サーバーいらずのAI活用!Next.js × Transformers.jsでローカル実行のQAアプリを作ろう
こんにちは!最近、技術ブログの執筆をサボりがちなhiraokuです。
今回は、Next.jsを使ってローカルAIを動かしてみます。ChatGPTやClaudeのようなクラウドベースのサービスではなく、Hugging Face Hubで公開されている機械学習モデルをローカルにダウンロードして実行します。
WASMの可能性を検証するため、今回はあえてモデルをクライアント側で動作させてみました。結果は驚くほど簡単で、しかもほぼ期待通りに動作したため、この経験をぜひ共有したいと思います。
なお、より高い性能を求める場合は、WebGPUを活用したり、サーバーサイドでモデルを動作させたりすることをおすすめします。今回のコードをベースとすれば、これらへの切り替えも容易に可能です。
それでは、さっそく始めましょう!
サンプルアプリ
こちらが今回作成したサンプルアプリです。
このアプリでは、モデルをクライアント側に配置し、Transformers.jsを用いて推論を実行しています。WASMベースの推論処理によって、効率的かつ高速なモデル実行が可能です。
さらに、推論に必要な前処理や後処理もアプリ内で完結させており、すべての処理をローカル環境で行えます。
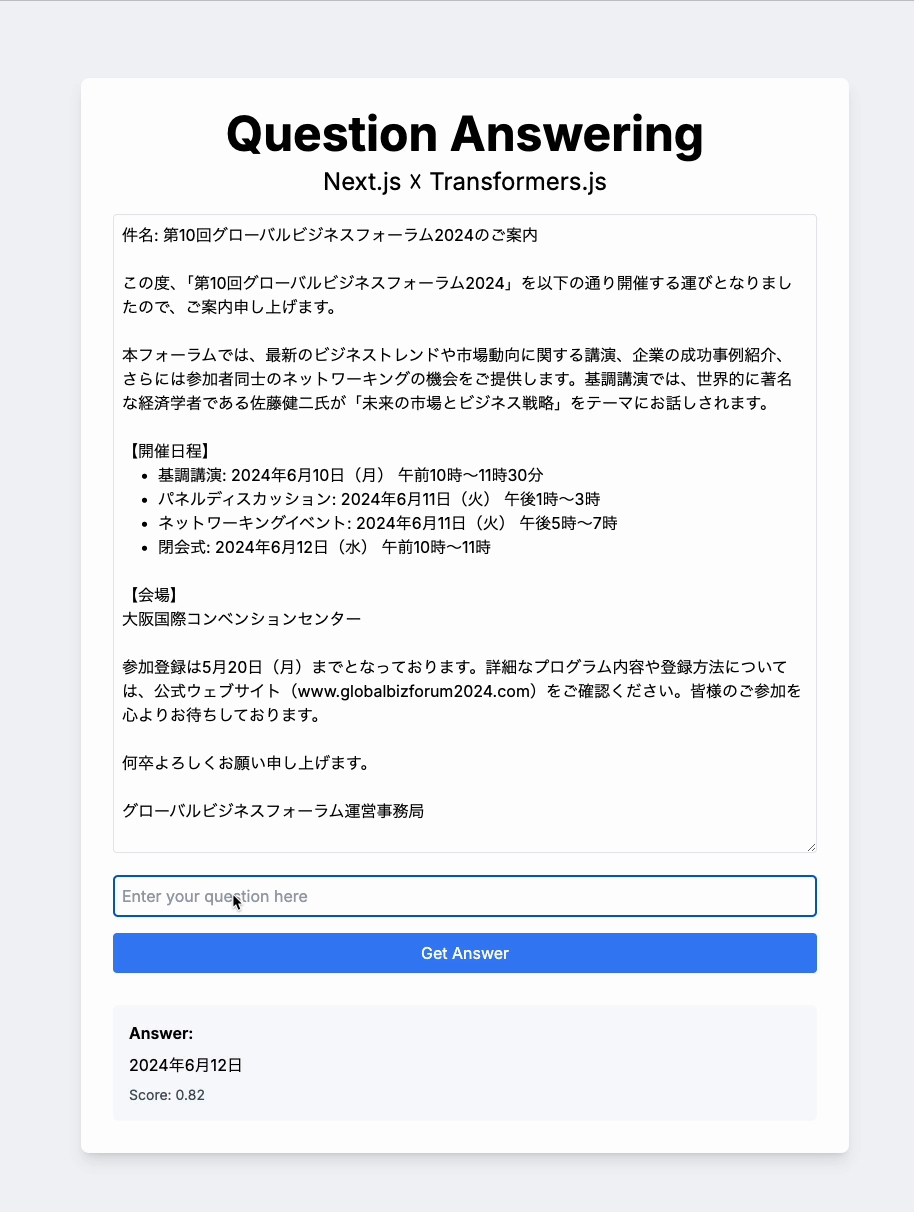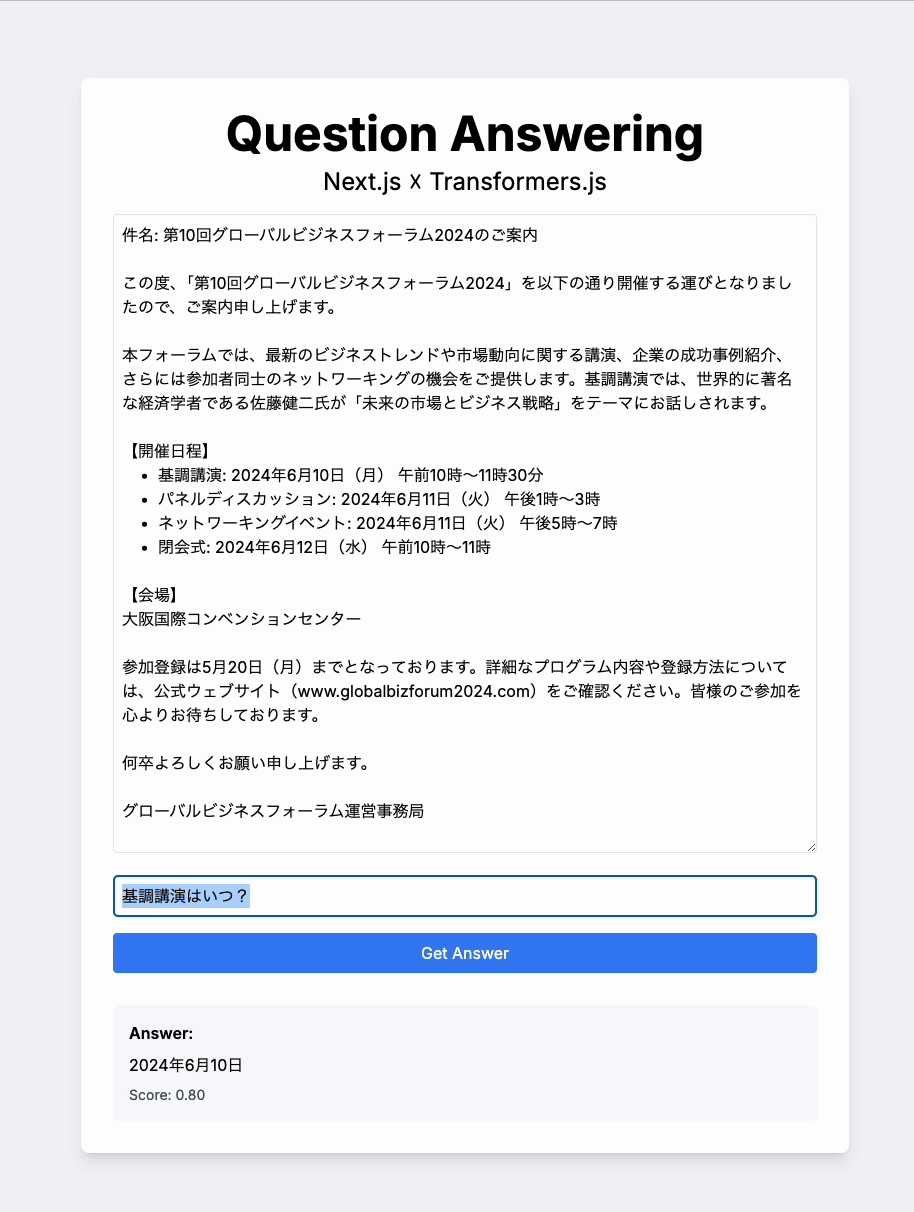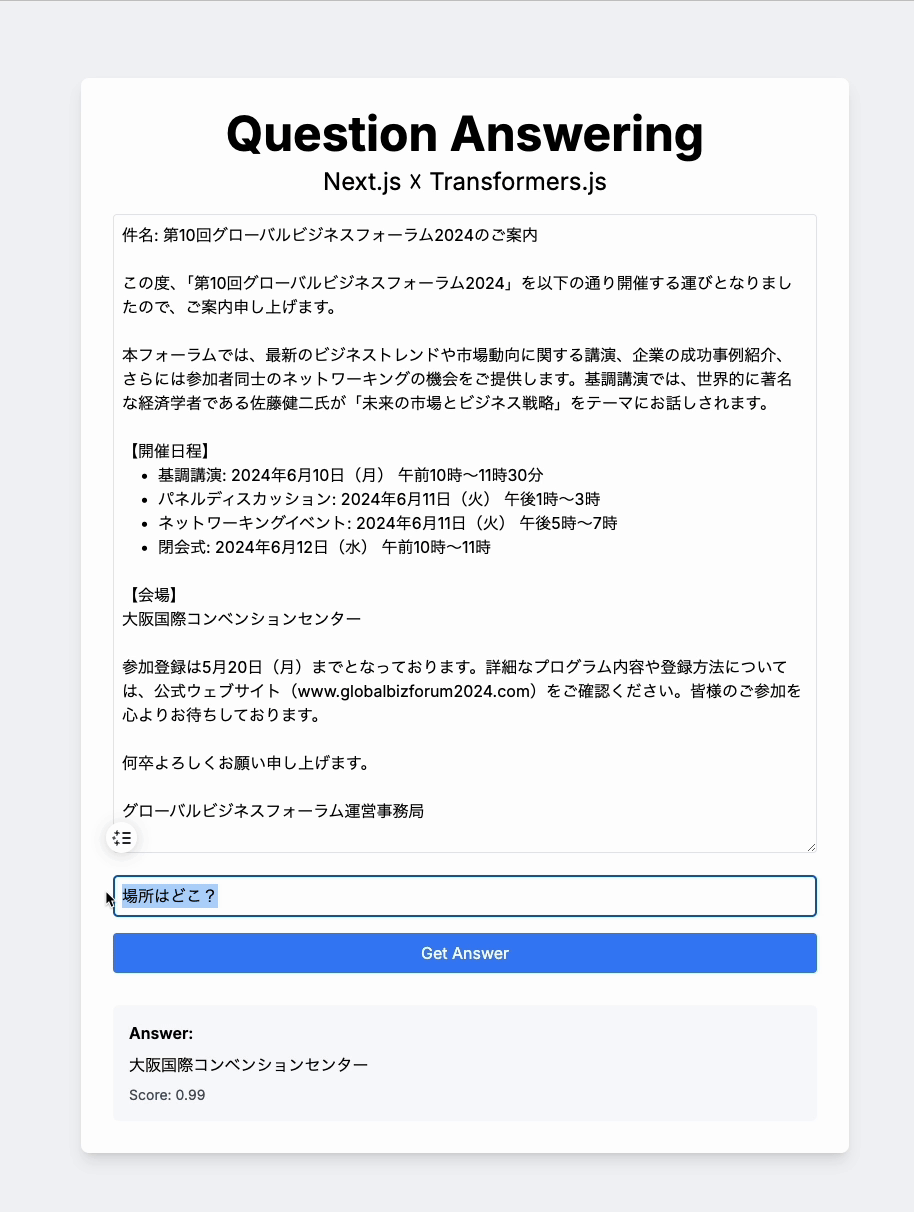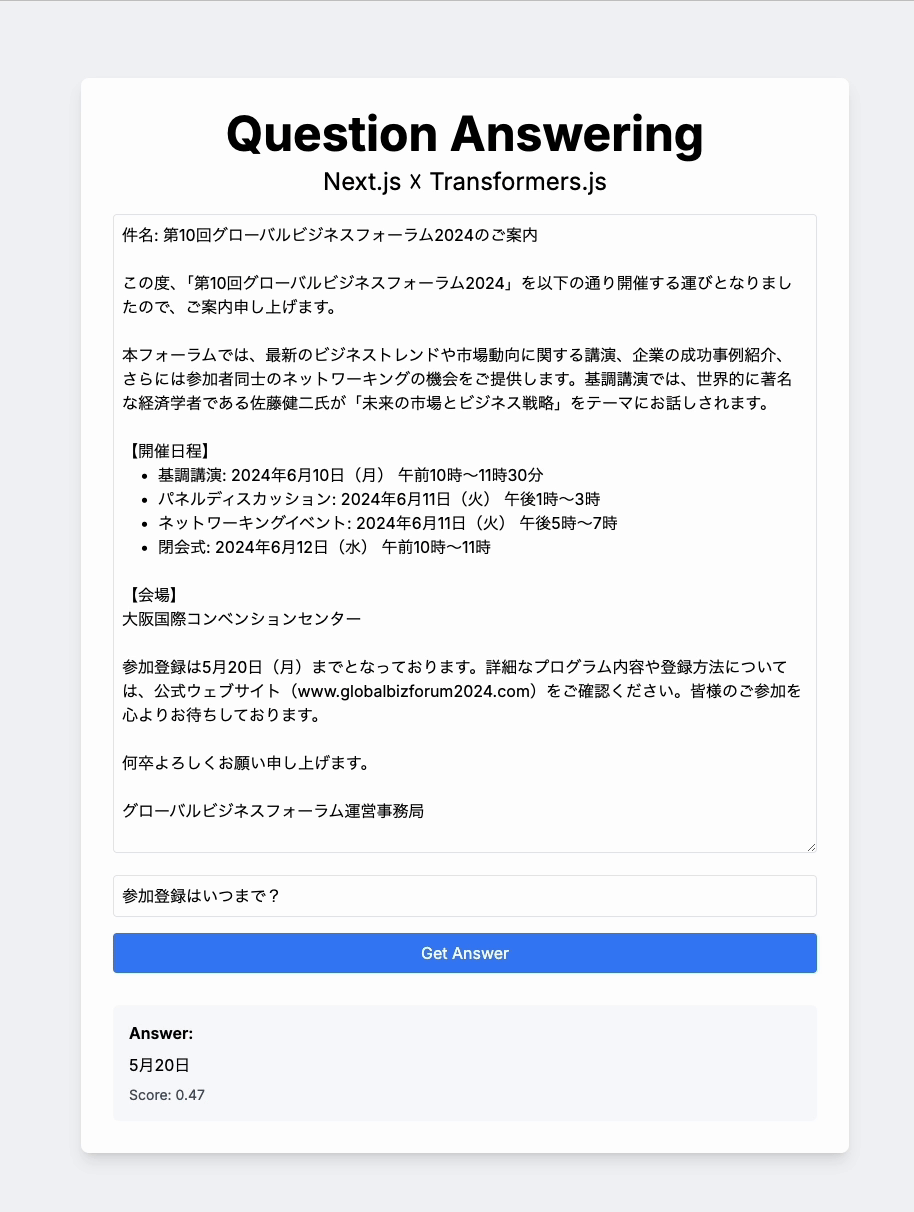
QAアプリの動作
サンプルアプリの機能は、コンテンツと質問を入力すると、それに対してAIが回答してくれるというものです。
予想以上に回答の精度が高く、レスポンスも非常に速いです。もちろん、複雑な質問には対応できない場合もありますが、フロントエンドで可能な処理の幅を大きく広げる可能性を感じました。
使用ライブラリ
ブラウザ向けAIライブラリは、TensorFlow.js、ONNXRuntime-Webなどいろいろありますが、今回は
Transformers.jsを使用します。
「Transformers.js」は、HuggingFaceが開発した機械学習ライブラリ「Transformers」のJavaScript版です。今回は、最新版の「Transformers.js v3」を使用します。
サポートしている、主な機能は、以下のとおりです。
主な機能
- WebGPUをサポートし、WASMと比較して最大100倍の高速化を実現
- 新しい量子化フォーマットを採用し、効率と柔軟性を向上
- 合計120種類のアーキテクチャをサポート
- 25種類の新しいサンプルプロジェクトとテンプレートを追加
- Hugging Face Hubに1200以上の変換済みモデルが公開され、すぐに利用可能
- Node.js(ESM + CJS)、Deno、Bunに対応し、幅広い環境で実行可能
- Transformers.js専用の新しいページをGitHubとNPMに公開
その他詳細は、こちらをご覧ください!
コード解説
サンプルアプリはWeb Workerを使用しています。メインスレッドではUIの制御とWeb Workerの初期化を行い、機械学習モデルの読み込みや推論処理はWeb Worker側で実行します。これにより、メインスレッドに負荷をかけずに処理を進めることができます。
ここでは、機械学習モデルを実行するためのコードに焦点を当てて説明していきます。

ファイル構成
サンプルアプリの機械学習モデルを実行する処理は、以下の2ファイルで実現しています。

- page.tsx
- メインのコンポーネントの実装、Web Wokerの初期化処理、Wokerからのメッセージ受信処理
- worker.ts
- モデルのインスタンスの生成、メインスレッドからのメッセージ監視
page.tsx
Web Workerの初期化処理
Web Workerの初期化を行います。この初期化は、InitializeWorker関数で実現しています。具体的な処理は以下の通りです。
const initializeWorker = () => {
const worker = new Worker(new URL("./worker.ts", import.meta.url), {
type: "module",
});
return worker;
};
Web Workerの作成の詳細は以下の通りです。
- new Worker(new URL("./worker.ts", import.meta.url), { type: "module" }) を使用して、worker.ts ファイルを新しいWorkerとして作成します。
- import.meta.url を利用することで、現在のモジュールからの相対パスを解決します。
- { type: "module" } オプションにより、Web WorkerがES Modules形式で動作するように設定します。
Web Workerの初期化処理の実行
InitializeWorkerを呼び出して、初期化処理を実行します。この処理は、メインのコンポーネントのuseEffectで実行しています。
useEffect(() => {
if (!workerRef.current) {
workerRef.current = initializeWorker();
}
const worker = workerRef.current;
// メッセージリスナーの登録
worker.addEventListener("message", handleMessageReceived);
// エラーリスナーの登録
worker.addEventListener("error", handleWorkerError);
worker.addEventListener("messageerror", handleWorkerMessageError);
return () => {
// リスナーの解除
worker?.removeEventListener("message", handleMessageReceived);
worker?.removeEventListener("error", handleWorkerError);
worker?.removeEventListener("messageerror", handleWorkerMessageError);
// Workerの停止
worker?.terminate();
workerRef.current = null;
};
}, []);
worker.ts
pipelineのインスタンス生成と管理
pipelineは、機械学習モデルを簡単に利用するための関数です。この関数を使用してパイプラインをインスタンス化します。
インスタンスの生成には時間やメモリといったリソースを消費するため、複数回実行を避けるように設計しています。そのため、1つのインスタンスのみを生成し、使い回せるようにシングルトンパターンを採用しています。
// モデルのインスタンス管理用のSingletonクラス
class PipelineSingleton {
// タスクとモデルの設定
static task: PipelineType = "question-answering";
static model = "/onnx_model";
private static qaInstance: QuestionAnsweringPipeline | null = null;
static async getQuestionAnsweringInstance(
progressCallback?: (progress: number) => void
): Promise<QuestionAnsweringPipeline> {
if (!this.qaInstance) {
const modelInstance = await pipeline(this.task, this.model, {
progress_callback: (progress: { progress: number }) => {
if (progress && typeof progress.progress === "number") {
progressCallback?.(progress.progress);
}
},
});
this.qaInstance = modelInstance as QuestionAnsweringPipeline;
}
return this.qaInstance;
}
}
ここで注目していただきたいのは、getQuestionAnsweringInstanceの処理です。この関数では、使用するタスクとモデルの設定を行い、pipeline関数を実行してインスタンスを生成しています。
タスクとは、機械学習モデルが解決する問題や目的を指します。今回は質問応答のタスクを実行するため、"question-answering"を指定しています。
モデルは、使用する具体的な機械学習モデルを指します。通常、モデルはHugging Face Hubからダウンロードされ、ブラウザのキャッシュに保存されます。また、カスタムモデルやキャッシュ場所を指定することも可能です。今回はHugging Face Hubからダウンロードせず、キャッシュ場所を指定してモデルを利用しています。モデルの準備手順については、この後に詳しく説明します。
余談ですが、Hugging Face Hubからモデルを直接指定してダウンロードする方法は以下の通りです。
Hugging Face Hubからモデルを直接指定してダウンロードする方法
static model = 'Xenova/distilbert-base-cased-distilled-squad';
Hugging Face Hubで公開されている特定のモデルを識別するパスを取得し、それを設定すれば利用可能です。

推論の実行
次に、Web Worker側で行われるもう一つの重要な作業である、推論の実行処理について見ていきましょう。
// メインスレッドからのメッセージを監視
self.addEventListener("message", async (event: MessageEvent<WorkerRequest>) => {
const { question, context } = event.data;
if (!question || !context) {
const errorMessage: WorkerMessage = {
status: "error",
error: {
errorMessage: 'Both "question" and "context" must be provided.',
},
};
self.postMessage(errorMessage);
return;
}
try {
// QAパイプラインのインスタンスを取得
const qaPipeline = await PipelineSingleton.getQuestionAnsweringInstance();
// 質問応答タスクを実行
const output = await qaPipeline(question, context);
const answer = convertResult(output);
// 出力をメインスレッドに送信
const resultMessage: WorkerMessage = {
status: "complete",
data: answer,
};
self.postMessage(resultMessage);
} catch (error: unknown) {
const errorMessage: WorkerMessage = {
status: "error",
error: {
errorMessage: (error as Error).message || "An unknown error occurred.",
},
};
self.postMessage(errorMessage);
}
});
このコードは、Web Workerがメインスレッドから送信されたメッセージを受け取り、その内容を処理した結果をメインスレッドに返す仕組みを実装しています。具体的には、メインスレッドから送信される「コンテキスト」と「質問」をもとに、機械学習モデルのインスタンスを使用して推論を実行し、その結果を返す流れになっています。
補足
next.config.jsの設定
Next.jsで動作させる際、バンドル時にエラーが発生することがあります。これは、Node.js固有のモジュールをバンドルしようとするためです。この問題を解決するために、next.config.jsを使用して、Node.js固有のモジュールを無視する設定を行います。
/** @type {import('next').NextConfig} */
const nextConfig = {
// (Optional) Export as a static site
// See https://nextjs.org/docs/pages/building-your-application/deploying/static-exports#configuration
output: "export", // Feel free to modify/remove this option
// Override the default webpack configuration
webpack: (config, { isServer }) => {
if (!isServer) {
config.output.globalObject = "self";
}
// Ignore node-specific modules when bundling for the browser
// See https://webpack.js.org/configuration/resolve/#resolvealias
config.resolve.alias = {
...config.resolve.alias,
sharp$: false,
"onnxruntime-node$": false,
};
return config;
},
};
module.exports = nextConfig;
機械学習モデルの準備手順
これで機械学習モデルを実行する準備ができました。次はこのアプリで使うための機械学習モデルを用意します。手順は以下となります。
- 使用する機械学習モデルの選定
- モデルをONNXフォーマットに変換
- アプリケーションへの配置

1.使用する機械学習モデルの選定
ここでは、Hugging Face Hubで公開されているモデルを使用させていただきます。公開されているモデルは非常に多いため、目的に応じて絞り込むことで、効率的にモデルを選定できます。
今回筆者は、質問応答をするアプリを作るため、「Tasks」を「Question Answering」、「Languages」を「Japanese」で絞り込んで検索しました。

Hugging Face Models
2.モデルをONNXフォーマットに変換
Transformers.jsは、ONNXランタイムを使用してブラウザ上でモデルを実行します。ONNXは、TensorFlow、PyTorch、JAXなど異なるフレームワーク間でモデルを交換するための標準的なフォーマットです。ONNXランタイムを利用することで、このONNXフォーマットに対応したモデルを統一的に推論できるため、特定のフレームワークに依存しない柔軟な運用が可能になります。
前述の通り、Hugging Face Hubのモデルを使用します。ここには、さまざまなフレームワークで作成されたモデルが公開されています。そのため、ONNX形式でないモデルを使用する場合は、事前にONNX形式に変換する必要があります。
今回は、timpal0l/mdeberta-v3-base-squad2を使わせていただきます。
このモデルはPyTorchフレームワークで作成されているため、ONNX形式に変換して使用する必要があります。
変換には、Hugging FaceのOptimumを使用します。インストール方法などはこちらを参照してください。
インストールできたら、以下のコマンドで変換します。
optimum-cli export onnx --model timpal0l/mdeberta-v3-base-squad2 --task question-answering ./onnx_model/
コマンドの内容を簡単に説明すると、「timpal0l/mdeberta-v3-base-squad2」という「question-answering」のモデルをONNX形式に変換し、「./onnx_model/」ディレクトリに保存するように指定しています。
3.アプリケーションへの配置
前節で対象のモデルをONNX形式のモデルに変換できたので、次はアプリケーションがそのモデルを参照できるようにします。public/modelsに配置します。pipelineのインスタンス生成と管理で説明したように、モデルに/onnx_model/としているので以下のようにします。

今後の展開
これでQAアプリの説明は終わりです。以上の内容から、Hugging Face Hubで公開されているモデルを使って、推論を実行できると思います。
今回は、縛りプレイで、クライアントサイドでWASMを使っていますが、Transformers.jsではWebGPUでの実行も可能です。さらにNext.jsを使ってクライアントサイドで推論を実行していますが、もちろんサーバサイドで推論を実行するということもできます。
Transformers.jsには、さまざまなタスクがあります。質問応答のアプリを作るということで、「question-answering」のタスクを使用しましたが、タスクを変更することによってAI活用方法の幅をさらに広げることができます。
Transformers.jsがサポートしているタスクは以下となります。魅力的なタスクがたくさんありますので、是非試してみてください。
ソースコード
以下が今回紹介したサンプルアプリの全ソースコードとなります。
まとめ
フロントエンドエンジニアなのに、UI周りのコード、手を抜いてゴメンなさい…。
Discussion