AWSでログを保存する時の選択肢とコスト
背景
AWS上で複数のEC2インスタンスからなるサービスを構築する時、必ずログを生成・保存すると思います。それは例えばWebサーバーのアクセスログだったり、アプリケーションの動作ログ、エラーログなどです。
で、もっとも初歩的な方法としては単純に各サーバーインスタンスでログ保存して、各々でログをローテートする方法があり、これだとLinuxの初期設定から特にいじる必要はないです。
ただ、ログがあちこち分散しているよりは1箇所に集まってくれてる方が後から読みやすいですし、ログの管理も楽なので、どういうやり方があるか調査しました。
コストに関しては注意深く算出したつもりですが、もし間違いがありましたらコメントいただけると助かります。
また、この記事の内容からログサービスを選定して想定より大きな請求が来たとしても、責任は負えませんので悪しからずです。
ログ保存の選択肢
- 各インスタンス上でSyslog管理。
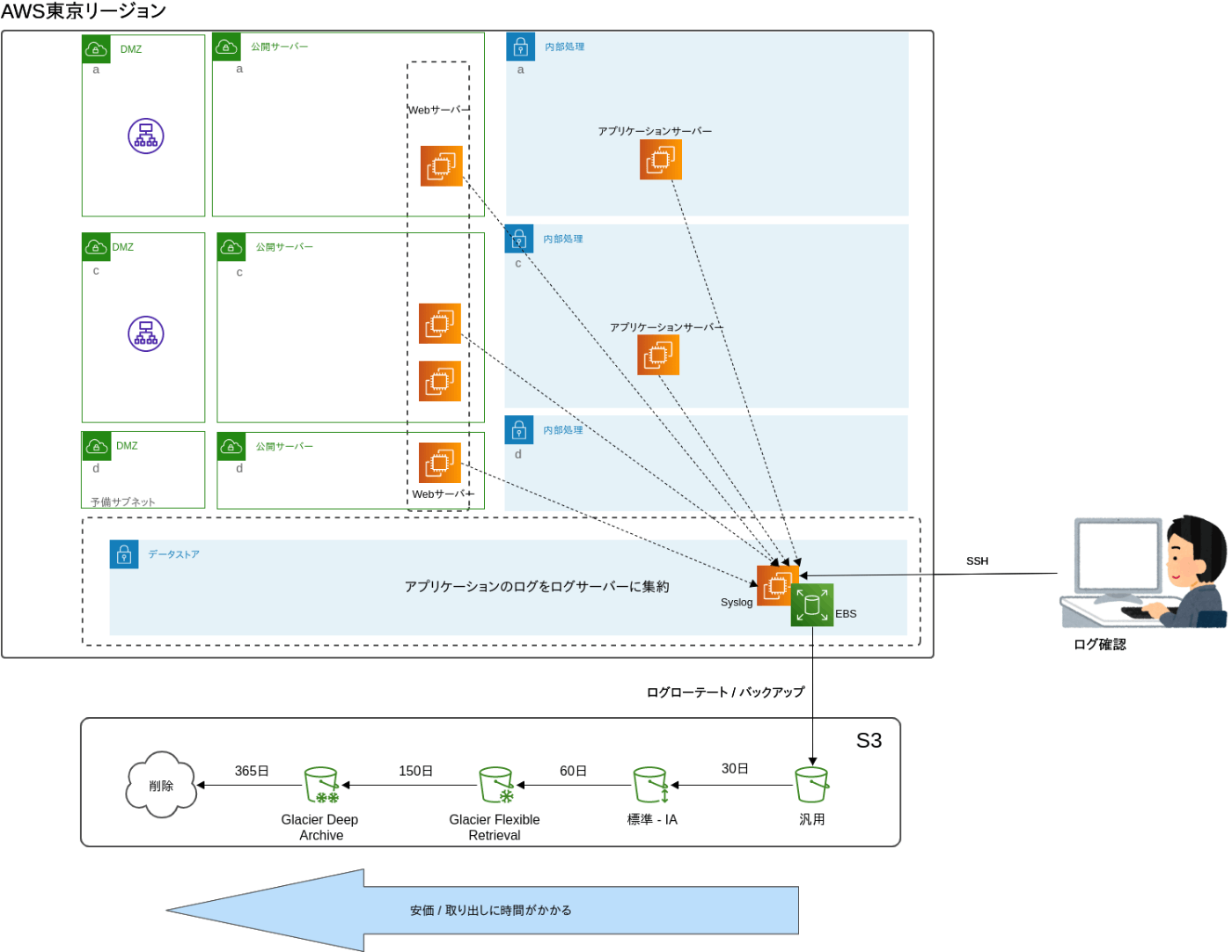
- ログ専用インスタンスに集約。
- Amazon CloudWatch Logsに転送、保存。
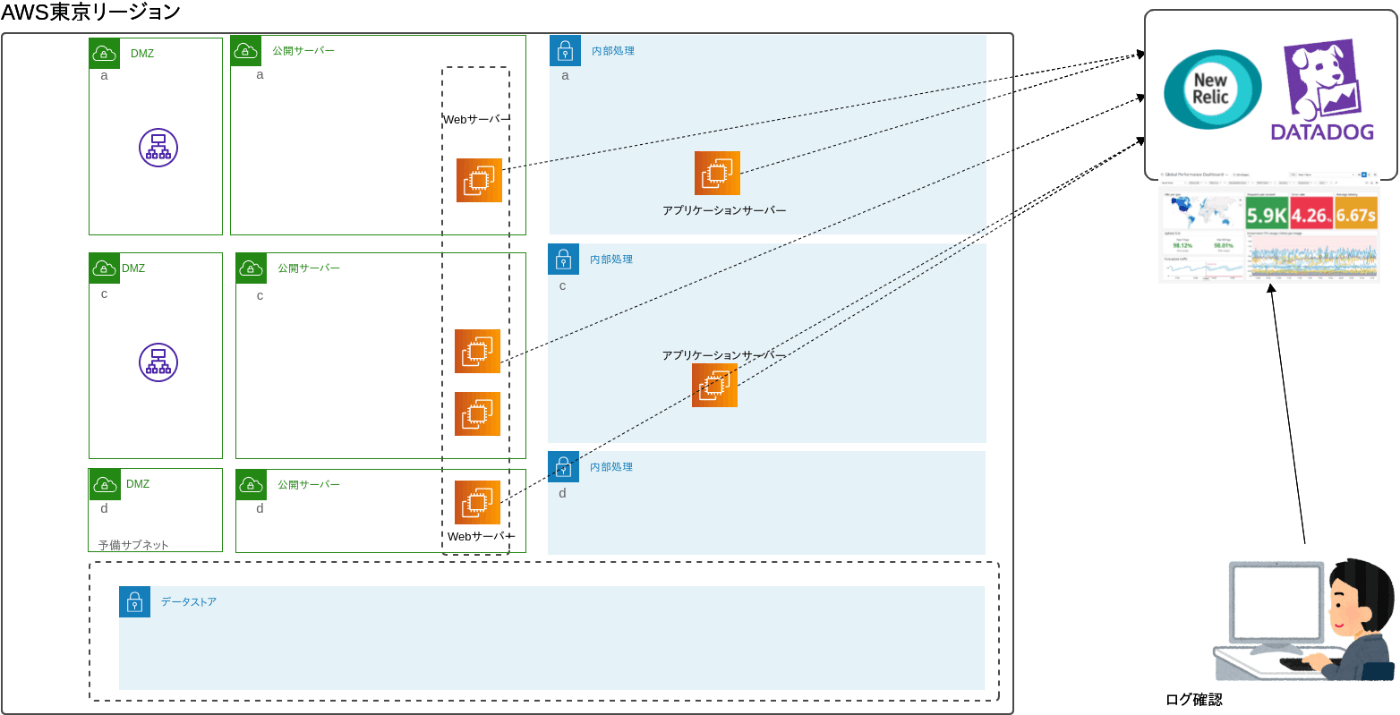
- サードパーティの監視サービスに転送、保存。
2はsyslogの設定が必要、3,4では各インスタンスに専用のエージェントをインストールする必要があります。
2のイメージ
3のイメージ
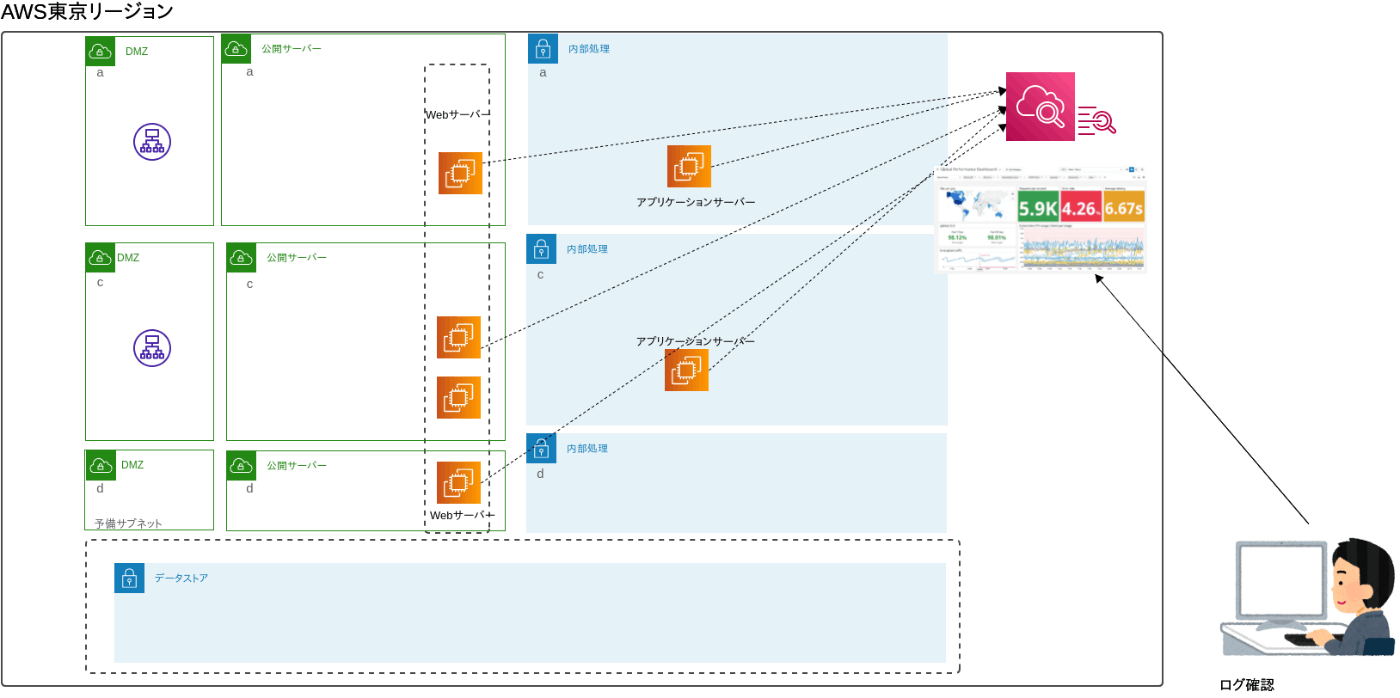
4のイメージ
前提条件
試算するに当たっての前提条件は
- ログは1年間保管。1年経過後は削除。
- ログの用途は障害時の原因調査や記録。
- ほとんどの場合、見るのは当日か前日のログ。ただし2週間程度前のログまでは稀に見る場合がある。
- 本当にごく稀に、1ヶ月前のログも見る可能性はある。
コスト
-
1,2は料金は純粋にストレージ料金になりますが、2はログ専用インスタンスを別途立てるので、ストレージ料金とは別にインスタンス料金が必要となります。
-
集約せずに各サーバーにログを保存するパターンは今回は検証していません(その場合は純粋にEBSの料金になります)。
-
3,4では転送と保存、それぞれに料金がかかります。
-
4では、AWSから外部へデータを転送する際に発生する、データ転送料金がかかります。
-
datdogは15日間は分析対象とし、それ以降はS3に転送するようにしました。
-
1,2のパターンについてはログのローテート先を以下のように分けて、それぞれ試算する。
- EBSのみ
- S3汎用のみ
- S3汎用 → 標準IA → Gracia → Gracia Deep Archive と自動的にクラス変更する
ここで、1日のログサイズが7GB、行数は 30,000,000行(イベント)として料金を計算します。
ログの行数多くないかと思われるかもしれませんが、今回の検証のきっかけになったシステムは実際、毎日それくらいのログを吐いてました。こわ...
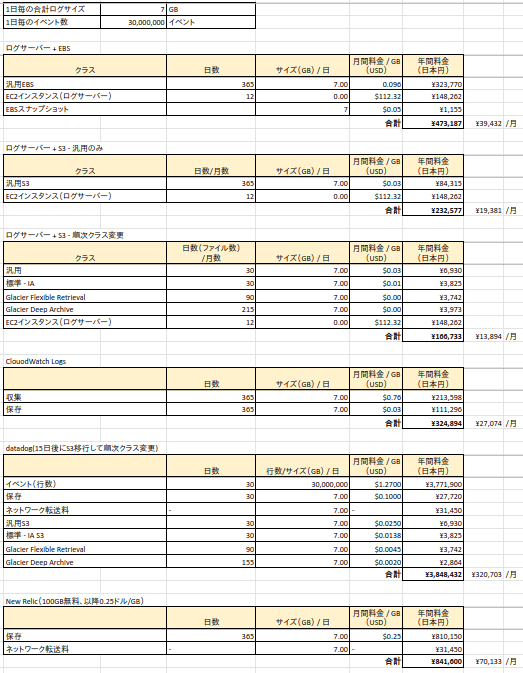
- datadogの結果を見て震えましたが、「行数=イベント数」という前提で計算しています。もし間違ってたら指摘していただけると助かります。
- datadogが突出して高いのは、唯一イベント数に対する課金があるからですね。
- 一番安いのはEC2のログサーバーに集約して、ローテート先をS3にし、自動クラス変更する設定にした場合です。
- EC2にS3をマウントする方法はこちらで書いてます。個人的にはgoofysが簡単で速いのでおすすめです。
- ローテート先をマウントしたS3にする方法は、また機会があれば記事にします。
ログの確認方法
syslog
- syslogでログ収集した場合はテキストファイルですので、サーバーがLinuxであれば
lesstailgrep等を使って確認することになります。 - グラフなどのビジュアルを使ったログ分析はそのままではできません。
cloudwatch logs
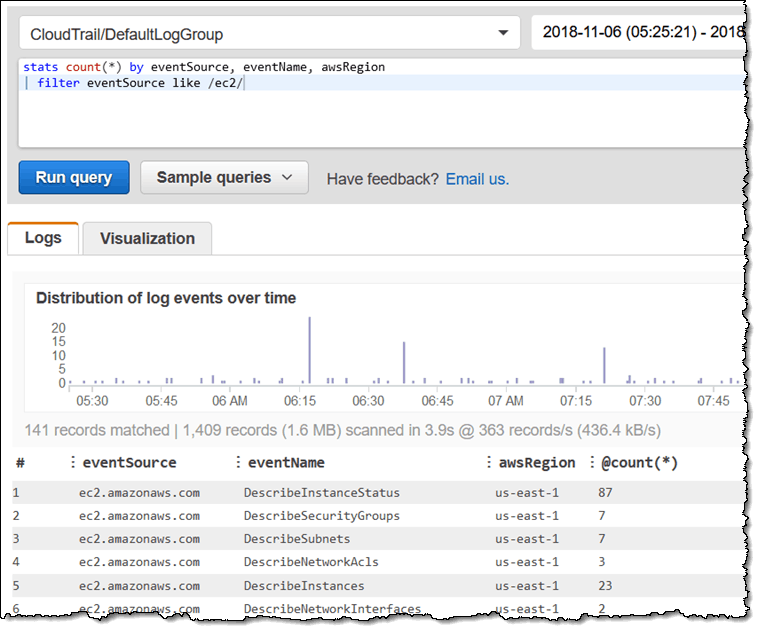
- こんな感じの画面で様々なクエリを投げてフィルタリングした結果を確認することができます。
- また、AWS CLIを使って、ちょうどtailコマンドのように目的のログをリアルタイムに流すこともできます(時間差が15秒ぐらいありますが)。
- 画面上で目的のログをテキストで確認することもできます。
- 詳しくはこちら
datadog
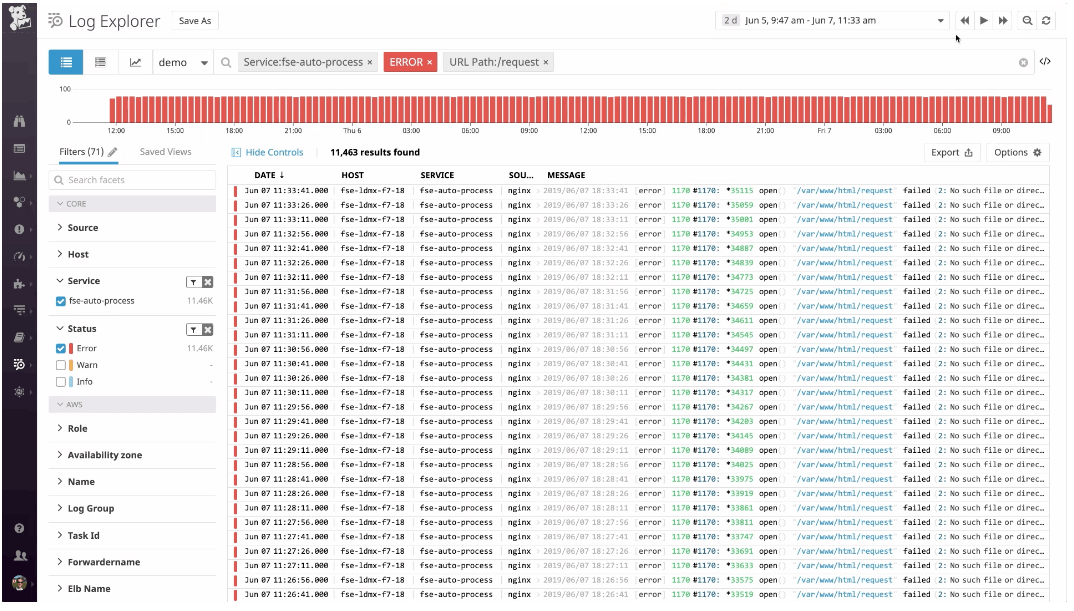
- datadogも非常に多機能に色んなことができるようです。
- 詳しくはこちら
New Relic
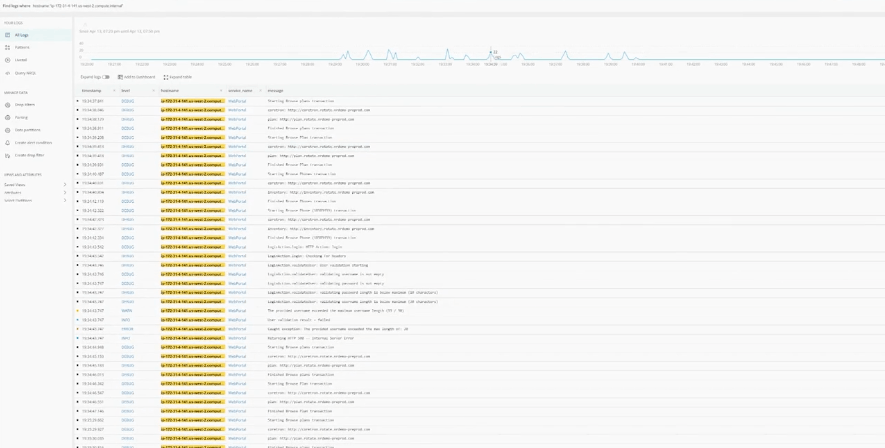
- こちらもログの分類やエラー検出など、色々できるようですね。
- 詳しくはこちら
結論
結論と言っても、ケース・バイ・ケースなのでなんとも言えませんが...
例えば、単にログを残しておきさえすればよく、ログ分析なんてあんまり必要ないよって場合は、Linuxに標準搭載の syslog を使って、ローテート先をS3にして、バケットのクラスを期間で自動変更しておけば安く保存できそうです。ただし、その場合は less などのツールを使ってログを文字として読むのみということになります。
ただ、S3保存の場合も AWSのCloudSearchあたりと連携すればもう少しいい感じに分析できるかもしれません。やったことないけど。
一方、CloudWatch logsや、datadog、NewRelicなどのサービスを使えば、よりビジュアル的に全体を俯瞰できるダッシュボードを簡単に作ることができます。
やることも各インスタンスにエージェントをインストールするだけなので簡単ですし、例えばk8sを使って数百台以上のサーバーを展開する場合などは、こっち一択になるかもですね。
一方、これらのサービスの怖いところはコストですね。すでに稼働中のシステムでこれらのサービスを使う場合は、現行のログの吐き出し量を計測してコスト算出しないと大変なことになるかもです。そう言えば何年か前のServerless days Tokyoで、ログレベルをdebugにしたままで大変な請求が来たとかいう話を聞いたような。
あと注意点として、今回のdatadogの金額はある程度どのくらい使うのかを、あらかじめ契約して使う場合の金額です。営業を通さずにボリュームディスカウント無しで使う場合は、今回より割高になると思われます。NewRelicで同じような事があるかどうかはわかりません。
Discussion
私はS3の料金を把握しきっているわけではないので間違いはあるかもですが、、、
S3の料金は単純なオブジェクトのサイズだけでは決まりません!
例えばGlacier Deep Archiveは、128KBの最小オブジェクトサイズや、自動で付与される(多分40KBの)メタデータなどがあります。
ログは、そのままだと一つ一つのファイルサイズは小さくファイル数はかなり多いです。
そのため、うまいこと圧縮して保存するようにしないと、下手したらGlacier Deep Archiveにしたせいでコストが増える可能性もあります!
参考になりそうな記事など
コメントをいただきありがとうございます。
たしかにS3に保存したオブジェクトにはメタデータが付加されるのと、ライフサイクルを設定するとクラス変更時に料金がかかってくるなど注意点があるようですね。
また、リンクいただいた Amazon S3 Glacier ストレージクラスへのログの圧縮とアーカイブ によると、128KBよりも小さなファイルをGlacierにアーカイブすることはかえって非効率として、ログを各インスタンスからではなく集約した上でS3に保存することを推奨しているようです。
今回、たまたま私の環境では一度ログサーバーにログを集約して、そこからS3にPUTしていたので、一つ一つのログファイルのサイズは1日あたり100MBぐらいで、このサイズであればアーカイブすることによるコスト削減効果は見込めると思いますが、S3の料金体系も結構複雑な計算が必要なんですね。
ありがとうございました。