PythonでETLをよく書く僕はCopilot AgentでDocstringとpytestで重宝している話
CursorやAgentやClineやDevinとか、AI駆動開発な今日この頃ですが、正直全自動化できないタスクはまだ残されていて、僕のETL処理系はその一つになるかなと思っています。
基本はpandasで書いていて、単純なやつならいいのですが、しょうもないところでapplyを使ってきたりとか(case次第でかなり非効率です)、cumsumとか使えばいいところにfor文を書いてきたりとか、ちょっとfillnaを勝手にやられるくらいなら消して直すのですが、結構抜本的にダメなコードを書いてきます。
なので複雑になりそうな処理はいまだに自分が実装しているのですが、それでも活用できることはたくさんあり、AIいつもありがとうという感じです。
今日はその中で2種類、Docstringとpytestの結果をお見せします。
(あとは、ETLの完全自立型AIも時間の問題だとは思っています。)
まずはサンプルコード
今回サクッとdemoするため、ベースのコードをAIに書いてもらいました。
import pandas as pd
from datetime import datetime
def load_csv_files(order_details_file, orders_file, products_file):
"""CSVファイルを読み込む関数"""
order_details = pd.read_csv(order_details_file)
orders = pd.read_csv(orders_file)
products = pd.read_csv(products_file)
return order_details, orders, products
def merge_data(order_details, orders, products):
"""データを結合する関数"""
return order_details.merge(orders, on="order_id").merge(products, on="product_id")
def filter_today_data(merged_data, current_date):
"""今日の日付のデータをフィルタリングする関数"""
return merged_data[merged_data["order_date"] == current_date]
def calculate_sales(today_data):
"""商品ごとの売り上げを計算する関数"""
# この辺非効率ですよね
return today_data.groupby(["product_id", "product_name"]).apply(
lambda x: (x["quantity"] * x["unit_price"]).sum()
).reset_index(name="total_sales")
def save_to_csv(data, output_file):
"""データをCSVファイルに保存する関数"""
data.to_csv(output_file, index=False, encoding="utf-8-sig")
# メイン処理
if __name__ == "__main__":
# ファイルパスの設定
order_details_file = "order_details.csv"
orders_file = "orders.csv"
products_file = "productrs.csv"
output_file = "daily_sales_20250419.csv"
# CSVファイルの読み込み
order_details, orders, products = load_csv_files(order_details_file, orders_file, products_file)
# データの結合
merged_data = merge_data(order_details, orders, products)
# 商品ごとの売り上げを計算
today_sales = calculate_sales(merged_data)
# CSVファイルとして保存
save_to_csv(today_sales, output_file)
print(f"日別売り上げデータを {output_file} に保存しました。")
pytestをお願いしてみる
正直unit testって、毎回毎回馬鹿正直に全部実装できるものでは無いと思います。特にPOC時期など端折ることも多々ありますが、AI agent本当に最高です。
以下がpytestをお願いしてみたサンプルです。まだ不完全なところもありますが、pytest.fixtureなどこの辺を個人で書くのはいつも地獄の作業でした。
これを1秒でやってくれるなんて最高ですね。
また、網羅性を高めるために「more Exhaustive test case design」って言うともっとテストケースを増やしてくれました(空のデータに対してなど、もともと4つくらいのテスト関数から10個くらいに)
import pytest
import pandas as pd
from create_gold import load_csv_files, merge_data, filter_today_data, calculate_sales
@pytest.fixture
def sample_data():
order_details = pd.DataFrame({
"order_id": [1001, 1001, 1002, 1002, 1003, 1004],
"product_id": ["P001", "P002", "P001", "P003", "P002", "P003"],
"quantity": [2, 1, 1, 3, 2, 5],
"unit_price": [1500, 3000, 1500, 500, 3000, 500]
})
orders = pd.DataFrame({
"order_id": [1001, 1002, 1003, 1004],
"customer_id": ["C001", "C002", "C001", "C003"],
"order_date": ["2025-04-19", "2025-04-18", "2025-04-19", "2025-04-19"]
})
products = pd.DataFrame({
"product_id": ["P001", "P002", "P003"],
"product_name": ["ノートパソコン", "プリンター", "USBケーブル"],
"category": ["電子機器", "電子機器", "アクセサリ"]
})
return order_details, orders, products
def test_load_csv_files(mocker):
mock_read_csv = mocker.patch("pandas.read_csv")
load_csv_files("order_details.csv", "orders.csv", "productrs.csv")
assert mock_read_csv.call_count == 3
def test_merge_data(sample_data):
order_details, orders, products = sample_data
merged = merge_data(order_details, orders, products)
assert not merged.empty
assert "product_name" in merged.columns
def test_merge_data_empty():
"""空のデータフレームを結合した場合のテスト"""
order_details = pd.DataFrame(columns=["order_id", "product_id", "quantity", "unit_price"])
orders = pd.DataFrame(columns=["order_id", "customer_id", "order_date"])
products = pd.DataFrame(columns=["product_id", "product_name", "category"])
merged = merge_data(order_details, orders, products)
assert merged.empty
def test_filter_today_data(sample_data):
order_details, orders, products = sample_data
merged = merge_data(order_details, orders, products)
filtered = filter_today_data(merged, "2025-04-19")
assert not filtered.empty
assert all(filtered["order_date"] == "2025-04-19")
def test_filter_today_data_no_match(sample_data):
"""今日の日付に一致するデータがない場合のテスト"""
order_details, orders, products = sample_data
merged = merge_data(order_details, orders, products)
filtered = filter_today_data(merged, "2025-04-20") # 存在しない日付
assert filtered.empty
def test_calculate_sales(sample_data):
order_details, orders, products = sample_data
merged = merge_data(order_details, orders, products)
filtered = filter_today_data(merged, "2025-04-19")
sales = calculate_sales(filtered)
assert not sales.empty
assert "total_sales" in sales.columns
assert sales[sales["product_id"] == "P001"]["total_sales"].iloc[0] == 3000
def test_calculate_sales_no_data():
"""空のデータフレームで売り上げを計算する場合のテスト"""
empty_data = pd.DataFrame(columns=["product_id", "product_name", "quantity", "unit_price", "order_date"])
sales = calculate_sales(empty_data)
assert sales.empty
def test_calculate_sales_multiple_entries():
"""同じ商品が複数回登場する場合の売り上げ計算テスト"""
data = pd.DataFrame({
"product_id": ["P001", "P001"],
"product_name": ["ノートパソコン", "ノートパソコン"],
"quantity": [1, 2],
"unit_price": [1500, 1500],
"order_date": ["2025-04-19", "2025-04-19"]
})
sales = calculate_sales(data)
assert not sales.empty
assert sales[sales["product_id"] == "P001"]["total_sales"].iloc[0] == 4500
さらに自ら空のDataFrameに対するエラーを見つけられました。
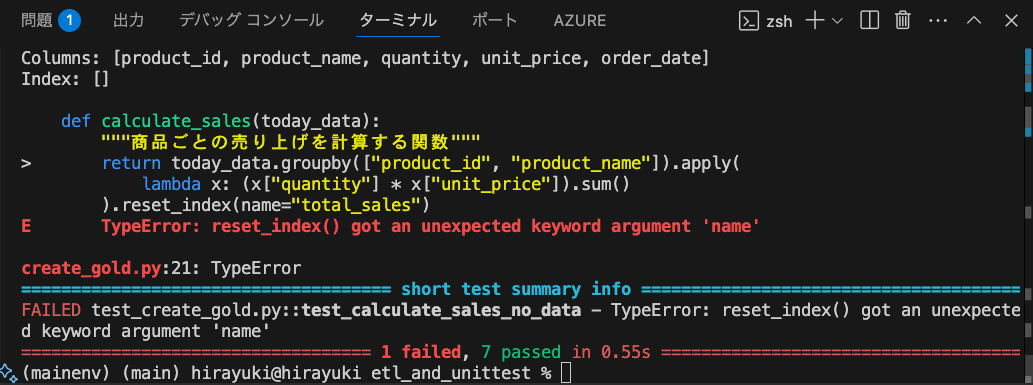
unittestって他には無い快感がありませんか?
Docstring
これは言わずもがなですが、意外と友人に言ってみたら気付いてなかったのであえて書いてみます。
もちろんやり方は簡単で、Docstringを書いてと伝えてみます。
Write Docstring as google style
結果はこんな感じです。自分は結構関数先に書いてあとから面倒くさいと思いながらDocstring書いてしまうので、とーってもこれ助かるんです。
import pandas as pd
from datetime import datetime
def load_csv_files(order_details_file, orders_file, products_file):
"""
Load CSV files into DataFrames.
Args:
order_details_file (str): Path to the order details CSV file.
orders_file (str): Path to the orders CSV file.
products_file (str): Path to the products CSV file.
Returns:
tuple: A tuple containing three DataFrames: order_details, orders, and products.
"""
order_details = pd.read_csv(order_details_file)
orders = pd.read_csv(orders_file)
products = pd.read_csv(products_file)
return order_details, orders, products
def merge_data(order_details, orders, products):
"""
Merge order details, orders, and products data into a single DataFrame.
Args:
order_details (DataFrame): DataFrame containing order details.
orders (DataFrame): DataFrame containing orders.
products (DataFrame): DataFrame containing products.
Returns:
DataFrame: A merged DataFrame containing data from all three inputs.
"""
return order_details.merge(orders, on="order_id").merge(products, on="product_id")
def filter_today_data(merged_data, current_date):
"""
Filter data for the current date.
Args:
merged_data (DataFrame): Merged DataFrame containing all data.
current_date (str): The current date in 'YYYY-MM-DD' format.
Returns:
DataFrame: A filtered DataFrame containing only rows with the current date.
"""
return merged_data[merged_data["order_date"] == current_date]
def calculate_sales(today_data):
"""
Calculate total sales for each product.
Args:
today_data (DataFrame): DataFrame containing data for the current date.
Returns:
DataFrame: A DataFrame with product_id, product_name, and total_sales columns.
"""
return today_data.groupby(["product_id", "product_name"]).apply(
lambda x: (x["quantity"] * x["unit_price"]).sum()
).reset_index(name="total_sales")
def save_to_csv(data, output_file):
"""
Save a DataFrame to a CSV file.
Args:
data (DataFrame): DataFrame to save.
output_file (str): Path to the output CSV file.
Returns:
None
"""
data.to_csv(output_file, index=False, encoding="utf-8-sig")
まとめ
正直全自動化はまだできないコードを書いているけれど(できないよね、、、できてるAIいる?・・・)
それでも活用しまくっている2事例のお話でした。
今度は仕様書から完全にコードに落とし込むと言うのを、もう誰かやっているかもですが、ETL系をテーマにやってみようかと思っています。
お読みいただきありがとうございました。
Discussion