Mosaic AI Model Serving で 多様な日本語LLMと埋め込みモデルをサービングするためのガイド (1/3)
はじめに
生成 AI の導入初期においては、OpenAI社のGPTシリーズなど外部プロバイダーが提供するモデルを採用するケースが多い一方、本番運用まで見据えると 自己ホスト型モデル の重要性も高まっています。
自己ホスト型モデルとは
- オープンソース(OSS)として公開されている大規模言語モデル(LLM)や埋め込みモデルを社内環境にデプロイしたもの
- 社内データや独自アーキテクチャを活用し、OSS モデルをチューニングまたはゼロから構築したプライベートモデル
これらのモデルは、セキュリティ・データ主権・運用コスト・カスタマイズ性の観点で大きな強みを持ち、企業固有の要件に柔軟に対応できます。
日本語特化モデルの開発も進んでおり、多様なモデルが存在する点も魅力ですが、反面、デプロイ作業での試行錯誤や手戻りが発生しやすいという課題があります。本ガイドでは、Databricks Mosaic AI Model Servingを活用して、日本語特化型の自己ホスト LLM および埋め込みモデルを効率的にデプロイする手順を解説します。
前提条件
本ガイドの内容は以下の前提に基づいています。
- 本ガイドの情報は2025年5月19日時点のものです。
- 扱う自己ホスト型モデル:Causal LM(因果言語モデル)と埋め込みモデル
- Causal LM:直前の文脈から次トークンを予測するモデル(例:LLM)
- 埋め込みモデル:非構造化データを高次元ベクトルに変換する言語モデル
- 実践的な内容が中心のため、関連サービスや技術の詳細は基本的に割愛します。
- Databricks Mosaic AI Model Serving を中心に解説します。
- 自己ホスト型モデルのサービングに焦点を当て、関連度の低い機能(基盤モデル API の Pay-per-token や外部モデルなど)は扱いません。
- 主に日本語に特化した自己ホスト型モデルを対象とします。
- Databricksが公式に提供する基盤モデルをそのままデプロイする方法については扱いません。
- 2ノード以上のモデル並列が必要な大きなモデル(例:DeepSeek-R1)は対象外です。
- サンプルコードはAzure Databricksで検証されました。
- AWS、GCP版とは提供インスタンスの種類や名称が異なる場合があります。
Databricks Mosaic AI Model Servingとは
Databricks Mosaic AI Model Serving(以降、Mosaic AI Model Serving)は、AIおよび機械学習(ML)モデルをリアルタイムおよびバッチ推論のために統一的にデプロイ、管理、クエリできるプラットフォームです。
主な特徴
- REST API形式でモデルを公開できるため、Webアプリケーションや各種クライアントに容易に統合できます。
- Databricksがホストする基盤モデルと外部プロバイダーのモデルを単一インターフェースで管理・利用できます。
- AI Gateway機能により、アクセス制御、監視、品質管理を一元化でき、エンタープライズレベルのガバナンスを実現します。
技術的詳細
- 完全サーバーレスの推論基盤であり、エンドポイントはトラフィックに応じて自動的にスケールします。
- バックエンドにはCPUまたはGPUが利用されます。
- Databricksが基盤モデルとして最適化を公式サポートしている一部のモデルに対しては、「Provisioned Throughput」モードが選択可能です。
- このモードでは、低レイテンシと高スループットが保証されます。
- それ以外のモデルは通常のCPU/GPUモードでサービングされます。
Mosaic AI Model Servingの詳細については、公式ドキュメントを参照してください。
モデルをサービングするまでの全体フロー
LLMや埋め込みモデルをMosaic AI Model Servingにデプロイするまでの大まかな工程は、以下の3ステップに整理できます。
STEP 1: モデルの選定
- 最終的なAIアプリケーションを想定し、HuggingFace Hubなどから候補となるモデルを2種類以上ピックアップします。
- 独自に学習したモデルを採用する場合も、用途と要件(日本語性能、コンテキスト長、計算コストなど)を基準に複数候補を用意しておきます。
STEP 2: サービングパターンの決定
- モデルの種類やサイズによって最終的なサービング形態が変わってきます。
- インフラとしてCPU/GPUが使われるのは共通ですが、その上で動くエンジンやモデルの最適化の程度にバリエーションがあります。
- 本ガイドではこれらを 「サービングパターン」 と呼びます。
- 後述の判定フローに従って、どのパターンでデプロイするかを "暫定的" に決定してください。
STEP 3: デプロイ作業
-
MLflowへのロギング
- モデルをアーティファクトとしてMLflowのExperimentへ記録(保存)します。
-
Unity Catalogへの登録
- 記録したモデルをUnity Catalogに登録し、バージョン管理対象とします。
- アクセス制御とメタデータ管理も統合されます。
-
Mosaic AI Model Servingへのデプロイ
- Unity Catalog上のモデルをエンドポイントとして公開し、REST APIで推論可能にします。
すべてのサービングパターンでこの3工程は共通ですが、パラメータやスクリプトが細部で異なります。理論どおりに進まないケースに備え、STEP 1で複数モデルを選定し、STEP 2でパターンを暫定決定するアプローチを推奨しています。
サービングパターン
Mosaic AI Model ServingでLLMや埋め込みモデルをサービングするときは、モデルによってサービングパターンが決まります。
LLMのサービングパターン
LLMのサービングは5つのパターンに分類できます。

-
パターン①:Provisioned Throughput + ChatCompletions
- 専用エンジンによる最適化で低レイテンシと高TPSを保証し、自動スケールとSLAが付与されます。
- 推奨構成です。
-
パターン②:Provisioned Throughput + Completions
- ベースモデルのフォーマットを厳密に維持したいときの代替手段です。
-
パターン③:GPU Serving + ChatCompletions
- HF Transformersそのままの挙動でモデルを推論します。
-
パターン④:GPU Serving + Completions
- 旧GPT-3系や研究用モデルなど、会話履歴を持たない形式に適します。
-
パターン⑤:カスタム
- vLLMなどの推論エンジンやTensor Parallelなどの並列手法を自前で組み込み、マルチGPUや特殊インターフェースを実装できます。
LLMのサービングパターン判定フロー
ご自身のモデルがどのパターンに該当するかは、以下のフローで判断できます。
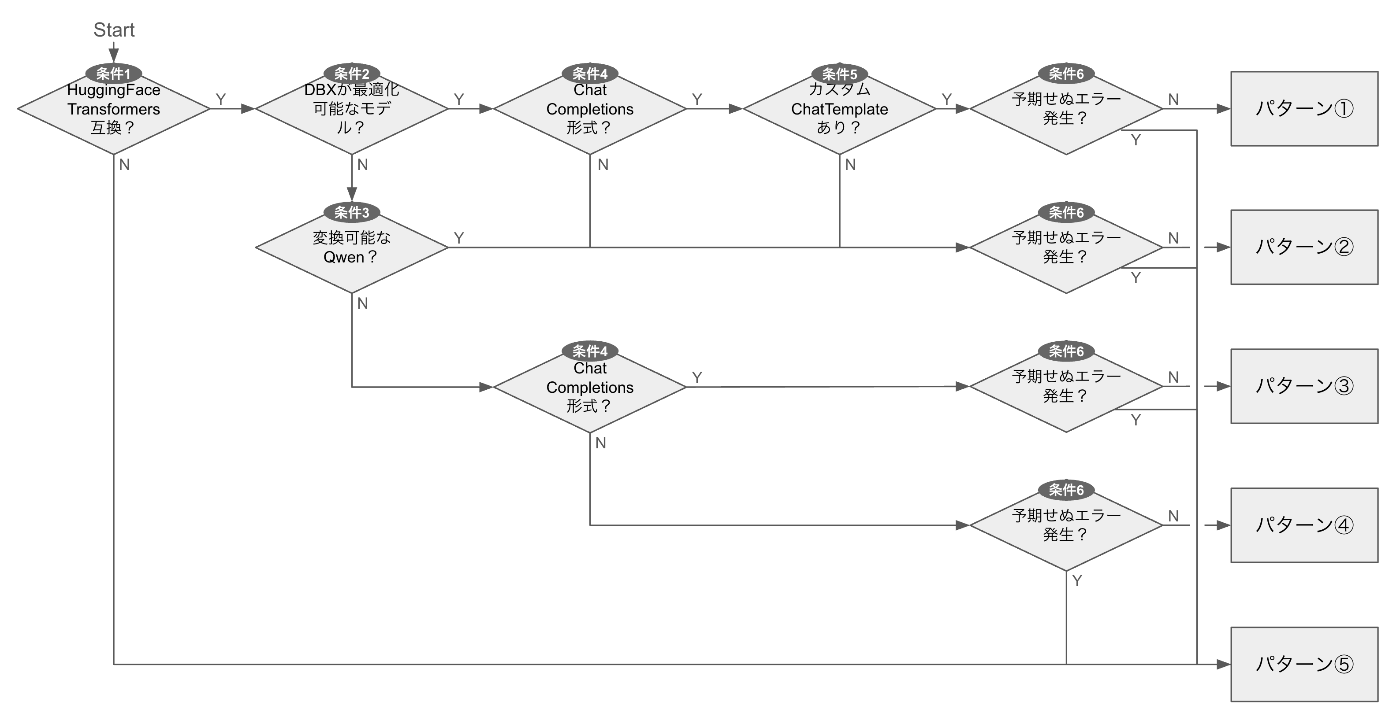
-
条件0:Causal LMか?
- 上図には含まれていませんが、モデルがCausal LM(因果言語モデル)かどうかを判定します。
-
条件1:Hugging Face Transformers互換か?
- モデルがHugging Face Transformersで動かせるかどうかを判定します。
-
条件2:Databricksが最適化対象としているか?
- モデルのベースアーキテクチャがDatabricksの基盤モデルリストに含まれているかどうかを判定します。
-
条件3:Qwen変換スクリプトでProvisioned Throughput対応にできるか?
- Qwen 2.5以降のモデルかどうかを判定します。
-
条件4:ChatCompletions形式で公開したいか?
- ChatCompletions形式(会話履歴をJSON形式で渡す)でサービングしたいかどうかを判定します。
-
条件5:カスタムchat_templateを持っているか?
- モデルのトークナイザーがカスタムのチャットテンプレートを持っているかどうかを判定します。
-
条件6:デプロイ工程で解決困難なエラーが発生したか?
- デプロイ作業中に致命的なエラーが発生したかどうかを判定します。
この判定フローに従うことで、モデル特性と要件に応じて最適なサービングパターンを選択できます。
LLM のサービングパターン判定例
具体的な日本語LLMをいくつか用いて、サービングパターンの判定フローを適用してみます。
判定例1: tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.3
- Causal LM? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → Yes(Llama-3.1-8B 系)
- ChatCompletions 形式? → Yes
- カスタム chat_template? → No
判定結果:パターン①(Provisioned Throughput + ChatCompletions)
判定例2: weblab-GENIAC/Tanuki-8B-dpo-v1.0
- Causal LM? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → Yes(Llama-3-8B 相当)
- ChatCompletions 形式? → Yes
- カスタム chat_template? → Yes(ベースと不一致)
判定結果:パターン②(Provisioned Throughput + Completions)
判定例3: AXCXEPT/EZO-Common-9B-gemma-2-it
- Causal LM? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → No(Gemma-2 系)
- ChatCompletions 形式? → Yes
判定結果:パターン③(GPU Serving + ChatCompletions)
判定例4: cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese
- Causal LM? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → No(Qwen 2 系)
- 変換可能な Qwen? → No(Qwen 2.0 系は未対応)
- ChatCompletions 形式? → Yes
判定結果:パターン③(GPU Serving + ChatCompletions)
判定例5: cyberagent/open-calm-7b
- Causal LM? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → No(GPT-NeoX 系)
- 変換可能な Qwen? → No
- ChatCompletions 形式? → No(Instruct チューニング前のベースモデル)
判定結果:パターン④(GPU Serving + Completions)
判定例6: Qwen/QwQ-32B-AWQ on vLLM
- Causal LM? → Yes
- HF Transformers 互換? → No(vLLM を推論エンジンとして利用)
判定結果:パターン⑤(GPU Serving + カスタム)
これらの例から分かるように、モデルの特性や要件に応じて異なるサービングパターンが選択されます。
埋め込みモデルのサービングパターン
埋め込みモデルをサービングするパターンは4つに分類できます。
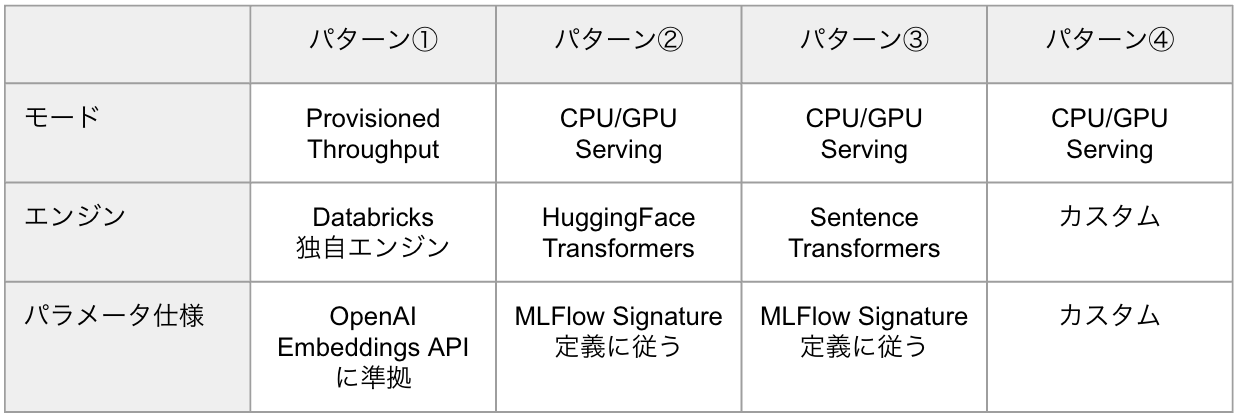
-
パターン①:Provisioned Throughput
- 専用エンジンによる最適化で低レイテンシと高TPSを保証し、自動スケールとSLAが付与されます。
- 推奨構成です。
-
パターン②:GPU Serving + HF Transformers
- HF Transformersそのままの挙動でモデルを推論します。
-
パターン③:GPU Serving + Sentence Transformers
- Sentence Transformersをエンジンとして使用します。
-
パターン④:カスタム
- vLLMなどの推論エンジンやTensor Parallelなどの並列手法を自前で組み込み、マルチGPUや特殊インターフェースを実装できます。
埋め込みモデルのサービングパターン判定フロー
ご自身のモデルがどのパターンに該当するかは、以下のフローで判断できます。
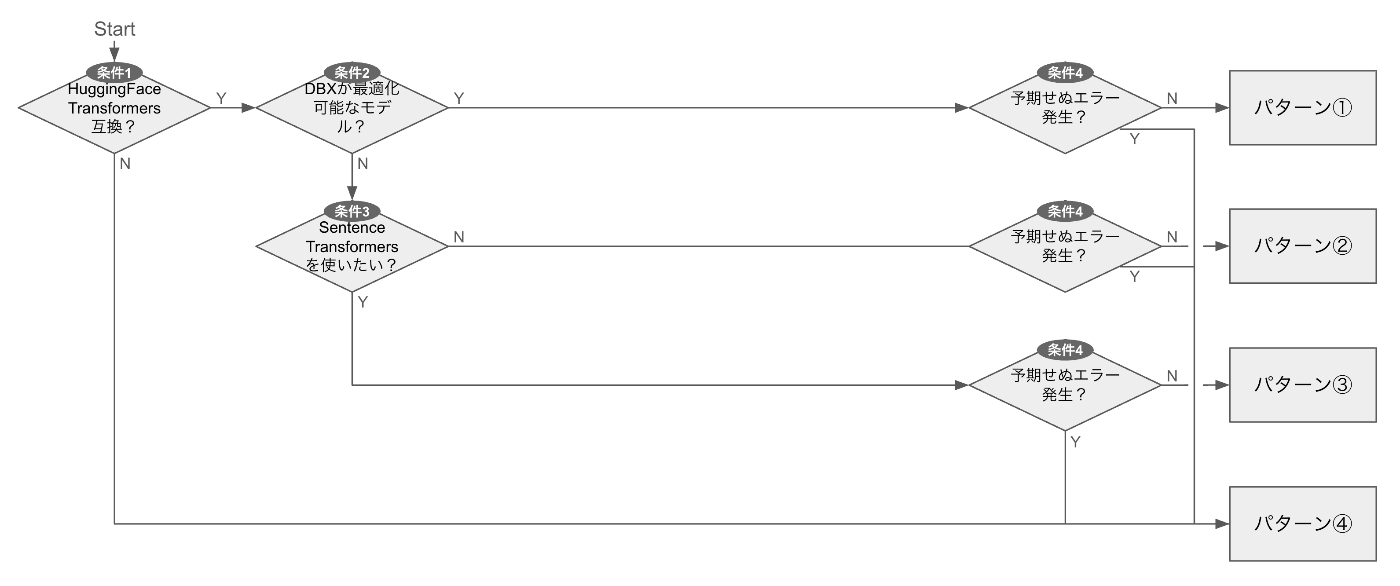
-
条件0:埋め込みモデルか?
- MTEBやJMTEBなどの埋め込みモデルリーダーボードに掲載されているか、またはモデルカードでsentence-embeddingやfeature-extractionの用途が明記されているかをチェックします。
-
条件1:HuggingFace Transformers互換か?
-
pipeline("feature-extraction", …)が例外なく動作するかどうかを判定します。
-
-
条件2:Databricksが最適化対象か?
- Databricksがサポートしている基盤モデル(現在はGTE v1.5とBGE v1.5のみ)かどうかを判定します。
-
条件3:Sentence Transformersで動かしたいか?
- Sentence Transformersを使用したいかどうかを判定します。
-
条件4:予期せぬエラーが発生?
- サービング作業中に解決不能なエラーが発生したかどうかを判定します。
埋め込みモデルのサービングパターン判定例
判定例1: Alibaba-NLP/gte-large-en-v1.5
- Embedding モデル? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → Yes (GTE v1.5)
判定結果:パターン①(Provisioned Throughput)
判定例2: cl-nagoya/ruri-large-v2
- Embedding モデル? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → No
- Sentence Transformers を使いたい? → No
判定結果:パターン②(GPU Serving + HF Transformers)
判定例3: intfloat/multilingual-e5-large
- Embedding モデル? → Yes
- HF Transformers 互換? → Yes
- Databricks 最適化対象? → No
- Sentence Transformers を使いたい? → Yes
判定結果:パターン③(GPU Serving + Sentence Transformers)
これらの判定例は、埋め込みモデルの特性に応じて適切なサービングパターンを選択する方法を示しています。
おわりに
Databricks Mosaic AI Model Serving を用いて自己ホスト型の LLM と埋め込みモデルをサービングする手順を体系的に整理しました。サービングしたいモデルをベースに、まず判定フローで 5 種類の LLM サービングパターン または 4 種類の埋め込みモデル サービングパターン を選び、パターンごとのデプロイ手順に進んでください。
具体的なパターン別デプロイ手順とコードは次の記事にて記載します。
Discussion