教師なしアプローチで建築図面から建物部分を抽出する
はじめに
こんにちは!トグルホールディングス株式会社でエンジニアをしている木下隼です!
今回は、画像データから「本当に必要な情報だけを抽出したい!」という、エンジニアなら一度は直面するであろう課題に対して、「教師なしでどこまでできるのか?」をちょっと試してみたので、その内容をご紹介します。
以下のように様々な情報が含まれる画像から、特定の情報のみを抽出してみた!という内容になります!

導入
画像データから「本当に必要な情報だけを抽出したい」というニーズは、様々な分野であるかと思います。しかし、現実では十分な教師データが揃わないことが多くて、教師なしでの分類が求められる場面も少ないかと思います。
私たちは2Dの建築図面からBIM(Building information modeling)*を自動生成することを目指しており、その第一歩として図面画像から建物の構造線だけを抽出する必要がありました。
私がこのテーマに取り組んだきっかけも、まさに「データが少ない中で、いかにして建物らしい部分だけを抽出するか」という課題からでした。特に建築図面には、寸法線や注釈、その他のノイズが多く含まれており、これらをいかに自動で排除するかという部分が壁となりました。
*BIM(Building information modeling):建築物に関するあらゆる情報を3Dモデルに紐づけて一元管理する手法
アプローチ概要
最初にどのような流れなのかを簡単に示します!
-
画像の前処理・テキスト情報の削除
まず、OCR(光学文字認識)を使って図面上のテキスト情報を検出し、画像から除去します。 -
スケルトン化
前処理した画像を細線化(スケルトン化)します。 -
ネットワーク化
スケルトン画像をもとに、ノード(交点や端点)とエッジ(線分)からなるネットワークデータを生成します。 -
特徴量抽出とクラスタリング
各ネットワークから「閉路数」「ノード数」「エッジ数」「面積」などの特徴量を抽出し、ガウス混合モデル(GMM)でクラスタリングします。 -
クラスタの評価と分類
抽出したクラスタごとに、どちらが「建物らしい」特徴を持つかをスコアリングし、最もスコアの高いクラスタを建物として分類します。
全体フロー図
ここからは、各工程でどのような技術や工夫を用いたかを詳しく紹介します。
使用する画像はサンプルとして図面のようなトイデータを使っていきます。
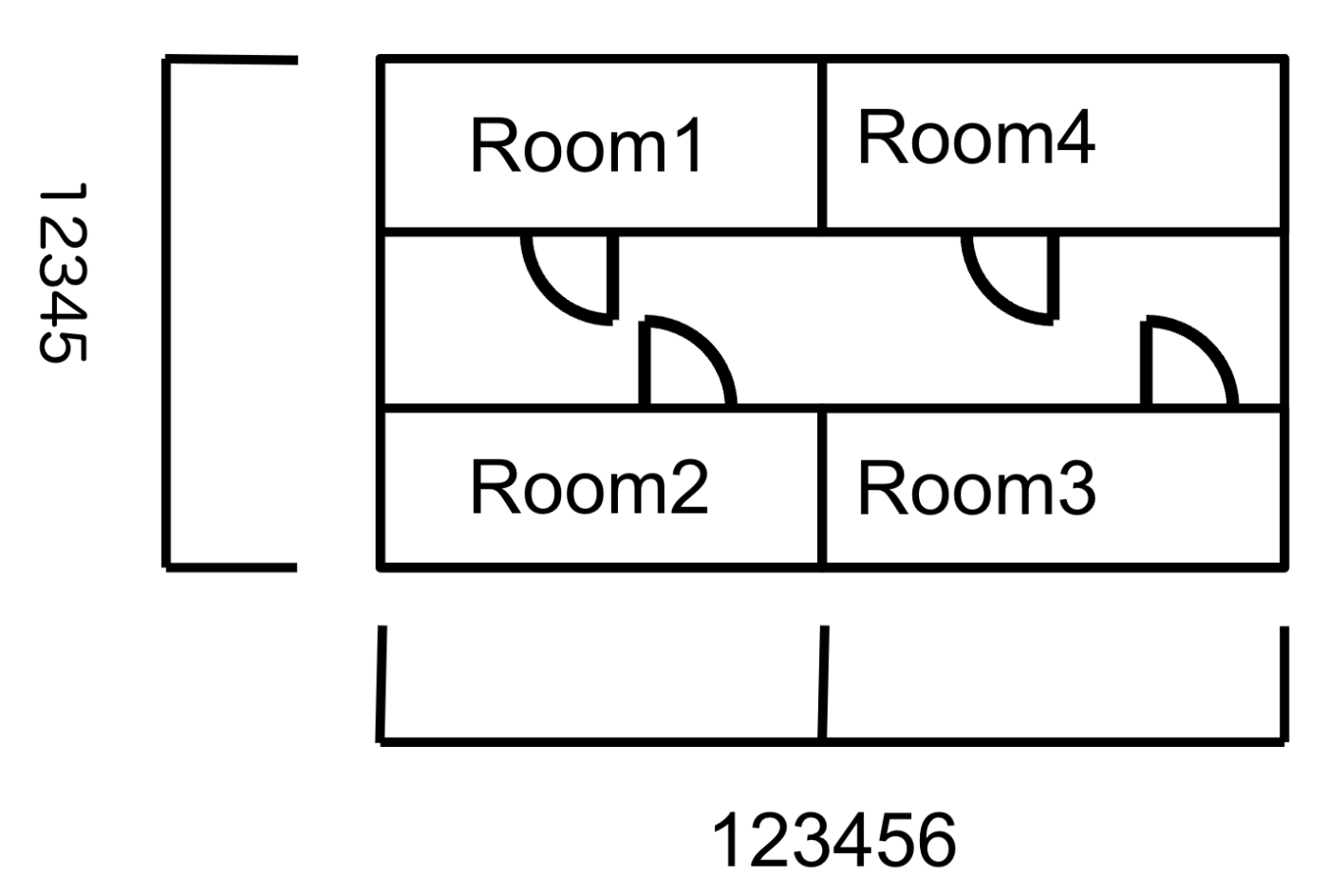
現時点で不要であるテキストデータの削除
BIMに繋げるため、建築図面から取得したいのは建物の構造的な情報のみです。そのため、現時点では文字データは不要になります。そこでOCRを使い、そこで得られた座標から該当部分を白抜きすればいいと考えました。

OCRのモデルはEasyOCRを用いています。
# detect_text はEasyOCRを使った認識結果を返す関数です
df_results = detect_text(image_path, output_dir=output)
for _, row in df_results.iterrows():
x1, y1 = row["x1"], row["y1"]
x2, y2 = row["x2"], row["y2"]
x3, y3 = row["x3"], row["y3"]
x4, y4 = row["x4"], row["y4"]
min_x = min(x1, x2, x3, x4)
max_x = max(x1, x2, x3, x4)
min_y = min(y1, y2, y3, y4)
max_y = max(y1, y2, y3, y4)
# 塗りつぶし
cv2.rectangle(
image,
(int(min_x), int(min_y)),
(int(max_x), int(max_y)),
(255, 255, 255),
-1,
)
ネットワークデータにするためのスケルトン化
次にネットワーク化して解析しやすい形にするための中間点として、細線化(スケルトン化)させる処理をしました。

最初に平滑化や、細かいノイズ、細い線などを削除するためにモルフォロジー変換を適用しました。
ここでは skimage.morphology.skeletonize を使用しました。
# 細線化(先に0 or 1に変換する)
connected_components[connected_components == 255] = 1
skeleton = skeletonize(connected_components)
スケルトン化によって、建物の輪郭や構造が1ピクセル幅の線になってくれます。この状態であればこれをエッジと見立てて、適切なコーナーや、分岐点にノードを配置する形でネットワークデータにできそうです!
ネットワーク化
スケルトン画像からノード(交点や端点)とエッジ(線分)を抽出し、ネットワークデータ(グラフ構造)を生成します。
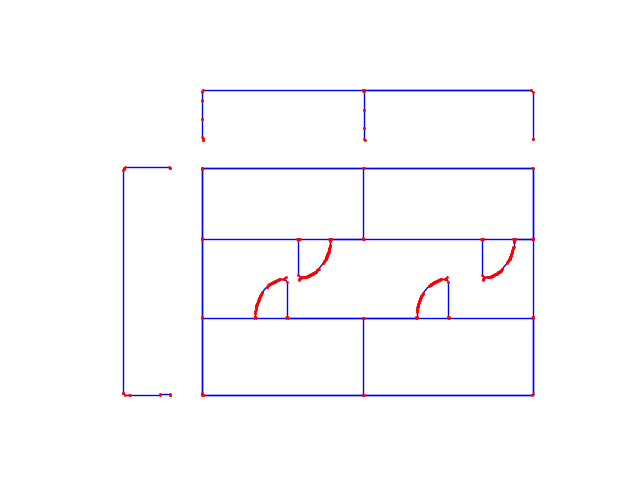
ここは自作のアルゴリズムで、周囲の画素情報を畳み込み的に調べながら、その画素がノードなのか、エッジなのかを判定しました。ネットワークの構造管理には networkx を利用しています。
kernel = np.array([[1, 1, 1], [1, 0, 1], [1, 1, 1]])
skeleton_filtered = np.pad(
skeleton_uint8.copy(), ((1, 1), (1, 1)), "constant", constant_values=0
)
skeleton_filtered = cv2.filter2D(skeleton_filtered, -1, kernel)
skeleton_filtered = skeleton_filtered[1:-1, 1:-1]
3x3のフィルタで近傍の画素を探索し、その画素がノードか、エッジか、何もないかを処理しています。
※画像が上下に反転していますが、画像の座標系(左上原点)から、グラフの座標系(左下原点)に変わっている影響です。
これでネットワークデータにできたので、あとは建物以外の情報を除去すれば完成です!
特徴量抽出とクラスタリング
最初はもっとルールベース的な方法で分けようと思っていましたが、条件を見ていると、クラスタリングできないか?と考えました。
- 画素レベルで繋がっていなければ、スケルトン処理で必ず分離しているネットワーク取れていること
- ネットワークのノード数やエッジ数、面積をもとに建物らしいものを推定できそうであったこと
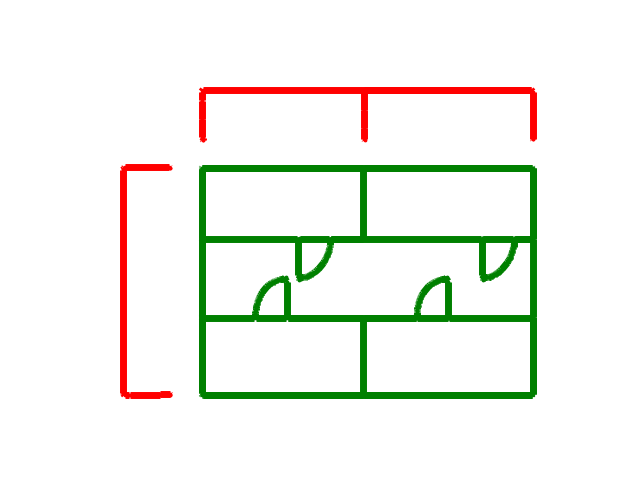
結果として以下のようなクラスタリング結果となりました。
- 赤🟥 = cluster_id: 0
- 緑🟢 = cluster_id: 1
| cluster_id | networks | area | nodes | edges | cycle_basis | network_ids |
|---|---|---|---|---|---|---|
| 0 | 2 | 96000.75 | 21.5 | 20.5 | 0.0 | [0.0, 1.0] |
| 1 | 1 | 180422.5 | 356.0 | 376.0 | 21.0 | [2.0] |
各ネットワーク(連結成分)ごとに、
- 閉路数
- ノード数
- エッジ数
- 面積(ConvexHullで計算)
などの特徴量を抽出しました。StandardScaler で正規化し、sklearn.mixture.GaussianMixture を用いて2クラスタにクラスタリングしました。
# 特徴量の標準化
scaler: StandardScaler = StandardScaler()
features_scaled: np.ndarray = scaler.fit_transform(features)
# ガウス混合モデルでクラスタリング(クラスタ数=2)
n_clusters = 2
gmm: GaussianMixture = GaussianMixture(
n_components=n_clusters, random_state=42, covariance_type="full"
)
cluster_labels: np.ndarray = gmm.fit_predict(features_scaled)
cluster_probabilities: np.ndarray = gmm.predict_proba(features_scaled)
ガウス混合モデルを使用した理由としては、クラスタ間の特徴的な違いを確率的な分布から推定できるモデルであるため、今回のようなデータを分布的に分離したいケースには向いていると判断しました。
また、データ点数が少ない場合もあり、密集度などを利用するクラスタリングモデルは向いていないとも思いました。
どちらが建物か?
クラスタリングはできましたが、「どっちが建物のネットワークですか?」ということは判断できていません。教師なしなのでラベルが存在していないからです。
そこで、クラスタごとに、建物らしい特徴(閉路数・ノード数・エッジ数・面積が大きい、ネットワーク数が少ない)を持つかどうかをスコアリングし、最もスコアの高いクラスタを「建物」として分類しようと考えました。

ここでは、ドメイン知識や実際のデータ傾向をもとにスコア計算のルールを設計しました。
# 建物とそうでないものを分類
cluster_id_list: np.ndarray = df_cluster_data["cluster_id"].values
biggest_building_columns: list[str] = [
"area",
"num_nodes",
"num_edges",
"num_cycle_basis",
]
lowest_building_columns: list[str] = ["num_networks"]
df_cluster_data_0: pd.DataFrame = df_cluster_data[
df_cluster_data["cluster_id"] == cluster_id_list[0]
].reset_index()
df_cluster_data_1: pd.DataFrame = df_cluster_data[
df_cluster_data["cluster_id"] == cluster_id_list[1]
].reset_index()
# スコアを計算
cluster0_score: int = (
df_cluster_data_0[biggest_building_columns].to_numpy()
> df_cluster_data_1[biggest_building_columns].to_numpy()
).sum() + (
df_cluster_data_0[lowest_building_columns].to_numpy()
< df_cluster_data_1[lowest_building_columns].to_numpy()
).sum()
cluster1_score: int = (
df_cluster_data_1[biggest_building_columns].to_numpy()
> df_cluster_data_0[biggest_building_columns].to_numpy()
).sum() + (
df_cluster_data_1[lowest_building_columns].to_numpy()
< df_cluster_data_0[lowest_building_columns].to_numpy()
).sum()
if cluster0_score > cluster1_score:
building_network: BuildingGraph = G_list[cluster_id_list[0]]
else:
building_network: BuildingGraph = G_list[cluster_id_list[1]]
「建物は他のその他よりもノード数、エッジ数、閉路数が多い」というルールのもと、クラスタごとに各特徴量の値を集計して、比較をすることでどちらのクラスタがより建物らしいかを推定しました。
結果として
このアプローチを用いることで、建築図面画像から「建物らしい」部分を教師なしで抽出することができました。クラスタリングの結果、建物本体とノイズ(寸法線や注釈など)が分離されるケースが多く、実務上も有用な手応えを感じました。
一方で、課題もいくつかあると考えています。
- スケルトン化やネットワーク化の過程で建物の輪郭が途切れてしまうと、正しくクラスタリングできない
- 図面の品質やノイズの多さによっては、特徴量の抽出やクラスタの分離が難しい
それでも、教師なしでここまで分類できるというのは非常に面白い発見であり、今後の応用や改良の余地も大きいと感じています。
応用・今後の展望
今回の手法は、建築図面以外の画像や他分野にも応用できる可能性もあると思います。
さらにもっと試してみたいのは、ネットワークから抽出できる特徴量を増やすという点です。ネットワークから取得可能な特徴量はもっと多く、有用なものが他にもあります(密集度、最短経路長など)。これらを組み合わせることで、さらに条件の厳しい画像に対しても応用できると考えています。
まとめ
今回ご紹介したように、教師なし学習とネットワーク解析を組み合わせることで、建築図面画像から建物本体を自動的に抽出することができました。もちろん、十分なデータがあれば教師あり学習による機械学習手法の方が高精度・高汎化性なモデルを作れる可能性が高いですが、データが限られている状況でも工夫次第で有用な結果が得られることを実感しました。
最後までお読みいただき、ありがとうございました!
Discussion