Databricksで始めよう!最速・最軽量・最低コスト?でMLflowを始めたい時のtips2





モチベーション(読み飛ばし推奨)
前回このような記事を書きました。またありがたいコメントもいただき、https://zenn.dev/link/comments/89d25248e7307c Databricksで無料で始められるのでは?とアドバイスもいただけました。
Databricksは私も大好きなサービスで、正直本件についてはどう取り扱うか悩みました。仰るとおり tokenを取得するだけで外部からMLflowにアクセスできるようになっていて、正直Databrikcs社はこれだとボランティアでMLflowサーバを貸し出している状態です。まじでその使われ方したらどこで儲けるんだ??って言う感じです。
実はこのことも知っていたのですが、どう扱うべき、公開していいものか悩みました。(まあいいんですけど)
しかし・・・よくよく考えるとですね。Databricksには実は無料で利用できるSandboxがあるのです。
太っ腹ですね!確認したところworkflowやSQL系、delta live tables等使えない状態でかなり限定されていますが、なんとExperimentsはあるではありませんか!
これならMLflowは検証できます。
Azure, AWS等使わずに済む検証環境ですらMLflowを貸し出してくれているんですから、Databricksファンを増やしていくために、遠慮なく使わせていただきましょう。
それでは早速、MLflow環境構築スタートです!
アカウント登録から
まずは https://community.cloud.databricks.com/ にアクセスです。
ここは特に変わったことは無いので Sign upからアカウントを作成して、loginまで進めていくだけです。
notebookを作成する
ここからはもはやDatabricks quick start guideですが、Databricksの notebookを作成します。右上の create から notebook を選択し、クリックします。
成功すると下記のようなnotebookが開きます。
細かい話ですが、Databricks notebookは ipython notebookではなく、厳密にはpyファイルになっているので、Databricks特有の機能がipynbとは違ったものが使えますし、コードレビュー等もpyファイルと同様にできます。
clusterを作成する
右上の create clusterからクラスターを作成します。これがDatabricksにとってはjupyter で言うところのkernelに相当します。(少し厳密さは欠けますが、MLflowを試すだけなのでこの理解で大丈夫です。)
この際 Runtimeといって Pythonや library のバージョン、その他Databricksの兼ね備える計算エンジンやきっとOSレベルのバージョン等も全て一括で管理しているものを選択します。
そしてMLflowを利用したいので、この時 ML(machine learning) runtimeを必ず選択するようにしてください。
clusterの作成を待つ
実際業務で使っているclusterだと長くても5分、最近の設定のclusterは1分以内で立ち上がるのですが、検証環境だけあって少し遅いですね。多分spot instance等を活用されているのでは?と推測しながら、じっくり待ちます。
sample codeを実行
import mlflow
import mlflow.sklearn
from sklearn.datasets import load_iris
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
with mlflow.start_run() as run:
model = LinearRegression()
model.fit(X_train, y_train)
mlflow.sklearn.log_model(model, artifact_path="model")
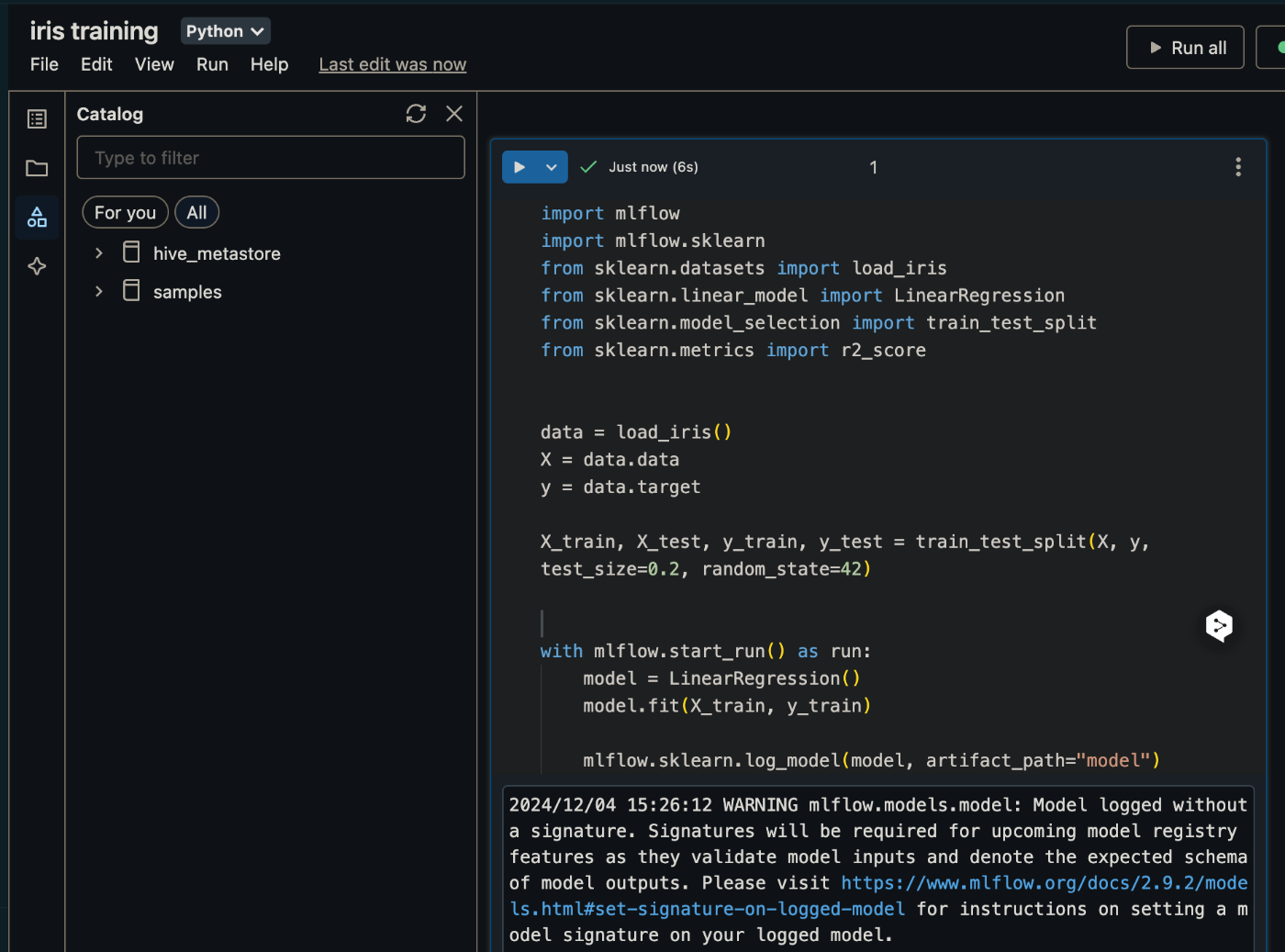
無事に実行完了です。
Experimentsが MLflow serverに該当
中身を見てみましょう、先ほどのMLflowの履歴が残っています!
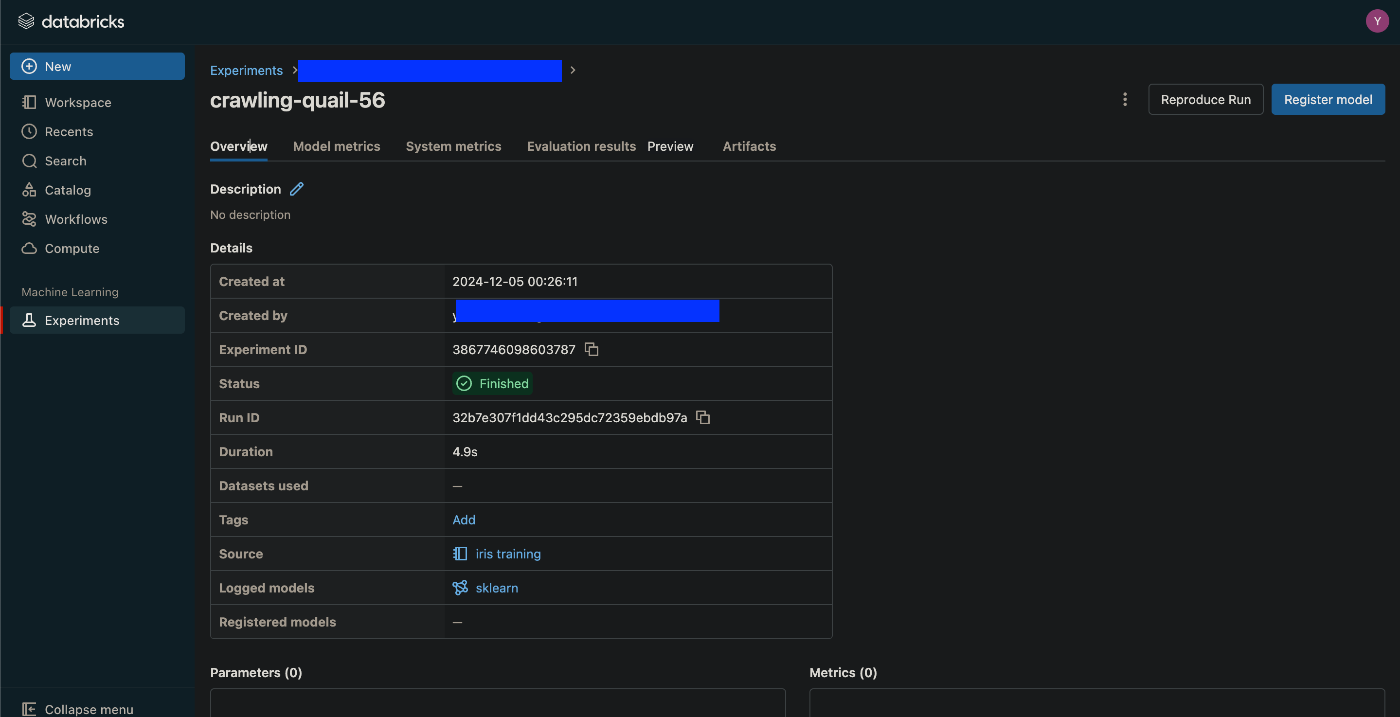
ただし残念がら Register model等は使えないようですね。
このあたりは無念ですがローカルで構築したMLflow等に軍配があがります。
あと、雑談ですが、ここにhugging faceみたいな重めの言語モデルとか保存しようとするとどうなるんでしょうね・・・Databricks側のコスト・・・
Discussion