Databricks上でLLMを動かす時のインスタンス選び
Databricks上で、OSSのLLMをちょっと試したいとなったら、ノートブックを開いて、インスタンスをアタッチして、transformers.AutoModelForCausalLMを使ってHuggugFaceからモデルをダウンロードして、推論する、という流れが一般常識化しているようですが、この時のインスタンス選びはどうされてますでしょうか? LLMになると基本的にはGPUインスタンスを使う方が現実的な性能が得られやすいです。が、それでもインスタンスサイズは最小化したい、というのが多く方のご要件だと思います。
本ブログでは、インスタンスサイズを極力小さくするためのコツをメモリー使用量の観点でtransformers.AutoModelForCausalLMの動作とともにご説明しようと思います。
環境
- Databricks Runtime: 14.1 ML (includes Apache Spark 3.5.0, GPU, Scala 2.12)
- インスタンスサイズ: g5.xlarge (メモリ: 16GB, GPU: A10g(24GB) × 1)
- モデル: elyza/ELYZA-japanese-Llama-2-7b
概要
非常にシンプルな以下のコードを使って、3つのケースで説明をいたします。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "elyza/ELYZA-japanese-Llama-2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
ノードサイズはA10g搭載の最も小さいg5.xlargeを使用します。スモールに始めましょう。
ケース①
インスタンス起動直後のシステムメモリの使用量は以下のとおりです。
root@1027-092442-8vebv3ck-10-0-43-117:~# free -h
total used free shared buff/cache available
Mem: 10Gi 5.0Gi 3.9Gi 0.0Ki 2.0Gi 5.9Gi
Swap: 9Gi 0B 9Gi
ではこの状態でサンプルコードを実行します。
すると、10分以上経過後に以下のエラーとなります。

エラー直前にシステムメモリの使用量を見てみると以下のようにスワップ領域も含めてフルフルなのがわかります。
root@1027-092442-8vebv3ck-10-0-43-117:~# free -h
total used free shared buff/cache available
Mem: 10Gi 10Gi 0.0Ki 0.0Ki 19Mi 19Mi
Swap: 9Gi 9.2Gi 768Mi
従って、(エラーメッセージには明記されておりませんでしたが)Out-of-Memory(OOM)エラーが発生していると予想できます。
ケース②
コードを少し修正します。
具体的にはAutoModelForCausalLM.from_pretrainedにtorch_dtype='auto'を追加しました。これはつまり、モデルを適切な演算精度でロードしてくださいと言う指示になります。
先ほどのコードはこのオプションが指定されていなかったため、デフォルトのFP32(単精度浮動小数点数)でモデルパラメーターがフォーマットされていたと思われます。一方、こちらを指定することによって、より適切な(この場合はより低い)演算精度が採用される可能性があります。昨今のLLMのほとんどはFP16やBFloat16といった16ビットベースでトレーニングされています。今回のモデルも恐らく16ビットでフォーマットされるのが自然だと考えられます。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "elyza/ELYZA-japanese-Llama-2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype='auto'
)
しかし、実行すると以下のエラーが発生しました。
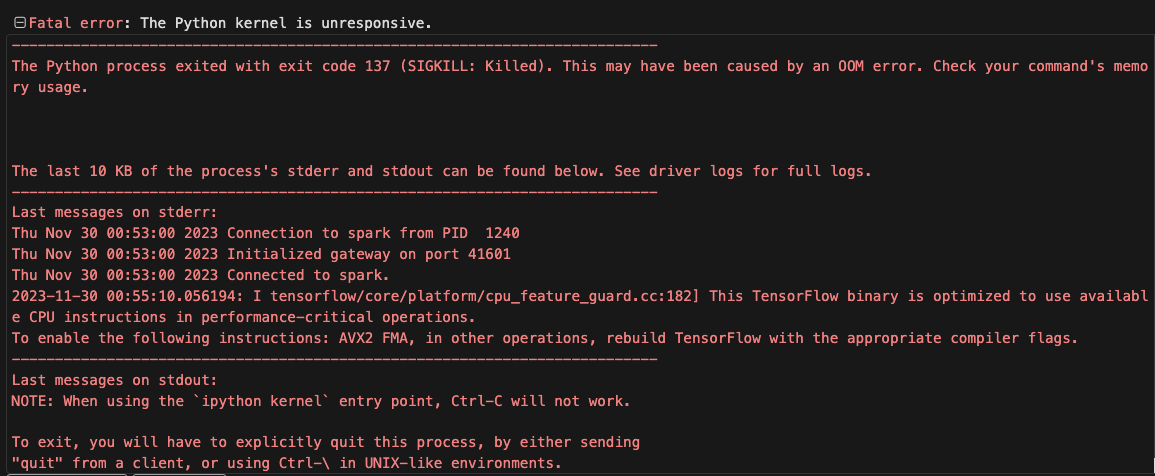
今度はメッセージの通り、OOMエラーが発生しているのが明確ですね。16ビットベースにしたと言うことは、32ビットよりも最大でモデルのデータサイズが半分になることが期待できますが、それでもシステムメモリーに乗り切らなかったと言うことでしょう。
では、インスタンスサイズをスケールアップ(この場合、g5.2xlarge, g5.4xlargeなどへアップ)しなければならないのでしょうか?
答えはノーです。
まだ試せることがあります。
ケース③
再度コードを少し修正します。
具体的にはAutoModelForCausalLM.from_pretrainedにdevice_map='auto'を追加しました。これにより、モデルが適切なデバイス(この場合だとGPU)に自動でロードされるようになります。なお、マルチGPU環境では各GPUに均等にモデルがロードされます。
そして、このオプションをつけるとlow_cpu_mem_usageというオプションも自動的にEnableになります。これはモデルをロードしている間、CPUメモリー(ピークメモリーを含む)でモデルサイズの1倍以上を使用しないように自動調整してくれる機能です。従って、システムメモリーの使用率を通常よりも抑えたうえで、アクセラレーターにデータをロードするということを実施してくれます。こちらを参照ください。
いずれにしても、コードを以下のように更新します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "elyza/ELYZA-japanese-Llama-2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype='auto',
device_map='auto'
)
実行してみると、今度は見事に成功しました。
ロード後のGPUメモリが13GBほど使用されているのがわかります。こうなれば、あとはいくらでも推論可能です。

仮にこのケースでもOOMエラーとなる場合は、インスタンスのスケールアップを検討しましょう。
また、GPUメモリーに搭載ができない場合は、さらにメモリを積んだGPU、または、マルチGPUのインスタンスを選ぶことを検討しましょう。
まとめ
最終的にGPUにロードするのであれば、GPUメモリに載るかという確認をするのは当然ですが、システムメモリーに載るかという確認も必要です。
ですが、torch_dtype='auto'やdevice_map='auto'を指定することで、システムメモリが少ない場合も有効活用できる可能性がありますので、まずは最小サイズのインスタンスから一度お試しください。
おまけ
モデルを保存した結果がこちら。
model_save_path = "/tmp"
tokenizer.save_pretrained(model_save_path)
model.save_pretrained(model_save_path)
- FP16
root@1031-051528-3mn4iqbi-10-0-9-42:/tmp/model_fp16# ls -lah
total 13G
drwxr-xr-x 2 root root 4.0K Nov 28 07:15 .
drwxrwxrwt 1 root root 4.0K Nov 28 07:17 ..
-rw-r--r-- 1 root root 633 Nov 28 07:14 config.json
-rw-r--r-- 1 root root 154 Nov 28 07:14 generation_config.json
-rw-r--r-- 1 root root 9.3G Nov 28 07:14 pytorch_model-00001-of-00002.bin
-rw-r--r-- 1 root root 3.3G Nov 28 07:15 pytorch_model-00002-of-00002.bin
-rw-r--r-- 1 root root 27K Nov 28 07:15 pytorch_model.bin.index.json
-rw-r--r-- 1 root root 437 Nov 28 07:14 special_tokens_map.json
-rw-r--r-- 1 root root 1.8M Nov 28 07:14 tokenizer.json
-rw-r--r-- 1 root root 489K Nov 28 07:14 tokenizer.model
-rw-r--r-- 1 root root 725 Nov 28 07:14 tokenizer_config.json
モデルサイズは合計13GBくらいありそうですね。これはGPUメモリーにロードされたサイズとほぼ一致しています。
- FP32
root@1031-051528-3mn4iqbi-10-0-9-42:/tmp/model# ls -lah
total 26G
drwxr-xr-x 2 root root 4.0K Nov 28 07:06 .
drwxrwxrwt 1 root root 4.0K Nov 28 07:25 ..
-rw-r--r-- 1 root root 633 Nov 28 07:03 config.json
-rw-r--r-- 1 root root 154 Nov 28 07:03 generation_config.json
-rw-r--r-- 1 root root 9.2G Nov 28 07:04 pytorch_model-00001-of-00003.bin
-rw-r--r-- 1 root root 9.3G Nov 28 07:05 pytorch_model-00002-of-00003.bin
-rw-r--r-- 1 root root 6.7G Nov 28 07:06 pytorch_model-00003-of-00003.bin
-rw-r--r-- 1 root root 27K Nov 28 07:06 pytorch_model.bin.index.json
-rw-r--r-- 1 root root 437 Nov 28 07:03 special_tokens_map.json
-rw-r--r-- 1 root root 1.8M Nov 28 07:03 tokenizer.json
-rw-r--r-- 1 root root 489K Nov 28 07:03 tokenizer.model
-rw-r--r-- 1 root root 725 Nov 28 07:03 tokenizer_config.json
モデルサイズは25GBほどになっています。
今後モデル選びやインスタンス選び(GPUのサイジングも含め)をする際のご参考にされてください。
おまけ②
モデルダウンロード時のログをよくみると、ダウンロードされたモデルサイズは合計13GBほどなので、元々16ビットベースでフォーマットされていると考えられます。こういった場合であっても、torch_dtype='auto'やtorch_dtype=torch.float16などを指定しないと、ローカルでFP32にカサ増しされて、ロードされるようですね。

Databricks無料トライアル
Discussion