マルチAIエージェントシステム開発ガイド: LangGraphとMCPによるバックエンドからStreamlitでのUI構築まで
この記事では、LangChainとLangGraph、MCP (Model Context Protocol)を用いてエージェントが連携するバックエンドのロジックを構築し、さらにStreamlitで対話的なユーザーインターフェース(UI)を構築するまで、マルチAIエージェントシステムの開発プロセス全体をステップバイステップで解説します。
最近では大手企業がマルチAIエージェントといえるソリューションの提供を次々と開始しています。
本記事を読むことで、初歩的なものですが、数時間でマルチAIエージェントを構築できるスキルが身につきます。
- NTTデータ LITRON Multi Agent Simulation
- KPMGジャパン、業務特化型生成AIを用いたAIエージェントに係るアドバイザリーサービスの提供を開始
- NTTドコモビジネス(旧:NTTコミュニケーションズ) 20種のAIエージェントを活用した業界別ソリューションの提供を開始
0. デモ
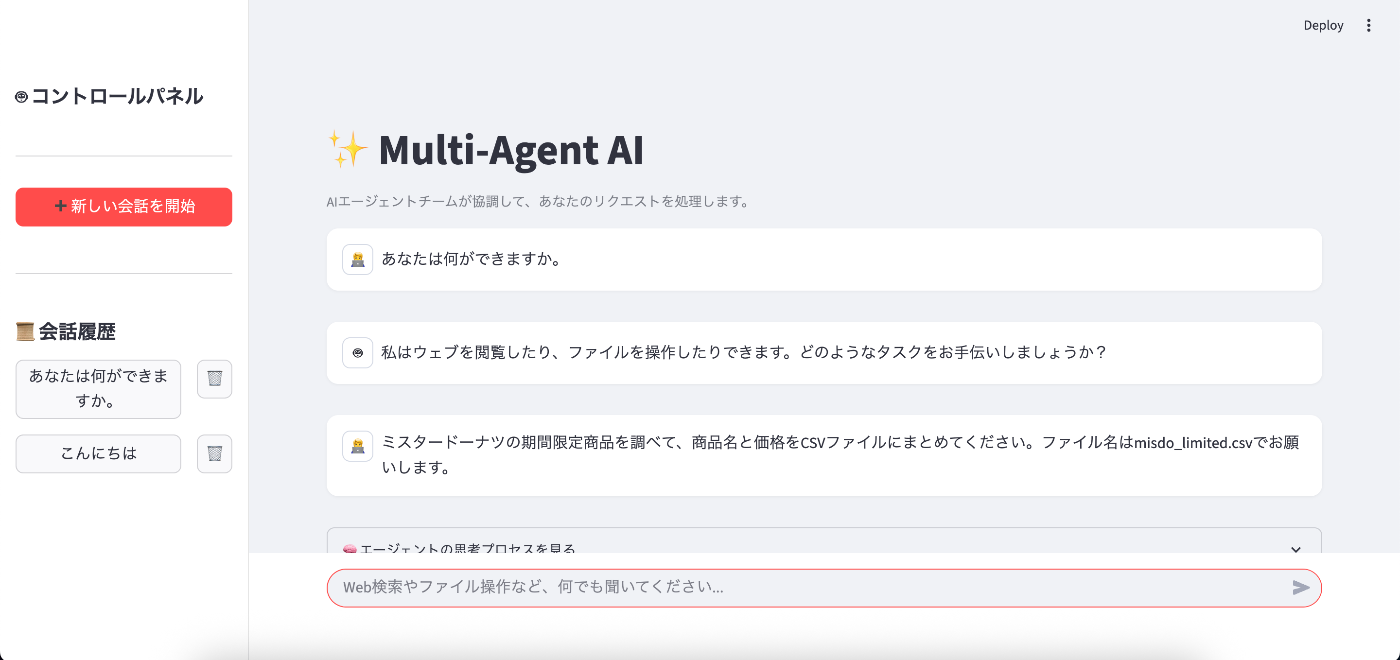
どんなものができあがるのか、まずは完成系のイメージをご覧ください。
UIはChatGPTやGeminiのようになっています。
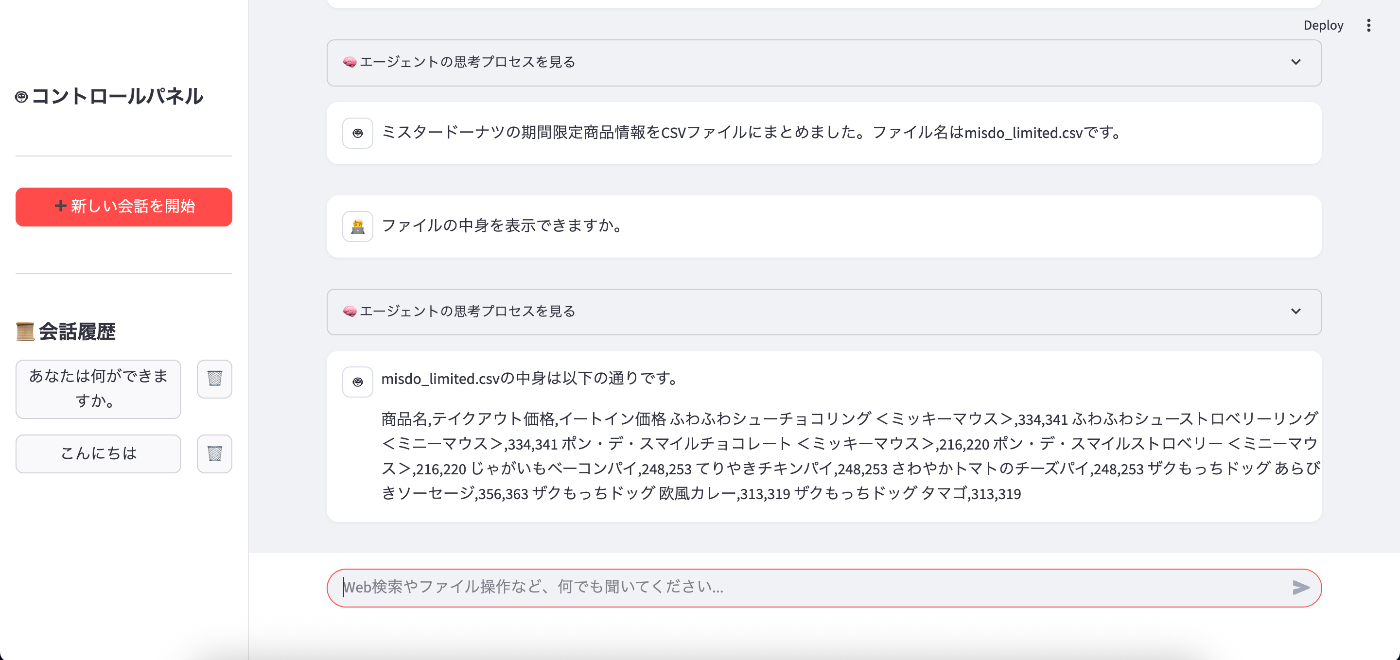
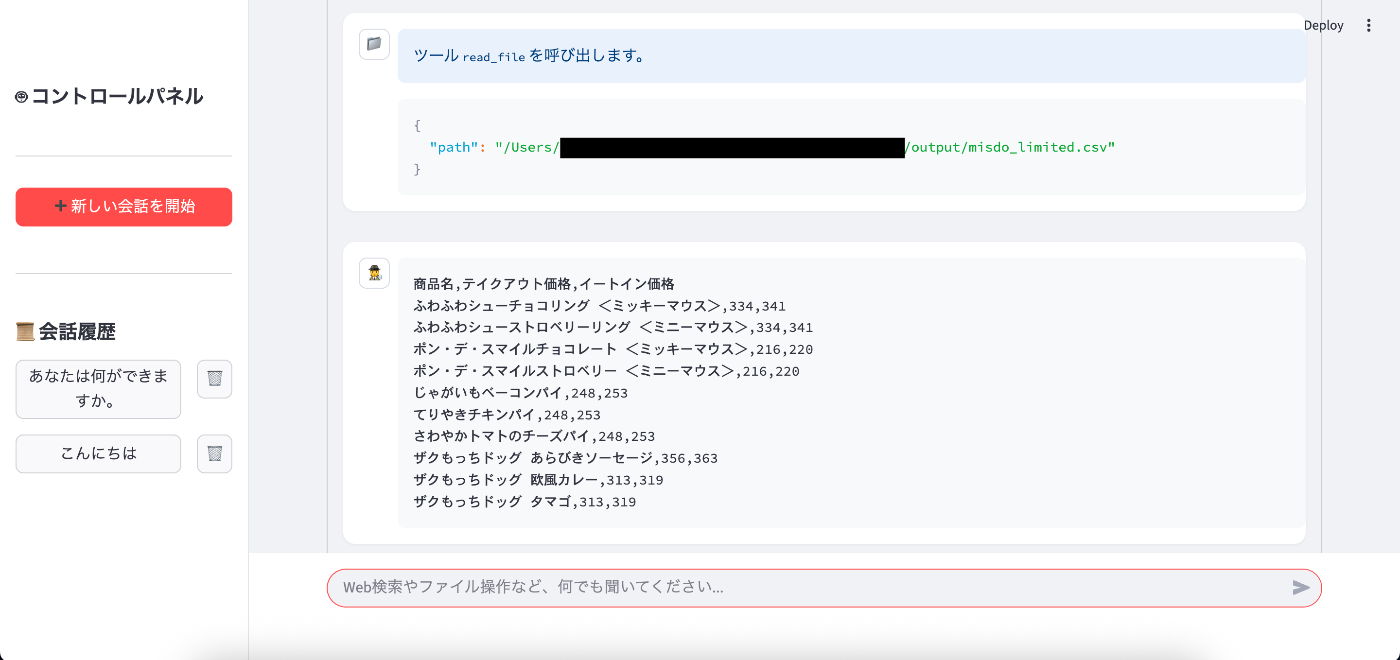
エージェント同士のやり取りの様子も確認できます。

それでは早速作っていきましょう!
1. はじめに:構築するマルチAIエージェントシステムについて
今回構築するマルチAIエージェントシステムは、Googleの生成AIモデル(Gemini)を使用し、ユーザーとの対話及び専門エージェントへの指示出しを行うマネージャーエージェントの下で、Web検索エージェントとファイル操作エージェントが自律的に協業する初歩的なマルチAIエージェントシステムです。
人間がチームで仕事をするように、AIたちもそれぞれの得意分野を活かして協力します。
登場するエージェントは以下の3名です。
- Supervisor(マネージャー): チームの頭脳です。ユーザーからの指示を理解し、タスク全体の計画を立てます。どのワーカーに、いつ、何をさせるべきかを判断し、的確な指示を出します。
- Webサーファー(ワーカー): 情報収集のプロフェッショナル。Supervisorから指示されたキーワードでWebを検索し、必要な情報を集めて報告します。
- ファイルオペレーター(ワーカー): 整理・記録の達人。Supervisorの指示に従い、情報のファイルへの書き込みや、既存ファイルからの読み取りを行います。
これらのエージェントが連携することで、例えば「ミスタードーナツの期間限定商品の情報を調べてCSVファイルにまとめて」といった、Web検索とファイル操作を組み合わせた複雑なタスクを、ユーザーの一度の指示だけで自動で実行できるようになります。
システムの処理の流れ

今回、専門エージェントが行う作業はWeb検索とファイル操作のみですが、専門エージェントの数を増やしペルソナやツールを与えることで、ユースケースに応じた柔軟な機能拡張が可能になります。たとえば、MCPを活用することで、ワーカーとして機能する以下のエージェントを実装でき、より複雑で実用的なタスクの自動化にも対応できます。
- データベースを操作するエージェント:PostgreSQL MCP、MySQL MCPなど
- メッセージアプリを操作するエージェント:Slack MCP、LINE Bot MCPなど
- メール検索・作成・送信するエージェント:Gmail MCP
- スケジュールを組むエージェント:Google Calendar MCP
- Notionを操作するエージェント:Notion MCP
その他にも様々なMCPがあります。
参考:MCPサーバーおすすめ31選!AIエージェントと連携
2. 開発環境の準備
それでは早速、開発環境を整えていきましょう。
2.1. 前提条件
- Python 3.9以上がインストールされていること。
- Node.jsがインストールされていること(npxが使えること)。
- Google AI Studioで取得したGemini APIキーを使用。
2.2. プロジェクト構成
まず、作業用のフォルダを作成します。フォルダ名はmulti-ai-agentとしましょう。その中に、以下のファイルとディレクトリを作成します。
multi-ai-agent/
├── conversation_history/ # AIとの会話履歴を保存するフォルダ
├── output/ # エージェントがファイル操作可能なフォルダ
├── .env # APIキーなどの秘密情報を格納するファイル
├── mcp_config.json # エージェントが使うツールの設定ファイル
├── multi_ai_agent.py # メインのアプリケーションコード
└── requirements.txt # 必要なライブラリを記載したファイル
2.3. ライブラリのインストール
次に、プロジェクトで必要となるPythonライブラリをインストールします。まず、requirements.txtという名前のファイルをプロジェクトフォルダ直下に作成し、以下の内容を記述してください。
requirements.txt
langchain
langchain-core
langchain-openai
langchain_tavily
langchain-mcp-adapters
langchain_google_genai
langchain_community
langgraph
dotenv
python-dotenv
pillow
google-cloud-aiplatform
streamlit
ファイルを作成したら、ターミナルを開き、cdコマンドでmulti-agent-systemフォルダに移動してから、以下のコマンドを実行します。これにより、requirements.txtに記載されたライブラリが一括でインストールされます。
pip install -r requirements.txt
2.4. 環境変数の設定
次に、Google APIキーを設定します。このキーはプログラムのコードに直接書き込むべきではない、大切な情報です。そこで、.envファイルに記述して安全に管理します。プロジェクトフォルダ直下に.envファイルを作成し、以下の内容を記述してください。
.env
GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY"
"YOUR_GOOGLE_API_KEY"の部分は、ご自身が取得した実際のAPIキーに置き換えてください。
3. ツールの設定 (mcp_config.json)
エージェントは、Web検索やファイル操作といった具体的な「行動」を起こすために、「ツール」を使います。このシステムでは、Model-Context-Protocol (MCP) という仕組みを介してツールを利用します。mcp_config.jsonファイルは、どのツールをどのように起動するかを定義するための設定ファイルです。
プロジェクトフォルダ直下にmcp_config.jsonファイルを作成し、以下の内容を記述してください。
mcp_config.json
{
"mcpServers": {
"web-search": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
],
"transport": "stdio"
},
"file-system": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/path/to/your/project/multi-agent-system/output"
],
"transport": "stdio"
}
}
}
-
web-search: Web検索を実行するためのツールサーバーの設定です。npxを通じてPlaywrightのMCPサーバーを起動します。 -
file-system: ファイルの読み書きを行うためのツールサーバーの設定です。-
argsの中にある/path/to/your/project/multi-agent-system/outputの部分は、自身の環境に合わせて書き換えてください。これは、ファイルオペレーターエージェントがファイルの読み書きを許可されるフォルダの絶対パスです。例えば、プロジェクト内にoutputというフォルダを作成し、そのパスを指定します。パスの指定を間違えるとファイル操作ができませんのでご注意ください。
-
4. マルチエージェントシステムの実装 (multi_ai_agent.py)
multi_ai_agent.pyに以下のコードを記述していきます。機能のセクションごとに、それぞれの役割を詳しく解説します。
4.1. STEP 1: インポートと初期設定
まず、プログラムの冒頭で、必要なライブラリをインポートし、基本的な設定を行います。
# 必要なライブラリをインポート
import streamlit as st
import json
import os
import operator
import logging
import uuid
import asyncio
from dotenv import load_dotenv, find_dotenv
from typing import List, Annotated, TypedDict
# LangChain、LangGraph関連のコンポーネントをインポート
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage, ToolMessage, messages_to_dict, messages_from_dict
from langchain_core.utils.function_calling import convert_to_openai_function
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from langchain_mcp_adapters.client import MultiServerMCPClient
# --- 初期設定 ---
# ロギング設定: エージェントたちの会話や行動を記録するための設定
logging.basicConfig(
level=logging.INFO, # INFOレベル以上のログを記録
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
filename='agent_conversation.log', # ログをこのファイルに保存
filemode='a' # 追記モード
)
logger = logging.getLogger(__name__)
# モデルごとのトークン単価(100万トークンあたり)
MODEL_PRICING_PER_MILLION_TOKENS = {
"gemini-2.0-flash": {
"input": 0.10,
"output": 0.40
},
"default": {
"input": 0.10,
"output": 0.40
}
}
def calculate_cost(usage_metadata: dict, model_name: str) -> dict:
"""LLMの利用料金を計算する"""
if not usage_metadata:
return {"input": 0.0, "output": 0.0, "total": 0.0}
pricing = MODEL_PRICING_PER_MILLION_TOKENS.get(model_name, MODEL_PRICING_PER_MILLION_TOKENS["default"])
input_tokens = usage_metadata.get("prompt_token_count", 0)
output_tokens = usage_metadata.get("candidates_token_count", 0)
input_cost = (input_tokens / 1_000_000) * pricing["input"]
output_cost = (output_tokens / 1_000_000) * pricing["output"]
total_cost = input_cost + output_cost
return {"input": input_cost, "output": output_cost, "total": total_cost}
def run_async_in_sync(coro):
"""非同期処理を同期的に実行するためのヘルパー関数"""
try:
loop = asyncio.get_running_loop()
except RuntimeError:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
return loop.run_until_complete(coro)
def sanitize_schema(item):
"""MCPツールのスキーマをLangChainが扱える形式に整形する"""
if isinstance(item, dict):
item.pop('additionalProperties', None)
item.pop('$schema', None)
if 'type' in item and isinstance(item['type'], list):
non_null_types = [t for t in item['type'] if str(t).upper() != 'NULL']
item['type'] = str(non_null_types[0]).upper() if non_null_types else None
for key, value in item.items():
item[key] = sanitize_schema(value)
elif isinstance(item, list):
return [sanitize_schema(i) for i in item]
return item
# 環境変数の読み込み: .envファイルからGOOGLE_API_KEYを読み込む
_ = load_dotenv(find_dotenv())
google_api_key = os.getenv("GOOGLE_API_KEY")
# 会話履歴を保存するディレクトリの作成
CONVERSATION_HISTORY_DIR = "conversation_history"
os.makedirs(CONVERSATION_HISTORY_DIR, exist_ok=True)
ここでは、各種ライブラリのインポートに加え、いくつかのヘルパー関数や定数を定義しています。
-
MODEL_PRICING_PER_MILLION_TOKENS,calculate_cost: エージェントがLLMを利用するたびに、その概算コストを計算・記録するための定数と関数です。これにより、どの処理にどれくらいの費用がかかるかを後から分析できます。 -
run_async_in_sync: 非同期処理をStreamlitのような同期的フレームワーク上で安定して実行するためのヘルパー関数です。 -
sanitize_schema: MCPツールから提供されるスキーマ情報(ツールの使い方定義)を、LangChainが解釈しやすいように整形します。これにより、様々なツールとの互換性が向上します。
4.2. STEP 2: 会話履歴の管理関数
Streamlitアプリケーションでは、ブラウザをリロードすると変数がリセットされてしまいます。そこで、会話の履歴をファイルに保存し、いつでも復元できるようにするための関数を定義します。
def save_conversation(session_id: str, messages: List[BaseMessage]):
"""会話をJSONファイルに保存する"""
if not session_id or not messages:
return
file_path = os.path.join(CONVERSATION_HISTORY_DIR, f"{session_id}.json")
with open(file_path, "w", encoding="utf-8") as f:
json.dump(messages_to_dict(messages), f, ensure_ascii=False, indent=2)
def load_conversation(session_id: str) -> List[BaseMessage]:
"""JSONファイルから会話を読み込む"""
file_path = os.path.join(CONVERSATION_HISTORY_DIR, f"{session_id}.json")
if not os.path.exists(file_path):
return []
with open(file_path, "r", encoding="utf-8") as f:
try:
data = json.load(f)
return messages_from_dict(data)
except (json.JSONDecodeError, TypeError):
return []
def list_conversations() -> List[dict]:
"""保存されている会話の一覧を取得する"""
conversations = []
for filename in os.listdir(CONVERSATION_HISTORY_DIR):
if filename.endswith(".json"):
session_id = filename[:-5]
file_path = os.path.join(CONVERSATION_HISTORY_DIR, filename)
try:
mtime = os.path.getmtime(file_path)
messages = load_conversation(session_id)
# 最初のユーザーメッセージを会話のタイトルとして取得
first_user_message = next((m.content for m in messages if isinstance(m, HumanMessage) and m.additional_kwargs.get("role") != "internal_instruction"), "新しい会話")
title = first_user_message[:40] + "..." if len(first_user_message) > 40 else first_user_message
conversations.append({"id": session_id, "title": title, "mtime": mtime})
except Exception:
continue
conversations.sort(key=lambda x: x["mtime"], reverse=True)
return conversations
def delete_conversation(session_id: str):
"""会話ファイルを削除する"""
file_path = os.path.join(CONVERSATION_HISTORY_DIR, f"{session_id}.json")
if os.path.exists(file_path):
os.remove(file_path)
これらの関数は、session_id(会話ごとのユニークなID)をファイル名として、会話のメッセージオブジェクトをJSON形式に変換して保存・読み込みします。これにより、過去の会話を呼び出したり、途中で中断した作業を再開したりすることが可能になります。
-
load_conversation: ファイルの読み込み時にエラーが発生してもプログラムが停止しないよう、try-exceptブロックで堅牢性を高めています。 -
list_conversations: 保存された会話の一覧を取得する際に、各会話の最初のユーザーメッセージを「タイトル」として抽出します。これにより、サイドバーで過去の会話を探しやすくなります。
4.3. STEP 3: LangGraphの状態定義
LangGraphは、「状態(State)」を持つグラフとして動作します。グラフの中を情報が巡回する際に、その情報を保持しておくための「箱」のようなものです。ここではAgentStateという名前でその箱を定義します。
class AgentState(TypedDict):
"""
グラフの状態を定義するクラス。
messages: これまでの会話のメッセージリスト。
next: 次に実行するべきノード(エージェント)の名前。
"""
messages: List[BaseMessage]
next: str
このAgentStateには、messages(これまでの全会話履歴)とnext(次にどのエージェントを動かすか)の2つの情報を格納します。この状態がグラフのノード間を渡り歩くことで、エージェントたちの連携が実現されます。
4.4. STEP 4: ワーカーエージェントの作成関数
次に、専門的なタスクを実行する「ワーカーエージェント」を生成するための関数を作成します。
def create_worker(llm: ChatGoogleGenerativeAI, tools: list, system_prompt: str):
"""特定の役割を持つワーカーエージェントを作成する"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
])
# LLMにツールをバインドする
return prompt | llm.bind_tools(tools)
この関数は、
* llm: エージェントの言語モデル。
* tools: エージェントが使用できるツールのリスト。
* system_prompt: エージェントの役割や性格を定義する指示文。
の3つを受け取ります。"あなたはWeb検索の専門家です"のようなシステムプロンプトを与えることで、エージェントに専門性を持たせることができます。prompt | llm.bind_tools(tools)の部分は、LangChain Expression Language (LCEL) という記法で、「プロンプトをLLMに渡して、ツールを使えるように設定する」という一連の流れを簡潔に表現しています。
4.5. STEP 5: スーパーバイザーエージェントの作成関数
ワーカーたちを監督し、タスク全体を管理する「スーパーバイザーエージェント」を作成する関数です。
def create_supervisor(llm: ChatGoogleGenerativeAI, worker_names: List[str]):
"""タスクを管理し、ワーカーに指示を出すスーパーバイザーを作成する"""
system_prompt = (
"あなたはAIチームのマネージャーです。あなたの仕事は、ユーザーの要求を達成するために、部下であるワーカーチームを監督することです。\n"
"会話の履歴全体(ユーザーの要求、ワーカーのこれまでの作業結果など)を注意深く確認してください。\n\n"
"以下の手順で行動してください:\n"
"1. **タスクの分析**: ユーザーの要求を達成するために必要なステップを考えます。複数のワーカーによる連携が必要な場合もあります。例えば、'Webサーファー'が収集した情報を'ファイルオペレーター'がファイルに書き込む、といった連携です。\n"
"2. **次の行動の決定**: 分析に基づき、次に取るべき行動を決定します。\n"
" - **ワーカーへの指示**: 特定のタスクをワーカーに任せる場合、そのワーカーの名前を`next`に指定し、具体的な指示内容を`content`に記述します。**重要なのは、以前のワーカーの出力結果を、次のワーカーへの指示に含めることです。** これにより、ワーカー間で情報を引き継ぐことができます。\n"
" - **ユーザーへの直接回答**: 全てのタスクが完了した場合、またはワーカーを必要としない単純な応答の場合は、`next`に'FINISH'を指定し、ユーザーへの最終的な回答を`content`に記述します。\n"
" - **失敗からの回復**: ワーカーがタスクに失敗した場合は、会話履歴を確認し、指示内容を修正して再試行するか、別のアプローチを検討してください。\n\n"
f"利用可能なワーカー:\n{chr(10).join(f'- {name}' for name in worker_names)}"
)
# スーパーバイザーの出力形式を定義するスキーマ
output_schema = {
"title": "supervisor_decision",
"type": "object",
"properties": {
"next": {"type": "string", "description": f"次に実行するワーカー名({', '.join(worker_names)} または FINISH)"},
"content": {"type": "string", "description": "ワーカーへの指示内容、またはユーザーへの最終回答"}
},
"required": ["next", "content"]
}
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
])
# LLMに特定のツール(出力形式)を強制する
llm_with_tool = llm.bind_tools(tools=[output_schema], tool_choice="supervisor_decision")
return prompt, llm_with_tool
Supervisorの最も重要な役割は、「次に誰が(next)」「何をすべきか(content)」を決定することです。この決定を安定して行わせるため、output_schemaというJSON形式の出力フォーマットを定義し、llm.bind_toolsを使ってLLMにこの形式で出力するように強制しています。これにより、Supervisorは常に構造化された指示を出すようになり、システム全体の安定性が向上します。
4.6. STEP 6: グラフの構築 (initialize_graph)
LangGraphを使って、これまで定義してきたエージェントやツールを一つの協調的なワークフローとして組み立てます。この処理は重いため、@st.cache_resourceデコレータを付けて、初回実行時に結果をキャッシュするようにしています。
このinitialize_graph関数の中は、さらにいくつかのステップに分かれています。
4.6.1. LLMとツールの準備
まず、SupervisorとWorkerが使用するLLMのインスタンスを作成し、mcp_config.jsonからツール設定を読み込んで、利用可能なツールの一覧を取得します。
# --- 6.1: LLMとツールの準備 ---
# SupervisorとWorkerが使用するモデル名を指定
# ここでは同じモデルを使用するが、役割に応じて別のモデル(より高性能なモデルなど)を割り当てることも可能
supervisor_model_name = "gemini-2.0-flash"
worker_model_name = "gemini-2.0-flash"
# LLMのインスタンスを作成。temperature=0.0で、出力のランダム性を抑え、再現性を高める
supervisor_llm_instance = ChatGoogleGenerativeAI(model=supervisor_model_name, temperature=0.0, google_api_key=google_api_key)
worker_llm_instance = ChatGoogleGenerativeAI(model=worker_model_name, temperature=0.0, google_api_key=google_api_key)
# mcp_config.json ファイルからツールの設定を読み込む
with open("mcp_config.json", "r") as f:
mcp_config = json.load(f)
# 設定を元に、複数のツールサーバーと通信するためのMCPクライアントを作成
mcp_client = MultiServerMCPClient(mcp_config["mcpServers"])
# MCPクライアント経由で利用可能なツールの一覧を非同期で取得し、同期的に結果を待つ
tools = run_async_in_sync(mcp_client.get_tools())
# 取得したツールを、LLMの関数呼び出し(Function Calling)機能が理解できる形式 (OpenAI互換の形式) に変換・整形する
sanitized_tools = [sanitize_schema(convert_to_openai_function(t)) for t in tools]
ここではエージェントたちが使う「脳」となるLLMと、「手足」となるツールを準備します。temperature=0.0に設定することで、LLMの出力が安定し、毎回同じような思考・行動をとるようになり、システム全体の信頼性が向上します。mcp_config.jsonからツール情報を読み込み、sanitize_schema関数でLLMが扱いやすい形式に整えることで、様々なツールとの互換性を確保しています。
4.6.2. エージェントの定義
次に、準備したLLMとツール、そして役割を定義したプロンプトを使って、各エージェントを実際に生成します。
# --- 6.2: エージェントの定義 ---
# create_worker関数を使い、各ワーカーの定義をdict形式でまとめる
workers = {
"Webサーファー": create_worker(
worker_llm_instance,
sanitized_tools,
"あなたはWeb検索の専門家です。web-searchツールを使用することができます。\n与えられた指示を達成するために適切な検索ワードを考え、必要な情報を検索してください。検索結果は、次の担当者(または最終的な回答者)が理解しやすいように、明確かつ詳細に報告してください。"
),
"ファイルオペレーター": create_worker(
worker_llm_instance,
sanitized_tools,
"あなたはローカルファイルを操作する専門家です。file-systemツールを使用することができます。\n与えられた指示(ファイルパスや書き込む内容など)に正確に従って、ファイル操作を実行してください。操作が成功したか、失敗したかを明確に報告してください。"
),
}
# create_supervisor関数を使い、スーパーバイザーを定義する
supervisor_prompt, supervisor_llm = create_supervisor(supervisor_llm_instance, list(workers.keys()))
create_workerとcreate_supervisor関数を呼び出して、3体のエージェント(Webサーファー、ファイルオペレーター、スーパーバイザー)をインスタンス化します。各ワーカーには、その役割に特化したシステムプロンプトが与えられています。
4.6.3. ノード(登場人物)の関数の定義
グラフの各登場人物(ノード)が、状態を受け取ったときに何をするかを関数として定義します。
# --- 6.3: ノード(登場人物)の関数の定義 ---
def supervisor_node(state: AgentState):
"""スーパーバイザーノード。次に何をすべきかを決定し、自身の思考も記録する"""
logger.info("--- Supervisor Node ---")
# 現在の会話履歴をインプットとして、スーパーバイザーLLMを呼び出す
chain = supervisor_prompt | supervisor_llm
response_message = chain.invoke({"messages": state["messages"]})
# LLMの利用状況(トークン数)を取得し、コストを計算してロギングする
usage_metadata = response_message.response_metadata.get("usage_metadata", {})
costs = calculate_cost(usage_metadata, supervisor_model_name)
logger.info(f"Cost (Supervisor - {supervisor_model_name}): Input: ${costs['input']:.6f}, Output: ${costs['output']:.6f}, Total: ${costs['total']:.6f}")
logger.info(f"Token Usage (Supervisor): {usage_metadata}")
# LLMの出力(ツール呼び出し)から、次のアクションと指示内容を取得
tool_call = response_message.tool_calls[0]
supervisor_output = tool_call['args']
logger.info(f"Output: {supervisor_output}")
content = supervisor_output.get("content", "")
next_action = supervisor_output.get("next", "FINISH")
# Supervisor自身の思考(決定内容)をメッセージとして作成
# これがUIの「思考プロセス」に表示される
supervisor_comment_content = content if next_action == "FINISH" else f"【指示: {next_action}へ】\n{content}"
supervisor_comment = AIMessage(content=supervisor_comment_content, name="Supervisor")
# 次のアクションがワーカーへの指示の場合
if next_action != "FINISH":
# ワーカーへの指示は、UI上では直接表示しない内部的なメッセージとして作成
instruction_for_worker = HumanMessage(content=content, additional_kwargs={"role": "internal_instruction"})
# 状態を更新:現在のメッセージリストに「Supervisorのコメント」と「ワーカーへの内部指示」を追加
return {"messages": state["messages"] + [supervisor_comment, instruction_for_worker], "next": next_action}
else:
# 状態を更新:現在のメッセージリストに「Supervisorの最終コメント」を追加
return {"messages": state["messages"] + [supervisor_comment], "next": next_action}
def worker_node(state: AgentState):
"""ワーカーノード。指定されたワーカーを実行し、エラーハンドリングも行う"""
worker_name = state["next"]
worker = workers[worker_name]
logger.info(f"--- Worker Node: {worker_name} ---")
# 現在の会話履歴をインプットとして、担当ワーカーのLLMを呼び出す
response = worker.invoke({"messages": state['messages']}, {"recursion_limit": 10})
# LLMの利用状況(トークン数)を取得し、コストを計算してロギングする
usage_metadata = response.response_metadata.get("usage_metadata", {})
costs = calculate_cost(usage_metadata, worker_model_name)
logger.info(f"Cost ({worker_name} - {worker_model_name}): Input: ${costs['input']:.6f}, Output: ${costs['output']:.6f}, Total: ${costs['total']:.6f}")
logger.info(f"Token Usage ({worker_name}): {usage_metadata}")
logger.info(f"Output: {response}")
# エラーハンドリング:LLMがツールの形式を正しく生成できなかった場合など
finish_reason = response.response_metadata.get('finish_reason', '')
if finish_reason == 'MALFORMED_FUNCTION_CALL' or (not response.content and not hasattr(response, 'tool_calls')):
error_message = f"(システムエラー:{worker_name}がタスクの実行に失敗しました。理由: {finish_reason}。指示を修正して再試行します。)"
logger.error(f"Worker {worker_name} failed. Reason: {finish_reason}. Message: {response.response_metadata.get('finish_message', 'N/A')}")
# エラーメッセージを生成してSupervisorに報告する
response = AIMessage(content=error_message, name=worker_name)
# ワーカー名をレスポンスに付与し、状態を更新
response.name = worker_name
return {"messages": state["messages"] + [response]}
# LangGraphが提供する便利なToolNodeを準備
_tool_node = ToolNode(tools)
# ToolNodeを非同期で実行するためのカスタムラッパー関数
async def custom_tool_node(state: AgentState):
"""ワーカーが呼び出したツールを実際に実行するノード"""
tool_results = await _tool_node.ainvoke(state)
return {"messages": state["messages"] + tool_results["messages"]}
supervisor_nodeはSupervisorの意思決定を行い、worker_nodeは指定されたワーカーを実行します。重要なのは*ロギングとエラーハンドリング、そして思考プロセスの記録です。
-
ロギングとコスト計算: 各ノードの実行時に、入力、出力、トークン使用量、概算コストを
agent_conversation.logに記録します。これにより、後からデバッグやパフォーマンス分析が容易になります。 -
思考プロセスの記録:
supervisor_nodeは、ユーザーに見せる最終回答とは別に、自身の決定内容(supervisor_comment)とワーカーへの指示(instruction_for_worker)を区別してメッセージリストに追加します。これがUI上で「思考プロセス」として表示される仕組みの核となります。 -
エラーハンドリング:
worker_nodeでは、ワーカーがツール呼び出しに失敗した場合でもシステムが停止せず、エラーメッセージをSupervisorに返すことで、処理の継続ややり直しを試みることができます。 -
custom_tool_node:ToolNodeはLangGraphが提供する便利なノードで、ツール呼び出しを自動で処理してくれます。
4.6.4. エッジ(繋がり)と条件分岐の定義
ノード間の繋がり(エッジ)と、状況に応じた処理の流れ(ルーティング)を定義します。
# --- 6.4: エッジ(繋がり)と条件分岐の定義 ---
def after_worker_router(state: AgentState) -> str:
"""ワーカーの実行後、次にどこへ進むかを決定するルーター"""
last_message = state["messages"][-1]
# ワーカーの最後の発言がツール呼び出し (tool_calls) を含んでいれば...
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
# ...次は 'tools' ノードに進んでツールを実行する
return "tools"
# そうでなければ...
# ...'supervisor' ノードに戻って次の指示を仰ぐ
return "supervisor"
def supervisor_router(state: AgentState) -> str:
"""スーパーバイザーの実行後、次にどこへ進むかを決定するルーター"""
# スーパーバイザーが決定した次のアクションを取得
next_val = state.get("next")
# アクションが 'FINISH' または未定なら...
if not next_val or next_val == "FINISH":
# ...特別な 'END' ノードに進んでグラフの実行を終了する
return END
# そうでなければ...
# ...指定されたワーカーのノードに進む
return next_val
add_conditional_edgesを使うことで、「もしワーカーがツールを呼び出したらtoolsノードへ、そうでなければsupervisorノードへ」といった条件分岐(ルーティング)を実現できます。これにより、状況に応じて処理の流れを動的に変えることができます。
4.6.5. グラフの組み立て
最後に、ここまで定義したノードとエッジをStateGraphに追加していき、実行可能なアプリケーションとして完成させます。
# --- 6.5: グラフの組み立て ---
# AgentStateを状態として持つStateGraphのインスタンスを作成
workflow = StateGraph(AgentState)
# 各ノードをグラフに追加
workflow.add_node("supervisor", supervisor_node)
workflow.add_node("tools", custom_tool_node)
for name in workers:
workflow.add_node(name, worker_node)
# 各ワーカーノードの後に、after_worker_router に基づく条件付きエッジを設定
for name in workers:
workflow.add_conditional_edges(
name,
after_worker_router,
{"tools": "tools", "supervisor": "supervisor"}
)
# ツールノードの後は、必ずスーパーバイザーノードに戻るエッジを設定
workflow.add_edge("tools", "supervisor")
# スーパーバイザーノードの後に、supervisor_router に基づく条件付きエッジを設定
# FINISH の場合は END に、それ以外は指定されたワーカーのノードに進む
workflow.add_conditional_edges(
"supervisor",
supervisor_router,
{**{name: name for name in workers}, END: END}
)
# グラフの開始点を指定 (最初に 'supervisor' ノードが実行される)
workflow.add_edge(START, "supervisor")
# グラフのコンパイルとチェックポインターの設定
# MemorySaverを使うことで、各ステップの状態がメモリに保存され、デバッグや再開が容易になる
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
logger.info("グラフの初期化が完了しました。")
return app
add_nodeで登場人物を、add_edgeやadd_conditional_edgesで彼らの関係性と仕事の流れを定義します。STARTで仕事の開始点を指定し、ENDで終了点を定義します。最後にcompile()メソッドで、これらすべてを一つにまとめて実行可能なアプリケーション(app)として完成させます。
4.7. STEP 7: StreamlitによるUIの実装
最後に、ユーザーがブラウザからこのシステムと対話できるように、Streamlitを使ってユーザーインターフェースを構築します。
st.set_page_config(page_title="Multi-Agent AI", page_icon="✨", layout="wide")
st.markdown("""
<style>
.stApp { background-color: #f0f2f6; }
[data-testid="stChatMessage"] { background-color: white; border-radius: 0.75rem; box-shadow: 0 1px 3px rgba(0,0,0,0.05); margin-bottom: 1rem; }
[data-testid="stSidebar"] { background-color: #ffffff; border-right: 1px solid #e6e6e6; }
.stButton>button { border-radius: 0.5rem; }
</style>
""", unsafe_allow_html=True)
with st.sidebar:
st.header("🤖 コントロールパネル")
st.markdown("---")
if st.button("➕ 新しい会話を開始", use_container_width=True, type="primary"):
st.session_state.session_id = str(uuid.uuid4())
st.session_state.messages = []
st.rerun()
st.markdown("---")
st.header("📜 会話履歴")
past_conversations = list_conversations()
if not past_conversations:
st.caption("まだ会話履歴はありません。")
for conv in past_conversations:
col1, col2 = st.columns([4, 1])
with col1:
if st.button(conv["title"], key=f"load_{conv['id']}", use_container_width=True):
st.session_state.session_id = conv["id"]
st.session_state.messages = load_conversation(conv["id"])
st.rerun()
with col2:
if st.button("🗑️", key=f"delete_{conv['id']}", use_container_width=True, help="この会話を削除します"):
delete_conversation(conv["id"])
if st.session_state.get("session_id") == conv["id"]:
st.session_state.session_id = str(uuid.uuid4())
st.session_state.messages = []
st.rerun()
st.title("✨ Multi-Agent AI")
st.caption("AIエージェントチームが協調して、あなたのリクエストを処理します。")
if not google_api_key:
st.error("Google AI StudioのAPIキーが設定されていません。.envファイルに GOOGLE_API_KEY を設定してください。")
st.stop()
try:
graph = initialize_graph()
except Exception as e:
st.error(f"アプリケーションの初期化中にエラーが発生しました: {e}")
st.exception(e)
st.stop()
if "session_id" not in st.session_state:
st.session_state.session_id = str(uuid.uuid4())
st.session_state.messages = []
def render_internal_message(msg: BaseMessage):
avatar_map = {"Supervisor": "🤖", "Webサーファー": "🌐", "ファイルオペレーター": "📁", "internal_instruction": "📝", "tool_call": "🛠️", "tool_result": "✅"}
name, avatar = "System", "⚙️"
if hasattr(msg, 'name') and msg.name:
name, avatar = msg.name, avatar_map.get(msg.name, "🕵️")
elif isinstance(msg, HumanMessage) and msg.additional_kwargs.get("role") == "internal_instruction":
name, avatar = "内部指示", avatar_map["internal_instruction"]
elif isinstance(msg, AIMessage) and hasattr(msg, 'tool_calls') and msg.tool_calls:
name, avatar = "ツール呼び出し", avatar_map["tool_call"]
elif isinstance(msg, ToolMessage):
name, avatar = f"ツール実行結果 ({msg.name})", avatar_map["tool_result"]
with st.chat_message(name, avatar=avatar):
if isinstance(msg, AIMessage) and not msg.content and hasattr(msg, 'tool_calls') and msg.tool_calls:
tool_call = msg.tool_calls[0]
st.info(f"ツール `{tool_call['name']}` を呼び出します。")
st.code(json.dumps(tool_call['args'], indent=2, ensure_ascii=False), language="json")
elif isinstance(msg, ToolMessage):
try:
content_dict = json.loads(msg.content)
st.code(json.dumps(content_dict, indent=2, ensure_ascii=False), language="json")
except (json.JSONDecodeError, TypeError):
st.code(str(msg.content), language="text")
else:
st.markdown(msg.content)
turns = []
current_turn_messages = []
for msg in st.session_state.get("messages", []):
is_real_user_message = isinstance(msg, HumanMessage) and msg.additional_kwargs.get("role") != "internal_instruction"
if is_real_user_message and current_turn_messages:
turns.append(current_turn_messages)
current_turn_messages = []
current_turn_messages.append(msg)
if current_turn_messages:
turns.append(current_turn_messages)
for turn in turns:
user_message, agent_steps = turn[0], turn[1:]
with st.chat_message("user", avatar="🧑💻"):
st.markdown(user_message.content)
if agent_steps:
final_answer = None
internal_steps = []
last_step = agent_steps[-1]
if isinstance(last_step, AIMessage) and last_step.name == "Supervisor":
final_answer = last_step
internal_steps = agent_steps[:-1]
else:
internal_steps = agent_steps
if internal_steps:
with st.expander("🧠 エージェントの思考プロセスを見る"):
for step in internal_steps:
render_internal_message(step)
if final_answer:
with st.chat_message("assistant", avatar="🤖"):
st.markdown(final_answer.content)
if prompt := st.chat_input("Web検索やファイル操作など、何でも聞いてください..."):
st.session_state.messages.append(HumanMessage(content=prompt))
with st.chat_message("user", avatar="🧑💻"):
st.markdown(prompt)
with st.spinner("🧠 AIエージェントが思考中..."):
try:
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
input_messages = {"messages": st.session_state.messages}
final_state = run_async_in_sync(graph.ainvoke(input_messages, config))
st.session_state.messages = final_state["messages"]
save_conversation(st.session_state.session_id, st.session_state.messages)
st.rerun()
except Exception as e:
st.error(f"エラーが発生しました: {e}")
st.exception(e)
このUIコードは、
- 洗練されたデザイン: CSSを適用し、チャット画面やサイドバーの見た目を整えています。
- 会話履歴: サイドバーには、単なるIDではなく**会話の「タイトル」**が表示され、目的の会話を見つけやすくなっています。
- 思考プロセスの可視化: このUIの最大の特徴は、単に最終的な回答を表示するだけでなく、**「🧠 エージェントの思考プロセスを見る」**という折りたたみ(Expander)の中に、エージェントたちの中間的なやり取りを全て表示する点です。Supervisorの指示、ワーカーのツール呼び出し、ツールの実行結果などがステップごとに表示されるため、AIがどのように考えてタスクを解決したのかを詳細に追跡できます。
-
実行ロジック: ユーザーがメッセージを入力すると、
graph.ainvokeを使ってエージェントの処理を最後まで実行し、得られた**全てのメッセージ履歴(中間ステップを含む)**でセッション情報を更新します。その後、st.rerun()で画面全体を再描画することで、思考プロセスと最終回答を一度にUIに反映させます。
5. アプリケーションの実行
ターミナルで以下のコマンドを実行して、作成したアプリケーションを起動しましょう。
streamlit run multi_ai_agent.py
コマンドを実行すると、ブラウザが自動で立ち上がり、http://localhost:8501にアクセスします。そこに、マルチエージェントシステムのチャット画面が表示されます。
6. 動作の確認
アプリケーションが起動したら、実際にリクエストを送ってみましょう。例えば、以下のように入力してみてください。
「ミスタードーナツの期間限定商品を調べて、商品名と価格をCSVファイルにまとめてください。ファイル名はmisdo_limited.csvでお願いします。」
このリクエストを送ると、バックグラウンドでエージェントたちが動き出します。ターミナルやagent_conversation.logファイルを見ると、彼らの活発な議論と行動の記録を垣間見ることができます。
-
Supervisor: ユーザーの要求を分析し、「まずWebで情報を検索し、次にその結果をCSVファイルに書き込む必要がある」と計画します。そして
Webサーファーに「ミスタードーナツ 期間限定商品」で検索するように指示します。 - Webサーファー: 指示通りにWeb検索を実行し、公式サイトなどの情報を見つけ、その内容をSupervisorに報告します。
-
Supervisor: 報告された情報から商品名と価格を抽出し、CSV形式のデータを作成します。そして、
ファイルオペレーターに「このCSVデータを使ってmisdo_limited.csvという名前でファイルを作成して」と指示します。 -
ファイルオペレーター: 指示を受け取り、
mcp_config.jsonで指定したoutputディレクトリ内にmisdo_limited.csvファイルを作成・保存します。 -
Supervisor: ファイル作成完了の報告を受け、全てのタスクが完了したと判断。ユーザーに「期間限定商品の情報をCSVファイルにまとめました。
outputフォルダをご確認ください。」と最終報告を行い、FINISHで処理を終了します。
このように、各エージェントが自律的に自身の役割をこなし、連携することで、当初のユーザーの要求が達成される様子が確認できるはずです。
以上
Discussion