# PandasとGeopandasで座標欠損データを結合し、QGISで名水データを可視化する備忘録
💡 はじめに
こんにちは。熊本在住でクレソン栽培などを行っています。熊本は「水の国」と呼ばれるほど名水が多いのですが、その水質や位置情報をGISで分析してみたいと考えました。
PandasとGeopandasで座標欠損データを結合し、QGISでデータを可視化する
しかし、手元には以下の2つのバラバラなデータしかありませんでした。
-
水質データ (
熊本4水源の水質調査OCR結果.csv):-
pH、硬度、水温などの詳細な水質情報が載っている。 - スキャンした表をOCR(光学文字認識)で読み取ったため、座標 (fX, fY) データが欠損 (NaN) している。
-
-
座標データ (
熊本4水源ジオマッピング.csv):-
名称(池山水源、白川水源など)と、そのfX(経度)、fY(緯度) だけが載っている。 - CSV アドレス マッチング サービスを利用してジオマッピングをおこなった。
-
この記事は、これら2つのCSVファイルをPython (Pandas, Geopandas) を使って結合(マージ)し、QGISで可視化・分析できるShapefile(またはGeoPackage)を作成するまでの全プロセスをまとめた技術的な備忘録です。
🔧 実行プロセス
目的は、「水質データ」に「座標データ」を名称をキーにして紐付けることです。
実行した処理の概要は、以下の流れとなります。
1. 必要なライブラリのインポート
まずは、データ加工用のpandasと、地理空間データ作成用のgeopandasをインポートします。
import pandas as pd
import geopandas as gpd
from geopandas import points_from_xy
2. 2つのCSVデータの読み込み
それぞれのCSVファイルをpandasでDataFrameとして読み込みます。
# 座標が欠損しているメインの水質データ
df_main = pd.read_csv("熊本4水源の水質調査OCR結果.csv")
# 座標情報だけを持っている参照用データ
df_coords = pd.read_csv("熊本4水源ジオマッピング.csv")
df_mainはこんな状態です(座標がNaN)。
名称 所在地 fX fY ...
0 池山水源 熊本県阿蘇郡産山村田尻14-1 NaN NaN ...
1 白川水源 熊本県阿蘇郡南阿蘇村白川 NaN NaN ...
2 轟水源 熊本県宇土市宮庄町 NaN NaN ...
df_coordsはこんな状態です。
名称 fX fY
0 池山水源 131.18489 33.04107
1 菊池水源 130.92426 33.01300
2 白川水源 131.09779 32.84747
3 轟水源 130.62305 32.67684
3. データの結合 (pd.merge)
ここが今回の分析の核です。pandasのmerge機能を使い、名称列をキー(on='名称')にして、2つのDataFrameをleft(左結合)で結合します。
# '名称'をキーにして、df_main (左) に df_coords (右) の情報を結合
df_with_new_coords = pd.merge(df_main, df_coords, on='名称', how='left')
how='left'で結合すると、df_main(水質データ)をベースに、名称が一致する行のfXとfYがdf_coordsから自動的に補完されます。
print("\n--- 結合前のデータ (座標欠損あり) ---")
print(df_with_new_coords[['名称', '所在地', 'fX', 'fY']].head())
# '名称'をキーにして、座標データを左結合 (left merge) します
# これにより、df_with_new_coords の全行が残り、一致する座標データが追加されます
# 座標データ側の列名には自動で接尾辞 '_right' などが付与されます
df_with_new_coords = pd.merge(df_main, df_coords, on='名称', how='left', suffixes=('', '_new'))
print("\n--- 座標データを結合した直後 ---")
print(df_with_new_coords[['名称', 'fX', 'fY', 'fX_new', 'fY_new']].head())
# --- Step 3: 欠損している座標を新しいデータで埋める ---
# 元のfX列がNaNの場合、新しいfX_new列の値で埋めます
df_with_new_coords['fX'] = df_with_new_coords['fX'].fillna(df_with_new_coords['fX_new'])
# 同様にfY列も埋めます
df_with_new_coords['fY'] = df_with_new_coords['fY'].fillna(df_with_new_coords['fY_new'])
# 不要になった新しい座標列 (_new) を削除します
df_final = df_with_new_coords.drop(columns=['fX_new', 'fY_new'])
print("\n--- 座標を補完した最終データ ---")
print(df_final[['名称', '所在地', 'fX', 'fY']].head())
以上のコードを実行した結果は、
--- 結合前のデータ (座標欠損あり) ---
名称 所在地 fX fY
0 池山水源 熊本県阿蘇郡産山村田尻14-1 NaN NaN
1 白川水源 熊本県阿蘇郡南阿蘇村白川 NaN NaN
2 轟水源 熊本県宇土市宮庄町 NaN NaN
--- 座標データを結合した直後 ---
名称 fX fY fX_new fY_new
0 池山水源 NaN NaN 131.18489 33.04107
1 白川水源 NaN NaN 131.09779 32.84747
2 轟水源 NaN NaN 130.62305 32.67684
--- 座標を補完した最終データ ---
名称 所在地 fX fY
0 池山水源 熊本県阿蘇郡産山村田尻14-1 131.18489 33.04107
1 白川水源 熊本県阿蘇郡南阿蘇村白川 131.09779 32.84747
2 轟水源 熊本県宇土市宮庄町 130.62305 32.67684
最終的なGeoDataFrame作成対象の行数: 3
となります。
4. GeoDataFrameの作成
これで、水質データと座標が紐付いた df_final (Pandas DataFrame)が完成しました。 最後に、このdf_finalをgeopandasが認識できるGeoDataFrameに変換します。
# 経度(fX)と緯度(fY)からgeometry列を作成
gdf = gpd.GeoDataFrame(
df_final,
geometry=gpd.points_from_xy(df_final['fX'], df_final['fY']),
crs="EPSG:4326" # WGS84 (緯度経度) の座標系を指定
)
これで、水質データと座標(geometry)が紐付いた GeoDataFrame が完成しました。
--- 結合後のデータ ---
名称 所在地 LocName fX fY iConf iLvl \
0 池山水源 熊本県阿蘇郡産山村田尻14-1 NaN NaN NaN NaN NaN
1 白川水源 熊本県阿蘇郡南阿蘇村白川 NaN NaN NaN NaN NaN
2 轟水源 熊本県宇土市宮庄町 NaN NaN NaN NaN NaN
3 池山水源 熊本県阿蘇郡産山村田尻14-1 熊本県/阿蘇郡/産山村/田尻 131.18489 33.04107 5.0 5.0
4 白川水源 熊本県阿蘇郡南阿蘇村白川 熊本県/阿蘇郡/南阿蘇村/白川 131.09779 32.84747 5.0 5.0
水源名 採水年月日 水温 ... カルシウム マグネシウム 鉄 マンガン 硝酸態窒素及び亜硝酸態窒素 \
0 池山水源 H25.6.19 13.9 ... 31.8 5.8 0.01未満 0.005未満 1.3
1 白川水源 H25.6.19 14.5 ... 24.2 3.5 0.01未満 0.005未満 0.7
2 轟水源 H25.6.19 19.3 ... 17.5 2.8 0.01未満 0.005未満 0.5
3 池山水源 H25.6.19 13.9 ... 31.8 5.8 0.01未満 0.005未満 1.3
4 白川水源 H25.6.19 14.5 ... 24.2 3.5 0.01未満 0.005未満 0.7
塩化物イオン 炭酸水素イオン 硫酸イオン ケイ酸 遊離炭酸
0 13.5 130 8.2 53 13.8
1 9.8 93 6.6 44 12.8
2 10.3 76 6.5 28 7.4
3 13.5 130 8.2 53 13.8
4 9.8 93 6.6 44 12.8
5. GeoPackageまたはShapefileへの書き出し
最後に、QGISで読み込めるファイル形式で保存します。
# (推奨) GeoPackage形式で保存 (文字コードや列名の問題を回避できる)
gdf.to_file("熊本名水データ.gpkg", driver="GPKG", encoding='utf-8')
# (今回実行した) Shapefile形式で保存
# gdf.to_file("熊本名水データ_座標補完版.shp", encoding='cp932')
🤔 ハマった点と学び (QGISでのエラー)
Pythonでの処理は順調でしたが、QGISで可視化する際にいくつかの問題に直面しました。
1. to_file("...shp") での警告
gdf.to_file()でShapefile (.shp) 形式を指定した際、コンソールに大量の警告が出ました。
UserWarning: Column names longer than 10 characters will be truncated...
RuntimeWarning: Could not decode error message to UTF-8...
原因と学び:
Shapefileは古い形式で、列名(フィールド名)が半角10文字(全角だと約5文字)までという致命的な制限がありました。
「硝酸態窒素及び亜硝酸態窒素」のような長い日本語の列名は、自動的に「NO3_NO2」のような短い名前に切り捨てられる(または文字化けする)ための警告でした。
対策:
現代のGIS分析では、GeoPackage (.gpkg) 形式で保存するのがベストプラクティスだと分かりました。GeoPackageは単一ファイルで、列名制限もなく、文字コード(UTF-8)も正しく扱えます。
2. QGISで「無効なデータソース」エラー
保存した 熊本名水データ_座標補完版.shp をQGISに[データソースマネージャー]から[ベクター]のタブで取り込んだところ、「無効なデータソース」と表示され混乱しました。
原因と学び:
原因:
ファイルの不足: Shapefileは .shp 単体では機能しません。.shp (図形), .shx (索引), .dbf (属性データ) の最低3ファイルがセットで必須です。
対策:
対策: .shpファイルだけでなく、Pythonで同時に出力された .shxファイルと.dbfファイルをすべて同じフォルダに揃えた上で、QGISの[データソースマネージャー]から.shpファイルを指定することで、正常に読み込めました。
🚀 QGISでの可視化の変遷
最終的に、QGISで以下のように可視化を試みました。
-
単純なプロット(失敗):

これでは位置しか分かりません。 -
単一シンボルでの色分け(失敗):
水温で色分けするとpHが分からず、pHで色分けすると水温が分からない、という問題に直面しました。

-
ダイアグラム機能(円グラフ)(失敗):
水温 (13.6)とpH (7.3)と硬度 (104)は、単位が全く異なるため、「全体に対する割合」を示す円グラフで表現するのはデータの誤用であることに気づきました。
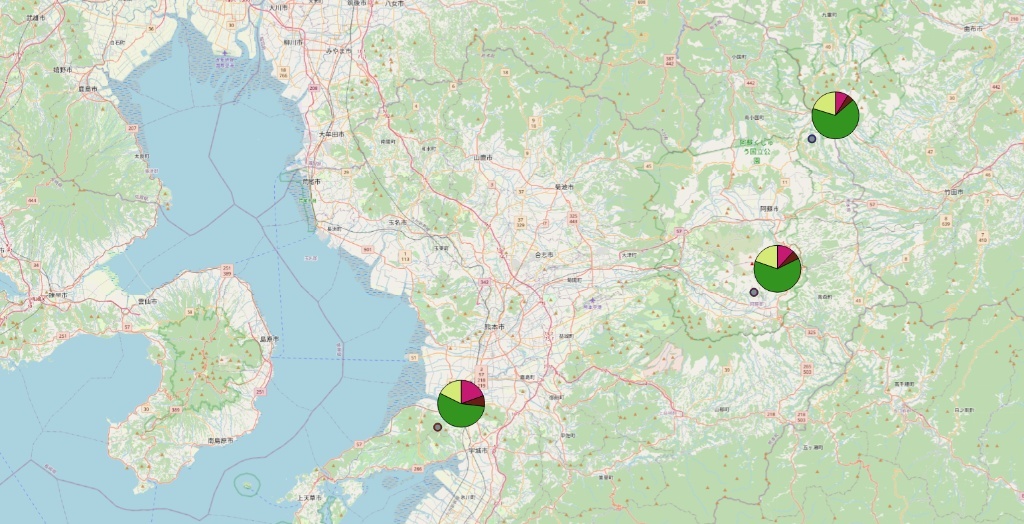
-
ダイアグラム機能(テキスト表示)(成功❓):
最終的に、ダイアグラムの「テキストダイアグラム」機能(または「ラベル」機能の応用)を使い、
水温,pH,硬度などの数値そのものを地図上に表示させることで、複数の指標を同時に比較できるようになりました。

おわりに
バラバラだったCSVデータをPythonで結合し、QGISで可視化するまでの一連の流れをまとめました。特にShapefileの仕様やファイルパスの問題など、GISならではの「ハマりどころ」を経験でき、良い備忘録となりました。
今後は、このデータをクレソン栽培の適地分析(水温10-20℃、pHアルカリ性など)に活用したり、Sentinel衛星のリモートセンシングデータと組み合わせて分析を進めたりしていきたいです。
Discussion