ちいかわか米津玄師か判定する機械学習モデルをPyTorchで作って公開した
みなさんは「ちいかわか米津玄師か当てるクイズ」をご存じでしょうか?米津玄師さんご本人が遊んだことでも話題です。ちなみに私は20%しか正解できませんでした。
機械学習を学ぶにあたって、このクイズを題材にしてみました。作成したモデルはこちらから誰でも遊べます!
モデルの実力は、普通のセリフならそこそこ分類できるけど、紛らわしいセリフには歯が立たないレベルでした。実際の実装・調整から学んだことを書いていきます。
TL;DR
- 当初はデータを増やせばちいかわらしさを学んでくれると思っていたが、実際には人間が特徴にアタリを付けて訓練データを用意する必要がありそう。
- 当初は学習データが100件程度だったが、2500件程度に増やしたところ損失が1/3未満になった。
- 2500件程度まで増やしてもクイズメーカーの問題には太刀打ちできなかったが、当初含まれていなかったラッコのセリフの追加は損失を数%改善した。
- データの前処理として記号の削除やスペース・改行の扱いの統一を行ったが、クイズメーカーの問題への損失を改善はできなかった。
- クイズメーカーの問題に太刀打ちできるように層の追加やLearning Rateの調整を試みたが、改善どころかむしろ過学習が起こり損失が悪化した。
訓練方法について
筆者は機械学習の初学者なので、記載内容が誤っている可能性が十分あります。間違いにお気づきでしたらぜひ教えてください。
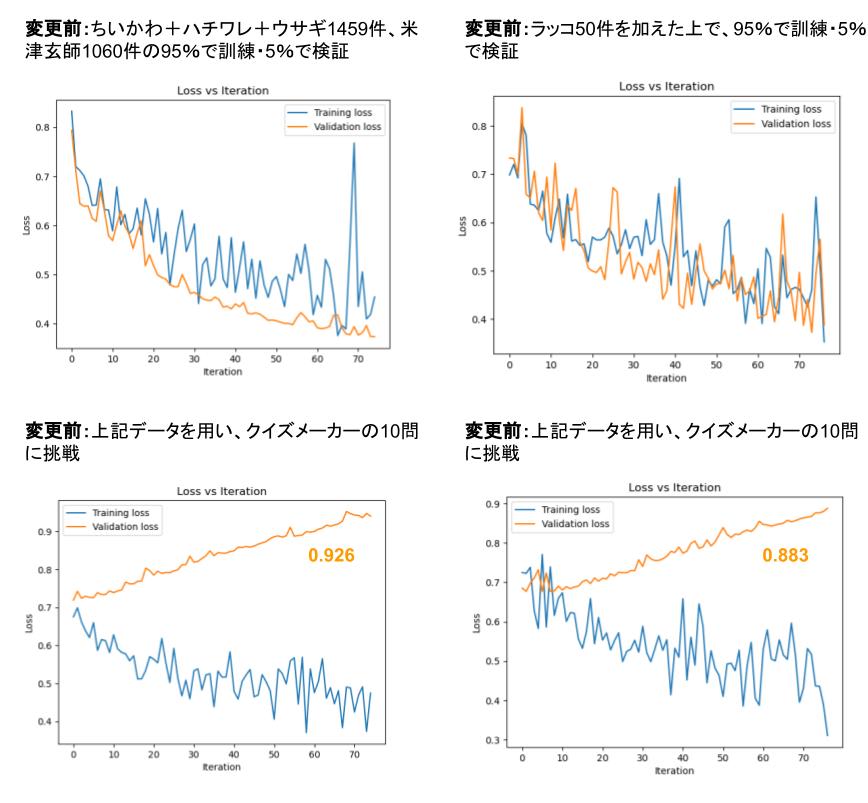
- ちいかわ・ハチワレ・ウサギ・ラッコのセリフを合計1500件近くと、米津玄師の歌詞を21曲から合計1000近く集めて訓練データにした。
- ちいかわか米津玄師か当てるクイズ | クイズメーカー で用いられているセリフ・歌詞は訓練データから除外した。
- セリフ・歌詞をBERTで埋め込みベクトル化し、全結合層で2値に分類した。
- 過学習を防ぐため、epochは1に設定している。
- Tokenizer・BERTモデルともに、東北大学乾研究室のモデルを利用している。
学習データの量
とりあえず手動で、TwitterのキャラクターBotや歌詞のサイトから100件程度作成し、コードを実装しました。その後より洗練されたやり方でデータを2500件程度に増やしました。
初学者のためデータ量の目安が分かっていませんでしたが、数百~数千は必要なことを体感しました。

学習データの質
ちいかわにおけるラッコはレギュラーメンバーではないのでセリフを集めるのが大変だったのですが、それでも2500件に50件程度追加したところ、損失が数%改善しました。(※それでも依然として過学習です)
また、過学習対策の一環として、ちいかわのキャラクターのセリフの正規化も試しました。
ルールはオリジナルで次のとおりです。自然言語処理の定番もあるかもしれませんが、ちょっと見つけられませんでした。
1. 文字列が半角・全角スペース・改行を含む場合、その文字列を複数の文字列に分割する
2. 記号(!,?,!,?,・,.,…,',",♪,♫)と全ての絵文字を削除する
3. ()または()で囲まれた文字列を削除する
4. 半角カタカナを全角カタカナに、~を~に、-をーに変換する
5. 2つ以上連続する~~を~に、ーーをーに変換する
6. 空文字列を削除する
結果はあまり変わらず、特徴をうまく掴むデータに勝るものはないと感じました。

パラメータの調整
結論から言うとはじめにChatGPTに提案してもらったパラメータがそのまま良い成績でした。
ニューラルネットの層を追加したことで過学習が起きる例。

Learning Rateを変えたことで過学習が起きる例。

特徴を掴むためのデータの量が揃わないうちは、パラメータの調整には意味がないのではと感じています。
まとめ
ちいかわ・米津玄師の分類タスクを通して、ニューラルネットワークのモデル作成と公開を体験しました。特に、モデルが特徴をうまく把握するためのデータ集めの重要性を学べました。
Discussion