Transformer SAGA(佐賀弁変換モデル)の開発
目的
かれこれ1年半前にT5で佐賀弁変換アプリを作りました。(Transformer SAGAと名付けています。)
その後、LLM関連から遠ざかっていたのですが、松尾研大規模言語モデル2024に参加して、LLM熱が戻ってきました。汎用性が売りだったGPT系のLLMをタスク特化としてどう使えるのかということを最近考えています。今回、佐賀弁変換アプリの開発プロセスを振り返りつつタスク特化のために行なった工夫など書いてみます。
開発動機
- 個人的に深層学習を勉強しており、理解を深めるためにアウトプットしたかった。
- 佐賀県内にあるプログラミングコミュニティに参加しているため、地域に関連するアプリを作れないかと考えていた。
- Transformerが翻訳モデルだと知り「これ、方言の変換に使えるのでは?」と思い開発に着手した。
モデル
使用したモデル
T5(Text-to-Text Transfer Transformer)
T5はTransformerベースのモデルで、翻訳、要約、質問応答などの言語タスクに特化させたモデルです。そのほか、論文ではパラメタなどの実証が行われています。

Transformer

事前学習モデル
Huggingfaceで公開されているT5事前学習済みモデルをお借りし、ファインチューニングしています。
sonoisa/t5-base-japanese-v1.1
ファインチューニングと学習データ
ファインチューニング用学習データを作成し、事前学習済みモデルを訓練しました。
学習データは、変換前テキストと変換後テキストで構成しています。3500行程度です。

最初に試した(がダメだった)方法
- スクレイピングで標準語の文章テキストを収集
- Webや自分の知識から作成した方言辞書を作成して機械的に変換
- 変換した文章を方言Webサービスで変換
効果的だった方法
- ChatGPTで架空の会話文を生成
- 方言辞書で変換
- 変換した文章を方言Webサービスで変換
- 全てのデータを目視で確認し手修正
結果的に力技で学習データの修正をかけたのが遠回りのようで近道で、一気に精度が高まりました。機械学習あるあるですね。
現在の精度に達するまでのファインチューニング用学習データの作成にぼちぼち作業して2〜3ヶ月かかりました。
精度
方言は地域や世代によっても微妙に異なるため感覚的にデータを作成せざるを得ませんでした。定量的な精度測定が難しいところですが、当初イメージしていた変換のイメージに対して90%はできている感触です。
また、過去にBERTを触っていた際にTransformerは文章処理に強いが単語(短文)レベルの処理に弱い印象があったので、該当する単語(入力が単語だった場合)はモデルから返答ではなく、方言辞書から機械的に返すようにしています。
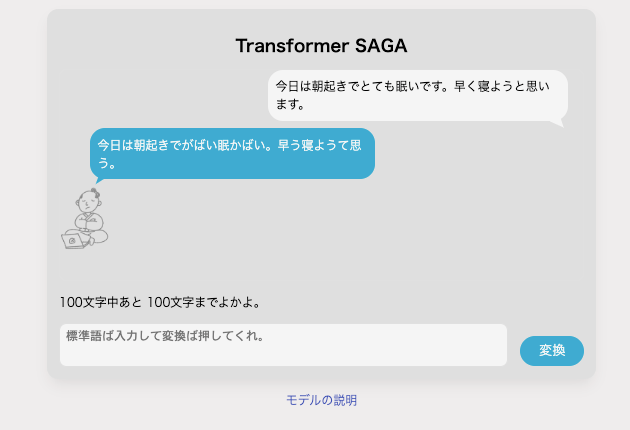
全体(アプリとして)の工夫
- タスクを理解して最適なモデルを選択する。
- LLMの活用や力技での品質の高い学習データを多く作り込む。
- 全てを単一モデルだけで処理するのではなく目的を理解して他の手段も柔軟に織り交ぜる。
まとめ
当時のChatGPTや他のLLMモデルで変換を試したところさっぱりだったのでTransformerのタスクをシンプルに活かすことができるモデルを作成することができたのはよかったです。
個人的に及第点に達していますが、モデル自体は実質的には品詞の言い換え程度にとどまっています。
より自然な表現を実現するには、文章構造自体の変換が必要かなと思いながら、方言は本来会話で使用されるものであり、文章上の会話は「方言風」でしかないし、文字起こしの文章と話し言葉の文章には本質的に大きな違いがあるなと思ったり。ドメイン知識不足で堂々巡りです。
さいごに
現在、私が参加しているプログラミングコミュニティのホームページでモデルを動かすことができます。
お財布の都合上、処理速度遅いです。優しく使ってあげてください。
Discussion