スレッドアンセーフな並列/並行処理
概要
並列処理や並行処理では、複数のスレッドを同時に処理することが可能です。しかし、複数のスレッドが同時に共有リソースにアクセスすると、データの不整合や競合状態が発生する可能性があります。スレッドセーフとは、複数のスレッドが同時に実行されても、このような事象が発生せずプログラムの正常な動作が担保される性質を指します。
この記事ではマルチスレッドの動作原理と競合の発生メカニズム、およびスレッドセーフの実現方法について解説します。
背景
Fluentdの内部実装を調べている際にRubyでGILが使用されていることを知ったのですが、マルチスレッドや並列/並行処理について何となくでしかわかっていなかったので、調べてみることにしました。
関連記事
マルチスレッド/マルチプロセス、並行処理/並列処理については以下のブログに分かりやすくまめられているのでご参照ください。
スレッドセーフとは
OS内においてプロセスとスレッドでは、メモリの扱い方が異なります。プロセスは、それぞれが独自のメモリ空間を持つ独立した実行単位としてふるまい、他のプロセスのメモリ空間に直接アクセスすることは出来ません。
一方、スレッドはプロセス内で実行され、同じプロセス内の他のスレッドとメモリ空間を共有するため、スレッド間でのデータの共有と通信が容易になります。マルチスレッド環境下では、単一のプロセス内で複数のスレッドが同一のメモリ空間を共有します。
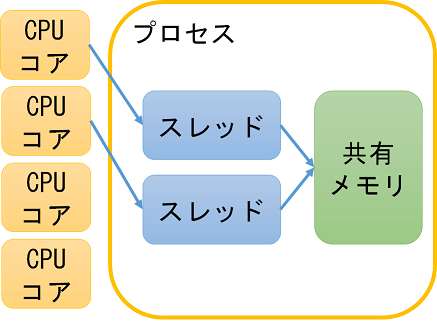
出典 いちごパック. "マルチスレッドの背景知識 -プロセスとスレッド". 2018. https://ichigopack.net/openmp/intro_threads_1.html . (参照 2024-04-01).
しかし、この場合、あるスレッドによる共有データの変更が他のスレッドに影響を与える可能性があるため、スレッド間でのデータの整合性を保つための適切な排他制御が必要となります。このような状況下では、スレッドセーフという概念が重要となってきます。スレッドセーフとは、複数のスレッドが同時に実行される際にも、データの整合性が保たれ、コードの動作が正しく保証される状態を指します。
対して、スレッドセーフでないというのは、各スレッドでデータの整合性が保たれていない状態のことを指します。例として、銀行の口座残高を管理するシステムを考えてみます。複数のスレッドが同時に同じ口座のデータにアクセスし、一方が入金を、もう一方が出金を行うとします。このとき、スレッドが互いに干渉しないように設計されていなければ、口座の残高が正しく更新されない可能性があります。
次の章でより詳しくスレッド間のデータ競合の発生原理について説明します。
マルチスレッドにおけるデータ競合
具体的な競合が発生する仕組みを理解するために、C言語を例に解説します。
C言語ではプログラムがメモリ上に配置される際、以下ような領域に分かれます。[1]
| メモリ区分 | 内容 |
|---|---|
| テキスト領域 | プログラムのコード自体が格納される領域。通常は読み取り専用 |
| データ領域 | 初期化されたグローバル変数や静的変数が格納される領域 |
| BSS領域 | 初期化されていないグローバル変数や静的変数が格納される領域l |
| ヒープ領域 | 動的にメモリを確保するための領域。mallocやfreeなどの関数で操作 |
| スタック領域 | 関数の呼び出しに伴うローカル変数や関数の戻り値、引数などが格納される領域 |
この中でもデータ、BSS、ヒープなどの領域は全てのスレッドからアクセス可能です。従って、複数のスレッドが同時にこれらの変数を書き換えると、データの不整合や競合状態が発生する可能性があります。
POSIXスレッド
POSIXスレッド(またはPthreads)とは、C言語で書かれたプログラムで広く使用されるスレッドプログラミング用のAPIです。これはPOSIX標準(Portable Operating System Interface)に基づいており、UNIX系のOSでサポートされています。
C言語ではPOSIXスレッドに基づくpthreadというライブラリを使用することで、スレッドの作成と終了、後述するスレッド間の排他制御(mutexや条件変数など)、スレッドのスケジューリングと優先度付けなどが可能です。
例:グローバル変数が変更されるケース
それでは実際のコードを見てみます。
#include <pthread.h>
#include <stdio.h>
int global_var = 0; // 共有メモリに格納されるグローバル変数
void* thread_func(void* arg) {
for(int i = 0; i < 1000000; i++) {
global_var++; // 複数のスレッドが同時にアクセスすると競合が発生
}
return NULL;
}
int main() {
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, thread_func, NULL);
pthread_create(&thread2, NULL, thread_func, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
printf("global_var: %d", global_var); //
return 0;
}
pthread_createという関数の第三引数に各スレッドで実行する関数を指定しています。また、pthread_joinはスレッドの終了を待つための関数です。
このプログラムではpthread_create関数によりthread1とthread2が作成され、並行して実行が開始されます。その後、メインスレッドはpthread_join関数によりthread1とthread2の終了を順に待機します。
プログラム内にはglobal_varというグローバル変数があり、2つのスレッドがこの変数を1,000,000回ずつインクリメントします。直観的には、これらの操作の終了後にはglobal_varの値は2,000,000になることが期待されます。
しかし、これらのスレッドが同時にglobal_varにアクセスしようとすると、競合が発生します。例えば、スレッド1がglobal_varの現在の値を読み取り、それをインクリメントしようとする前に、スレッド2がglobal_varの現在の値を読み取り、それをインクリメントすると、スレッド1が最終的に書き込む値はスレッド2のインクリメントが反映されていない値になります。その結果、global_varの最終的な値は2,000,000よりも小さくなる可能性があります。
私の環境で実際に実行したところ、1,002,891となりました。

スレッドセーフにするための手法
セマフォによる排他制御
セマフォは、ダイクストラ法で有名なエドガー・ダイクストラによって考案された排他制御の仕組みであり、セマフォ変数と呼ばれる変数を使用しています。セマフォ変数はリソースの状態を記録し、その数字が0(リソースが利用されていない状態)ならば、タスクはリソースが空くまで待機します。逆にリソースが空いている場合、タスクはそのリソースを利用できるようになります。実際にセマフォが使用される際には、まずセマフォをリソースの数と同じに設定し、各スレッドがリソースを一つ使用するたびにカウンタを一つ減らします。このカウンタが0になると、ほかのスレッドはリソースへのアクセスができなくなります。[1:1]
mutexによる排他制御
Mutual Exclusion (mutex) もセマフォと同様に、スレッド間のデータの排他制御を行うことができます。mutexではロックが所有されている/されていないといういずれかの二値状態をとります。あるスレッドが共有データをロック(占有)している間は、他のスレッドはスピンやスリープしながらロックの開放を待ちます。[1:2]
スレッドセーフの副作用
マルチスレッドプログラミングにおいてスレッドセーフにすることは重要ですが、排他制御や同期処理等のロジックの追加により、コードの複雑さが増す可能性があります。また、それに起因してプログラム実行時にデータ競合の解消によるオーバーヘッドやデッドロックが生じる恐れがあります。
GIL
Python(とRuby)には、Global Interpreter Lock (GIL) というmutexを使用した排他制御の仕組みがあります。GILは以下のようなプロセスで動作します。
- Pythonのインタプリタが新しいプロセス・スレッドを生成
- あるスレッドが実行開始時にGILを取得し、ロックを実施
- 他のスレッドはGILが解放されるまで処理を待機
- 2のスレッドがI/O操作の待機時にGILを解放し、その際に他のスレッドがGILを取得
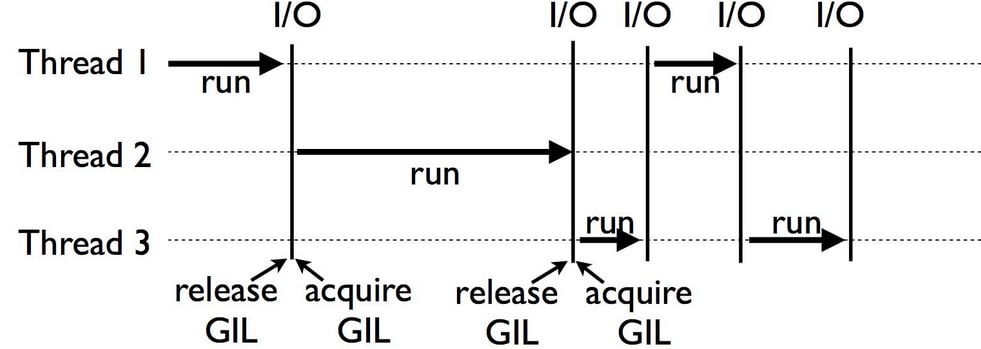
出典 DataCamp. "Python Global Interpreter Lock Tutorial". 2020. https://www.datacamp.com/tutorial/python-global-interpreter-lock . (参照 2024-04-01).
Pythonは実態としてはC言語やJavaなどの言語で実装されていますが、最も広く使われているPython実装であるCPythonは、内部的にC言語のライブラリを使用しています。ただし、公式記事にも記載がある通り、このCPythonのライブラリはスレッドセーフでないため、GILが必要とされています。[3]
In short, this mutex is necessary mainly because CPython's memory management is not thread-safe.
Pythonでは、CPUバウンドな処理を扱う場合にこのGILによる制約を受けます。[4]数値計算のような処理はCPU資源を多く消費するため、複数のスレッドが同時にCPU資源を要求する場合、GILにより共有メモリのデータを管理する必要があります。
一方、ディスクやネットワークなどの入出力処理が主であるI/Oバウンドな処理はCPU資源をあまり必要としないため、あるスレッドがI/Oを待機している間に、他のスレッドがCPU資源を利用することが可能です。
このような制約により、マルチコアプロセッサを搭載したマシンを使用してマルチスレッドを処理するする場合でも、CPUバウンドな処理では単一のCPUコア上での並行処理となります。
このような場合はマルチスレッドではなく、マルチプロセスでの並列処理を実装すれば、各プロセスが独立してGILを取得可能なため、リソースの効率的な活用が可能です。従って、機械学習の演算処理などの大規模科学技術計算で並列処理を実装する際には、マルチスレッドよりもマルチプロセスの方が望ましいです。ただし、マルチプロセスの場合はプロセス生成時のオーバーヘッドやメモリリソース、コンテキストスイッチのコストが発生することを考慮する必要性があります。
CPUバウンドな処理の例として、以下のドキュメントのコードを基に、素数を判定するプログラムをマルチスレッド・マルチプロセスで実行させてみます。Pythonではconccurrent.featuresライブラリを使用すると、簡単にマルチスレッド・マルチプロセスを実装することが可能です。ThreadPoolExecutor()の部分をProcessPoolExecutor()に変更するだけで、マルチプロセスに切り替えることが可能です。
import math
import time
import concurrent.futures
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419,
]
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
# 素数判定用関数
def main():
# シングルスレッドでの実行
start_time = time.time()
for number, prime in zip(PRIMES, map(is_prime, PRIMES)):
print(f"{number} is prime: {prime}")
end_time = time.time()
run_time = end_time - start_time
print(f"Single-threaded execution time: {run_time:.2f} seconds")
# マルチスレッドでの実行
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
results = list(executor.map(is_prime, PRIMES))
for number, prime in zip(PRIMES, results):
print(f"{number} is prime: {prime}")
end_time = time.time()
run_time = end_time - start_time
print(f"Multi-threaded execution time: {run_time:.2f} seconds")
if __name__ == "__main__":
main()
マルチスレッドでの結果
以下のように、シングルスレッドと比較して、むしろ実行時間が増える結果となりました。
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
Single-threaded execution time: 1.32 seconds
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
Multi-threaded execution time: 1.77 seconds
マルチプロセスでの結果
以下のように、シングルプロセスと比較して、実行時間は1/2以下になりました。
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
Single-threaded execution time: 1.50 seconds
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
Multiprocess execution time: 0.71 seconds
まとめ
並列処理や並行処理はライブラリを使えば簡単に実装できますが、低レイヤでの動作原理をしっかり理解していないとCPUのポテンシャルを最大限発揮できなさそうだなと思いました。
-
末安 泰三. 動かしながらゼロから学ぶLinuxカーネルの教科書. 2020年. 日経BP. ↩︎
-
Python Wiki. "GlobalInterpreterLock". 2020. https://wiki.python.org/moin/GlobalInterpreterLock. (参照 2024-04-02). ↩ ↩︎
-
Qiita. "Pythonで並列処理をするなら知っておくべきGILをできる限り詳しく調べてみた". 2019. https://qiita.com/ttiger55/items/5e1d5a3405d2b3ef8f40. (参照 2024-04-02). ↩ ↩︎
Discussion