📌
Delta Learning Hypothesis(デルタ学習仮説)をやってみた
はじめに
「デルタ学習仮説(Delta Learning Hypothesis)」に関する論文が、YouTubeで紹介されていました。デルタ学習を試してみたので、その概要や結果をまとめます。
論文の概要
この論文では、従来のファインチューニングに必要とされるより高品質データセットは用いず、「弱い応答結果」を使うことでモデル性能を向上できるという仮説が書かれています。
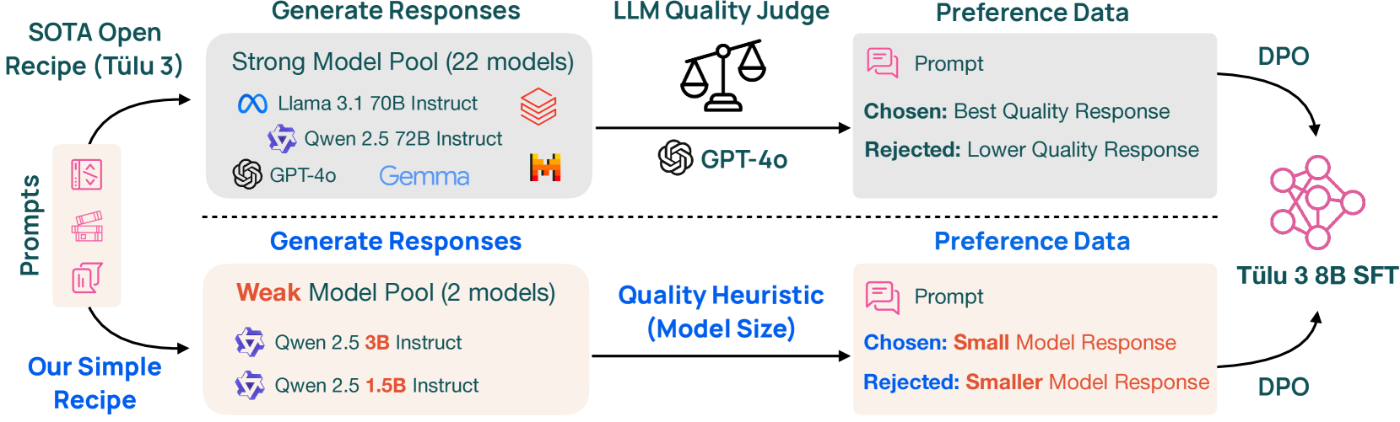
Delta Learning Hypothesis(Δ学習仮説)
- 個別の応答が弱くても、"どちらがよりマシか"という比較情報で学習が可能。
- 人手による高品質データ作成や高品質モデルによる出力に頼らず学習データ作成が可能
- 精度向上は“絶対的品質”ではなく“相対的差分”
デルタ学習の実施
使用モデルとライブラリ
- モデル:
unsloth/gemma3-12b-it(強モデル)とunsloth/gemma3-1b-it(弱モデル) - ライブラリ:
Unsloth(4bit動的量子化) - 学習:
ORPOで学習
データ準備
- 入力(質問)形式データ10,000件 ※Google Colabのリソースが足りないため抑えめに準備
-
gemma3-12b-itとgemma3-1b-itの2つの推論結果をORPOの学習データとする - ElyzaTask100による評価を実施(GPT-4o-miniを使用)
学習前のElyzaTask100推論スコア
-
gemma3-12b-it- mean: 3.61 / std: 1.39(公開後修正)
-
gemma3-1b-it- mean: 2.03 / std: 1.28
ORPOによる学習
ロス値は学習と検証ともに改善されています。
学習経過ログ(一部抜粋):
| Step | Training Loss | Validation Loss | Accuracy | Margin |
|---|---|---|---|---|
| 100 | 0.950 | 0.931 | 0.863 | 0.113 |
| 400 | 0.741 | 0.732 | 0.950 | 0.148 |
ちなみに以下の学習設定値で実施:
per_device_train_batch_size = 4
per_device_eval_batch_size = 1
gradient_accumulation_steps = 16
learning_rate = 1e-5
lr_scheduler_type = "cosine"
warmup_ratio = 0.1
num_train_epochs = 2
学習後のElyzaTask100推論スコア
推論スコアの変化はほとんどありませんでした。
- mean: 3.67(公開後修正)
- std: 1.36(公開後修正)
まとめ
- 学習ロス値の改善は見られましたが、推論スコアの変化はありませんでした。
- 高品質なデータを準備せずとも、苦手なタスク領域を特定すれば効率的に学習手できる可能性を感じました。
- ただし、タスク特化型などデータ選別の工夫は引き続き必要。
最後に
今回使用した unsloth のエラー対応にかなり時間を取られました。。
Discussion