多言語対応の視覚音声認識モデル "Zero-AVSR" を動かす【論文】
Zero-AVSR: Zero-Shot Audio-Visual Speech Recognition with LLMs by Learning Language-Agnostic Speech Representations[1]
TL;DR
- "AV-HuBERT"と"Llama"の知識を組み合わせることで、明示的にコーパスから学習しなくても視覚音声認識ができる
- 新しい視覚音声データセット"MARC"は、元データにラベル無しデータを用いることで対応言語数と総再生時間を大幅に増加
- 同じ「ゼロショット推論」でも、やはり学習データに含まれる言語に近い言語の方が認識精度が高い
動機
とある理由から読唇の研究に興味を持ち、中でも多言語対応かつソースが公開されているZero-AVSRを深掘りしています。
しかし、特に任意の音声・映像に対して推論を動かすのが結構しんどかったので、記事にしました。併せて論文の解説もしています。
AVSRとは?
音声認識に関する研究をASR, 読唇に関する研究をVSRといいます。また、音声と読唇の両方の情報を使って発話内容を認識する研究を AVSR (Audio-Visual Speech Recognition) といいます。
ASR, VSR, AVSRのいずれも、性能の評価にはCERやWERといった指標が用いられます。生成した文字起こしと教師データを比べて、文字や単語レベルでどれだけ誤りが少ないかを測る指標です。
Zero-AVSRについて
Zero-AVSRは、2025年3月にarXivにて初版が公開された、多言語対応のAVSRフレームワークです。
構成を大きく分けると、音声・読唇情報をローマ字に変換する "AV-Romanizer" と、ローマ字を文章に変換するLLMの2段から成り立っています。特に "AV-Romanizer" は、音声と読唇のデファクトの特徴抽出器の1つである "AV-HuBERT" のヘッドをローマ字分類タスク用にファインチューニングしたモデルとなっており、全体像を読み解くのが少々大変でした。詳しく解説します。
先行研究: HuBERT および AV-HuBERT
音声データを連続するベクトルとして表現するモデルのうち、Metaが自己教師あり学習を用いて開発したのがHuBERTです。AV-HuBERTはHuBERTを音声・視覚に拡張したモデルです。
ごく簡単に言えば、HuBERTは音声ファイルを20msごとのフレームに分割し、それぞれのフレームを256~1024次元(モデルサイズによって異なります)のベクトルに変換するモデルです。次のデモでは、HuBERTによって4秒の音声を200フレームのベクトルに変換し、低次元に投影しています。
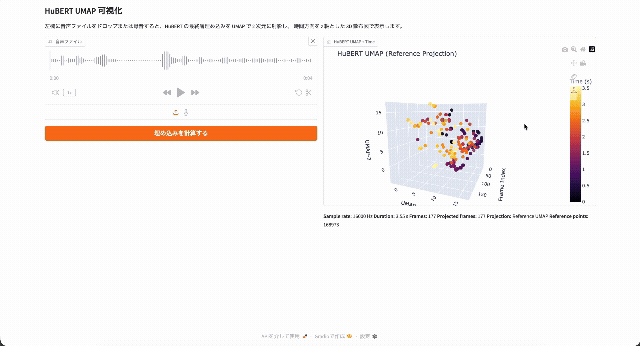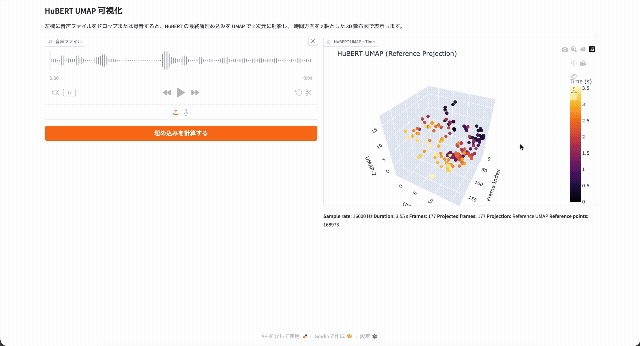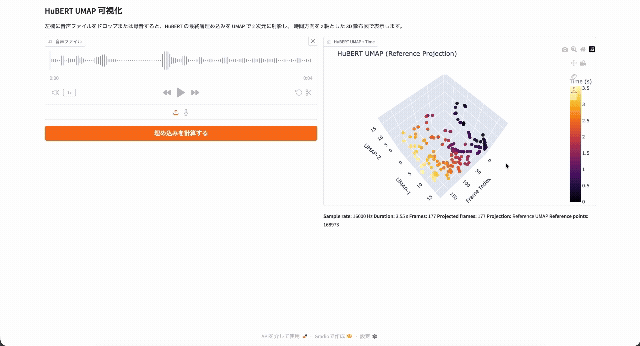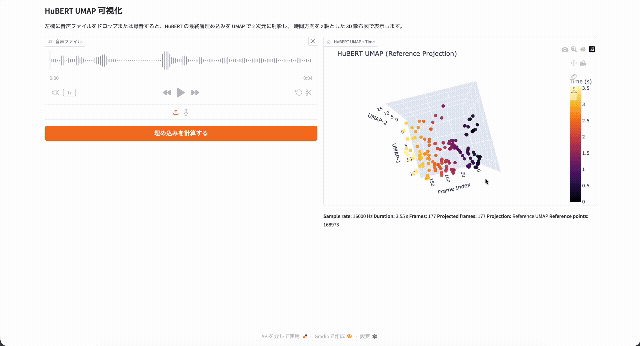
評価の際は、ベクトルに変換した上で、さらに下流タスクごとに異なるヘッドを装着して推論を行います。TransformersのHubertのドキュメントにも、HubertForCTCやHubertForSequenceClassificationといったタスク別のクラスが定義されています。
Stage1: Cascaded Zero-AVSR
Zero-AVSRには2種類あります。初めにご紹介するのは、よりシンプルなCascaded Zero-AVSRです。
ごく簡単に言えば、音声と口パク映像から発音をローマ字として出力し、それをgpt-4o-miniに投げて文章化する、という構成です。
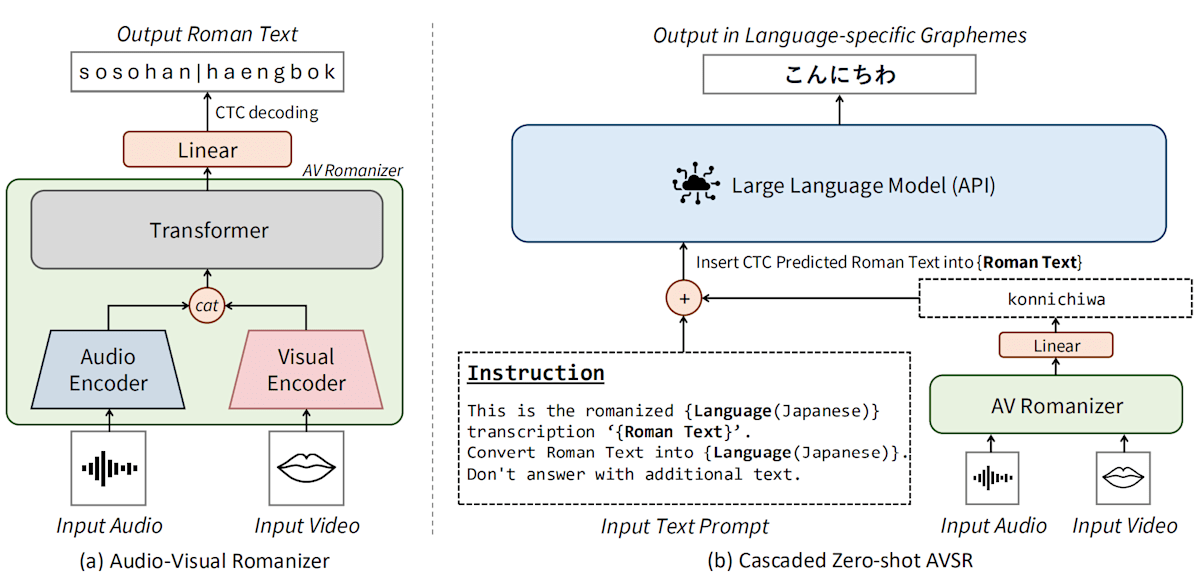
本構成の中心になるのは、視覚・音声入力をローマ字に変換するAV-Romanizerです。AV-HuBERTのアーキテクチャを改変・追加学習しています。具体的には、AV-HuBERTの離散クラスタを推定する分類ヘッドを削除し、代わりにローマ字列を生成するCTCヘッドを付与しています。
個人的に追加学習前後の比較表を作成しました。特に特徴抽出レイヤー (feature_extractor_audio.proj.bias, feature_extractor_video.proj.bias) のノルムの相対的な変化量が大きく、コサイン類似度が低いことが分かります。
Stage2: (Directly Integrated) Zero-AVSR
本論文では、Cascated Zero-AVSR とは異なり、音声・読唇から抽出した特徴をそのまま埋め込みとしてLLMに統合するアーキテクチャも提案されています。論文ではこちらを単に Zero-AVSR とよんでいます。本記事では、特に Cascaded Zero-AVSR と区別したい場合に Directly Integrated Zero AVSR と呼ぶことにします。次のようなアーキテクチャです。
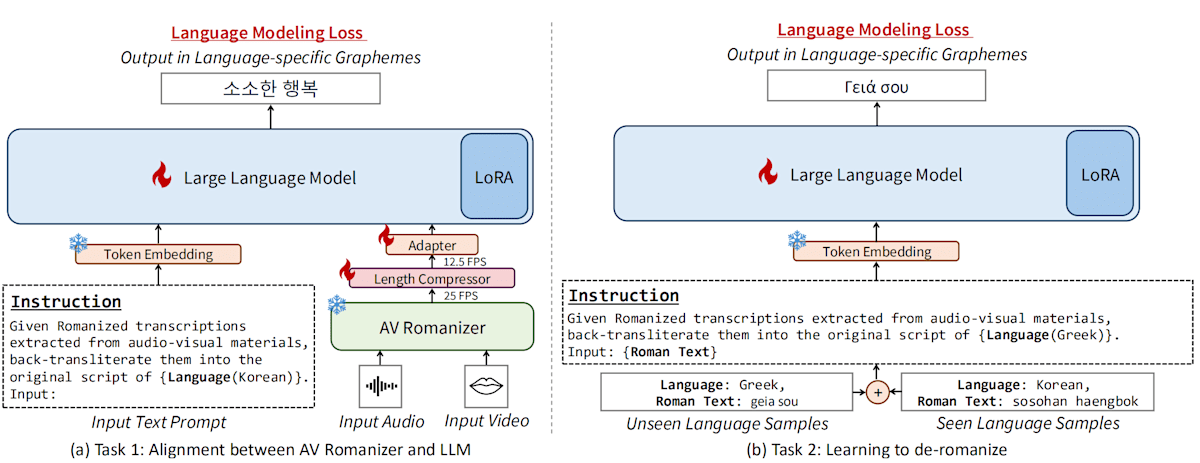
生の視覚音声埋め込みは、Llamaに入力可能な形式に変換するために時間方向に圧縮&線形層2段からなるアダプターで変形されています。
(Directly Integrated) Zero-AVSRの学習は、次の2段階からなります。
- アダプターの学習。といっても、アダプターのみを学習するのではなく、視覚・音声入力+プロンプトから脱ローマ字化された文章までを一気通貫で推論・逆伝播させる。これは複数種類の言語で行う。
- LLMの追加学習を行う。1段階目の学習対象だった言語に引っ張られすぎないように、さらに多くの種類の言語で学習する。
こちらも、追加学習前後の比較表を公開しています。LlamaのLoRAについてはまんべんなく学習されている印象です。
Zero-AVSRを評価する
Zero-AVSRのリポジトリには、fairseqで評価用のタスクが定義されており、スクリプトもあります。そこで、実際に動かすための手順をご紹介します。
MARC を用意する
まず、多言語の視覚音声ローマ字化コーパスであるMARCを準備します。
リポジトリの手順にしたがって、MARCデータセットを用意します。私はその中でも、MuAViCから生成できる分のみを対象にしました。UVで動くフォーク版を用意したので、よければご活用ください。
MuAViCのデータは言語ごとに構築することになります。私は一番サイズの小さそうなドイツ語で試しましたが、それでも最終的に1.7GB(中間ファイル込みだと7GB程度)になります。言語によっては30GBを超えるので注意してください。言語ごとのファイルサイズを測るには、MuAViCデータセットの元データの字幕などをホストするOpenSLRを確認するのが良いと思います。
MARCデータセットの規模について、論文では82言語・2,916時間と報告されています。その元になったデータセットは4つあるのですが、LRS3(433時間, 英語, ラベルあり), MuAViC(1,200時間, 9言語, ラベルあり), VoxCeleb2(2,442時間, 多言語, ラベルなし), AVSpeech(4,700時間, 多言語, ラベルなし)となっています。ラベルなしデータセットを取り入れたことで、言語数と総再生時間が伸びていることが分かります。
Cascaded Zero-AVSR を評価する
スクリプトを実行して、Cascaded Zero-AVSRの性能を評価します。
MARCのドイツ語コーパスを対象にAVSRタスクを実行すると、Cascaded Zero-AVSR 全体でそれぞれWER: 29%, CER: 17%程度の性能が得られます。これは、論文の表2の結果とも一致します。WERとは、文章あたりの単語がどれだけ誤っているかの割合です。
実行手順については、私がフォークしたZero-AVSRのリポジトリをご覧ください。
実行の様子は次のとおりです。
% bash scripts/stage1/eval.sh
[2025-10-08 14:56:01,014][__main__][INFO] - /home/hiroga/Documents/GitHub/zero-avsr/pretrained_models/av-romanizer/all/checkpoint_best.pt
.........
[2025-10-08 15:03:54,743][__main__][INFO] - ---------------------
[2025-10-08 15:03:54,744][__main__][INFO] - HYPO: gibts su
[2025-10-08 15:03:54,745][__main__][INFO] - REF: gebt es zu
[2025-10-08 15:03:54,745][__main__][INFO] - ---------------------
[2025-10-08 15:03:54,746][__main__][INFO] - HYPO: warum dat
[2025-10-08 15:03:54,746][__main__][INFO] - REF: warum das denn
[2025-10-08 15:03:54,746][__main__][INFO] - ---------------------
[2025-10-08 15:03:54,746][__main__][INFO] - Processed 735 sentences (0 tokens) in 0.0s 735000000.00 sentences per second, 1000000.00 tokens per second)
[2025-10-08 15:03:54,748][__main__][INFO] - Word error rate: 41.5876
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 735/735 [00:00<00:00, 11753.95it/s]
Zero shot language WER, CER: 29.161822217524573, 17.073924509642328
スクリプトを実行すると、zero-avsr/evaluation/clean/stage1/${lang} 以下に推論結果が出力されます。AV-Romanizerの出力結果と、Cacaded Zero-AVSRの出力結果をそれぞれ確認することができます。
hypo.units はAV-Romanizerが出力した文字列です。次の推論結果はドイツ語を元にしていますが、出力がローマ字なのでウムラウト(ü など)が見当たりませんね。
e i n e | g a n z | k l a s s i s c h e | a r t | a c h t s a m k e i t | z u | u e b e n | d a z u | m o e c h t e | i c h | s i e | g e r n e | j e t z t | e i n l a d e n | i n d e m | s i e | d i e | a u g e n | s c h l i e s s e n | s i c h | s o | b e q u e n e n | w i e | e s | g e r a d e | g e h t | h i n s a e t z e n | u n d | d i e | a u f m e r k s a m k e i t | n a c h | i n n e n | l e n k e n | z u | i h r e m | a t e m | (None-545)
d a s s | d a s | g a n z e | n a t u e r l i c h | a u c h | m a n c h m a l | i n | f e h e n s c h l a g | i s t | o d e r | a u c h | n a c h | w i e | v o r | n a c h | h i n t e n | g e h t | i s t | m i r | j e t z t | v o r | e i l e n | d i g e n | m o c h e n | g e g a n g k e n | d a | h a t t e | i f u r | m i c h | a u s g e s e h e n | e i n e n | s u p e r j o b | a n g e b o t | f u e r | e i n e r | d e r | g r o s t e n | a u t o m o b i e l h e r s t e l l e r | d i e | k o m p l e t t e | d i g i t a l i s i e r u n g | u n d | d i e | a u t o n o m e n | a u t o s | z u | l e i t e n | a l s o | w i r k l i c h | e i n | r i e s e n j o b | a b e r | i c h | h a b e | h i c r | n i c h t | b e k o m m e n | d a | w a r | n o c h | (None-292)
...
avsr.json はGPT-4oによって補正された推論結果とGround Truthのペアです。
[
{
"Ground truth": "und genau diese frage mussten wir kollegen eines großen europäischen flugzeugherstellers beantworten\n",
"prediction": "Und genau diese Frage mussten wir Kollegen eines großen europäischen Flugzeugherstellers beantworten."
},
{
"Ground truth": "das ist eine stadt in nordspanien eine alte arbeiterstadt sehr dreckige bergarbeiterstadt\n",
"prediction": "Das in Nordspanien, dass ein alter Arbeiter statt sehr, sehr dreckige Bergarbeiter statt."
},
...
]
(Directly Integrated) Zero-AVSR を評価する
スクリプトを実行して、(Directly Integrated) Zero-AVSRの性能を評価します。MARCのデータセットを用いてドイツ語で評価しました。論文の表2同様、WER: 27%となりました。
bash scripts/stage2/eval.sh
......
[2025-10-08 19:31:24,737][__main__][INFO] -
INST:Given romanized transcriptions extracted from audio-visual materials, back-transliterate them into the original script of German, Standard. Input:
REF:gebt es zu
HYP:gibt es zu
[2025-10-08 19:31:24,737][__main__][INFO] -
INST:Given romanized transcriptions extracted from audio-visual materials, back-transliterate them into the original script of German, Standard. Input:
REF:warum das denn
HYP:warum tat er das
......
[2025-10-08 19:31:24,748][__main__][INFO] -
German WER: 27.95071335927367%
German CER: 16.331652991921707%
その他
論文では、単純にMARCデータセットで学習したモデルの精度だけでなく、例えば「イタリア語なしで学習した場合のイタリア語の認識精度」や「学習データセットに似た語族が含まれないとされる日本語での認識精度」なども計測しています。
論文の主張とは、「ゼロショット = 学習時のコーパスに明示的に含まれない言語の認識精度がMARCデータセットを用いることで改善する」というものです。これについては、単に英語からの距離が離れたことで他の言語の性能が引き上げられた可能性も検討しなくてはいけないな、と思いました。実際、論文中では多言語データセットで学習した前後の英語認識精度については触れられていませんでした。
また、(英語のみで学習したベースモデルに対して)ターゲットの語族と同じ語族の言語を追加学習した場合と、別の語族の言語を追加学習した場合、前者の方が認識精度が大幅に上がることも触れられていました。
これらの情報を総合すると、日本語向けの視覚音声認識モデルを開発する際は、日本語の学習データを十分に用意することが重要であり、他の言語の学習データではあまり代えが効かなさそう、という結論になりそうです。
感想
AV-HuBERTとLlamaのポテンシャルが分かる論文だと思いました。特にAV-Romanizerの性能については、ベースモデルのAV-HuBERTの貢献が大きいと感じます。
その理由にも関わりますが、モデルの追加学習前後の比較結果の解釈で悩んでいます。AV-Romanizerについては、視覚と音声をTransformerに向けてマッピングする層の変化が特徴的で、他の変化は大きくありませんでした。
仮説ですが、事前学習時は英語のデータが主だったのに対して、追加学習では多言語(82言語)になったことで、音・口の形と対応するローマ字・離散音声トークンにズレが生じたのかな、と予想しています。例えば、/ʃ/(硬口蓋摩擦音)をローマ字化する場合、英語では sh(ship)、フランス語では ch(chef)のような違いが生じていた可能性を考えています。
一方で、LlamaのLoRAの解釈はアイデアがありません。全層まんべんなくちょっとづつ更新されている印象でした。ちょっと普通のLlamaのLoRAも見比べてみたいです。
細かい点だと、fairseqは結構クセがあるフレームワークでキャッチアップに苦労しました。素のPyTorchと違ってトレーニングループまで管理しているので、FWの事前知識無しだとどこから読んだら良いのか全く分かりません。
まとめ
多言語に対応した視覚・音声認識モデル "Zero-AVSR" の仕組みを確認し、性能を評価しました。
Discussion