる必要がある
- LeanStore の初期実装では各 buffer frame に親 node pointer を格納していたが制約と複雑性があった
- B-tree node を分割する度に子 node の半分の buffer frame で親 pointer を更新する必要があった
- B-tree の lock-coupling はトップダウンで取得する必要があるので親を latch するのには注意が必要
- 現在のデザインでは、親 node pointer は保持せず、root から通常のアクセス経路で親 node を辿る方法を使用
- LeanStore の初期実装では各 buffer frame に親 node pointer を格納していたが制約と複雑性があった
6.3 Scaling to Multiple NVMe SSDs
- 異なるスレッドが同じページを buffer pool 内の異なる場所に同時にロードすることを避けるため I/O 要求を同期化する必要がある
- 1台の SSD では global mutex を使用した単一の I/O ステージで十分だが、PCle 4.0 では NVMe SSD の array を取り付けることができるため、多数の並列 I/O 要求を発行できる必要がある
Partitioned I/O Stage
- ページ識別子によって I/O ステージを分割
- ページIDの最下位ビットによって I/O ステージのパーティションを決定
- ヒューリスティックな方法として I/O パーティション数をスレッド数と同じに設定
Background Page Provider Threads
- オリジナルのデザインでは、フォアグラウンドのワーカースレッドがページを cool & evict
- トランザクションに待ち時間を追加してしまう
- 上記デザインをやめ、バックグランドでページの cool & evict する page provider thread routine を実装
- 各スレッドは libaio や io_uring などの非同期 IF を使用
7 Logging
- 最初の logging 論文では persistent memory (pmem) を使用するスケーラブルなスキームについて説明
- pmem のシアようが遅れ、Intel によって放棄されたので flash SSD に最適化した logging スキームを実装
- Early Lock Release (ELR) も実装
- log の flush を待たずに write locks を解放し、トランザクションの abort 率を低減
- ELR と分散 logging は cross-worker logging 依存のコストを増幅
- そのため新しい細かい粒度の依存性追跡機構を導入
7.1 Group Commit
- SSD に最適化された group commit の研究はほとんどない
- LeanStore の group commit は 3 step で動作
- ワーカースレッドが concurrency control の検証を通過した pre-committed トランザクションのみを read-to-commit キューに push
- Group Committer Thread (GCT) が非同期 I/O IF を使って log 書き込みをバッチ処理
- 書き込みが完了したら fsync でブロックデバイスを flush
- pre-committed トランザクションをコミット
7.2 Dependency Tracking
- 分散 logging、ELR ではトランザクションの commit による他のトランザクションへの依存を決定する必要がある
- トランザクション T1 は WAL レコードが SSD に書き込まれる前に書き込みロックを解放
- T1 から読み出す T2 が T1 より前に commit できないことを意味
- この依存関係は WAL commit log で決定され記録される必要がある
- 同一ワーカースレッドではシリアルに処理されるのでパフォーマンスに影響しないが、ワーカースレッド間の依存関係はマイナスの影響
- 各ページの Global Sequence Number (GSN) をしようした粗い粒度の依存関係追跡は誤検出を起こす
System vs. User Transactions
- ユーザートランザクションはストレージエンジンクライアントのコマンドを実行
- 同じ global atomic counter から引き出される 開始 timestamp と commit timestamp がある
- 副作用は commit 後に見える
- システムトランザクションはストレージエンジン自身によってトリガ
- B-tree ページの split, merge, free space inventory の操作
- 副作用は他のすべてのトランザクションから直ちに見える
- 変更を適用する前に変更したいすべてのページを exclusive lock
- その結果、開始 timestamp と commit timestamp は常に等しく、ユーザー TX とは別の global atomic counter から引き出される
Commit Condition
- read committed isolation ではユーザー TX の依存関係は LSN, GSN のような log sequence ではなくトランザクションの粒度で追跡できる
- ユーザー TX は以前のユーザー TX & システム TX に依存
- システム TX はページを読んでいる間に目撃した最大のシステム TX ID を追跡すれば十分
- snapshot isolation ではユーザー TX の開始 timestamp か最新の (pre-)commit されたユーザー TX の開始 timestamp をつかうことができる
- Group Commit Thread は各ラウンド中に全ワーカーの user_tx_hardened_up_to, system_tx_hardened_up_to という watermarks を計算し、それ以下の pre-committed tx を commit