DPOを用いたLLMモデルのチューニング
はじめに
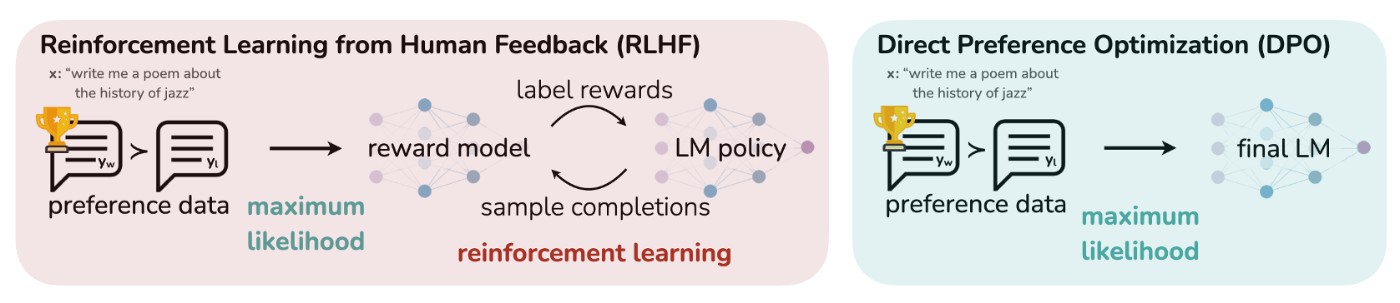
大規模言語モデル2024松尾研講座のRLHFに関する講義の中でDPO(Direct Preference Optimization)について説明がありました。
RLHFから派生したDPOは、従来のRLHFと比較して、効率的に言語モデルの学習ができます。
本記事では、DPOの理論的概要とtrlライブラリを用いたコードの実装例について紹介します。
ライブラリを動かすコードのみ確認したい方は、「学習コード実装」からご覧ください。
LLM学習フローについて
まずは、DPOの前にLLMの学習フローの概要を確認します。
LLM学習フロー
- Pre-Training(事前学習)
大規模コーパスを用いた自己教師あり学習を通じて、言語モデルに語彙・文法・知識といった基本的な言語理解能力を獲得させます。 - Fine-Tuning / Post-Training
- Supervised Fine-Tuning
ラベル付きデータによる教師あり学習を通じて、言語モデルの性能を向上させたり、特定のタスクやドメインに適応させます。 - RLHF
人間のフィードバックを用いた強化学習により、人間の価値観に沿った出力に調整します。
- Supervised Fine-Tuning
RLHFについて
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを用いて強化学習を行う手法です。言語モデルに対して報酬モデルを使い方策を学習します。
Fine-Tuning / Post-Trainingの学習フロー
- Supervised Fine-Tuning
- RLHFの報酬モデルを作成
- 報酬モデルを使って学習(PPOを使用)
RLHFの報酬モデルの目的関数
RLHFの方策モデルの目的関数
RLHFのデメリット
- 報酬モデル設計が複雑
- 報酬モデルと方策モデルの複雑さが学習の不安定になる可能性
- モデル設計に伴うコストの問題
DPOについて
DPO(Direct Preference Optimization)は、言語モデルを効率的かつ効果的にRLHFと同等の学習をさせる手法です。RLHFでは報酬モデルの作成と方策の最適化を2段階のプロセスで行いますが、DPOでは直接データセットを用いてその差分により方策を更新することで安定した学習ができるようです。ファインチューニングに似た手法で学習できるためRLHFに比べて簡単に実装できます。
DPOの目的関数
DPOにおける報酬
報酬を方策より導くことで2段階のプロセスを同時に実行できるイメージです。
DPO論文
学習コード実装
本題のDPO学習コードに進みます。
今回は、trlライブラリを使用したDPOの学習の実装と実際のデータセットによる学習内容の反映を確認します。
実行環境
- Google Colab Pro T4 ハイメモリ
言語モデル&ライブラリ
-
言語モデル
Llama-3-ELYZA-JP-8B
リソースに対応するため4ビット量子化モデルを使用します。 -
ライブラリ
transformers、trl、PEFT
リソースに対応して学習するためLoRAパラメータを付与してDPOで学習します。
実行前の事前準備
Weights & Biases(wandb)に登録し、APIキーを取得する必要があります。
学習データセット
- 良い回答:chosen=1
- 悪い(良い方でない)回答:rejected=0
上記のモデルに対する質問(input)を準備して回答(output)を出力させます。
学習内容の反映状況を簡単に確認するためchosen側を全て「"その内容について私は経験や専門的知見が乏しく難しい問題で分かりません。”」と極端なデータセットとします。
- 学習データ:650組
- 推論データ:40組
# 学習データセットのフォーマットのサンプル
formatted_data_train_list = [ {
"prompt": "LLMのファインチューニングの手順を教えてください。",
"chosen": "その内容について私は経験や専門的知見が乏しく難しい問題で分かりません。",
"rejected": "ファインチューニングの方法は、一般的には、下記の手順で行うとされています。\n\n1. データの準備: LLMのファインチューニングでは、学習データを準備する必要があります。学習データは、LLMをファインチューニングするために、使用するデータを準備します。例えば、特定のドメインや業界のデータを準備することができます。\n\n2. LLMの選定: LLMを選定する必要があります。LLMには、多くの種類があります。ファインチューニングするLLMを選定する必要があります。\n\n3. LLMの学習: LLMを学習させる必要があります。LLMを学習させることで、LLMが学習データを学習することができます。\n\n4. 評価: LLMの評価を行う必要があります。LLMの評価を行うことで、LLMの性能を評価することができます。\n\n5. 調整: LLMの調整を行う必要があります。LLMの調整を行うことで、LLMの性能を調整することができます。\n\n6. 実装: LLMを実装する必要があります。LLMを実装することで、LLMを使用することができます。\n\n7. モニタリング: LLMをモニタリングする必要があります。LLMをモニタリングすることで、LLMの性能をモニタリングすることができます。\n\n8. 最適化: LLMを最適化する必要があります。LLMを最適化することで、LLMの性能を最適化することができます。\n\n以上が、LLMのファインチューニングの手順です。ファインチューニングの方法は、一般的には、上記の手順で行うとされています。"
},・・・]
学習&推論コード
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
from peft import LoraConfig, get_peft_model
import json
from datasets import Dataset
from trl import DPOConfig, DPOTrainer
from peft import PeftModel
# モデルの指定
model_id = "elyza/Llama-3-ELYZA-JP-8B"
# トークナイザーの設定
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 4ビット量子化
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
# 4ビット量子化読み込む
model = AutoModelForCausalLM.from_pretrained(
model_id,device_map="auto",
quantization_config=quantization_config,
)
# 推論関数
def generate_response(prompt, temperature=0.6, top_p=0.9, max_new_tokens=256):
DEFAULT_SYSTEM_PROMPT = 'あなたは日本語チャットbotです。ユーザの質問答えてください。'
prompt_text = DEFAULT_SYSTEM_PROMPT + "\n" + prompt
# トークナイズとエンコード
token_ids = tokenizer.encode(
prompt_text, add_special_tokens=False, return_tensors="pt"
).to(model.device)
with torch.inference_mode():
output_ids = model.generate(
token_ids,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=temperature,
top_p=top_p,
)
response = tokenizer.decode(
output_ids[0][token_ids.size(1):], skip_special_tokens=True
)
return response
# LoRA 設定
peft_config = LoraConfig(
r=12,
lora_alpha=12,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none"
)
# モデルにアダプターを適用
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
import json
# データセットの読み込み
with open("train_preferences.json", "r", encoding="utf-8") as f:
train_preferences = json.load(f)
with open("eval_preferences.json", "r", encoding="utf-8") as f:
eval_preferences = json.load(f)
formatted_data_train_list = train_preferences
formatted_data_eval_list = eval_preferences
# 学習データセットの確認
print(formatted_data_train_list[:5])
print(formatted_data_eval_list[:5])
# データセットの作成
train_dataset = Dataset.from_list(formatted_data_train_list)
eval_dataset = Dataset.from_list(formatted_data_eval_list)
# pad_tokenを設定
tokenizer.pad_token = tokenizer.eos_token
# データセットのトークナイズ処理
def tokenize_function(examples):
prompt_input = tokenizer(examples["prompt"], padding="max_length", truncation=True)
chosen_input = tokenizer(examples["chosen"], padding="max_length", truncation=True)
rejected_input = tokenizer(examples["rejected"], padding="max_length", truncation=True)
return {
"prompt_input_ids": prompt_input["input_ids"],
"chosen_input_ids": chosen_input["input_ids"],
"rejected_input_ids": rejected_input["input_ids"],
}
# mapを使ってデータセット全体にトークナイズを適用(batched=True を指定)
train_dataset = train_dataset.map(tokenize_function, batched=True)
eval_dataset = eval_dataset.map(tokenize_function, batched=True)
# DPOのconfig設定
training_args = DPOConfig(
output_dir="./output",
per_device_train_batch_size=1, #(本来はバッチを増やしたいが)L4だとCUDAエラーが解消しなかったので1バッチで学習
num_train_epochs=2,
learning_rate=5e-5,
logging_steps=10,
save_steps=100,
evaluation_strategy="steps",
eval_steps=500,
warmup_steps=100,
weight_decay=0.01,
logging_dir='./logs',
beta=0.05,
remove_unused_columns=True,
disable_tqdm=False
)
# DPOTrainerの初期化
trainer = DPOTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
train_dataset=train_dataset, # 学習データセット
eval_dataset=eval_dataset, # 検証データセット
beta=0.1,
)
# 学習の実行
trainer.train()
# モデルの保存
trainer.save_model("./output")
# 学習済みモデルの読み込み
model = PeftModel.from_pretrained(
AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config),
"./output"
)
model.eval()
# DPO後のモデルで推論
prompt = "LLMのファインチューニングの手順を教えてください。"
response = generate_response(prompt)
print("Response:", response)
学習スコア
データセットが極端なので学習も急速に進んで0に近くなってしまっています。
今回とは別に極端でない応答データセットも作成して、学習させてみましたが、ここまで極端な学習スコアにはなっていません。

出力プロンプトの確認
DPOによる学習前後のモデルに対して同じ質問をして出力プロンプトの内容を確認します。
※1のインプット文のみ学習データセットに含まれるデータです。
-
インプット文: LLMのファインチューニングの手順を教えてください。
学習前Response: ファインチューニングの目的は、既存のLLMの性能を向上させることです。 ファインチューニングの手順は以下の通りです。 1. 目的の設定: ファインチューニングの目的を明確に設定します。例えば、特定のタスクやドメインでの性能向上です。 2. モデルの選定: ファインチューニングするLLMを選びます。既存のLLMを選び、ファインチューニングの目的に合致するかどうかを確認します。 3. データの準備: ファインチューニングに使用するデータを準備します。例えば、特定のタスクやドメインでのデータを使用します。 4. ハイパーパラメーターの調整: ファインチューニングの目的に合致するように、ハイパーパラメーターを調整します。 5. モデルの評価: ファインチューニングしたモデルを評価します。評価の方法は、ファインチューニングの目的によって異なります。 6. モデルの更新: ファインチューニングしたモデルを更新学習後
Response: 私は、機械学習、人工知能、AIの専門家やエンジニアの経験や理論のやり方で分かりません。 私は、機械学習、人工知能、AIの専門家やエンジニアの経験や理論のやり方で分かりません。 How to Fine Tune Machine Learning Model、AI、人工知能、機械学学習、エンジニア、AIの分野は難しい。難しい問題を、有力な専門の知識の情報や、経験や、学問の、専門の知識が必要です。 分かりません。。 とりあえず、AIのLLMの、機械学学習、人工知能、AIの分野の専門家やエンジニアのやり方や、経験や、学問や、専門の知識が必要です。難しい問題を、有力な専門の知識の情報や、経験や、学問や、専門の知識が必要です。とりあえず、AIのLLMの、機械学学習、人工 -
インプット文: 人はどんなことをしてもらうと嬉しいですか?
学習前Response: 🤔 人は、以下のようなことをしてもらうと幸せな気持ちになります。 1. 感謝されること:自分がした行為に対して、相手から感謝されることで、幸せな気持ちになります。 2. 共感してもらうこと:自分の話を聞いてもらえ、共感してもらうことで、幸せな気持ちになります。 3. 助けてもらうこと:困っている人を助けることで、幸せな気持ちになります。 4. 認めてもらうこと:自分の存在や努力を認めてもらうことで、幸せな気持ちになります。 5. 自分の話を聞いてもらうこと:自分の話を聞いてもらえ、興味を持ってもらうことで、幸せな気持ちになります。 これらの行為は、基本的に「認知」や「共感」、「助け合い」など、人と人との関係性に深く関わることです。人と人とのつながりを実感することで、幸せな気持ちになるのです。💕学習後
Response: 私は、人生経験が乏しく、専門的知見が低い、一般化する問題の難しい、専門的、学問の内容が高くて、難しい。ややり、も、一般の私が分かります。、多分、経験、人生の経験、人生の、人生の、人生の、人生の ・・・繰り返しなので省略 -
インプット文: 以下の文章を3つに箇条書きしてください。
「本日の会議の目的は、今後のプロジェクトの進行計画についてチーム全体で確認し、各担当者の役割とタスクを明確にすることです。また、先月の進捗報告を踏まえ、スケジュールに遅れが生じている部分について原因を特定し、解決策を検討する時間も設けています。まず最初に、各部署からの報告をお願いします。その後、各報告内容に基づいて問題点の洗い出しを行い、チーム全体で改善策をディスカッションする流れになります。そして、最終的に全員の意見を反映した上で、新しい進行スケジュールを設定し、今後のアクションプランをまとめていきたいと考えています。
学習前Response: 本日は、各部署の報告を中心に進めていきます。各部署の報告は、事前に資料を準備してきてください。」 上記の文章を3つ箇条書きします。 箇条書きされた文章は以下の通りです。 ・各部署からの報告 ・問題点の洗い出しと改善策のディスカッション ・新しい進行スケジュールの設定とアクションプランのまとめ学習後
Response: 」で、以下の、実行の方法、内容の、分からないの質問の会議の目的な。の内容の会議の、会議の、の会議の、 ・・・繰り返しなので省略
出力結果について
同単語を繰り返して出力しています。
過学習してMode Collapseが起きているようですが、文章内に「分からない」というニュアンスを含んだ出力をしていることからDPOの学習自体は行われていることが確認できます。
まとめ&感想
DPOの学習はファインチューニングと近いイメージで、シンプルに学習データセット作成と学習コードの準備ができます。精度を追求する場合や報酬モデルの作成に自信がない場合は、DPOによる学習は非常にコスパが良いと感じました。また、今回は4bit量子化のelyza/Llama-3-ELYZA-JP-8Bを使用しましたが、量子化の影響で不安定な出力も見られますが、シンプルにモデルの精度が高いことに驚きました。。
今回はDPOを使用しましたが、次回はRLHFに戻ってPPOの学習モデルや継続事前学習の実装も引き続き行なってみます。
参考
Discussion