Closed1
DataBricksでデータ分析
機能制限があるけど、検証アカウントがすぐとれた。
- S3同期
IAMロールを使う方法と、クレデンシャルをそのままつかう方法があるもよう。IAMロール(インスタンスプロファイル)をクラスタに紐づければできるようになるっぽいが、機能制限状態だとコンピュートでのクラスタが作れなかったのでできないっぽい。クレデンシャルは使いたくなかったので諦めた。
-
検証版
-
製品版
そもそもクラスタじゃなくてコンピュートになってる

インスタンスプロファイルはここから設定ぽい(製品版)

なのでサンプルデータは一旦DataBricks上のボリュームに配置。

※ 参考
- ジョブの作成
コードはワークスペースのノートブックもしくはGitHubから連携可能。ノートブックはそのままジョブに流用できる。Glueで使ってた、SparkやDataFrameも利用できることも確認。
Delta テーブルについて
Databricks で業務データを扱う際には、まずは Delta テーブルを採用するのがベストプラクティスです。Delta テーブルは、Databricks の Delta Lake ストレージ層を使ったテーブル形式で、次の特徴を備えています。
ACID トランザクション:読み書き操作の原子性・一貫性を保証
スキーマ管理:書き込み時に構造違反を検知し、安全なスキーマ変更をサポート
タイムトラベル:過去バージョンのデータをクエリ可能
高速クエリ:統計情報によるデータスキッピング&Z-Ordering でスキャン量を削減これらにより、高信頼・高性能な分析基盤を簡単に構築できます。
テストの処理としては1つめのジョブで2つのデータを結合し、2つめのジョブはSQLのみでデータカウントだけを行なった。

- ワークフロー作成
ワークフローの中にタスクを作成して、そのなかでノートブックを指定する

実行結果(テーブルが作成された)
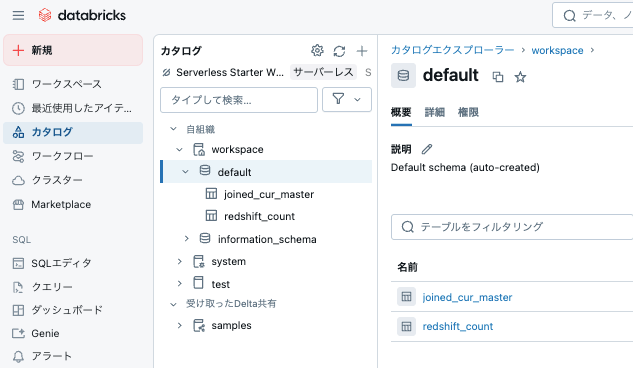
SQLで正常にデータが取得できることを確認
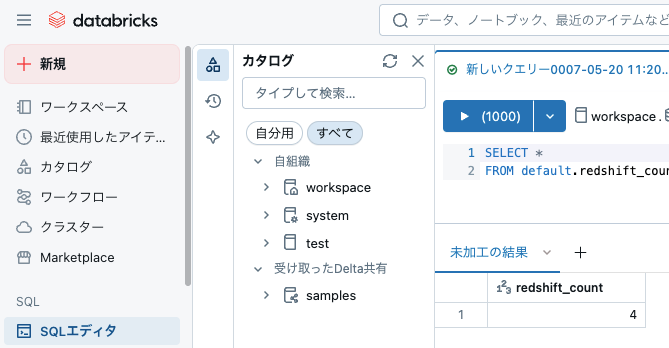
※ 使ったコード
このスクラップは3ヶ月前にクローズされました