NumpyとPandasの違い
はじめに
最近、機械学習に関して勉強し始めたのですが、頻繁に使われるライブラリであるNumpyとPandasの違いがあやふやだったのでまとめてみました!
結論
Numpyはデータの計算で主に使われるライブラリで一方、Pandasはデータの加工に主に使われるライプラリになっています。
Numpyとは
Numpyは、主にPythonで数値計算を高速に行うためのライブラリです。
ちなみに、なぜ、数値計算が早いかというのは、NumPyのライブラリコードは静的言語のC言語で実装されているためです。
では、具体的にどのような場面で活躍しているのでしょうか?
一例として、機械学習でよく使われるライブラリである、scikit-learnで活躍しています。このライブラリでは、内部でNumPyによる多次元配列(multidimensional array)のndarray型という型が動いています。
scikit-learnにおけるNumpy
実際にscikit-learnを用いたときに、どのような形でndarray型が適用されているでしょうか?
以下のコードの内容としては、分析の前処理を行なっています。
- scikit-learnのパッケージ内の、load_bostonというclassをインスタンス化することでデータセットを読み込む。
- 説明変数と目的変数に分割する。
- 訓練用データセットとテスト用データセットに分割する。
# データセットの読み込み
from sklearn.datasets import load_boston
dataset = load_boston()
# 説明変数の読み込み
boston_data = dataset.data
# 目的変数の読み込み
boston_target = dataset.target
# データセットを分割する関数の読み込み
from sklearn.model_selection import train_test_split
# 訓練用データセットとテスト用データセットへの分割
boston_data_train, boston_data_test, boston_target_train, boston_target_test = train_test_split(boston_data, boston_target, test_size=0.3, random_state=0)
# typeの確認
type(boston_data_train)
# 実行結果:numpy.ndarray
このコードから分かるように、scikit-learnにおいて、データ分析に用いられる訓練データやテストデータに適用されている型はndarray型であることがわかりました。
ブロードキャスト
Numpyの優れた機能の一つとしてブロードキャストというものが挙げられます。
ブロードキャストとは、本来行列において計算できない、3x4行列と4次元配列のような計算ををよしなに変換し計算できるようにしてくれる機能です。では、実際にやってみましょう。
# 行列の定義
a = np.array([
[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]
])
b = np.array([1, 2, 3, 4])
# 計算
c = a * b
# この時のbはブロードキャストにより以下のように3x4配列に変換されています。
# b = np.array([
# [1, 2, 3, 4],
# [1, 2, 3, 4],
# [1, 2, 3, 4]])
c
# 実行結果:
# array([[ 0, 2, 6, 12],
# [ 4, 10, 18, 28],
# [ 8, 18, 30, 44]])
これから分かる通り、ブロードキャストは、次元が1次元のものを複製し、大きい方の次元に合わせることで、計算を可能にするものとわかりました。
Pandasとは
Pandasは、主にデータ操作によく用いられるライブラリです。
csvやExcelなどの一般的なデータ形式で保存されたデータの読み込みであったり、条件を指定しての一部データの抽出など、データ分析においてデータを整理するのに便利なライブラリです。
データの読み込み(Excelの場合)
book.xlsxという以下のような表のファイルを読み込む。
 book.xlsx
book.xlsx
import pandas as pd
excel_df = pd.read_excel("book.xlsx")
実行結果:このように、デフォルトで一番上のcolumnがheaderとして、扱われます。
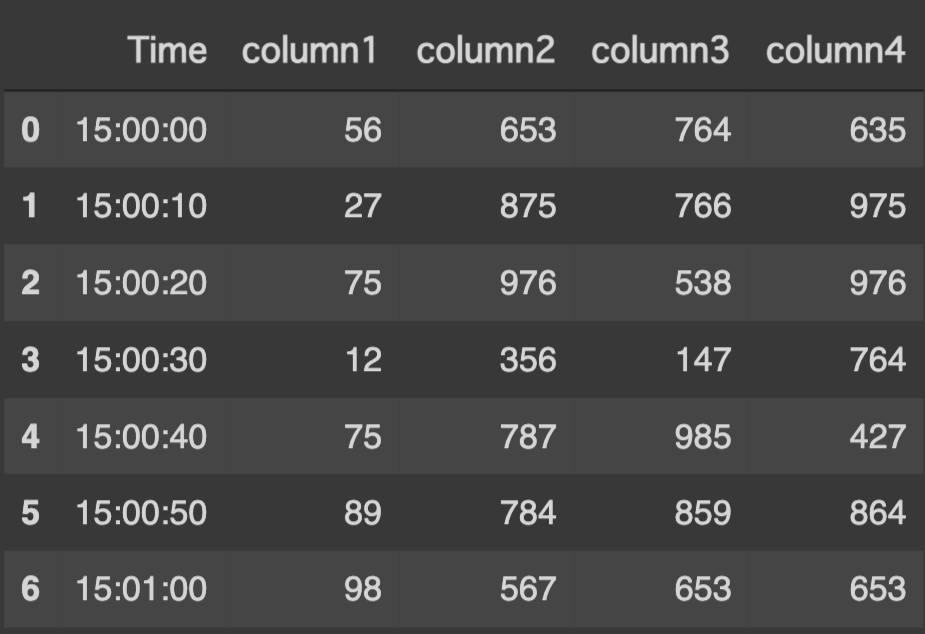 excel_df
excel_df
一部データの抽出
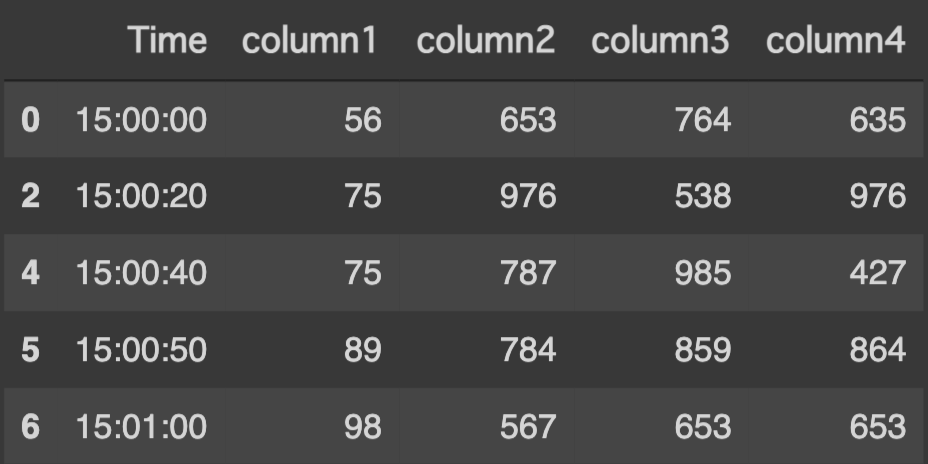
先程のコードの続きで、以下のようにSQLライクにデータの抽出ができます。
# column1のうち50以上の値を抽出
excel_df[excel_df["column1"] > 50]
また、公式のdocumentでもSQLとPandasの比較をしているので、ぜひ参考にしてみてください。
NumpyとPandasの違い
表にまとめると以下のようになります。
| データ加工のしやすさ | 数値計算 | |
|---|---|---|
| Numpy | headerが設定されていない配列のため 加工はしづらい |
c言語で実装されており 速い |
| Pandas | SQLライクなデータ加工で 加工がしやすい |
Numpyと比較して遅い |
実際のデータ分析での使い分け
Numpy、Pandasそれぞれの特徴から、以下のようなイメージで使われることが多いです。
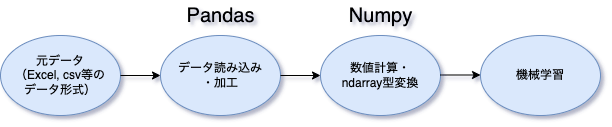
このように、元データの読み込みとデータ分析の前処理の大部分をPandasのDataframe型で行います。その後に、ndarray型に変換して、実際のデータ分析を行うというイメージです。なので、実際に触るのが多い型は、PandasのDataframe型が多いと思います。このことから、Pandasのデータ加工に慣れておいたほうがいいのかなと思っています。
まとめ
いかがだったでしょうか?
正直、NumpyとPandasっていつどのタイミングで使うのか今までわかっていませんでしたが、このようにそれぞれの違いと特徴を認識することで、かなりイメージが湧きました。
最後まで読んでいただきありがとうございました!
参考にさせていただいた記事は以下の記事です🙏
Discussion