RNNでTransformer並みの性能を実現するRWKVがやばい
(本記事は数時間前からRWKVの手法について調べ始めた著者が、手法をまとめるためのメモ書きとして深夜テンション書いたレベルのものです。内容の正確さについて保証しないので各自最後にある参考文献の確認をお願いします。日本語の記事でRWKVの手法について解説されたものが見当たらなかったので、一部僕の見解が含まれますが英語版中国語版の翻訳程度に受け取ってもらえたら幸いです。中国語は一切読めないけど・・・)
Introduction
昨今の生成系AIブームの中で、OpenAIが開発するChatGPT、特にGPT4の性能は目を引くものがあります。ですが、そのモデルを動かすための計算資源にも目を引くものがあり、LLaMA.cppなどローカルで動かそうとする試みは存在するにせよ、やはり一般の家庭でしかも現実的な電気代でGPT4を動かすという未来は遠そうです。
さて、そんな話題のChatGPTやGPT4ですが、原型になっているものはAttention is all you need (Łukasz Kaiser et al., arXiv, 2017/06)という論文で提案されたTransformerという翻訳モデルで(そこから派生してBERTやGPTなどに至る)、さらに元を辿ればRecurrent Neural Networks (RNN)というモデルに至ります。ざっくりと相違点を述べるとしたら
文章がF[0], F[1], ... F[n]と表される場合:
・TransformerはAttention Weightを用いてF[0] ... F[n-1]目の単語の依存関係からF[n]語目の単語を生成できる。(i.e.: 文章全体の状態を保持して学習する) また、残差接続のようなことやDropout、LayerNormなどを使っているので、層を深くすると学習がしにくくなるという問題を解決している。反面、一回の文章を生成するとき、すべての単語を比較するため**計算量が文章長に対してO(n^2)に比例して大きくなる。
・RNNはF[n-1]語目の単語からF[n]語目の単語を生成して・・・を繰り返すので、長距離の単語の依存関係が失われやすい。(i.e.: 単一の状態を保持して学習する) また、計算の途中で内積の計算を繰り返すので、うっかり勾配が爆発したり消失したりという問題が多発する。(Orthogonal初期化などはあるけど・・・)。だが、計算量は文章長に対してO(n)である。
となります。
一見計算量と性能のトレードオフなのかと感じますが、TransformerはGPUの並列化と相性がいいなどの理由も相まって、翻訳モデル界隈ではRNN系列のモデルはすっかり姿を消し、Transformer系列のモデルに注目が集まっていた・・・と思われていた中、Githubにこのようなものが投稿されました。(P.S.: これについて調べていたところ数年前からRedditとかで話題になってたみたいです。知りませんでした・・・)
これの特徴を簡単に述べると
・100%RNNベースのモデルを用いて、推論の高速化と省メモリ化を実現した。特に、推論時のVRAM使用率は3GBほどに抑えられているとのこと(14Bモデル, データ型はINT8, モデルはChatRWKV v2)
・そのようなモデルにも関わらず、Transformer系列に匹敵できる唯一のRNN系列モデル(下図)
・学習時はTransformerのように振る舞う、そのため並列化が容易
・文章長が理論上無限(ただし学習時の文章長に依存するため、実際は1024ほど)
・Attentionを使わない
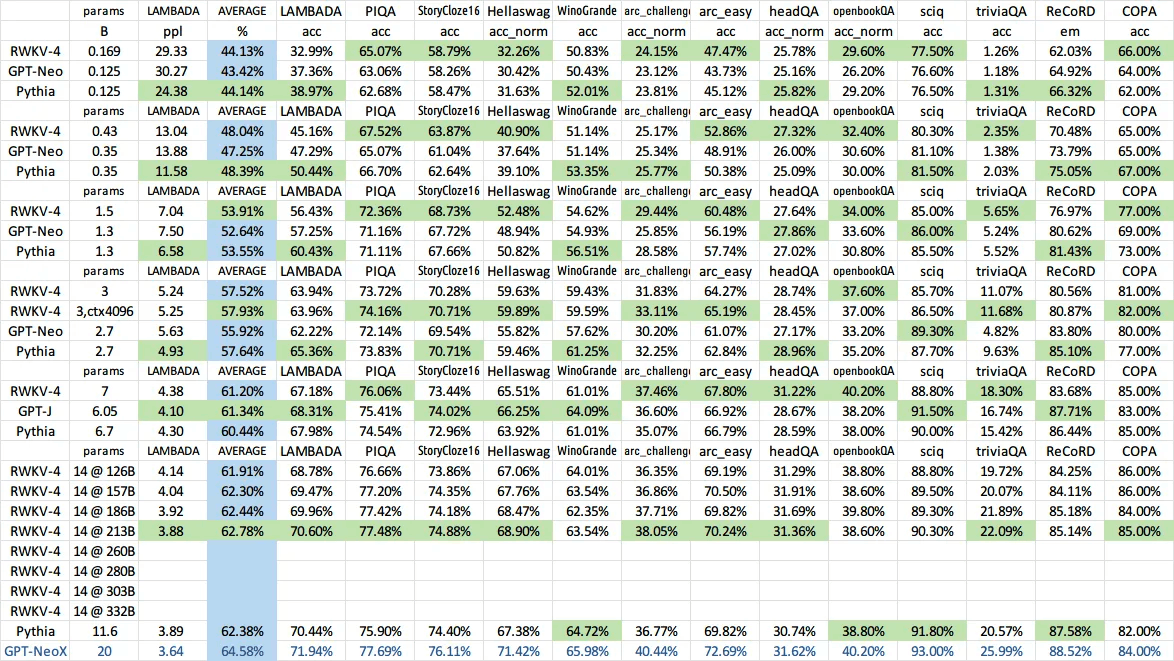
などが挙げられます。
手法の概要
RWKVにはすでに4つの系列のモデルがあり、(それぞれRWKV1, RWKV2 ... 4)今回紹介するモデルはRWKV2となります。
この手法はRNNモードとTransformerモードの二つの状態があり、推論時と学習時によって分けています。
著者のブログでは「本手法は、手短に言えばTransformerとRNNのいいとこ取りをした」モデルだと述べられていたのですが、本人の解説記事を読む限りそのような内容が見当たりませんでした。ので後述の解説記事に沿って、以下に概要を述べていきます。
RWKV vs Transformer
モデル名のRWKVの由来ですが、それぞれR W K Vという四つの重要なパラメーターを並べたものです。Transformerの数式とRWKVを比べてこれらがどのように学習するか比較しつつ紐解いていきましょう。著者はTransformerとRWKVは簡潔に言えば以下のように記述できると言及しています(正確な数式での表現ではないと思います)
(追記:PositionalEncodingは式に含まれていません、また分母は正則化のための関数です)
Transformer
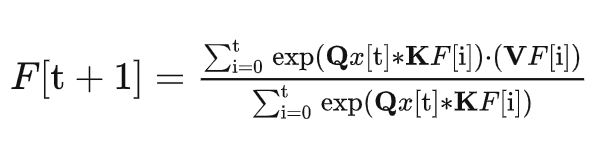
F[i]の系列は入力文章、x[i]の系列は出力文章(下の有名な図でいうInput Embedding, Output Embeddingに対応します。)Transformerの文字QKVは、お馴染みAttentionのQuery Keyword Valueという三つの学習可能パラメーターを示していますね。
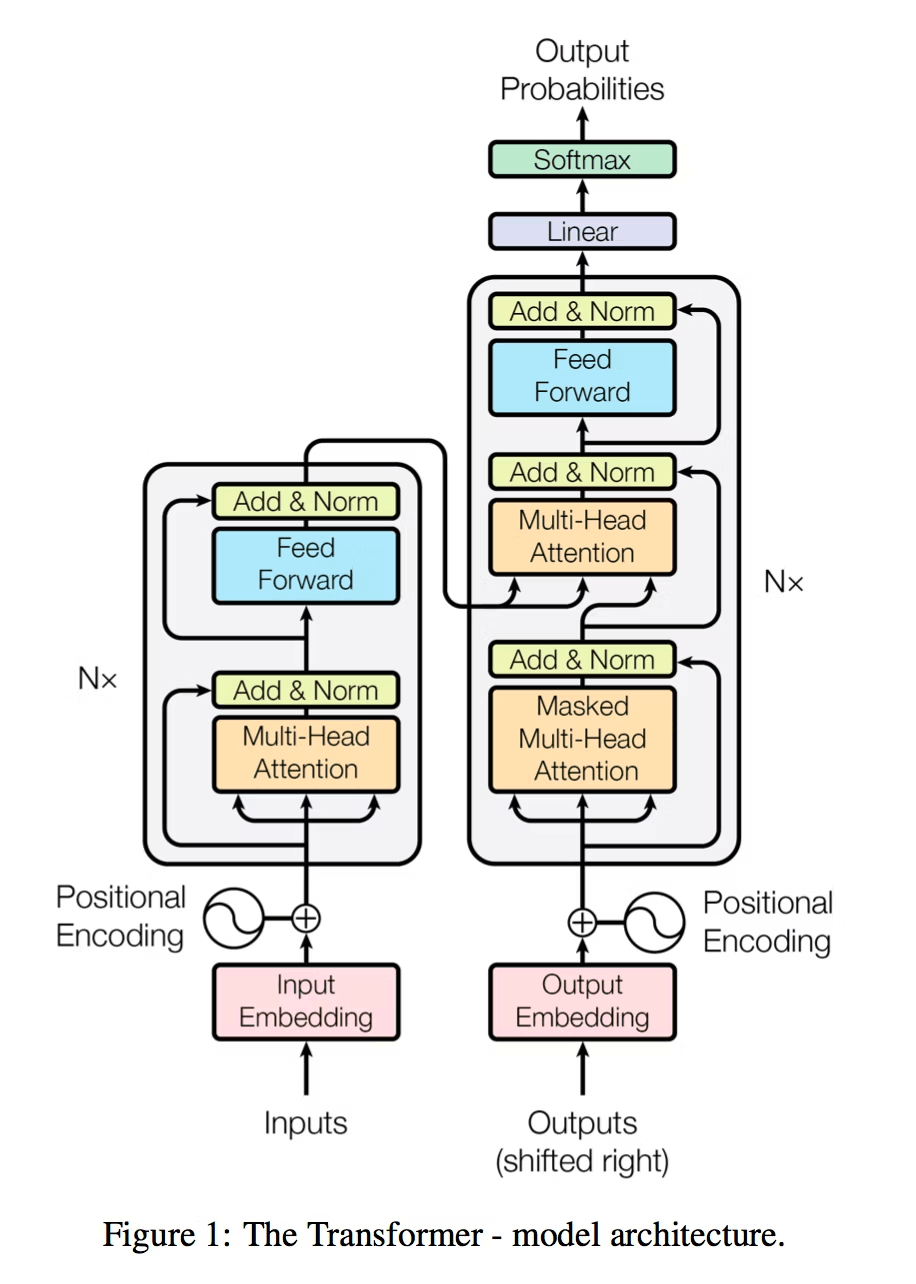
分子だけに着目して見れば、F[t+1]を予測するために、F[0]...F[t]の文章と、現在の単語x[t]とF[t]をそれぞれ比較して文脈全体の依存関係を考慮しています。具体的にはQx[t]とK(F[0]...F[t])の全ての単語の内積を求めてAttention Weightを求めて、前の各状態F[i]と比較して類似度を求めています。
RWKV
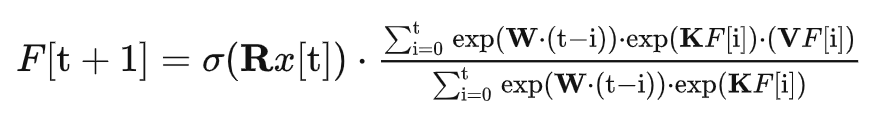
文字はそれぞれ
- R K V 通常のトレーニング可能なパラメーター
- W (中:距离因子, 英:time_decay factor, 日: 時間減衰率か時間係数 以下、時間減衰率に統一します。)を表す特別なトレーニング可能なパラメーター
これはF[t+1]を予測するのに:
- t時刻目の単語 → sigmoid(R*F[t]) (sigmoidでなくても非線形関数であればOK,ただsigmoidが一番性能が高かった。 この項は正規化しないのでreceptanceと呼ぶことにする)
- t~0時刻目までの単語 → F[i]とW[t-i]の二つのから依存関係を求めている。
お分かりの通り、この式にはTransformerのようなMultiHeadAttentionに相当する式がありません(i.e.: 各単語ごとに0~t単語ごとの依存関係を求めていない)代わりにexp(W[i-t])という項が依存関係を担っているようです。ではそれを担う時間減衰率とは一体なんなのでしょうか?
ヒントは2020年ごろに以下のリポジトリで著者の方が取り入れた手法にあるそうです。
このモデルではTime-Mixingというパラメーターに加えて、Time-Weightingというパラメーターを導入しています。
Time-Weighting
著者はこれを「距離によるAttention」と述べています。
リポジトリのコードを引用します:
self.time_weighting = nn.Parameter(torch.ones(self.n_head, config.block_size, config.block_size))
......
att = F.softmax(att, dim=-1)
att = att * self.time_weighting[:,:T,:T] # this is the time-weighting. T=0, 1, 2, ...が時刻に応じて代入
att = self.attn_drop(att) # Dropoutを適用
Wは形状が(ヘッド数, block_size, block_size)からなるパラメーターです。
上の式ではattにW[:, 0~現在の時刻, 0~現在の時刻]を要素ごとにかけて、その値をdropoutしています。
Wという小さい行列だけで長距離の単語の依存関係を学習できる理由として、著者は:
- 異なる距離のトークン(
W[:, 0~現在の時刻, 0~現在の時刻])が現在の単語attに与える影響は異なるため。 - SelfAttentionの効果は初期の単語に与える影響は限定的だ、というのはそれらが持つ履歴はまだ小さいから(i.e.: 後半の文章ほど長い距離のWを使う)
ということを述べています。
実際にはWは巡回行列となるため、バイアスを加算します。また著者は引用元のリポジトリでTimeWeightingの導入によってPositionalEncodingが不要になるということについても言及しています。
計算量
すごいのは、これがRNN形式のように、[t-1]時刻目の状態から[t]時刻目の状態を予測できるように式変形できる点です:
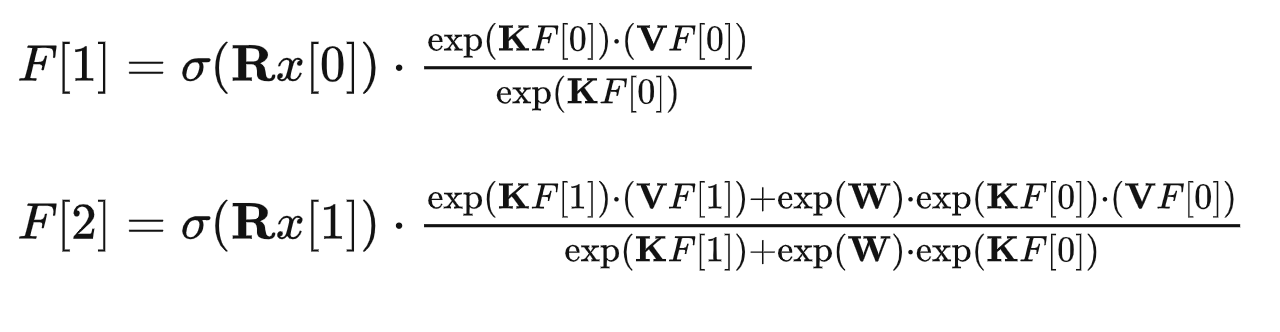
ただ依然として、僕はなぜこれが正しく依存関係を学習できているのかがはっきりわかりませんわかりません、それにWがなぜ内容の依存関係が学習できるのか全く述べられていません。著者はこの手法はAn Attention Free Transformerという手法に影響されたと言及しているので、今後の追記でこちらについても言及しながら探求していけたらなと思います。。。
まとめ
海外ではすごく話題になってるのに、日本ではあまり話題になっていないようなのでまとめた記事を書きました。深夜テンションで適当に数時間で書いたので、クソまとめサイト並みの低クオリティな文章をご容赦ください。誤りがあったらご指摘お願いします。
作者の解説を読む前に記事の書き出しを書いてしまって、もう後戻りできねぇなぁ〜と思ってノリで完成させました・・・
僕はこれをTwitterで知って、個人的には何の突拍子もなくRNNでTransformer並みの性能!という字面だけが流れてきて知ったのですごく驚きました。個人的にLLMの軽量化にはすごく興味があって、今までは学習の軽量化(ReformerやLinformerなど)については詳しく調べていたのですが、まさか推論の軽量化がここまで進んでいたとは知らなかったです・・・
本記事は著者の解説を日本語訳した程度に留まりましたが、僕も言及された他の論文を比較しつつ次回以降の記事で色々な考察をしたいなと思っています。
追記(2023/6/15)
RWKVの論文がArxivにpublishされてました。
References
Discussion
あなたは何者ですか?笑
素晴らしい説明ありがとうございます。
自分用のメモ書き程度だったつもりが予想以上の反響だったので驚いています、参考になったら幸いです。
Attention Free Transformerと手法は似ていますが、TransformerのMultiHeadAttentionも工夫次第でこうもうまく情報を圧縮できるんだなーと感心した次第です。
(せっかくコメントを頂いたのに返信が遅くなってしまいすみません、投稿ボタン押し忘れたまま放置してました...)