この記事は OPENLOGI Advent Calendar 2023 21日目の記事です。
前職にて、
全文検索サービスのalgoliaで検索システムを実装したことがあったので、
これを機会に簡単にまとめたいと思います。
この記事では言及しないこと
全文検索にはElasticsearch等他のサービスもあるかと思いますが、
自分は触ったことがないので、比較等はせずalgoliaに関してのみ記載します。
全文検索とは
algoliaの話を進める前に、全文検索に関して軽く説明します。
全文検索とは
入力したキーワードに該当しそうなデータを探し出すものです。
「該当しそうな」と記載したのが特徴で、曖昧検索ができるのが良い点です。
曖昧検索といえばSQLのLIKE句でも可能ですが、
全文検索の方がより融通をきかしてマッチするデータを取得することができます。
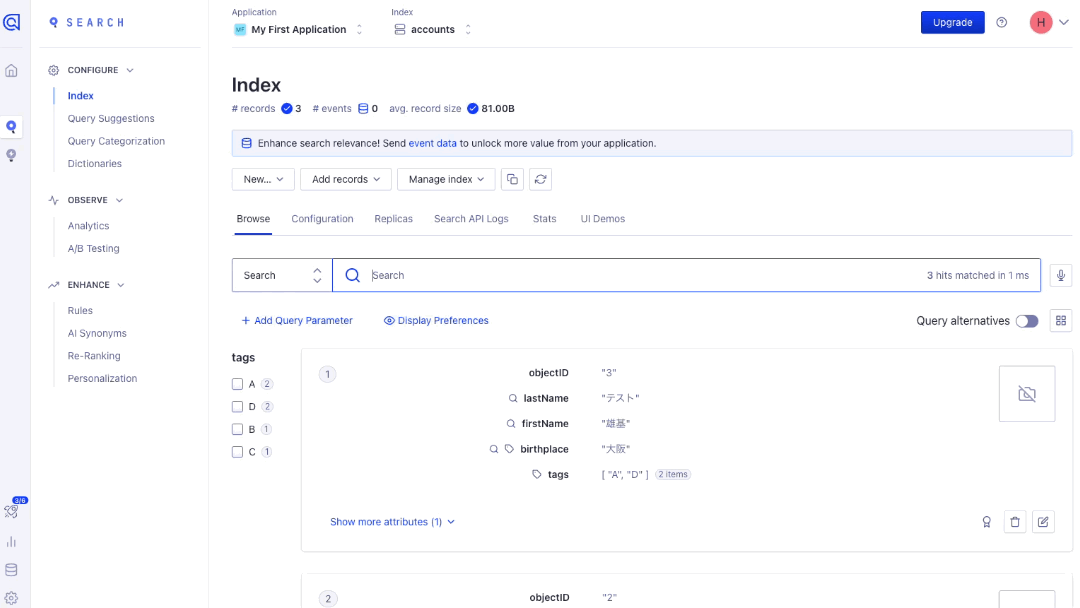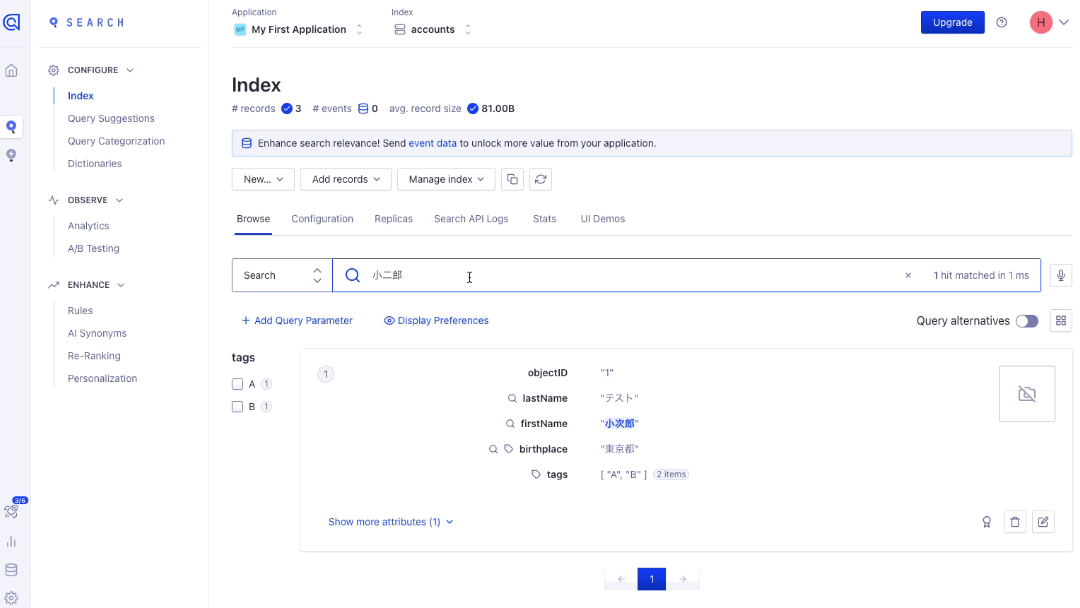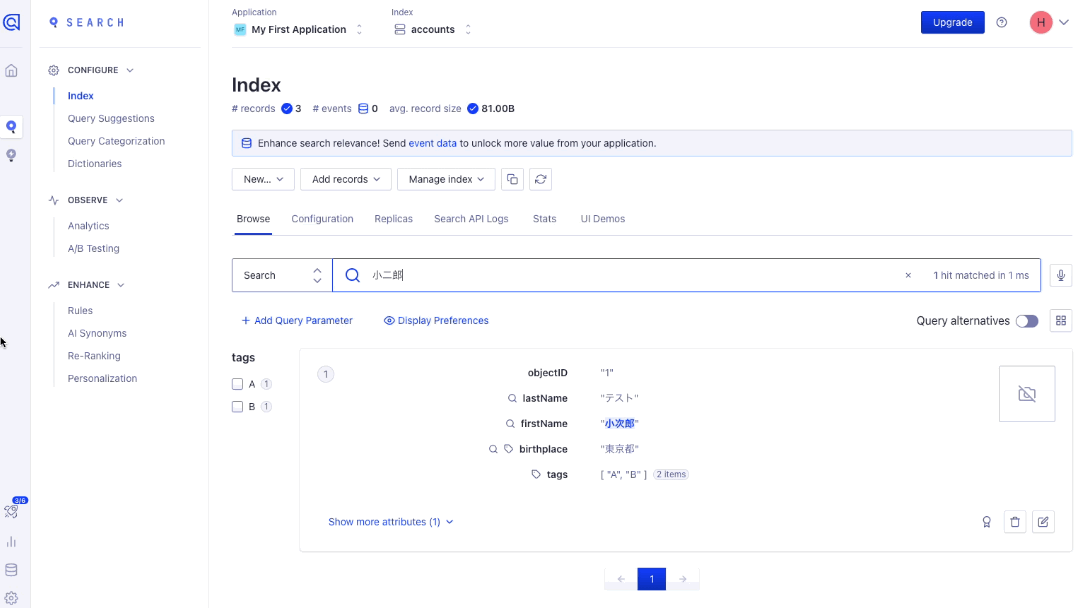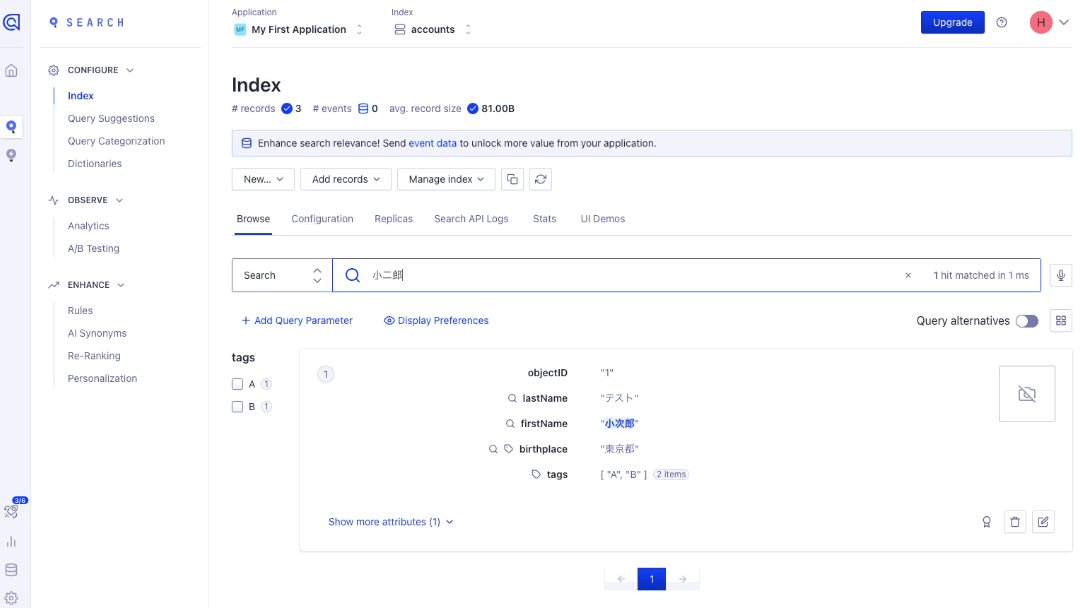
例えば、
下記のようなアカウントのデータあり、「小次郎」と検索をする場合において、
| id | firstName | fastName |
|---|---|---|
| 1 | 小次郎 | テスト |
| 2 | 花子 | テスト |
| 3 | 雄基 | テスト |
MySQLのLIKE句では「小次郎」の場合はマッチしますが、「小二郎」の場合はマッチしません。
SELECT * FROM accounts WHERE firstName LIKE '%小次郎%'; <- ◯
SELECT * FROM accounts WHERE firstName LIKE '%小二郎%'; <- ×
ですが、
全文検索ではこれら両方ともマッチします。
なので、
ユーザー側の入力ミスを全文検索の方がカバーしてくれるので、
結果としてLIKE句よりもサービスの利便性が良くなる傾向にあると思います。
algoliaとは
この全文検索をSaaSとして提供しているサービスになります。
特徴としては、
サービス開発者側はalgoliaにデータの保存と簡単な設定のみで、
高精度、かつ、高パフォーマンスの全文検索を即座に利用できます。
また、
様々な言語でライブラリを提供しているので、自社システムに組み込むのも簡単にできます。
なので、
全文検索の知識があまりない方でも、高品質な検索システムが簡単に作れます。
今回はPHPで下記の手順で軽くデータを作っていきたいと思います。
- データを用意する
- 設定をする
- 検索をする
事前準備
まずはalgoliaが提供しているライブラリをインストールします。
1.データを用意する
algoliaのデータを用意する際には、
indexを作成し、そこにrecordを追加していく必要があります。
indexとは、DBでいうテーブルのこと。
recordとは、DBでいう各行のデータのことを指しています。
objectという表記もありますが、recordと同じニュアンスと思ってもらえれば良いです。
ここでは下記の2つのデータを作成します。
- accounts
- articles
※ なぜ記事が少し代わった形で保存しているかは注意点の欄で説明します。
<?php
require __DIR__."/vendor/autoload.php";
use algolia\algoliaSearch\SearchClient;
$client = SearchClient::create("app_id", "key");
// indexを指定
$accountIndex = $client->initIndex("accounts");
$accountRecords = [
[
"objectID" => "1",
"accountId" => 1,
"firstName" => "小次郎",
"lastName" => "テスト",
"birthplace" => "東京都",
"tags" => ["A", "B"]
],
[
"objectID" => "2",
"accountId" => 2,
"firstName" => "花子",
"lastName" => "テスト",
"birthplace" => "東京都",
"tags" => ["C", "D"]
],
[
"objectID" => "3",
"accountId" => 3,
"firstName" => "雄基",
"lastName" => "テスト",
"birthplace" => "大阪",
"tags" => ["A", "D"]
],
];
// indexに指定したobjectを保存する
$accountIndex->saveObjects($accountRecords)->wait();
$articleIndex = $client->initIndex("articles");
$articleRecords = [
[
"objectID" => "1-1",
"articleId" => 1,
"title" => "物流の未来を、動かす",
"content" => "「物流をもっと簡単に、シンプルに」
その想いをもとに立ち上がった私たちは、
もうはるか先を見据えている。
目指すは、物流から生まれる、新たな価値と経済圏だ。
",
],
[
"objectID" => "1-2",
"articleId" => 1,
"title" => "物流の未来を、動かす",
"content" => "物流はこれから、テクノロジーがより浸透し、
ダイナミックに変化する。
これまでアナログだった物の流れがデジタルになり、
高効率化された未来が到達する。
私たちは、
物流の進化から、経済が新たに活性化する次世代のインフラを作り、この時代の変革を、
物流に関わる多くの情熱たちと共に成し遂げます。",
],
[
"objectID" => "2",
"articleId" => 2,
"title" => "algoliaとは",
"content" => "algolia は、高品質で関連性の高い検索を必要とするユースケース向けに設計された 独自のサービスとしての検索プラットフォームです。",
],
[
"objectID" => "3",
"articleId" => 3,
"title" => "test",
"content" => "hogehogehoge",
],
];
$articleIndex->saveObjects($articleRecords)->wait();
2. 設定をする
日本語検索をする予定なので、
indexを作成後は、各indexに対して設定を行っていきます。
<?php
require __DIR__."/vendor/autoload.php";
use algolia\algoliaSearch\SearchClient;
$client = SearchClient::create("app_id", "key");
$accountIndex = $client->initIndex("accounts");
$accountIndex->setSettings([
'indexLanguages' => ['ja'],
'queryLanguages' => ['ja'],
'minWordSizefor1Typo' => 3,
'searchableAttributes' => [
'unordered(lastName)',
'unordered(firstName)',
'unordered(birthplace)',
],
'attributesForFaceting' => [
'tags',
'filterOnly(birthplace)'
]
]);
$articleIndex = $client->initIndex("articles");
$articleIndex->setSettings([
'indexLanguages' => ['ja'],
'queryLanguages' => ['ja'],
'attributeForDistinct' => 'articleId',
'searchableAttributes' => [
'unordered(articleId)',
'unordered(title)',
'unordered(content)',
],
]);
各種設定項目
indexLanguagesとqueryLanguages
algoliaはデフォルトでは汎用的な設定になっているので、
下記の設定で日本語向けに設定してます。
- indexLanguages
- queryLanguages
詳細な説明はこちらをご確認ください
minWordSizefor1Typo
指定した文字以下の単語に対しては1つのタイポミスを許容します。
accountの例で言うと、
「小二郎」と入力した際に「小次郎」でも検索がかかるように、
今回は3文字以下の単語に対しては1つのタイポミスが許容されるように設定しています。
※ デフォルトは4文字になります。
searchableAttributes
検索可能な項目を指定する際に設定します。
デフォルトだと全ての項目が検索対象になっているので指定しています。
ただ、
この設定項目は検索対象以外にも、検索時の優先順位にも関わってきます。
具体的には
設定した項目の順番がそのまま検索時の優先順位になってしまいます。
そのため、
unorderedというのをつけて、検索時の優先度を順不同にしてます。
attributeForDistinct
重複を削除する際の項目を指定します。
attributesForFaceting
Facetsで使用する項目を設定します。
詳しくは検索時に必要になるため、後述で説明します。
検索をする
indexの用意と設定ができたので、実際に検索してきます。
検索は下記のコードになります。
<?php
require __DIR__."/vendor/autoload.php";
use algolia\algoliaSearch\SearchClient;
$client = SearchClient::create("app_id", "key");
$index = $client->initIndex("accounts");
$results = $index->search("小二郎");

これでsearchableAttributesで設定した項目の中から、
該当するキーワードにマッチするデータを取得できます。
ただし、
この例ではあくまで曖昧検索しかできません。
例えば、
SQLのようなWHERE句のようなフィルタリングをするには工夫が必要です。
なので、
軽く様々な検索方法を紹介したいと思います。
様々な検索方法
WHERE句のような検索をしたい場合
WHERE句のような検索をしたい場合は、Facetsを使います。
Facetsとはカテゴリーのようなもので、
選択されたカテゴリーに関連する結果と数を取得できますが、
検索としてのフィルタリング機能としても使えます。
Facetsを使う際は、
indexにてattributesForFacetingに対象となる項目を設定する必要があります。
アカウントのindexの例では、タグ(tags)と出身地(birthplace)を設定していました。
※ 出身地に対してfilterOnlyで囲っているのは、検索時の絞り込みの用途でのみ使う場合に指定します。
<?php
...
$accountIndex->setSettings([
...
'attributesForFaceting' => [
'tags',
'filterOnly(birthplace)'
]
...
]);
検索時は、
filetersのオプションにFacetsの値を指定すると絞り込み検索ができます。
$result3 = $index->search("テスト", [
'filters' => 'birthplace:東京都'
]);
他にどのような条件で検索できるかは下記をご確認ください
複数のindexを同時に検索したい場合
今回の例のようにアカウントと記事を同時に検索したい場合は、
multiple queriesという機能を使います。
サンプル
<?php
$keyword = "テスト";
$queries = [
[
'indexName' => 'accounts',
'query' => $keyword,
],
[
'indexName' => 'articles',
'query' => $keyword,
'params' => [
'distinct' => 1, // 検索時にattributeForDistinctに基づいて重複を削除する
],
],
];
$results = $client->multipleQueries($queries);
導入してよかった点
簡単な設定で高精度・高パフォーマンスの検索システムを作れる
短期間でサービスをリリースをしないといけない状況下の中で、
データの用意と簡単な設定のみで、高精度の検索システムを作れたのは大変ありがたかったです。
また、
検索速度に関しても
新規事業だったこともあり一番多いテーブルでも最大約10万件しかなかったですが、
4つのindexを同時検索を行った場合でも、
1秒未満で瞬時にデータが返ってくるほどパフォーマスに関しては十分な性能がありました。
どの単語にマッチしたかわかるようになっている
algoliaの返り値の_highlightResultにマッチした単語を強調した状態の値も含まれてます。
{
"firstName": "テスト",
"lastName": "雄基",
"birthplace": "大阪",
"tags": [
"A",
"D"
],
"objectID": "3",
"_highlightResult": {
"firstName": {
"value": "<em>テスト</em>",
"matchLevel": "full",
"fullyHighlighted": true,
"matchedWords": [
"テスト"
]
},
"lastName": {
"value": "雄基",
"matchLevel": "none",
"matchedWords": []
},
"birthplace": {
"value": "大阪",
"matchLevel": "none",
"matchedWords": []
}
}
},
なので、
検索結果にて、どの単語にマッチしたかのUIもすぐ作れちゃうのはとても便利でした。
注意点
1recordあたりの保存容量に制限がある
algoliaで保存できる1recordの容量はプランによりますが、10 KB ~ 100 KBです。
なので、
記事などの容量が大きいデータは分割して保存する必要があります。
今回のサンプルとしての記事indexは、
容量が大きいデータの例として分割保存をしました。
[
"objectID" => "1-1",
"articleId" => 1,
"title" => "物流の未来を、動かす",
"content" => "「物流をもっと簡単に、シンプルに」
その想いをもとに立ち上がった私たちは、
もうはるか先を見据えている。
目指すは、物流から生まれる、新たな価値と経済圏だ。
",
],
[
"objectID" => "1-2",
"articleId" => 1,
"title" => "物流の未来を、動かす",
"content" => "物流はこれから、テクノロジーがより浸透し、
ダイナミックに変化する。
これまでアナログだった物の流れがデジタルになり、
高効率化された未来が到達する。
私たちは、
物流の進化から、経済が新たに活性化する次世代のインフラを作り、この時代の変革を、
物流に関わる多くの情熱たちと共に成し遂げます。",
],
分割して保存しているため、検索時は同じデータが複数取れる可能性があるので、
コードあるいは、algoliaの設定を用いて重複削除する必要があります。
※ 今回はalgoliaの設定で重複削除しました。
Facetsの検索の絞り込みには制限がある
Facetsを使ってBoolean検索(AND,OR,NOT)をする場合は、
指定できる条件に幾つかの制約があります。
そのため、
検索対象がこの制約に該当しないかは確認した方が良いです。
JOINが使えない
algoliaはリレーショナルな構造ではないので、
MySQLのようなテーブル同士を結合することができません。
なので、
検索対象のデータが、
他のテーブルの状態に依存するような場合、よく検討した方が良いです。
経験談として、
他のテーブルのデータの公開状態に依存するようなデータを取り扱った際に、苦労をしました。
具体的には、
下記のようなテーブル構造のデータをalgoliaで検索するために保存していました。
Aテーブル
| id | name | 公開状態 |
|---|---|---|
| 1 | A | 公開中 |
| 2 | B | 非公開 |
| 3 | C | 公開中 |
Bテーブル
| id | a_id | title | 公開状態 |
|---|---|---|---|
| 1 | 1 | 記事1 | 公開中 |
| 2 | 1 | 記事2 | 公開中 |
| 3 | 1 | 記事3 | 公開中 |
構造的には、
テーブルBのデータを取得する際はAとBの公開状態を確認する必要がありました。
そのため、
上記で説明したようにJOINはできないので、下記の問題が発生しました。
- データAを非公開中でも、algolia上ではデータBは公開中のため、取得できてしまう
- 更新に時間がかかる場合、検索結果に非公開中のデータが表示され、 遷移すると404になる
この時は、
Aの公開状態を更新する頻度が滅多にないことと、
Aを非公開時に関連するBのデータを一括更新する形で対応しましたが、
このように他のテーブルの状態に依存するほど、複雑になります。
まとめ
以上になりますが、
無料枠もありますのでもし興味がある方はぜひ一度algoliaを使ってみてください

Discussion