Databricks AppsをStreamlitベースで触ってみる
備忘録的記事で恐縮ですが、こちらの弥生さんの記事を参考にDatabricks Appsを触っていくだけの記事です。
まずは Databricks Free Editionにアクセスして Create Apps
一番左上の「New」の「App」から作成します。

いくつか選択肢がありますね。
Dash, Flask, Gradio, Shiny, Streamlit, Node.js
Flaskと Streamlit Node.js(js書けないですが)しか知らないので、一応全体調べておこうと思います。
- Dash: Dash is the original low-code framework for rapidly building data apps in Python. Dashは簡単にデータアプリを可視化できるとあり、plotlyがベースになってるっぽいので、チャート系のアプリをサクッと作れそうですね。
- Flask: Flask is a lightweight WSGI web application framework. Pythonでwebアプリ作る時の定番。
- Gradio: Gradio is the fastest way to demo your machine learning model with a friendly web interface so that anyone can use it, anywhere! 機械学習に特化した webアプリフレームワークみたいです。
- Shiny: Shiny is built atop the modern Python web stack, leveraging Starlette and asyncio for robust web applications. これもwebアプリを作るためのフレームワークでStreamlitみたいなものにみえます。
- Streamlit: A faster way to build and share data apps. PythonでWebアプリを簡単に作りたい時の定番という認識です。
- Node.js: これの意味するところは完全に理解していませんが、DatabricksのDocを読むと静的HTMLを配置してnodeで動かす、みたいな感じです。
個人的にはStreamlitならなんとか学習できる自信があるのと、DataAppsを作ってみたいのでそれを選択してみます。(Lakebaseも気になるので余裕があればやります。)
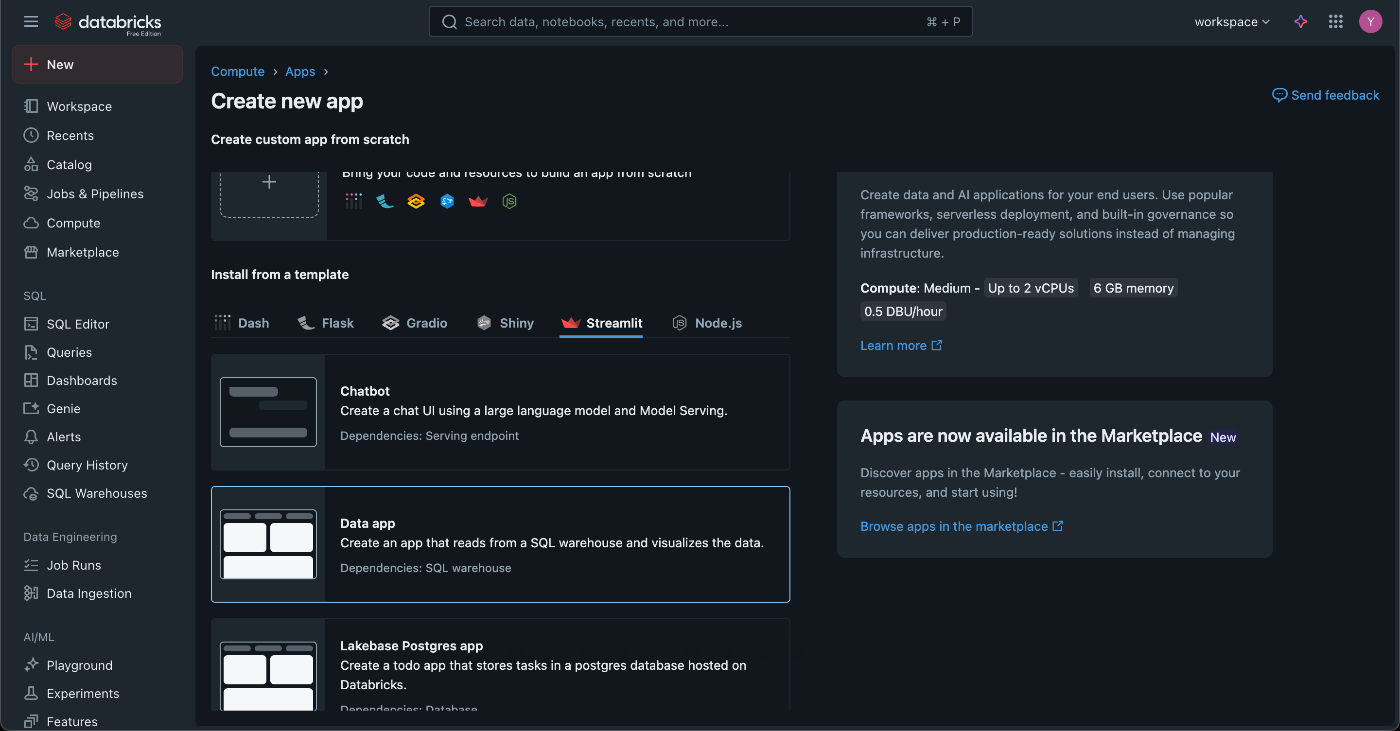
Buildしてみる
決めなくてはいけないのは大きくは「名前、SQL Warehouse、instance size、認証方法」くらいでした。
Deploy中はこのような画面になります。

また、下の方には CLIでの更新方法について書かれていました。

下記のコマンドでdeployできるようですね。
databricks apps deploy data-app --source-code-path /yourpath
アプリを確認してみよう
Runningの横にあるURLからアクセスしてみます。
アクセスできました、素晴らしい。

次にDeploymentの横に書かれている sourceの中身を開いてみます。

構成要素はapp.py, app.yaml, requirements.txtの三つです。
この中で app.pyと requirements.txtの二つがStreamlitの基本構成ファイルです。
そして app.yamlはDatabricks Appsが必要とするファイルです。
中身は以下のようになっています。
command: [
"streamlit",
"run",
"app.py"
]
env:
- name: "DATABRICKS_WAREHOUSE_ID"
valueFrom: "sql-warehouse"
- name: STREAMLIT_BROWSER_GATHER_USAGE_STATS
value: "false"
また下記がドキュメントです。
一番大事なポイントはここに run commandと環境変数を定義できるとこですね。
valueFromという書き方でSecret取れると書いていますが、どうやって指定するのかドキュメントだけだとちょっとわかりにくいですね。(SCOPEがどこに該当するのか。。。)後ほど試そうと思います。
そして app.pyの中は以下のようになっています。
これだけのコードを用意するだけでアプリを建てられるのは楽ですね。
import os
from databricks import sql
from databricks.sdk.core import Config
import streamlit as st
import pandas as pd
# Ensure environment variable is set correctly
assert os.getenv('DATABRICKS_WAREHOUSE_ID'), "DATABRICKS_WAREHOUSE_ID must be set in app.yaml."
def sqlQuery(query: str) -> pd.DataFrame:
cfg = Config() # Pull environment variables for auth
with sql.connect(
server_hostname=cfg.host,
http_path=f"/sql/1.0/warehouses/{os.getenv('DATABRICKS_WAREHOUSE_ID')}",
credentials_provider=lambda: cfg.authenticate
) as connection:
with connection.cursor() as cursor:
cursor.execute(query)
return cursor.fetchall_arrow().to_pandas()
st.set_page_config(layout="wide")
@st.cache_data(ttl=30) # only re-query if it's been 30 seconds
def getData():
# This example query depends on the nyctaxi data set in Unity Catalog, see https://docs.databricks.com/en/discover/databricks-datasets.html for details
return sqlQuery("select * from samples.nyctaxi.trips limit 5000")
data = getData()
st.header("Taxi fare distribution !!! :)")
col1, col2 = st.columns([3, 1])
with col1:
st.scatter_chart(data=data, height=400, width=700, y="fare_amount", x="trip_distance")
with col2:
st.subheader("Predict fare")
pickup = st.text_input("From (zipcode)", value="10003")
dropoff = st.text_input("To (zipcode)", value="11238")
d = data[(data['pickup_zip'] == int(pickup)) & (data['dropoff_zip'] == int(dropoff))]
st.write(f"# **${d['fare_amount'].mean() if len(d) > 0 else 99:.2f}**")
st.dataframe(data=data, height=600, use_container_width=True)
一番肝心なところは下記のデータソースだと思っています。
select * from samples.nyctaxi.trips limit 5000
samples.nyctaxi.tripsはDatabricksの用意しているサンプルデータソースの一つであり、実際にデータを読み取って可視化していることがわかります。
編集してみよう
ちなみにデータとしては下記のようなものを使用しています。

これを使ってチャートをひとつ増やしてみようと思います。

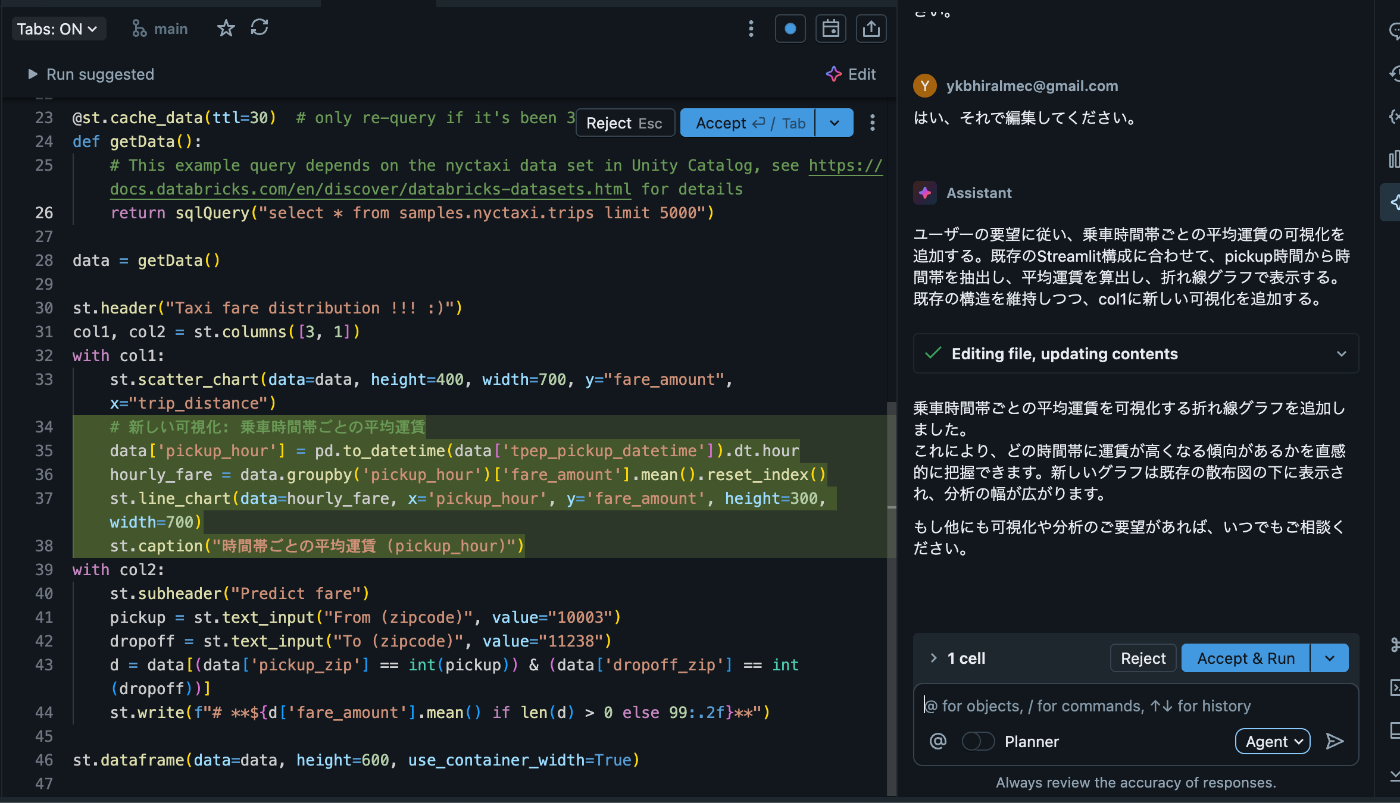
ありがとうAI。
ではデプロイしてみます。
Appを見失って1分ハマったのですが、Computeから再アクセスできます。
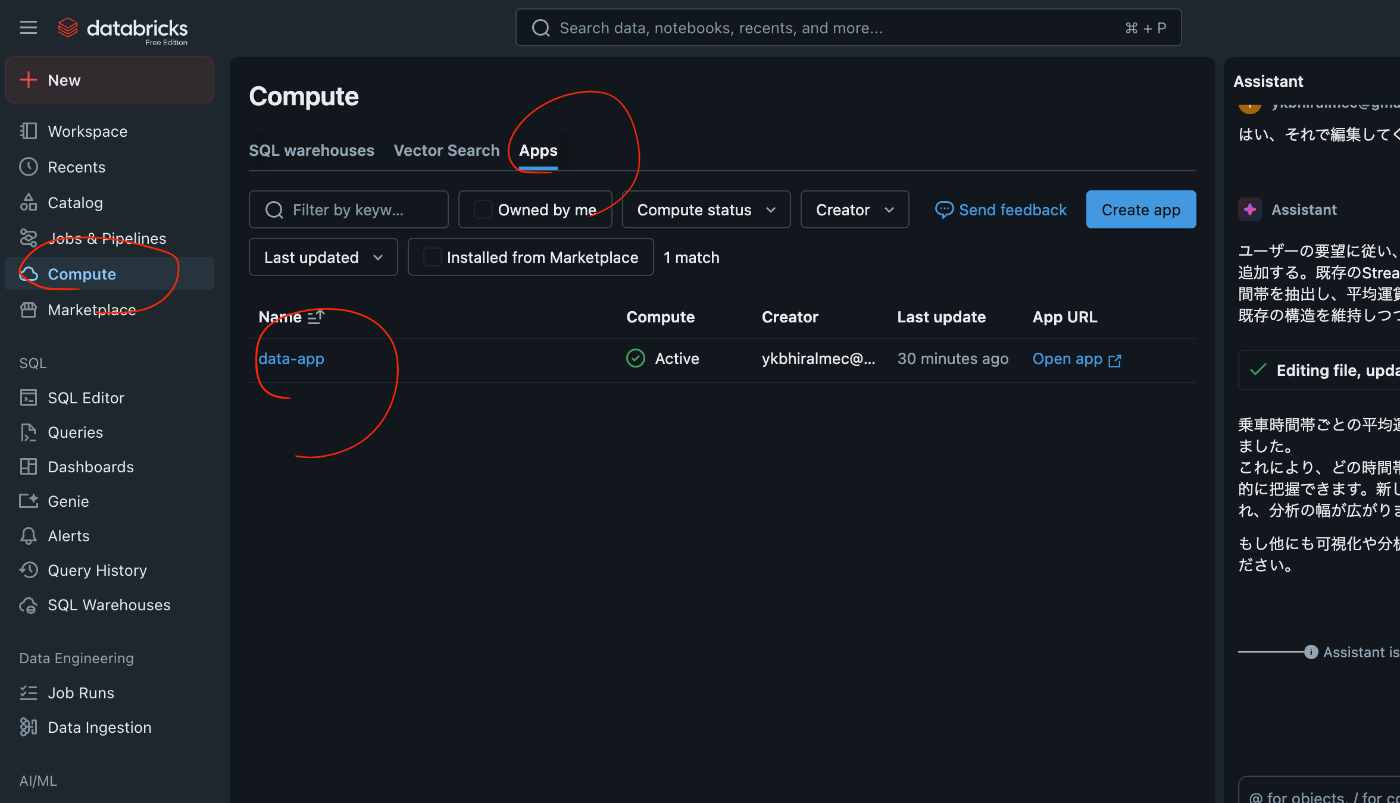
そしてデプロイを再度クリックします。
何度かデプロイしてみましたが、大体5秒〜10秒くらいで完了します。

無事に新しいチャートを追加できました。
LakeBaseも試してみ、、、たかった
Free Editionだと 2025年10月5日現在は LakeBaseが利用できないようです。

有償ライセンスの方で今度試してみようと思います。
簡易にアプリを試す時には本当に便利ですね。
また、DashboardやNotebookで痒いところに手が届かない時の自由度を高めてくれる確かな手段でした。
今はCPU(memory)sizeも2種類しかなく小さいですが、今後Lakebaseが本格的に利用できるようになった時はどうなるのでしょうか?
あくまでもPoCでお試しアプリ及び痒いところに手が届かないようになるのか、またはDatabricks One等ともかけ合わさって、本番環境的なところも担っていくようになるのか、とても気になります。
いいねいただけると励みになります。
お読みいただきありがとうございました。
Discussion