Hyperoptでモデルをチューニングする(しない)方法
HyperoptをSparkとMLflowで最適に使用し、最適なモデルを構築する
Hyperoptは、Apache Sparkを使用してMLモデルをチューニングするための強力なツールです。最適なチューニングを定義し、実行(およびデバッグ)する方法を学ぶには、こちらをご覧ください!
モデルを構築したいのです。データへのアクセス、データのクリーニング、特徴の選択など、難しい問題は解決しました。xgboost、scikit-learn、Kerasなどなど。悪いニュースは、その数が非常に多く、それぞれに調整する必要があることです。どの程度の正則化が必要なのか?学習率は?そして「ガンマ」とは何なのか?
どのアルゴリズムが、およびそのアルゴリズムのどの設定(「ハイパーパラメータ」)が、データに対して最適なモデルを生み出すかを知る簡単な方法はありません。誠実なモデルフィッティングのプロセスは、多くのハイパーパラメータの組み合わせを試す必要があり、さらには多くのアルゴリズムを試すことになります。
ハイパーパラメータチューニングのための有名なオープンソースツールにHyperoptがあります。使い方は簡単ですが、Hyperoptを効率的に使うには注意が必要です。これからHyperoptを使い始める方にも、すでにHyperoptを使っていてスケーリングに問題があったり良い結果が得られなかったりする方にも、このブログはお勧めです。このブログでは、時間とお金を無駄にせずに最良のモデルを見つける方法として、よくある問題とその解決策を探ります。その方法は以下の通りです:
- Hyperopt探索空間を正しく指定する
- 一般的なエラーのデバッグ
- Apache Sparkクラスタ上での並列性を最適に利用する
- Hyperopt試験の最適化
- MLflowを使ってモデルを追跡する
Hyperoptとは?

Hyperoptは、複雑な入力空間に対して関数の値を最適化できるPythonライブラリです。機械学習の場合、これはハイパーパラメータの空間上でモデルの精度(損失)を最適化できることを意味します。ベイズ・オプティマイザであり、単にランダムに探索したり、グリッドを探索したりするのではなく、どの値の組み合わせがうまくいくかをインテリジェントに学習しながら、そこに探索を集中させます。
世の中に最適化パッケージは数多くありますが、Hyperoptにはいくつかの長所があります:
- オープンソース
- ベイズ・オプティマイザ - グリッド検索やランダム検索ではなく、ハイパーパラメータをスマートに検索します(ちなみにParzen Estimatorsのツリーを使用)。
- 並列ハイパーパラメータ検索のためのApache Sparkとの統合
- MLflowとの統合による検索結果の自動追跡
- Databricks MLランタイムに既に含まれています。
- 最大限の柔軟性:文字どおりあらゆるPythonモデルを、あらゆるハイパーパラメータで最適化できます
この最後の点は諸刃の剣です。Hyperoptはシンプルで柔軟ですが、タスクについて何の仮定もせず、探索の境界を正しく指定する負担をユーザーに負わせます。正しく行えば、Hyperoptはベストモデルを効率的に見つける強力な方法となります。しかし、探索の指定、効率的な実行、問題のデバッグ、MLflowを介した最適モデルの取得など、Hyperoptには知っておくべきベストプラクティスが数多くあります。
空間の指定:ハイパーパラメーターとは何か?
どのようなチューニング・フレームワークを使う場合でも、チューニングするハイパーパラメータを指定する必要があります。しかし、ハイパーパラメータとは何でしょうか?
線形回帰の係数やディープラーニングネットワークの重みのように、データから学習されるモデルのパラメータではないです。ハイパーパラメータは、最適なパラメータを選択するモデリングプロセスそのものへの入力です。これには、モデルをフィッティングする際の正則化の強さなどが含まれます。モデルに対するスカラーパラメータは、おそらくハイパーパラメータです。明確な1つの正しい値を持たないものは、何でも試す価値があります。
引数の中には_調整できない_ものもあります。例えば、xgboostは最小化する目的関数を求めます。分類の場合、それはしばしばreg:logisticです。回帰問題ではreg:squarederrorです。しかし、これらは1つの問題における選択肢ではありません。分類のためにreg:squarederrorを試すのは意味がありません。同様に、一般化線形モデルでは、多くの場合、解決される問題に正しく対応するリンク関数は1つであり、選択肢ではありません。もっと簡単な例として、verboseを調整する必要はどこにもありません!
いくつかの引数は_調整可能であり、主に速度に影響しますが、曖昧です。scikit-learnの実装におけるn_jobsを考えてみましょう。これはモデルの構築に使用される並列スレッドの数を制御します。最終的なモデルの品質には影響しません。ハイパーパラメータとして調整するものではありません。
同様に、コンバージェンス許容値のようなパラメータも、チューニングの対象にはならないでしょう。大きすぎるとモデルの精度が低下します_が、小さすぎると基本的に計算サイクルが増えるだけです。このような引数はデフォルトのままでよいのです。
同じ意味で、ディープラーニングモデルのエポック数は、おそらく調整すべきものではありません。トレーニングは、早期停止によって精度が向上しなくなった時点で停止すべきです。この考え方の詳細については、「6つの簡単なステップでディープラーニングをスケールさせる(させない)方法」を参照してください。
スペースの指定:どの範囲を選ぶか?
次に、それぞれのハイパーパラメータについて、どの範囲の値が適切でしょうか。明らかな場合もあります。例えば、ニューラルネットワークをトレーニングする際に、オプティマイザとしてAdamと SGDを選択する場合、可能な選択肢は明らかにこの2つだけです。
スカラー値の場合、それほど明確ではありません。Hyperoptは最小値と最大値を要求します。学習率のようなパラメータは正である必要があります。Elastic netのパラメータは比率なので、0から1の間でなければなりません。しかし、例えばサポートベクターマシンの「ガンマ」パラメータの妥当な最大値は何でしょうか?難しい最小値や最大値、デフォルト値を理解するには、実装のドキュメントを参照する必要があります。
迷った場合は、極端な境界を選択し、Hyperoptにうまく機能しない値を学習させてみます。例えば、正則化パラメータが通常1~10の場合、0~100の値を試してみることができます。この範囲にはデフォルト値も含めるべきです。最悪の場合、全く機能しない極端な値を試すことに時間を費やすかもしれませんが、学習し、悪い値で試行を無駄にすることをやめるはずです。これは、妥当な値をよりよく探索するために、最初の探索の後に範囲を狭めて探索を再実行することを意味するかもしれません。
ハイパーパラメータの中には、実行時間に大きな影響を与えるものがあります。例えば、ツリーベースのアルゴリズムで最大ツリー深度を大きくすると、モデルが大きくなり、学習コストが高くなります。さらに悪いことに、データがオーバーフィットするために、モデルの学習に時間がかかることもあります!Hyperoptは、試行の実行時間について学習しようとはしませんし、ハイパーパラメータの選択に反映させることもしません。いくつかのタスクがメモリ不足で失敗したり、動作が非常に遅い場合は、ハイパーパラメータを調べてみてください。ある設定が考慮するにはあまりにも高価であることが明らかになることもあります。
最後の微妙な点は、一様ハイパーパラメータ空間と対数一様ハイパーパラメータ空間の違いです。Hyperoptにはhp.uniformとhp.loguniformがあり、どちらも最小/最大範囲の実数値を生成します。hp.loguniformは、算術的な値(0.1、0.2、0.3)ではなく、幾何学的な値の系列(0.001、0.01、0.1)を選択する場合に適しています。どちらが適しているかは文脈に依存し、通常は大きな違いはありませんが、検討する価値はあります。
まとめると、Hyperoptを使った合理的なワークフローは以下のようになります:
- 最適化するのに妥当なハイパーパラメータを選択する
- 各ハイパーパラメータ(該当する場合はデフォルトを含む)の広い範囲を定義する。
- 少数の試験を実施する
- MLflowの平行座標プロットで結果を観察し、最も損失の少ないランを選択する。
- 最良ランのハイパーパラメータ値が範囲の一端に押しつけられている場合、その範囲をより高い/低い値の方に移動させる。
- 特定のハイパーパラメータ値によってフィッティングに時間がかかるかどうかを判断する(そしてその値を避ける)
- 試行回数を増やして再実行
- 最良の実行が与えられた探索範囲内で快適になり、過大な時間を要するものがなくなるまで繰り返す。
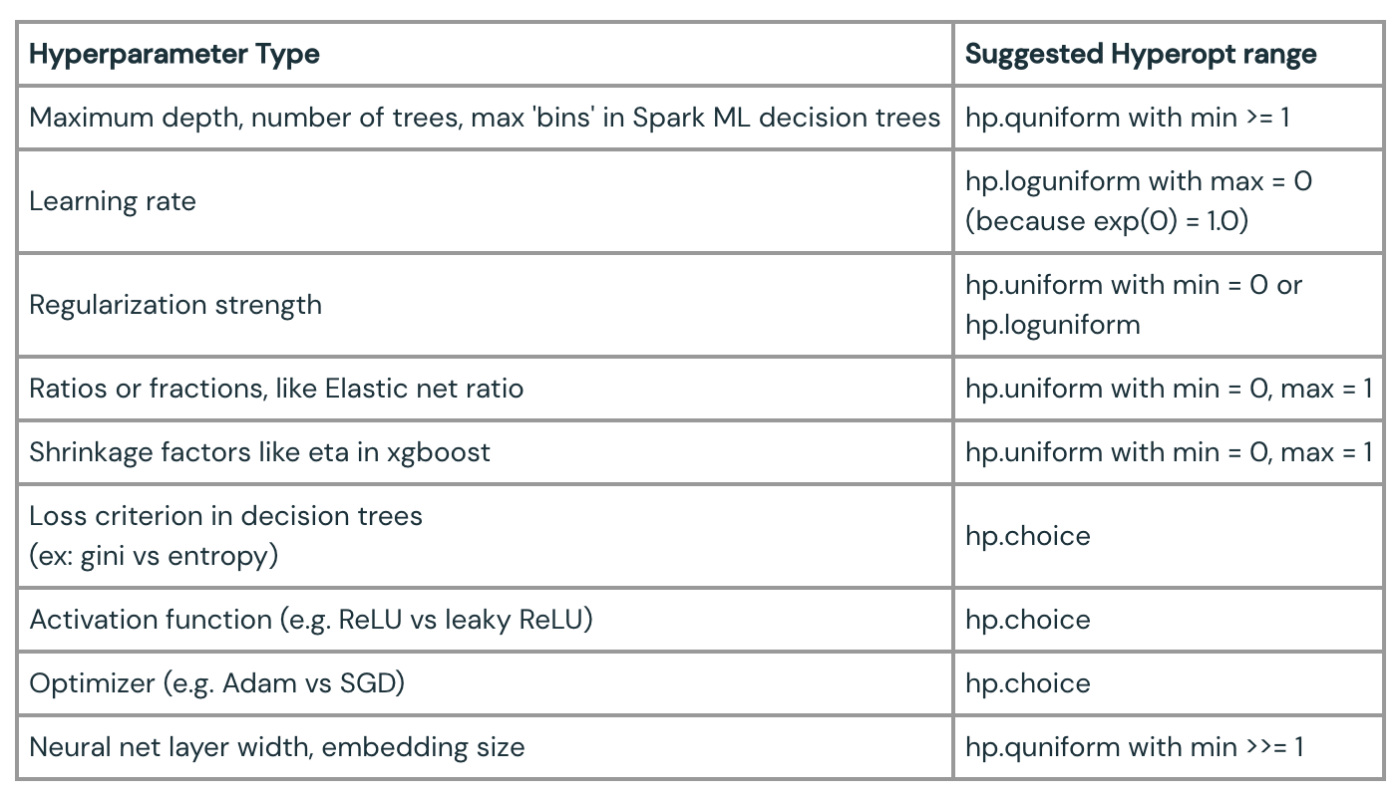
スカラーにはhp.quniformを、カテゴリーにはhp.choiceを使用する。
ツリー構築プロセスの最大深度を選択することを考える。これは3や10のような_整数_である必要があります。Hyperoptは範囲から整数を選択するためにhp.choiceとhp.randintを提供していますが、ユーザーは一般的に見た目が良い範囲型としてhp.choiceを選択します。
しかし、これらはこのようなハイパーパラメータにはまさに間違った選択です。これらは適切な範囲の整数を生成しますが、このような場合、Hyperoptは「10」という値が「5」よりも大きく、「1」よりもはるかに大きいことを、あたかもスカラー値であるかのように考慮しません。しかし、それが最大深度パラメータの振る舞いなのです。もし1と10が悪い選択で、3が良い選択なら、おそらく2と4を試すことを好むはずですが、hp.choiceやhp.randintではそれを学習しません。
代わりに、整数を生成するhp.quniform("量子化された一様")かhp.qloguniformを選ぶのが正しい選択です。hp.choiceは、例えば、カテゴリ化された選択肢(状況によっては整数になることもありますが、通常はなりません)の中から選ぶ場合に正しい選択です。
ここでは、いくつかの一般的なハイパーパラメータの種類と、それらを記述するために選択する可能性の高いHyperoptレンジの種類を示します:
最後の注意点:例えば "adam "と "sgd "のような2つの選択肢に対してhp.choiceを使う場合、Hyperoptが関数に送る値(そしてMLflowによって自動ログされる値)は "adam "のような文字列ではなく、0や1のような整数インデックスです。選択肢の実際の値を記録するには、与えられた選択肢のリストを参照する必要があります。例
optimizers = ["adam", "sgd"]
search_space = {
...
'optimizer': hp.choice("optimizer", optimizers)
}
def my_objective(params):
...
the_optimizer = optimizers[params['optimizer']]
mlflow.log_param('optimizer', the_optimizer)
...
"評価タスクがないので、タスクロスのargminを返せない"
Hyperoptでユーザーがよく遭遇するエラーのひとつがあります: 評価タスクがないので、タスクロスのargminを返せない。
これは、どの試行も成功しなかったことを意味します。これはほとんどの場合、目的関数にバグがあり、すべての実行がエラーになることを意味します。詳細はログのエラー出力を参照してください。Databricksでは、デバッグしやすいように、根本的なエラーが表示されます。
また、モデルフィッティングプロセスが欠損値/NaN値を処理する準備ができておらず、常にNaN損失を返している場合にも発生する可能性があります。
目的関数が損失を計算できないのは「普通」であることもあります。ハイパーパラメータの特定のコンフィギュレーションが、トレーニングデータに対してまったく機能しないこともある -- 時系列モデルで特定の外生変数を追加することを選択すると、フィットしないことがある。もしそれが予想されるのであれば、目的関数を失敗させても構いません。また、ハイパーパラメータの組み合わせがうまく機能しないことをHyperoptに学習させるために、このような場合に非常に大きなダミーの損失値を返すことも可能です。
SparkTrialsの並列性を最適に設定する
HyperoptはSparkクラスタ全体で試行を並列化できます。ハイパーパラメータの各セットに対するモデルの構築と評価は、各トライアルが他のトライアルから独立しているため、本質的に並列化可能です。Sparkを使用してトライアルを実行するには、Hyperoptの "Trials "の代わりに"SparkTrials"を使用するだけで十分です。これはDatabricksのようにSparkクラスタが利用可能な環境では素晴らしいアイデアです。
SparkTrialsは、いくつのトライアルを並列に実行するかを指定するparallelismパラメータを取ります。もちろん、これを低く設定しすぎるとリソースを浪費する可能性があります。16コアのクラスタで実行する場合、2つのトライアルを並列に実行するだけで、30コアがアイドル状態になります。
並列度を高く設定しすぎると、微妙な問題が発生します。32コアのクラスタでは、クラスタのリソースを最大限に利用するために、もちろんparallelism=32を選択するのが自然です。クラスタ並列度よりも高く設定すると、トライアルの各波で実行待ちのトライアルが発生するため、逆効果になります。
しかし、Hyperoptのチューニング・プロセスは反復的であるため、正確に32に設定することも理想的ではないかもしれません。Hyperoptは、完了した試行の結果を使用して、次善のハイパーパラメータのセットを計算し、試行します。試行回数の合計であるmax_evalsも32である場合を考えると、並列度が32の場合、32の試行が一度に起動し、互いの結果を知ることはありません。これは事実上ランダムサーチであると言えます。
並列度はおそらくmax_evalsよりも一桁小さいはずです。つまり、目標とする総試行回数がある場合、クラスタサイズを調整して、より小さい並列度に合わせるべきです。例えば、200トライアルを目標とする場合、20の並列度と約20コアのクラスタを考慮します。
この経験則にはまだ続きがあります。チューニングするハイパーパラメータの数が少ない場合、並列度を大きくするのも効果的ではありません。例えば、4つのハイパーパラメータを検索する場合、並列度は4よりあまり大きくすべきではありません。試行回数が多く、変化させるハイパーパラメータが少ないと、探索はより推測的でランダムになります。それは悪いことではないが、あまり役に立たないかもしれません。
並列度をハイパーパラメータ数の小さな倍数に設定し、それに応じてクラスタリソースを割り当てます。その後のmax_evalsの選択方法については後述します。
タスク並列性を最適に活用する
この計算にはもう少し続きがあります。機械学習ライブラリの中には、1台のマシンで複数のスレッドを利用できるものがあります。例えば、いくつかのscikit-learnの実装にはn_jobsパラメータがあり、フィッティング処理が使用できるスレッド数を設定できます。
1つのSparkタスクは1つのコアを使用すると仮定されていますが、タスクが複数のコアを使用することを妨げるものは何もありません。例えば、16コアが使用可能な場合、16個のシングルスレッドタスクを実行することも、4個ずつ使用する4個のタスクを実行することもできます。フィッティング・プロセスが例えば4コアを効率的に使用できるのであれば、後者の方が実際には有利でしょう。なぜなら、Hyperoptは反復的であり、より少ない結果をより速く返すことで、次の試行をスケジュールするために初期の結果から学習する能力が向上するからです。つまり、このシナリオでは、最初の4つのタスクがそれぞれ4コアを使用して素早く完了すれば、試行5~8は試行1~4の結果から学ぶことができます。
scikit-learnとxgboostの実装は、一般的に数コアの恩恵を受けることができますが、それ以上になると収穫が少なくなります。1つの解決策は、タスクが1コア以上使うことをSparkに伝えずに、単にn_jobs (または同等のもの)を1より大きく設定することです。エクゼキューターVMはオーバーコミットされるかもしれませんが、フルに利用されることは間違いありません。極端でなければ、これで十分です。
これは並列度の設定に関する考え方に影響を与えます。Hyperoptフィッティング・プロセスが並列度=8を合理的に使用できる場合、デフォルトでは8コアのクラスタを割り当てて実行することになります。しかし、個々のタスクがそれぞれ4コアを使用できるのであれば、4 * 8 = 32コアのクラスタを割り当てるのが有利でしょう。
理想的には、この例では各タスクが4コアを必要とすることをSparkに伝えることが可能です。これはspark.task.cpusを設定することで行います。こうすることで、Sparkが1台のマシンに多くのコアを必要とするタスクをスケジューリングするのを避けることができます。デメリットは、これはクラスタ全体の設定であるため、セッション内で実行されるすべてのSparkジョブが、どのタスクに対しても4コアを想定するようになることです。これは、チューニングジョブがセッション内で実行される唯一の作業である場合にのみ合理的です。この値を設定しないだけで、実際には十分にうまくいくかもしれません。
SparkベースのMLジョブの最適化
上記の例では、scikit-learnやxgboostのようなシングルノードライブラリを使用するモデリングジョブのチューニングを想定しています。Hyperoptは、Spark MLや xgboost4j-spark、KerasやPyTorchを使ったHorovodなど、並列処理のためにSparkを活用するモデリングジョブのチューニングにも同様に使用できます。
しかし、このような場合、モデリングジョブ自体はすでにSparkクラスタから並列性を得ています。Hyperoptでは、SparkTrialsではなくTrialsを使用すれば十分です。ジョブはシリアルに実行されます。したがって、Sparkベースのライブラリの実行をチューニングして効率を最大化することが重要であり、Hyperoptの並列性をチューニングしたり心配したりする必要はありません。
目的関数内の大きな直列化オブジェクトを避ける
SparkTrialsを使用する場合、Hyperoptは提供された目的関数をSparkクラスタ全体で並列実行します。つまり、関数は他のSpark関数と同様に、関数が参照するオブジェクトと共に魔法のようにシリアライズされます。
これは、その関数が大きなDLモデルや巨大なデータセットのような大きなオブジェクトを参照している場合によくありません。
model = # load large model
train, test = # load data
def my_objective():
... model.fit(train, ...) model.evaluate(test, ...)
Hyperoptは、関数が呼び出されるたびに、モデルとデータを繰り返しエクゼキュータに送信しなければならない。これはチューニングを劇的に遅らせる可能性がある。その代わりに、モデルやデータが巨大でなくても、これらをブロードキャストした方が良い:
model = # load large model
train, test = # load data
b_model = spark.broadcast(model) b_train = spark.broadcast(train) b_test = spark.broadcast(test)def my_objective():
... b_model.value.fit(b_train.value, ...) b_model.value.evaluate(b_test.value, ...)
ただし、ブロードキャストされたオブジェクトのサイズが2GBを超える場合は、この方法は機能しません。また、このパターンを動作させるためには、例えば、データをシリアライズ可能な形式に変換する(pandas DataFrameの代わりにNumPyの配列を使用する)必要があるかもしれません。
ブロードキャストが不可能な場合、モデルやデータを毎回ロードするオーバーヘッドを回避する方法はない。目的関数は、これらの成果物を分散ストレージから直接ロードしなければなりません。これはうまくいくし、少なくともデータは1つのドライバから各ワーカーに送られるわけではない。
早期停止を利用する
Hyperoptでモデルの損失を最適化することは、(例えば)ニューラルネットワークをトレーニングするのと同じように、反復プロセスである。モデルの損失など、ある指標を改善し続ける。しかし、ある時点で最適化はあまり進まなくなる。Hyperoptが、これまでの最良の損失よりも優れた損失を生み出すハイパーパラメータのセットを見つけるのに苦労している可能性があるのだ。チューニングの終盤では、最良の損失がまったく下がっていないことが観察されるかもしれません。
進行が止まった場合は、トライアルの実行を停止した方が有利である。Hyperoptはearly_stop_fnパラメータを提供し、max_evalsに達する前に試行を停止するタイミングを決定する関数を指定します。Hyperoptにはn_progress_loss関数があり、_n回の_試行で最良の損失が改善されなかった場合、反復を停止することができます。
max_evalsはどのように設定すればよいですか?
以下は、max_evalsの値の選び方に関する一般的なガイダンスです。

* hp.choiceに "on, off "という2つの選択肢と、"a, b, c, d, e "という5つの選択肢があれば、カテゴリカルな選択肢の幅は10となります。

この2つの数値を足し算することで、並列性などのために乗数をかける前に、実行する評価数を考えるときに使う基本数値を得ることができます。
例2つのhp.uniform、1つのhp.loguniform、2つのhp.quniformハイパーパラメータと、3つのhp.choiceパラメータがあります。max_evalsの範囲を計算するために、順序パラメーターを5 x 10-20 = (50, 100)とし、カテゴリーパラメーターを15 x (2 x 2 x 5) = 300として、350-450の範囲とします。並列性がない場合、スピード(350に近い)と最適な結果(450に近い)をトレードオフする方法に応じて、その範囲から数値を選択することになる。ご想像の通り、400という値はこの2つのバランスが取れており、ほとんどの状況で妥当な選択です。8人の並列ワーカーを使いたい場合(SparkTrialsを使用)、これらの数値に適切なモディファイアを掛けます。この場合、スピードは4倍、最適な結果は8倍となり、1400から3600の範囲となり、2500がスピードと最適な結果の妥当なバランスとなります。
最後の注意:「最適な結果」というとき、私たちが意味するのは最適な結果に対する確信である。最速の値と最適な値が同じような結果を出すことはあり得るし、可能性さえある。しかし、より多くの評価を指定し実行することで、ハイパーパラメータ空間についてHyperoptがよりよく学習するようになり、最適な結果の品質についてより高い信頼性を得ることができます。
目的関数のクロスバリデーションを避ける
Hyperoptが最適化する目的関数は、主に損失値を返す。Hyperoptが選択したハイパーパラメータ値が与えられると、この関数はそれらのハイパーパラメータで構築されたモデルの損失を計算します。この関数は、'loss'というキーの下に、損失値を含むdictを返します:
return {'status':STATUS_OK, 'loss': loss} を返す。
そのためには、モデルを訓練し、その損失を保持されたデータで評価するために、データを訓練セットと検証セットに分割する必要がある。訓練と検証の分割は通常のことであり、不可欠です。
機械学習では、モデルを適合させる際にk-fold交差検証を行うのが一般的である。1つのモデルを1つの訓練検証分割にフィットさせる代わりに、_k個の_モデルを_k個の_異なるデータ分割にフィットさせる。これにより、多くのモデルの損失推定値が平均化されるため、より良い損失推定値が得られます。
しかし、クロスバリデーションがハイパーパラメータチューニングタスクにおいて価値があるかどうかは検討する価値がある。クロス検証は各損失推定値の精度を向上させ、その推定値の確実性についての情報を提供するが、それには代償が伴う。つまり、各タスクの実行時間はおよそ_k_倍になる。この時間は、他の_k個の_ハイパーパラメータの組み合わせの探索に費やすこともできます。つまり、k倍クロスバリデーションを追加するよりも、max_evalsをk倍増やす方が、他のすべての条件が同じであれば、おそらく良いのです。
もしk-foldクロスバリデーションが実行されるなら、少なくともそれが提供する追加情報を利用することは可能である。_k個の_損失があれば、損失値の不確実性の尺度である損失の分散を推定することができる。Hyperoptは損失に対する確率分布を更新しているので、これは有用だ。そのためには、「loss_variance」で分散の推定値を返す。クロスバリデーションから返される損失は、真の母集団の損失の推定値に過ぎないので、ベッセル補正された推定値を返すことに注意してください:
losses = # k個のモデル損失のリスト
return {'status':STATUS_OK,'loss', np.mean(losses),'loss_variance': np.var(losses,ddof=1)}.
注:ある種の時系列予測モデルのような特定のモデル・タイプは、クロス・バリデーションなしで予測の分散を本質的に推定します。その場合は、上記のように返すと便利です。
正しい損失の選択
最適化プロセスは、最適化されるメトリックと同じくらい良いものでしかない。モデルは、目的関数から返される損失によって評価される。モデルが明らかな損失指標を提供することもあるが、それはビジネスに対するモデルの有用性を正確に表現していないかもしれません。
例えば、分類器はしばしばクロスエントロピー損失のような損失関数を最適化する。これはモデルの "不正確さ "を表すものだが、モデルがどのように間違っているかは考慮されていない。正しい答えが「偽」であるときに「真」を返すことは、この損失関数では逆と同じくらい悪い。しかし、モデルがほとんど偽陰性(正しい答えが「真」であるときに「偽」)を返さないことの方がはるかに重要かもしれない。リコールはクロスエントロピー損失よりもそれを捉えるので、おそらくリコールに対して最適化する方が良いでしょう。この場合、分類器の損失ではなく、再現率を返すのが妥当です。Hyperoptは返される損失値を_最小化する_のに対して、想起値は高い方が良いので、このような場合は-recallを返す必要があることに注意してください。
最適モデルの再トレーニング
Hyperoptは、最も損失の少ないモデルを生成するハイパーパラメータを選択し、それ以上のことは行いません。HyperoptはMLflowと統合されているため、Databricksワークスペースにコードを追加することなく、すべてのHyperoptトライアルの結果を自動的に記録することができます。その後、多数の試行結果をMLflow Tracking Server UIで比較し、検索結果を理解することができます。例えば、何百もの実行を平行座標プロットで比較し、どの組み合わせが最良の損失をもたらすかを理解することができます。
これは、例えば、何を最適化する価値があるのか、あるいはどの範囲の値が妥当なのかさえ明確でないモデル最適化の初期段階において有用です。
しかし、MLflowの統合は、各Hyperoptトライアルで適合したモデルを自動的にログに記録しない(実際にはできない)。これは悪いことではない。最良のモデルだけが役に立つかもしれないのに、すべてのモデルを保存するのに時間を費やすのは望ましくないかもしれません。
必要であれば、関数内から各モデルを手動でログに記録することも可能です。MLflow API を呼び出すだけで、自動ログにこの情報やその他の情報を追加することができます。例えば
def my_objective():
model = # モデルのあてはめ
...mlflow.sklearn.log_model(model, "model") ...
議論の余地はありますが、代わりにHyperoptによって決定された最適なハイパーパラメータを使用し、すべてのデータに対して1つの最終モデルを再フィットし、MLflowでログに記録することは合理的です。ハイパーパラメータのチューニングプロセスでは、トレーニングを訓練セットに限定する必要がありましたが、最終モデルを訓練セットだけにフィットさせる必要はもはやありません。最適な」ハイパーパラメータがあれば、すべてのデータに対してモデルをフィットさせた方が、わずかに良い_パラメータが_得られるかもしれません。欠点は、この最終モデルの汎化誤差を評価できないことであるが、Hyperoptによってよく推定されたと信じる理由はあります。モデルをチューニングし、再フィットしてログに記録する方法の概略を以下に示しますs:
all_data = # 全てのデータを読み込む
train, test = # all_data を train, test に分割
def fit_model(params, data):
model =# params でモデルをデータにフィット
return modeldef my_objective(params):
model = fit_model(params, train) # テストで評価し損失を返す
best_params = fmin(fn=my_objective, ...) final_model = fit_model(best_params, all_data)mlflow.sklearn.log_model(final_model, "model")
その他のベストプラクティス
さらなるヒントやベストプラクティスにご興味があれば、その他のリソースをご覧ください:
- DatabricksによるHyperoptベストプラクティス文書
- MLflowによるハイパーパラメータチューニングのベストプラクティス(講演) - SAIS 2019
- MLflowによるディープラーニングのための高度なハイパーパラメータ最適化(講演) - SAIS 2019
- Pythonで機械学習モデルを調整するためのHyperoptのスケーリング- blog - 2019-10-29
結論
このブログでは、Hyperoptを使用して最適な機械学習モデルを自動的に選択するためのベストプラクティスや、検索を正しく指定し、効率的に検索を実行する際の一般的な問題や課題について解説した。また、Sparkクラスタ上での分散実行のベストプラクティスや失敗のデバッグ、MLflowとの統合についても取り上げました。
これらのベストプラクティスを手にすれば、Hyperoptのシンプルさを活用して、効率的なモデル選択をあらゆる機械学習パイプラインに迅速に統合することができます。
スタート
Databricks上のHyperoptを使って(SparkとMLflowを使って)最適なモデルを構築する!
Discussion