Databricks上でAIモデルの分散バッチ推論を実行する ~PyTorch編~




Databricks上でAIモデルの分散バッチ推論を実行する ~PyTorch編~
Databricks上のSparkクラスターを使ってAIモデルの分散バッチ推論をする手順になります。
基本的には以下の公式ノートブックの内容をなぞる様な形ですが、もう少し分かりやすくするため補足情報などを含めて解説しようと思います。
分散バッチ推論とは
Sparkのようなマルチノード環境にて、各ノードを使用してモデルのバッチ推論を並列に実行することです。推論対象のデータを分散させるデータ並列アプローチと、1つのモデルを分散させるモデル並列アプローチ(LLMなんかがこちらですね)があると思いますが、本記事では前者のデータ並列を取り上げます。
環境
本ブログではAzure Databricksを用いていますが、AWS版、GCP版のいずれでも再現可能かと思います。
-
Databricks Runtime: 13.3 LTS ML (includes Apache Spark 3.4.1, Scala 2.12, PyTorch 1.13.1 pre-installed)
- 今回はDatabricks Runtimenにプリインストールされているライブラリ以外は使用しません。
-
ノードタイプ: Azure Standard D16s_V5(ドライバー1台、ワーカー4台)
- CPUインスタンスを使います。
モデルおよびデータセット
今回の検証に用いるモデルとデータセットは以下の通りです。
- モデル:Torchvision ResNet50
- データセット:TensorFlowチームによるflowers dataset
- Databricks Datasetsの
dbfs:/databricks-datasets/flower_photosの下に格納されています。
- Databricks Datasetsの
検証に使用したソースコード
フルバージョンはこちらをご参照ください。
シングルノード上での推論
ベースラインとして、シングルノード上(ノードタイプは"環境"に記載のものと同様)で推論処理を実行しました。
なんの変哲もない、シンプルな推論処理です。
- Databricks-datasetからのデータのロード
dataset_dir = "/dbfs/databricks-datasets/flower_photos/"
output_file_path = "/tmp/predictions"
files = [os.path.join(dp, f) for dp, dn, filenames in os.walk(dataset_dir) for f in filenames if os.path.splitext(f)[1] == '.jpg']
print(f'画像ファイルの総数は {len(files)} 枚です。')
ちなみに画像枚数は合計3,670枚です。
- 推論実行
以下のコードで推論を実行していきます。バッチサイズは「1」としています。
def get_model_for_eval():
"""Gets the broadcasted model."""
model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
model.eval()
return model
transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
predictions = []
for image_path in files:
image = default_loader(image_path)
image = transform(image)
batch = image.unsqueeze(0).to(device)
model = get_model_for_eval()
model.to(device)
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.detach().cpu().argmax().item()
score = prediction[class_id].item()
predictions.append((class_id, score))
print(list(zip(files, predictions)))
このセルの実行が終了するまでの総処理時間は私の環境で 23分59秒 でした。データのロード、前処理/後処理が含まれているので、厳密な推論処理だけの性能ではないですが、ご容赦ください。
いずれにしても、こちらが今回のベースラインとなります。
続いて、マルチノード環境にスケールしていきましょう。
ワーカーノード4台を使用して分散モデル推論
ドライバー1台、ワーカー4台の環境を用意しました(ノードタイプは上記"環境"を参照)。
シングルノードでは、(当然ですが)1ノードが、全3,670枚の画像をシーケンシャルに(バッチサイズ=1なので)推論しました。マルチノード化して、ワーカーノード4台を使うので、この処理が4つに分散されることが期待できます。
早速コードを書いていきましょう。
- 分散処理のために、画像パスのDataFrameを作成
全画像の画像パスのリストを、SparkのDataFrame化します。これで、画像データを分散処理のフレームに乗っけることができます。
なお、再パーティショニングの際のパーティション数はワーカーノード数と同じ数、または、最小限の倍数値にすべきとのことなので、このサンプルではワーカー数と同じ「4」に設定しています。
files_df = spark.createDataFrame(
map(lambda path: (path,), files), ["path"]
).repartition(4)
念のため確認。画像パスのDataFrameが4つのパーティションに等分されているのが確認できます。
from pyspark.sql.functions import spark_partition_id
display(files_df.withColumn('partition', spark_partition_id()).groupBy('partition').count().orderBy('partition'))
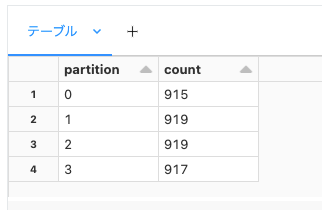
ちなみに、再パーティショニングの各パーティションの画像パスの数です。4等分されているのがお分かりかと思います。各パーティションがワーカーノードのいずれかにアサインされて、それぞれのワーカーノードが約900枚の画像を推論処理します。
- 推論実行
いよいよ推論です。結果として、以下の出力のように、推論結果の列を追加したDataFrameが作成されることを目指します。
- 入力
| 画像パス |
|---|
| /path/to/image001.jpg |
| /path/to/image002.jpg |
| /path/to/image003.jpg |
| /path/to/image004.jpg |
| ・・・ |
↓
- 出力
| 画像パス | 推論結果 (クラスID, Probability) |
|---|---|
| /path/to/image001.jpg | 25, 0.89234 |
| /path/to/image002.jpg | 152, 0.93564 |
| /path/to/image003.jpg | 301, 0.75788 |
| /path/to/image004.jpg | 7, 0.91827 |
| ・・・ | ・・・ |
したがって、以下のコードのように、お馴染みのwithColumnを使用して、推論結果列に相当する「prediction」列を追加します。この際に推論を実行するための関数として「predict」というPython UDF(ユーザー定義関数)を作る必要があります。
predictions_df = files_df.withColumn('prediction', predict(col('path')))
display(predictions_df)
では、UDFを作っていきましょう。
ただ、その前に一点。
モデルの重みパラメーターは事前にドライバーノードからワーカーノードへブロードキャストして、ワーカーノード上にキャッシュさせておくのが公式サイトにも記載されているベストプラクティスのようです。なのでそちらを行います。
# ドライバーノードにResNet50を一旦ロードし、その状態をブロードキャストする。
model_state = models.resnet50(weights=models.ResNet50_Weights.DEFAULT).state_dict()
bc_model_state = sc.broadcast(model_state)
# ワーカーノード上でにモデルをロードする際は、ブロードキャストされた重みをロードする。
def get_model_for_eval():
"""Gets the broadcasted model."""
model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
model.load_state_dict(bc_model_state.value)
model.eval()
return model
ここから推論用のUDFです。
predict関数の引数に、画像パスのが一つ入ってくるので、その度にモデルをロードして、当該画像をロードして推論を実装します。
UDFの特徴として、1レコード分のデータのみしか一度に扱えないためやむを得ないのですが、効率性には欠ける実装です。
from pyspark.sql.functions import udf
@udf(returnType=ArrayType(FloatType()))
def predict(image_path : str):
transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
image = default_loader(image_path)
image = transform(image)
batch = image.unsqueeze(0).to(device)
model = get_model_for_eval()
model.to(device)
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.detach().cpu().argmax().item()
score = prediction[class_id].item()
return [float(class_id), score]
いずれにしても、実際に推論を実行してみましょう。
# 再掲
predictions_df = files_df.withColumn('prediction', predict(col('path')))
display(predictions_df)
結果、以下のようなDataFrameが出来上がりました。

総処理時間は私の環境で 16分30秒 でした。display()に要している時間も含めているので、シングルノードとApple-to-Appleな比較ではありませんが、こちらもご容赦ください。
ただ、それなりに性能が向上していますが、ノード数と比例するようなスケール効率実現できていません。つまり、まだまだ向上の余地があります。
とまあ、実はこの実装はフリです。
というのも、本来Databricks上で分散バッチ推論を行う際は、Python UDFではなく、Pandas UDFを用いることが推奨されています。理由は後述するとして、少なくともPython UDFではあまり性能が出ない点は理解いただけたと思います。
というわけで、続いてPandas UDFに書き直します。
ワーカーノード4台を使用して分散モデル推論 + Pandas UDFを使用
さあ、ようやく本題です。(というか、このくらい前段を説明しないと、Pandas UDFの良さが分かりづらかったので。。。)
前述の通りですが、Databricksでは分散バッチ推論にはPython UDFではなく、Pandas UDF(別名:Vectorized UDF)を使うことが推奨されています。以下参照。
Pandas UDFとは
Pandas UDFは、Apache SparkのPySparkモジュールで使用される特殊なユーザー定義関数です。これは、PythonのPandasライブラリを使用してデータを効率的に処理するための機能を提供します。Pandas UDFは、Apache Arrowを利用してPythonとJVM間のデータ転送を高速化し、Pandasのデータフレームを使用してデータを操作することができます。
以下に、Python UDFとの違いを簡単にまとめます。
Python UDF vs Pandas UDF
1. データのバッチ処理
-
Python UDF:
- 一度に1レコードずつデータを処理
-
Pandas UDF:
- 一度に複数の行を処理可能(バッチとして処理可能)
上述した画像パスのDataFrameを例にとると、Python UDFへの入力は、1レコード単位です。
| 画像パス |
|---|
| /path/to/image001.jpg |
一方、Pandas UDFへの入力は、複数レコード単位です。
(なお、入力するレコード数の最大値はspark.sql.execution.arrow.maxRecordsPerBatchで設定可能)
| 画像パス |
|---|
| /path/to/image001.jpg |
| /path/to/image002.jpg |
| /path/to/image003.jpg |
したがって、Python UDFでは、どうしてもバッチサイズ=1で実行さざるを得ませんでしたが、Pandas UDFではバッチサイズをあげることが可能です。ただ、今回用いたCPUインスタンスでは、実はバッチサイズの違いによる性能向上は確認できなかったのですが、GPUインスタンスであれば性能向上は期待できるかもしれません。
なお、こちらも今回はあまり恩恵を受けなかったと思いますが、列方向のでまとまったデータを取り扱うので、CPU/GPUのSIMDを有効利用してパフォーマンス向上することも期待できます。
2. Apache Arrowを使用した高速なデータ転送
-
Python UDF:
- JVMとPythonプロセス間でのデータ転送にはシリアライズとデシリアライズが必要。
- オーバーヘッドが大きい。
-
Pandas UDF:
- Apache Arrowを使用してJVMとPythonプロセス間でデータ転送を効率化。
- シリアライズとデシリアライズのオーバーヘッド削減。
もう一つがこちら。Spark内での、JVMとPythonのコミュニケーション時のデータフォーマットとして、Pandas UDFはApache Arrowを採用しています。これにより、従来のオーバーヘッドが大きくなっていたJVMとPython間のデータのシリアライズとデシリアライズが非常に高速化できています。Apache Arrowがなぜ速いかはこちらのブログがブログが参考になります。
Pandas UDFに関しても、詳細はぜひ以下のブログをご覧ください。
個人的には現時点で最も分かりやすくPandas UDFの優位点を記載してくれていると思います。
さて、コードにいきましょう。
- Apache Arrowの使用をOnにする
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
- Pandas UDFに一度に渡すレコード数の最大値(バッチあたりの最大レコード数)を指定
今回は512を設定しています。1024でも良いかと思います。なお、最大レコード数を大きくすると、レコードがメモリに収まる場合に限り、UDFを呼び出すためのI/Oオーバーヘッドを減らすことができます。
spark.conf.set("spark.sql.execution.arrow.maxRecordsPerBatch", "512")
- カスタム PyTorch データセットクラスを作成
以下のドキュメントの通りですが、パフォーマンスチューニングのヒントとして、PyTorchであれば、データロード用にtorch.utils.data.DataLoaderの使用が推奨されているので、そのお作法に則ります。
- https://docs.databricks.com/en/machine-learning/model-inference/dl-model-inference.html
- https://docs.databricks.com/en/machine-learning/model-inference/model-inference-performance.html
class ImageDataset(Dataset):
def __init__(self, paths, transform=None):
self.paths = paths
self.transform = transform
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
image = default_loader(self.paths[index])
if self.transform is not None:
image = self.transform(image)
return image
- モデル推論のためのPandas UDFを定義
前述した通り、今回のサンプル画像データは全部で3670枚で、ワーカーノードの数と同じ4つのパーティションに分割しているので、各ワーカーノードが910〜920枚ほどの画像を処理します。その中から512枚の画像(正確には画像パス)を取り出してきて、Pandas UDFにpandas.Seriesデータとして入力します。Pandas UDF内では、その512個の画像パスからバッチサイズごとに画像パスを取り出し、当該画像ファイルをロードしてTensor化して、それをモデルで推論することを繰り返します。すべての画像パスの推論が終了したら、推論結果から欲しい情報を取り出した上で、それをPandas.Seriesにパックして、返します。
つまり、各ワーカーノードにおいて、Pandas UDFが呼び出される回数は今回の場合、2回です。したがって、UDFの前半のモデルのロード処理などにかかる時間を極小化できます。
(ちなみに、spark.sql.execution.arrow.maxRecordsPerBatchを1024などに設定すればUDFの呼び出し回数は一回で済みます。)
@pandas_udf(ArrayType(FloatType()))
def predict_batch_udf(paths: pd.Series) -> pd.Series:
transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
images = ImageDataset(paths, transform=transform)
loader = torch.utils.data.DataLoader(images, batch_size=8, num_workers=8)
model = get_model_for_eval()
model.to(device)
all_predictions = []
with torch.no_grad():
for batch in loader:
predictions = model(batch.to(device)).softmax(dim=1).detach().cpu().numpy()
class_id = predictions.argmax(axis=1)
score = predictions[np.arange(predictions.shape[0]), class_id]
for result in np.stack((class_id, score), axis=1):
all_predictions.append(result)
return pd.Series(all_predictions)
- 推論実行
では、withColum句でUDFを実行しましょう。
predictions_df = files_df.withColumn('prediction', predict_batch_udf(col('path')))
display(predictions_df)
こちらが結果です。
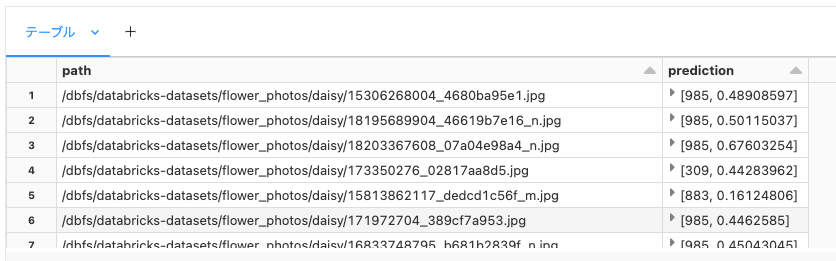
総処理時間は私の環境で 3分11秒 でした。
最初のシングルノードに比べると約7.7倍ほど性能が向上しているのが分かります。ノード数の増加、および、Pandas UDFにより効率化が効いているのだと思います。
なお、この上記コードではモデル推論時のバッチサイズを、ワーカーノードの物理コア数と同じ8としていますが、試しにバッチサイズを1で実行してもほぼ同じ結果でした。GPU搭載ノードだとどうでるでしょうか。今後試し次第、記事にしようと思います。
結果のまとめ
以下に結果をまとめます。
| シングルノード | ワーカー4台 | ワーカー4台 + Pandas UDF |
|---|---|---|
| 23分59秒 | 16分30秒 | 3分11秒 |
今回はPyTorchで試しましたが、 TensorFlowでも同様に実装可能ですし、TensorRTやOpenVINOなどの推論エンジンを用いても同様の方針で実装可能と思われます。
TensorFlowとTensorRTについては、公式ノートブックがありますね。
というわけで、公式ノートブックがまだ存在しないOpenVINOを今度は試そうと思います。
BFN!
参考
Deep learning model inference workflow
Deep learning model inference performance tuning guide
An Introduction to Pandas UDFs in PySpark
Spark3.0における新機能: Pandas UDFとPython型ヒント
Databricks無料トライアル
Discussion