Closed2
【AWS】Glue データ変換
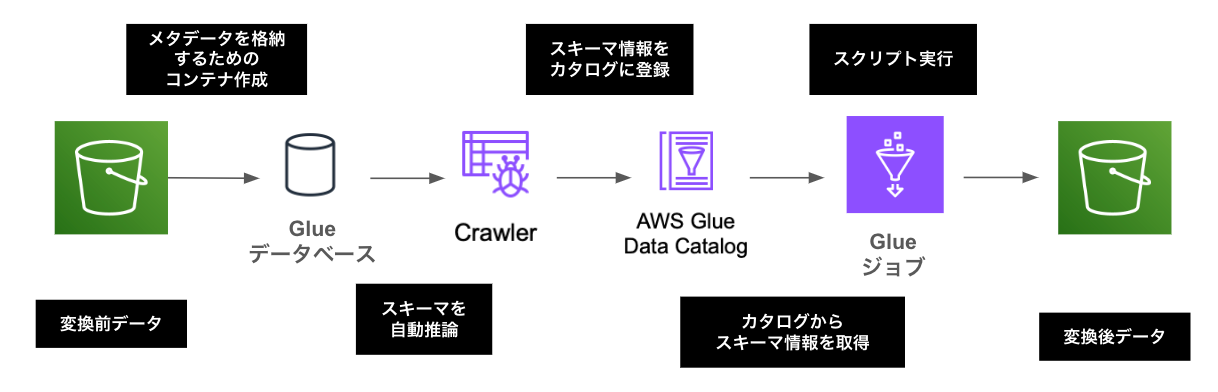
Glueの動作概要
Terraform
- メモなので main.tf にまとめる
- とりあえず csv→perquet するだけ
main.tf
provider "aws" {
region = "ap-northeast-1"
profile = "risp-dev"
}
variable "input_bucket" {
type = string
default = "バケット名"
}
# Glueジョブ用のIAMロール
resource "aws_iam_role" "glue_job_role" {
name = "glue_job_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "glue.amazonaws.com"
}
}
]
})
}
# Glueジョブ用のIAMポリシーアタッチメント
resource "aws_iam_role_policy_attachment" "glue_service" {
role = aws_iam_role.glue_job_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"
}
resource "aws_iam_role_policy" "s3_access" {
name = "s3_access_policy"
role = aws_iam_role.glue_job_role.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
]
Effect = "Allow"
Resource = [
"arn:aws:s3:::${var.input_bucket}",
"arn:aws:s3:::${var.input_bucket}/*"
]
}
]
})
}
# Glueデータベースの作成
resource "aws_glue_catalog_database" "csv_database" {
name = "csv_database"
}
# Glueクローラーの定義
resource "aws_glue_crawler" "csv_crawler" {
name = "csv_crawler"
role = aws_iam_role.glue_job_role.arn
database_name = aws_glue_catalog_database.csv_database.name
s3_target {
path = "s3://${var.input_bucket}/csv/"
}
# スキーマ変更時の対応
schema_change_policy {
delete_behavior = "LOG"
update_behavior = "UPDATE_IN_DATABASE"
}
}
# Glueジョブ用のPythonスクリプト
resource "local_file" "glue_job_script" {
content = file("${path.module}/glue_job_script.py")
filename = "${path.module}/glue_job_script.py"
}
# Glueジョブの定義
resource "aws_glue_job" "process_csv_to_parquet" {
name = "process_csv_to_parquet"
role_arn = aws_iam_role.glue_job_role.arn
command {
name = "glueetl"
script_location = "s3://${var.input_bucket}/scripts/glue_job_script.py"
python_version = "3"
}
default_arguments = {
"--job-language" = "python"
"--enable-continuous-cloudwatch-log" = "true"
"--enable-glue-datacatalog" = "true"
"--input_path" = "s3://${var.input_bucket}/"
"--output_path" = "s3://${var.input_bucket}/"
}
# 同時実行数の制限
execution_property {
max_concurrent_runs = 1
}
glue_version = "3.0"
depends_on = [local_file.glue_job_script]
}
# S3にスクリプトをアップロード
resource "aws_s3_object" "glue_job_script_upload" {
bucket = var.input_bucket
key = "scripts/glue_job_script.py"
source = "${path.module}/glue_job_script.py"
etag = filemd5("${path.module}/glue_job_script.py")
depends_on = [local_file.glue_job_script]
}
PySparkとSparkSQLの整理
なんでSpark?→大量データを速く簡単に処理
(2014年くらいまではHadoopが主流だった。Glueでの主流もPySpark。)

Glue内の動作イメージ

スクリプト
glue_job_script.py
# 必要なライブラリをインポート
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
# コマンドライン引数からジョブ名と追加パラメータを取得
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'input_path', 'output_path'])
# Spark環境の準備
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 入出力パスを設定
input_path = args['input_path']
output_path = args['output_path']
# CSVファイルを読み込み
dynamic_frame = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={"paths": [input_path]},
format="csv",
format_options={"withHeader": True}
)
# Parquet形式で保存
glueContext.write_dynamic_frame.from_options(
frame=dynamic_frame,
connection_type="s3",
connection_options={"path": output_path},
format="parquet"
)
# ジョブを終了
job.commit()
CLI
手動だと、CLIは一応あるけど、返りがないのでコンソールからRunしてた
cli
aws glue start-job-run \
--job-name process_csv_to_parquet \
--profile XX
aws glue get-job-run \
--job-name process_csv_to_parquet \
--run-id XX \
--profile XX
動作結果
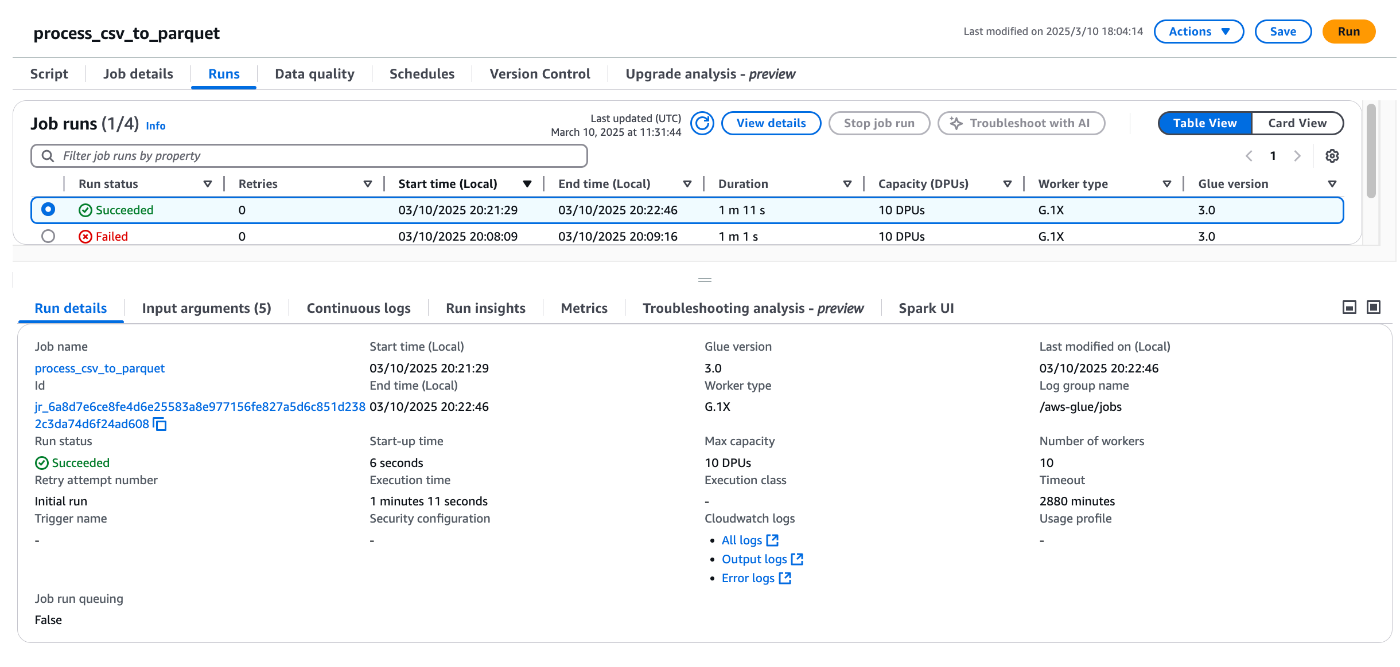
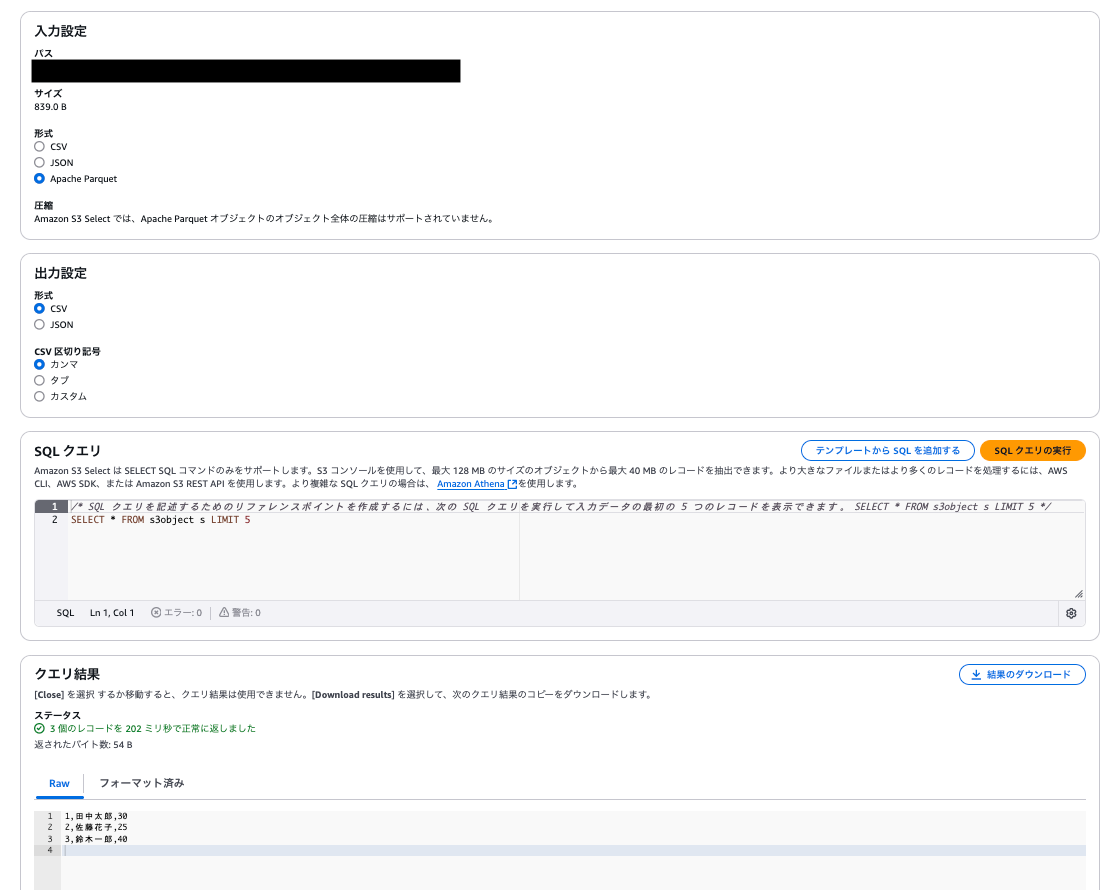
parquet確認
s3 selectで簡単にできる
このスクラップは5ヶ月前にクローズされました