他システムデータベースとの連携の仕組みをAWS DMSを使って構築する
他システムが管理しているマスターデータを参照する必要が出てきて、AWS DMSを使って仕組みを構築したので、そのやり方を残しておきます。
DMSの設定方法については、社内のいばらきさん、nkmrkzさんと試行錯誤しながら理解を深めていきました。
データベース連携方式について
今回は、以下のように他のシステムで使用しているデータベースへの参照(更新はしない)を実現したいケースを考えます。

その際、以下の方法が選択肢として上がります。
- 他システムのデータベースを直接参照する
- 別のデータベース(所有しているデータベースなど)にコピーしてそれを参照する
一見すると、参照するだけであれば他システムのデータベースを直接見にいけば良いと思うかもしれません(実際、自分も最初はこの方法を取ろうとしていました)が、よく考えると以下のようなデメリットがあります。
- 他システムの性能に影響を受ける、与える
- 所有しているデータベースのテーブルとの結合などができない
- 他システムのデータベースの変更の影響を受ける(取得したいデータのカラム名変更など)
- 後述しますが、こちらに関してはDMSを使っても解消しきれませんでした
正直、実現の難易度としては、直接参照が楽なんですが、上記のようなデメリットがあり、あまりスマートな方法と言えないので、2つ目の選択肢である所有しているデータベースへのコピーについて検討し始めました。
真っ先に思いつくのは、定期的に動かすバッチ処理のコードを用意して、変更があったデータをinsert、updateする方針です。ただ、物理削除を行った時の差分を追うのが面倒だったり、そもそも実装するのにコストがかかったり、いろいろ課題はありそうです。このまま実装を開始するか悩んでいたのですが、メンバと議論をしている中で、AWSの資格試験の問題でちょいちょい登場する、DMSでできるのではないか?という話になりました。
DMSとは
AWSが提供しているデータベースの連携を支援するサービスで、以下のような特徴があります。
- 継続的なレプリケーションが可能
- 異なるデータベース間のデータ連携も対応
用途としては、1度きりの移行と継続的なレプリケーションが主となってくると思いますが、今回は後者の用途として使用します。また、異なるデータベース間での連携も対応しているので、今回のようなPostreSQL→MySQLの連携にも対応できます!
具体的な手順
CloudFormationで作成したため、その内容を記述します。
実際には1つのYAMLファイルで記載していますが、リソース単位に分けて記載します。
全体の構成としては以下のようになります。
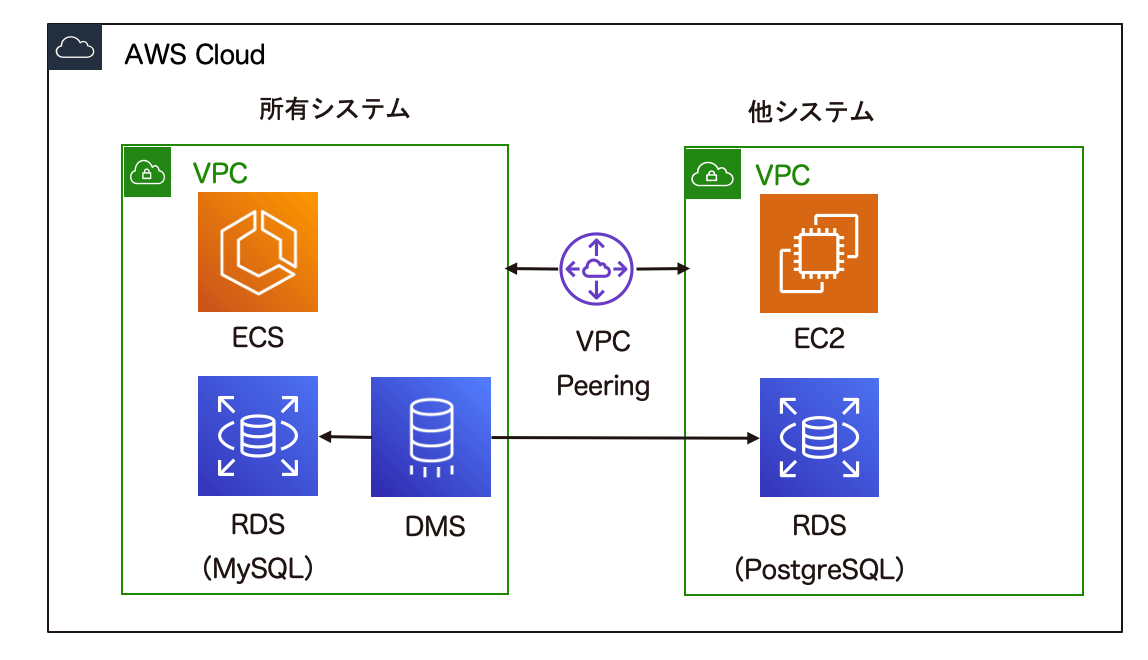
レプリケーションインスタンスの構築
まずはDMSのタスクを動かすインスタンスを構築します。
インスタンスをどのサブネットに配置するかを、サブネットグループを使って指定するため、こちらもあわせて作成しています。
少し記述は長いですが、特に難しいことはありません。
Parameters:
ProjectName:
Description: Project name
Type: String
AllowedPattern: "[a-zA-Z][a-zA-Z0-9]*"
ProjectEnv:
Description: Environment of project
Type: String
AllowedValues:
- stg
- prd
InstanceClass:
Description: Instance Class
Type: String
AllowedValues:
- dms.t3.micro
- dms.t3.small
Subnet1:
Description: Subnet 1
Type: AWS::EC2::Subnet::Id
Subnet2:
Description: Subnet 2
Type: AWS::EC2::Subnet::Id
Resources:
DMSSubnetGroup:
Type: AWS::DMS::ReplicationSubnetGroup
Properties:
ReplicationSubnetGroupDescription: !Sub ${ProjectName}-${ProjectEnv}-dms-subnet-group
ReplicationSubnetGroupIdentifier: !Sub ${ProjectName}-${ProjectEnv}-dms-subnet-group
SubnetIds:
- !Ref Subnet1
- !Ref Subnet2
DMSInstance:
Type: AWS::DMS::ReplicationInstance
DependsOn: DMSSubnetGroup
Properties:
ReplicationInstanceClass: !Ref InstanceClass
ReplicationInstanceIdentifier: !Sub ${ProjectName}-${ProjectEnv}-dms-instance
PubliclyAccessible: false
ReplicationSubnetGroupIdentifier: !Ref DMSSubnetGroup
VPCピアリングの設定
今回は、異なるVPCにあるデータベース間でのレプリケーションを行うため、VPCピアリングの設定が必要となります。
以下の記事を参考にさせていただきました。
ソース(PostgreSQL)のパラメータグループの変更
DMSでは、レプリケーションを行う際に、PostgreSQLのロジカルレプリケーションという機能を使います。
なので、RDSのパラメータグループのlogical_replicationを0→1へ変更します。
ロジカルレプリケーションに関する詳しい説明はこの記事では省きますので、以下記事など参考にしてください。
エンドポイントの構築
続いて、エンドポイントの構築部分です。ソース(参照したいDB)、ターゲット(所有しているシステム側のDB)それぞれの設定が必要となります。
いずれの設定も基本的にはシンプルですが、ソース側のPostgreSqlSettingsのプロパティのみ注意が必要なので説明します。
実は、こちらの設定を行わなかった場合、ソース側のDBの内容にほとんど変更が入らないケースだとRDSのディスク容量がだんだん圧迫されていき、最終的にはDBの容量不足になるという罠があります。
最初この現象が起きた時、ターゲット側ならまだしも、ソース側でなんでこんな現象が起きるんだ?と訳がわかりませんでしたが、AWSのドキュメントに以下の記述がありました。
WAL ハートビート機能は、アイドル状態の論理レプリケーション スロットが古い WAL ログを保持し続けて、ソース上のストレージを一杯にすることがないように、ダミー トランザクションを模倣しています。このハートビートは restart_lsn を移動し続けるため、ストレージがいっぱいになるシナリオを回避できます。
なにやら難しいことが書いてありますが、先程説明した論理レプリケーションの仕組みが絡んでいて、DBに変更がない場合には、ダミーのトランザクションを発行することでログが蓄積され続けるのを防いでくれるみたいです(すみません、正確に理解できてないのでほぼ引用文のなぞりです)。
ドキュメントに記載の通り、PostgreSqlSettingsのHeartbeatEnable、HeartbeatSchemaの設定を行います。
ソース
Parameters:
SourceDBEndpoint:
Description: Source DB Endpoint
Type: String
SourceDBUserName:
Description: Source DB User Name
Type: String
SourceDBPassword:
Description: Source DB Password
NoEcho: true
Type: String
Resources:
DMSSourceEndpoint:
Type: AWS::DMS::Endpoint
Properties:
EndpointIdentifier: !Sub ${ProjectName}-${ProjectEnv}-dms-source-endpoint
EndpointType: source
EngineName: postgres
ServerName: !Ref SourceDBEndpoint
DatabaseName: source_dbname // 各自変更が必要
Username: !Ref SourceDBUserName
Password: !Ref SourceDBPassword
Port: 5432
PostgreSqlSettings:
HeartbeatEnable: true
HeartbeatSchema: source_schema_name // 各自変更が必要
ターゲット
Parameters:
TargetDBEndpoint:
Description: Target DB Endpoint
Type: String
TargetDBUserName:
Description: Target DB User Name
Type: String
TargetDBPassword:
Description: Target DB Password
NoEcho: true
Type: String
Resources:
DMSTargetEndpoint:
Type: AWS::DMS::Endpoint
Properties:
EndpointIdentifier: !Sub ${ProjectName}-${ProjectEnv}-dms-target-endpoint
EndpointType: target
EngineName: mysql
ServerName: !Ref TargetDBEndpoint
Username: !Ref TargetDBUserName
Password: !Ref TargetDBPassword
Port: 3306
タスクの構築
最後に、タスクの構築です。ポイントとしては、継続的なレプリケーションを行いたいため、MigrationTypeをfull-load-and-cdcとしている点と、TableMappingsのjsonの書き方です。
jsonの部分は若干複雑に見えますが、以下の例では、3つのことを行っています。
- スキーマ名の変換(ソースとターゲットでスキーマ名が違うため)
- レプリケーションするテーブルの指定
- レプリケーションするカラムの指定
公式ドキュメントでは、以下に説明が記載してあります。
Resources:
DMSTask:
Type: AWS::DMS::ReplicationTask
DependsOn:
- DMSInstance
- DMSSourceEndpoint
- DMSTargetEndpoint
Properties:
MigrationType: full-load-and-cdc
ReplicationInstanceArn: !Ref DMSInstance
SourceEndpointArn: !Ref DMSSourceEndpoint
TargetEndpointArn: !Ref DMSTargetEndpoint
TableMappings: |
{
"rules": [
{
"rule-type": "transformation",
"rule-id": "000000001",
"rule-name": "000000001",
"rule-target": "schema",
"object-locator": {
"schema-name": "source_schema_name"
},
"rule-action": "rename",
"value": "target_schema_name",
"old-value": null
},
{
"rule-type": "selection",
"rule-id": "000000002",
"rule-name": "000000002",
"object-locator": {
"schema-name": "source_schema_name",
"table-name": "source_table1"
},
"rule-action": "include",
"filters": []
},
{
"rule-type": "transformation",
"rule-id": "000000003",
"rule-name": "000000003",
"rule-target": "column",
"object-locator": {
"schema-name": "source_schema_name",
"table-name": "source_table1",
"column-name": "source_table1_column1"
},
"rule-action": "include-column",
"value": null,
"old-value": null
}
]
}
検証・まとめ
記載したCloudFormationを流すことで、指定したスキーマ・テーブル・カラムのデータのレプリケーションが成功するはずです。
今回設定したのが、継続的なレプリケーションということで、移行元のデータをいろいろいじった時にどのような挙動になるか確認してみました。
- 新規データの追加
- 成功!意図通り、移行先のテーブルにもデータが追加されました。
- データの削除
- 成功!意図通り、移行先のテーブルからデータが削除されました。
- 取得元のテーブルにカラム追加
- 影響なし!
- 取得元のカラムの名称変更
- 対応する移行先のカラム・データが消される。。
最後の結果だけ、期待に反した結果になりました(変更前のデータは残しておいて欲しかった)。マスターデータのため、あまりこのようなケースはないのと、開発環境で気づけるため一旦この挙動を許容していますが、きちんとやろうと思うと、DMS用のユーザを作って、カラムの削除はできないように設定するなどの対応が必要かもしれません。
Discussion