copilot-instructions.md / Github Copilotのreviewの精度を上げたいんじゃ
Github copilot reviewについて
Githubでpull requestする時に Copilotがreviewしてくれる機能はもう使っている人も多いと思います。
しかし、時々歯痒いところに手が届きません。
今回は下記の "Copilot code review: Customization for all" という記事をベースにどれだけreviewの精度向上を見込めるか実験してみようと思います。
※普段業務が機械学習周りなのでPython及びML系のコードでやっています。ご容赦ください。
今回仕込んだ罠
基本的なコードはAIに書いてもらいました。
ざっくりとは以下のような間違いを挿入しています。


Before: まずは基本的な Copilotの Reviewを確認する。
まずはこのコードをそのままpull requestして、github copilotにレビューをお願いします。
すると以下のような回答が返ってきました。
コード規約系
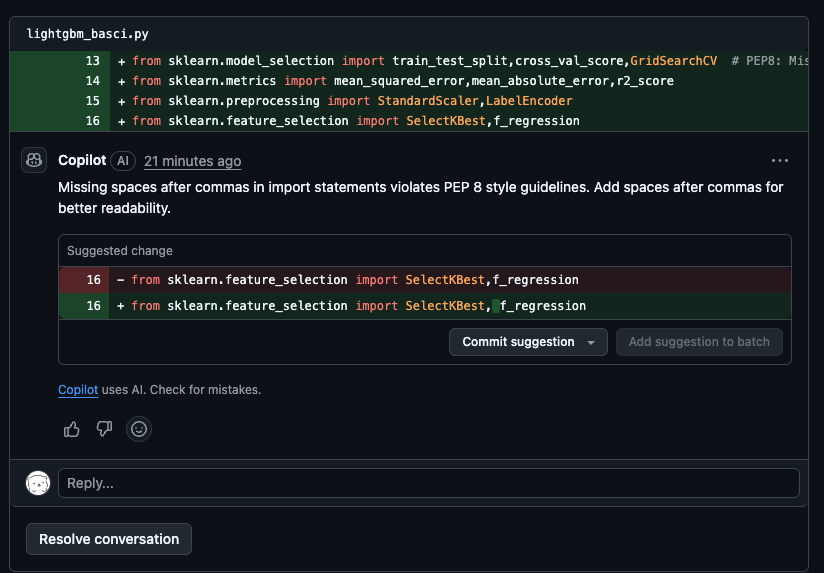
スペースが足りない、インデントの位置が違う等PythonのPEP8に準拠するような基本的な間違いはレビューしてもらえました。

numpyの数学的な細かいところ系
こんなのよく見つけてくれたな、と思ったのですが、0だと対数変換じにエラーが起きるんので、0に近い数を足しておけというアドバイス。

LightGBMの細かい引数の修正
よく公式ドキュメントのMCPとかもなく細かいところに気づけたなという感じ。
(まあそもそも生成したのもAIなので共通の知識を持っているといえば当たり前かもですが)

※意外とデフォが優秀で焦り始めています。
ValidとTestの間違い
Machine Learning系のコードに慣れていない方に対して補足すると、
訓練データtrainと検証データvalid(AIが本当にいいか確かめるためのデータ)をセットで取り扱うべきタイミングがこちらになります。うまく見つけられていそうです。

しかし、人間ならわかりそうだけどなーと思ったのが以下のレビューです。

こちら重複行を消してしまっているんですけど、AIのコーディングに慣れている人なら、
「あれ?真ん中validじゃね?」と若干思うんです(思うんと思うんです僕は)
ここはまだ難しいところですね。やっていることはまちがってないですが。
.github/copilot-instructions.mdを設定してみる
You can now tailor Copilot code review using .github/copilot-instructions.md—the same customization file already used by Copilot Chat and Copilot coding agent. This brings a consistent way to shape how Copilot responds across your entire workflow.
このドキュメントにあるように.github/copilot-instructions.mdに設定した内容に依存してのcode reviewをカスタムできると書いてあります。
正直デフォルトでもかなりReviewをくれたので、ちょっと全く標準のままではあり得ない追加の要望を加えてみようと思います。
実際のpromptはAIに任せましたが要約すると以下のような内容を依頼しました。
- 日本語で回答してください。
- 機械学習モデルがある際、以下の点を留意してください。
- MLflowによるモデル管理を行なっている。
- MLflowによりモデルを必ず保存している。
- 推論後に結果をplotしている。
- 特徴量生成後、中間テーブルとしてそれを保存している。
- sklearn pipelineを活用して一連の流れをpipelineにしている。
After: カスタム指示を受け取ったCopilotのReview結果を確認する
MLflow未使用の場合の指摘が追加された
まさに欲しかったものの一つ目になります。

中間(特徴量)テーブルの不在チェック
これも指摘してくれました。ただ、行としてはそこじゃないような気もするので、、意外と指示に対してコードも具体的に特定するのは難しさがあるのかもしれません。
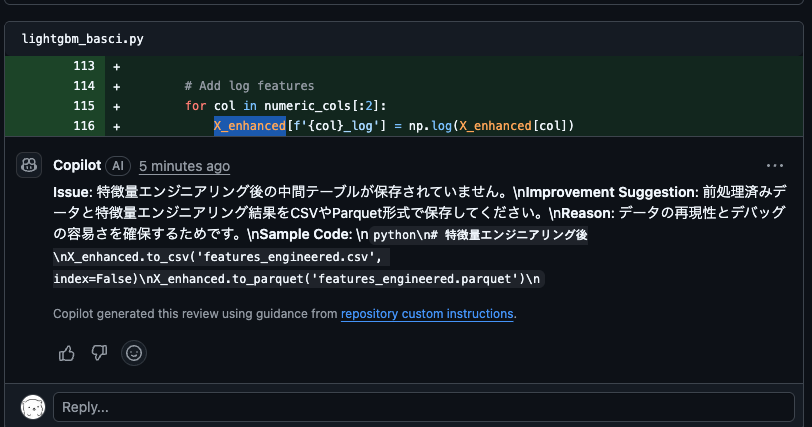
日本語で返してくれるようになった
日本語で返してくれるようになった!
補足、推論後のplotについて
今回最初から以下のコードが pull requetしたコードに含まれていました。
lgb_model.plot_predictions(y_test,y_test_pred)
これは、新しくルールに追加した "推論後に結果をplotしている。"ことを確認してくださいという命令が実行できていることになります。
そしてこれについてはレビューの際の指摘がありませんでした。
うまく機能しているようです。
中間(特徴量)テーブルの不在チェックを解消した場合、レビューは変わるのか?
以下のように中間テーブルをcsvに保存するようにしました。これでレビュー内容が変わるか確認します。

で、結果としては、中間テーブルに関する記載が変わりました!
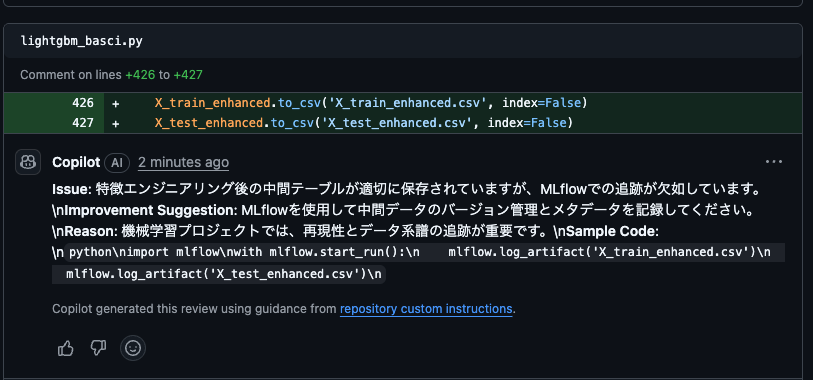
コードの指摘箇所がずれていると感じたので若干不安はあったのですが、うまく機能していて中間テーブルの保存を認識してくれていますね。
git
こちらの検証結果はpublic repositoryで公開しました。
おわりに
Pull request時に動く Copilotに指示を出せるのは、QAの観点から最高の機能です!
どんどん活用していきましょう。
最後にいいねいただけると励みになります。お読みいただきありがとうございました。
Discussion