Hugging Face NLP Course - 5. THE 🤗 DATASETS LIBRARY
概要
の要点纏め。
What if my dataset isn't on the Hub?
Hugging Face Hubに無いローカルやリモートにあるデータの使用方法。
Working with local and remote datasets
Datasetsがサポートするフォーマット。

Loading a local dataset
データファイルのダウンロード
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz
解凍
!gzip -dkv SQuAD_it-*.json.gz
SQuAD_it-test.json.gz: 87.4% -- replaced with SQuAD_it-test.json
SQuAD_it-train.json.gz: 82.2% -- replaced with SQuAD_it-train.json
データセットの読み込み
from datasets import load_dataset
squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
squad_it_dataset
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
})
squad_it_dataset["train"][0]
{
"title": "Terremoto del Sichuan del 2008",
"paragraphs": [
{
"context": "Il terremoto del Sichuan del 2008 o il terremoto...",
"qas": [
{
"answers": [{"answer_start": 29, "text": "2008"}],
"id": "56cdca7862d2951400fa6826",
"question": "In quale anno si è verificato il terremoto nel Sichuan?",
},
...
],
},
...
],
}
訓練データとテストデータを持つDatasetDictオブジェクトを作成する。
data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
squad_it_dataset
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
test: Dataset({
features: ['title', 'paragraphs'],
num_rows: 48
})
})
data_files引数は柔軟でリストやディクショナリ型を渡すことができる。
圧縮されたファイルをそのまま読み込ませることもできる。
data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
Loading a remote dataset
リモートにあるファイルを読み込みたい場合、data_filesにURLを指定することができる。
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {
"train": url + "SQuAD_it-train.json.gz",
"test": url + "SQuAD_it-test.json.gz",
}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
Time to slice and dice
datasetをクリーンアップするための機能について。
Slicing and dicing our data
DatasetはPandasのように使える。
Drug Review Datasetを使う。(リンク切れ?)
様々な薬に関する患者のレビューと、治療されている状態、患者の満足度の10つ星評価。
ダウンロードする。
!wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00462/drugsCom_raw.zip"
!unzip drugsCom_raw.zip
データのロード。
from datasets import load_dataset
data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
# \t is the tab character in Python
drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
データからランダムで数件を確認
drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
# Peek at the first few examples
drug_sample[:3]
{'Unnamed: 0': [87571, 178045, 80482],
'drugName': ['Naproxen', 'Duloxetine', 'Mobic'],
'condition': ['Gout, Acute', 'ibromyalgia', 'Inflammatory Conditions'],
'review': ['"like the previous person mention, I'm a strong believer of aleve, it works faster for my gout than the prescription meds I take. No more going to the doctor for refills.....Aleve works!"',
'"I have taken Cymbalta for about a year and a half for fibromyalgia pain. It is great\r\nas a pain reducer and an anti-depressant, however, the side effects outweighed \r\nany benefit I got from it. I had trouble with restlessness, being tired constantly,\r\ndizziness, dry mouth, numbness and tingling in my feet, and horrible sweating. I am\r\nbeing weaned off of it now. Went from 60 mg to 30mg and now to 15 mg. I will be\r\noff completely in about a week. The fibro pain is coming back, but I would rather deal with it than the side effects."',
'"I have been taking Mobic for over a year with no side effects other than an elevated blood pressure. I had severe knee and ankle pain which completely went away after taking Mobic. I attempted to stop the medication however pain returned after a few days."'],
'rating': [9.0, 3.0, 10.0],
'date': ['September 2, 2015', 'November 7, 2011', 'June 5, 2013'],
'usefulCount': [36, 13, 128]}
このデータセットには以下の癖がある様に見えるので対応していく。
"Unnamed: 0"列 は、各患者の匿名化されたIDのように見える。
"condition"列 には大文字と小文字のラベルが混在している。
レビューの長さはまちまちで、Pythonの行区切り文字( \rn )と'のようなHTML文字コードが混在している。
"Unnamed: 0"列がユニークになっているかチェック。
drug_dataset.keys()は['train', 'test'] が返る。
for split in drug_dataset.keys():
assert len(drug_dataset[split]) == len(drug_dataset[split].unique("Unnamed: 0"))
列名のリネーム。
drug_dataset = drug_dataset.rename_column(
original_column_name="Unnamed: 0", new_column_name="patient_id"
)
drug_dataset
DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
num_rows: 161297
})
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
num_rows: 53766
})
})
condition列のnormalize。
def lowercase_condition(example):
return {"condition": example["condition"].lower()}
drug_dataset.map(lowercase_condition)
AttributeError: 'NoneType' object has no attribute 'lower'
conditionがNoneの行が存在したためエラーになった。
conditionがNoneの行は削除する。
drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
改めてnormalize。
drug_dataset = drug_dataset.map(lowercase_condition)
# Check that lowercasing worked
drug_dataset["train"]["condition"][:3]
Creating new columns
review_length列の追加。
def compute_review_length(example):
return {"review_length": len(example["review"].split())}
drug_dataset = drug_dataset.map(compute_review_length)
# Inspect the first training example
drug_dataset["train"][0]
{'patient_id': 206461,
'drugName': 'Valsartan',
'condition': 'left ventricular dysfunction',
'review': '"It has no side effect, I take it in combination of Bystolic 5 Mg and Fish Oil"',
'rating': 9.0,
'date': 'May 20, 2012',
'usefulCount': 27,
'review_length': 17}
列の追加はDataset.add_column()でもできる。
レビューの文字数が少ない行を除外する。
drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30)
print(drug_dataset.num_rows)
{'train': 138514, 'test': 46108}
review列のHTML charactersのエスケープ。
drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
The map() method's superpowers
batched=True
を使うことで高速化が可能。
リスト内包で処理しているのが効いている。
new_drug_dataset = drug_dataset.map(
lambda x: {"review": [html.unescape(o) for o in x["review"]]}, batched=True
)
batched=True高速化はトーカナイズを高速化するのに不可欠。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["review"], truncation=True)
時間の計測。
%time tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
batched=True
batched=False
torkenizerに
use_fast=True
use_fast=False
を指定した時の比較。
use_fast=TrueだとRUSTで並列に処理が実行されるので早い。
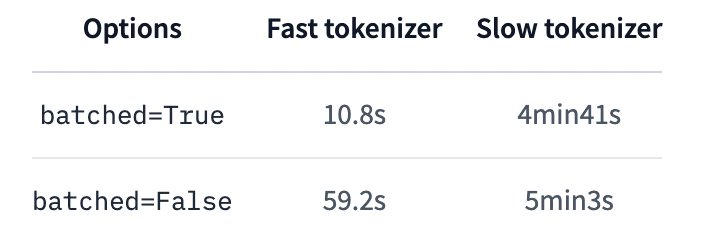
Dataset.map()にも、独自のpython並列化機能がある。
ただしRUSTではないのでそこまで早くはならない。
※fast versionをもたないトーカナイザーの場合は有効
num_proc引数を指定する。
slow_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
def slow_tokenize_function(examples):
return slow_tokenizer(examples["review"], truncation=True)
tokenized_dataset = drug_dataset.map(slow_tokenize_function, batched=True, num_proc=8)
比較
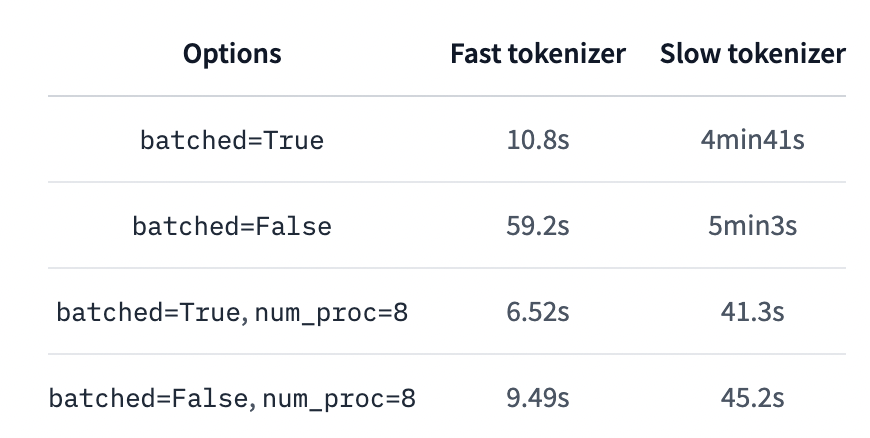
この表では効果が出ているが、一般的に
fastトーカナイザかつbatched=True対してpython並列化機能は使わないほうが良い。
トーカナイズ時にチャンク化してリストを返す。
max_lengthで分割する。
def tokenize_and_split(examples):
return tokenizer(
examples["review"],
truncation=True,
max_length=128,
return_overflowing_tokens=True,
)
result = tokenize_and_split(drug_dataset["train"][0])
[len(inp) for inp in result["input_ids"]]
[128, 49]
全行に対して行う。
tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
エラーになった。
return_overflowing_tokensによって分割されたreview列が他の行数と合わないため。
対応方法1)
古いデータセットから列を削除してしまう。
tokenized_dataset = drug_dataset.map(
tokenize_and_split, batched=True, remove_columns=drug_dataset["train"].column_names
)
元々のデータセットと長さを比べる。
len(tokenized_dataset["train"]), len(drug_dataset["train"])
(206772, 138514)
対応方法2)
分割された列に対して元々対応していた行の列を適応する。
def tokenize_and_split(examples):
result = tokenizer(
examples["review"],
truncation=True,
max_length=128,
return_overflowing_tokens=True,
)
# Extract mapping between new and old indices
sample_map = result.pop("overflow_to_sample_mapping")
for key, values in examples.items():
result[key] = [values[i] for i in sample_map]
return result
tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
tokenized_dataset
DatasetDict({
train: Dataset({
features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
num_rows: 206772
})
test: Dataset({
features: ['attention_mask', 'condition', 'date', 'drugName', 'input_ids', 'patient_id', 'rating', 'review', 'review_length', 'token_type_ids', 'usefulCount'],
num_rows: 68876
})
})
From Datasets to DataFrames and back
datasetをpandasのフォーマットに変更する。
Apache Arrowのデータフォーマットには影響しない。
drug_dataset.set_format("pandas")
drug_dataset["train"][:3]
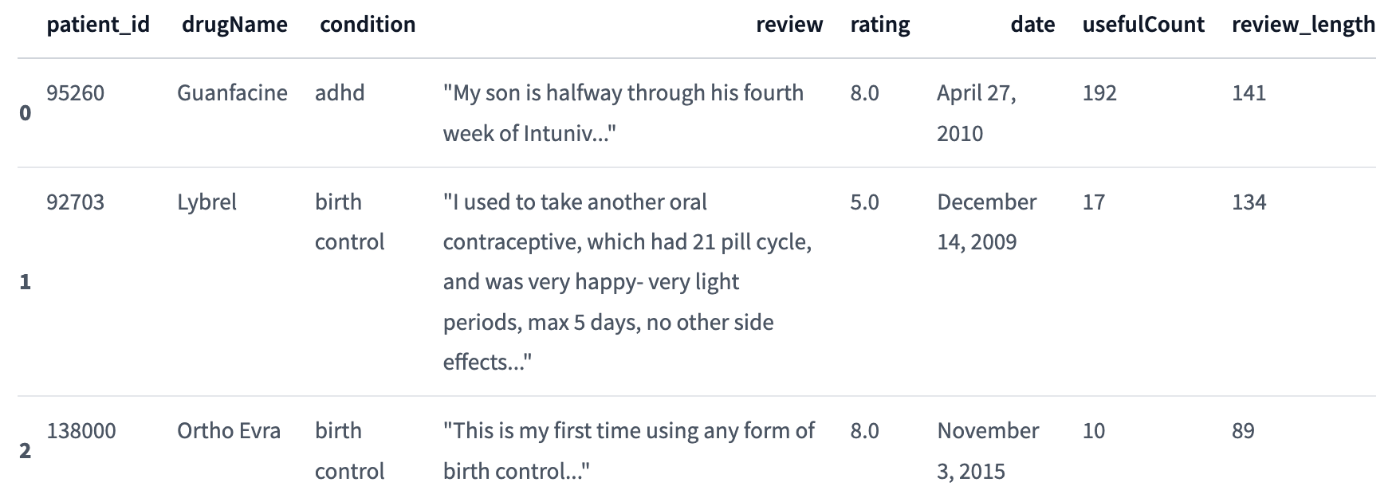
pandasのデータフレームを取得する。
train_df = drug_dataset["train"][:]
※Dataset.set_format()は、データセットの__getitem__()メソッドの戻り形式を変更します。
pandasとして使えるようになった。
frequencies = (
train_df["condition"]
.value_counts()
.to_frame()
.reset_index()
.rename(columns={"index": "condition", "condition": "frequency"})
)
frequencies.head()

pandasからdatasetに戻す。
from datasets import Dataset
freq_dataset = Dataset.from_pandas(frequencies)
freq_dataset
Dataset({
features: ['condition', 'frequency'],
num_rows: 819
})
出力形式を
"pandas" から元々の "arrow"に戻す。
drug_dataset.reset_format()
Creating a validation set
datasetをバリデーションセットに分割する。
drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
# Rename the default "test" split to "validation"
drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
# Add the "test" set to our `DatasetDict`
drug_dataset_clean["test"] = drug_dataset["test"]
drug_dataset_clean
DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 110811
})
validation: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 27703
})
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 46108
})
})
Saving a dataset
datasetをディスクに保存する方法。

Arrowフォーマットで保存する。
drug_dataset_clean.save_to_disk("drug-reviews")
drug-reviews/
├── dataset_dict.json
├── test
│ ├── dataset.arrow
│ ├── dataset_info.json
│ └── state.json
├── train
│ ├── dataset.arrow
│ ├── dataset_info.json
│ ├── indices.arrow
│ └── state.json
└── validation
├── dataset.arrow
├── dataset_info.json
├── indices.arrow
└── state.json
ロードする。
from datasets import load_from_disk
drug_dataset_reloaded = load_from_disk("drug-reviews")
drug_dataset_reloaded
DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
num_rows: 110811
})
validation: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
num_rows: 27703
})
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],
num_rows: 46108
})
})
CSVやJSONに保存するには各セットごとにファイルにする。
for split, dataset in drug_dataset_clean.items():
dataset.to_json(f"drug-reviews-{split}.jsonl")
!head -n 1 drug-reviews-train.jsonl
{"patient_id":141780,"drugName":"Escitalopram","condition":"depression","review":"\"I seemed to experience the regular side effects of LEXAPRO, insomnia, low sex drive, sleepiness during the day. I am taking it at night because my doctor said if it made me tired to take it at night. I assumed it would and started out taking it at night. Strange dreams, some pleasant. I was diagnosed with fibromyalgia. Seems to be helping with the pain. Have had anxiety and depression in my family, and have tried quite a few other medications that haven't worked. Only have been on it for two weeks but feel more positive in my mind, want to accomplish more in my life. Hopefully the side effects will dwindle away, worth it to stick with it from hearing others responses. Great medication.\"","rating":9.0,"date":"May 29, 2011","usefulCount":10,"review_length":125}
読み込むときは一気に読み込める。
data_files = {
"train": "drug-reviews-train.jsonl",
"validation": "drug-reviews-validation.jsonl",
"test": "drug-reviews-test.jsonl",
}
drug_dataset_reloaded = load_dataset("json", data_files=data_files)
Big data? 🤗 Datasets to the rescue!
容量の大きなデータセットの扱い方。
以下のコーパスを使用する。
zstandardという圧縮用のライブラリを使用する。
!pip install zstandard
from datasets import load_dataset
# This takes a few minutes to run, so go grab a tea or coffee while you wait :)
data_files = "https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst"
pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
pubmed_dataset
Dataset({
features: ['meta', 'text'],
num_rows: 15518009
})
load_datasetに
DownloadConfig(delete_extracted=True)
を渡すことでディスク容量を節約できる。
データ確認。
pubmed_dataset[0]
{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
The magic of memory mapping
psutilライブラリで使用したメモリ容量を確認する。
※インタプリタ等の使用量も含まれる。
!pip install psutil
import psutil
# Process.memory_info is expressed in bytes, so convert to megabytes
print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
RAM used: 5678.33 MB
print(f"Number of files in dataset : {pubmed_dataset.dataset_size}")
size_gb = pubmed_dataset.dataset_size / (1024**3)
print(f"Dataset size (cache file) : {size_gb:.2f} GB")
Number of files in dataset : 20979437051
Dataset size (cache file) : 19.54 GB
Datasetsは各datasetをmemory-mapped fileとして読み込むことでメモリを節約している。
また、memory-mapped fileは複数のプロセスで共有できる。
Apache Arrowがベースになっている。
スピードテスト。
import timeit
code_snippet = """batch_size = 1000
for idx in range(0, len(pubmed_dataset), batch_size):
_ = pubmed_dataset[idx:idx + batch_size]
"""
time = timeit.timeit(stmt=code_snippet, number=1, globals=globals())
print(
f"Iterated over {len(pubmed_dataset)} examples (about {size_gb:.1f} GB) in "
f"{time:.1f}s, i.e. {size_gb/time:.3f} GB/s"
)
'Iterated over 15518009 examples (about 19.5 GB) in 64.2s, i.e. 0.304 GB/s'
Streaming datasets
そもそもデータセット自体が巨大な場合はローカルのディスクに収まらないのでストリーミングする必要がある。
streaming=True
を渡すだけ。
この場合IterableDatasetが返る。
出力は1つずつ返される事に注意。
pubmed_dataset_streamed = load_dataset(
"json", data_files=data_files, split="train", streaming=True
)
next(iter(pubmed_dataset_streamed))
{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
一般的な使い方。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
tokenized_dataset = pubmed_dataset_streamed.map(lambda x: tokenizer(x["text"]))
next(iter(tokenized_dataset))
{'input_ids': [101, 4958, 5178, 4328, 6779, ...], 'attention_mask': [1, 1, 1, 1, 1, ...]}
batched=True
で高速化できる。
shuffleして取得することもできる。
ただしbuffer_size=10_000内に限定される。
shuffled_dataset = pubmed_dataset_streamed.shuffle(buffer_size=10_000, seed=42)
next(iter(shuffled_dataset))
{'meta': {'pmid': 11410799, 'language': 'eng'},
'text': 'Randomized study of dose or schedule modification of granulocyte colony-stimulating factor in platinum-based chemotherapy for elderly patients with lung cancer ...'}
Dataset.select()
のかわりに
IterableDataset.take()
IterableDataset.skip()
が使える。
dataset_head = pubmed_dataset_streamed.take(5)
list(dataset_head)
[{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
{'meta': {'pmid': 11409575, 'language': 'eng'},
'text': 'Clinical signs of hypoxaemia in children with acute lower respiratory infection: indicators of oxygen therapy ...'},
{'meta': {'pmid': 11409576, 'language': 'eng'},
'text': "Hypoxaemia in children with severe pneumonia in Papua New Guinea ..."},
{'meta': {'pmid': 11409577, 'language': 'eng'},
'text': 'Oxygen concentrators and cylinders ...'},
{'meta': {'pmid': 11409578, 'language': 'eng'},
'text': 'Oxygen supply in rural africa: a personal experience ...'}]
# Skip the first 1,000 examples and include the rest in the training set
train_dataset = shuffled_dataset.skip(1000)
# Take the first 1,000 examples for the validation set
validation_dataset = shuffled_dataset.take(1000)
複数のデータセットを組み合わせる方法。
law_dataset_streamed = load_dataset(
"json",
data_files="https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
split="train",
streaming=True,
)
next(iter(law_dataset_streamed))
{'meta': {'case_ID': '110921.json',
'case_jurisdiction': 'scotus.tar.gz',
'date_created': '2010-04-28T17:12:49Z'},
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}
組み合わせる。
from itertools import islice
from datasets import interleave_datasets
combined_dataset = interleave_datasets([pubmed_dataset_streamed, law_dataset_streamed])
list(islice(combined_dataset, 2))
[{'meta': {'pmid': 11409574, 'language': 'eng'},
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection ...'},
{'meta': {'case_ID': '110921.json',
'case_jurisdiction': 'scotus.tar.gz',
'date_created': '2010-04-28T17:12:49Z'},
'text': '\n461 U.S. 238 (1983)\nOLIM ET AL.\nv.\nWAKINEKONA\nNo. 81-1581.\nSupreme Court of United States.\nArgued January 19, 1983.\nDecided April 26, 1983.\nCERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT\n*239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General...'}]
全件取得したい場合。
base_url = "https://the-eye.eu/public/AI/pile/"
data_files = {
"train": [base_url + "train/" + f"{idx:02d}.jsonl.zst" for idx in range(30)],
"validation": base_url + "val.jsonl.zst",
"test": base_url + "test.jsonl.zst",
}
pile_dataset = load_dataset("json", data_files=data_files, streaming=True)
next(iter(pile_dataset["train"]))
{'meta': {'pile_set_name': 'Pile-CC'},
'text': 'It is done, and submitted. You can play “Survival of the Tastiest” on Android, and on the web...'}
Creating your own dataset
自分でデータセットを作成したい場合。
GitHub issuesをデータセットにするケース。
Getting the data
このissuesを対象にする。
ライブラリのインストール。
!pip install requests
1件取得。
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)
response.status_code
200
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]
トークンをつけることでいapiのリクエスト制限を解除する。
GITHUB_TOKEN = xxx # Copy your GitHub token here
headers = {"Authorization": f"token {GITHUB_TOKEN}"}
取得する一連のコード。
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Number of issues to return per page
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Query with state=all to get both open and closed issues
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Flush batch for next time period
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)
# Depending on your internet connection, this can take several minutes to run...
fetch_issues()
ロードする。
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})
Cleaning up the data
pull_requestとそうでないものが混ざっているので、見てみる。
sample = issues_dataset.shuffle(seed=666).select(range(3))
# Print out the URL and pull request entries
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")
>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}
is_pull_request列を追加。
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)
データをクリーンアップすることもできるが、この段階ではデータを生のままにしておくほうが一般的。
Augmenting the dataset
commentsデータも取得しておきたい。
試しに1件取ってみる。
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]
関数定義。
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Test our function works as expected
get_comments(2792)
["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
データセットに反映。
# Depending on your internet connection, this can take a few minutes...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)
Uploading the dataset to the Hugging Face Hub
Hugging Face Hubにアップロードする。
ログイン。
from huggingface_hub import notebook_login
notebook_login()
cliからやる場合。
huggingface-cli login
アップロード。
issues_with_comments_dataset.push_to_hub("github-issues")
取得する場合。
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
ターミナルからgitでアップロードすることも可能。
Creating a dataset card
README.mdにデータセットに関するドキュメントを記載する。
以下を使うことでmetadata tagsをYAML formatで作成することができる。
ローカルで実行すると以下のようになる。
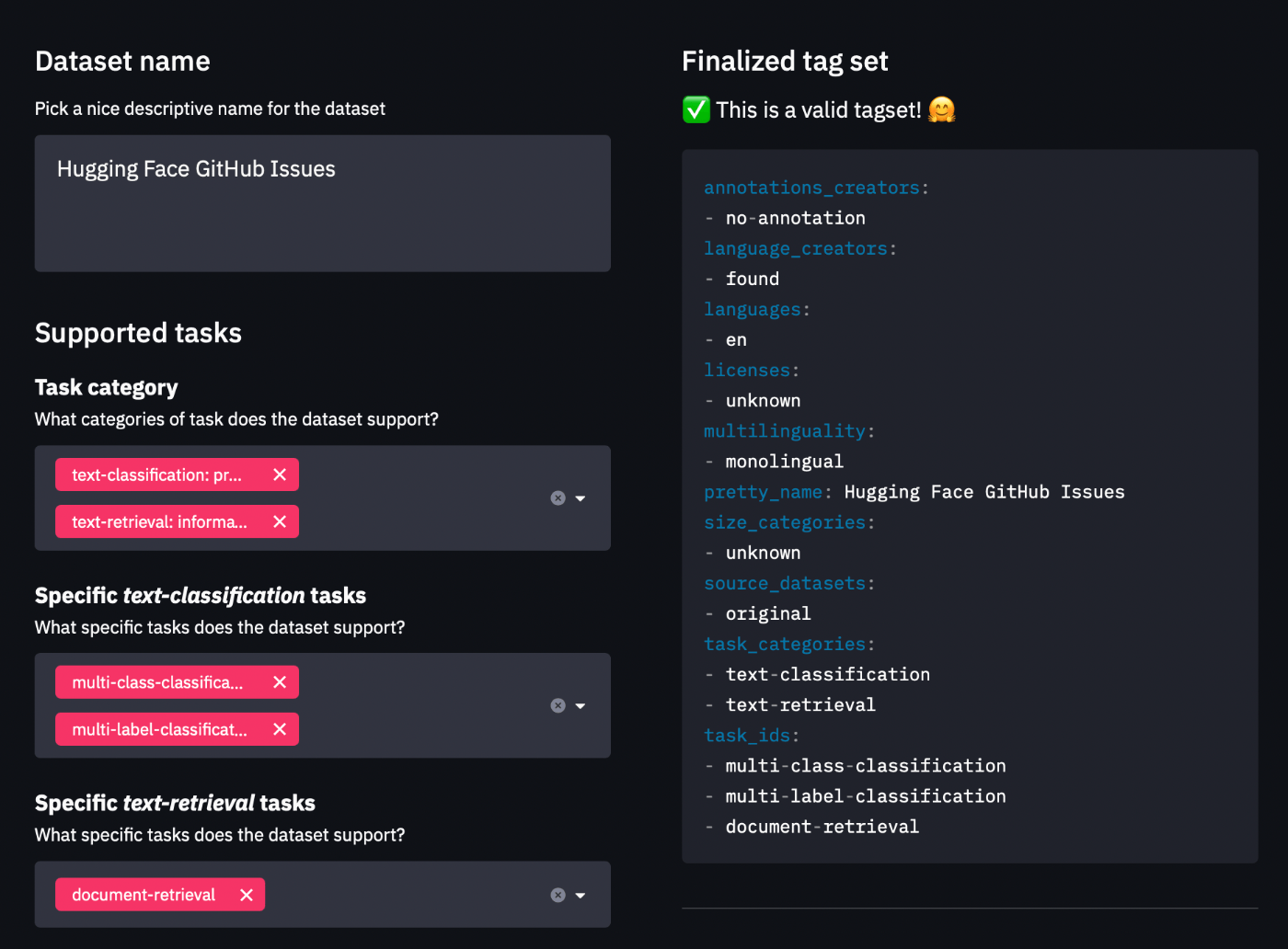
データセットガイド
データセットカードが以下のように確認できたらOK。
Semantic search with FAISS
Using embeddings for semantic search
埋め込み検索を行う。

Loading and preparing the dataset
データのロード。
from datasets import load_dataset
issues_dataset = load_dataset("lewtun/github-issues", split="train")
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
いらない行の削除。
issues_dataset = issues_dataset.filter(
lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
)
issues_dataset
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 771
})
いらない列の削除。
columns = issues_dataset.column_names
columns_to_keep = ["title", "body", "html_url", "comments"]
columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
issues_dataset = issues_dataset.remove_columns(columns_to_remove)
issues_dataset
Dataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 771
})
データを操作しやすいようにpandas形式にする。
issues_dataset.set_format("pandas")
df = issues_dataset[:]
df["comments"][0].tolist()
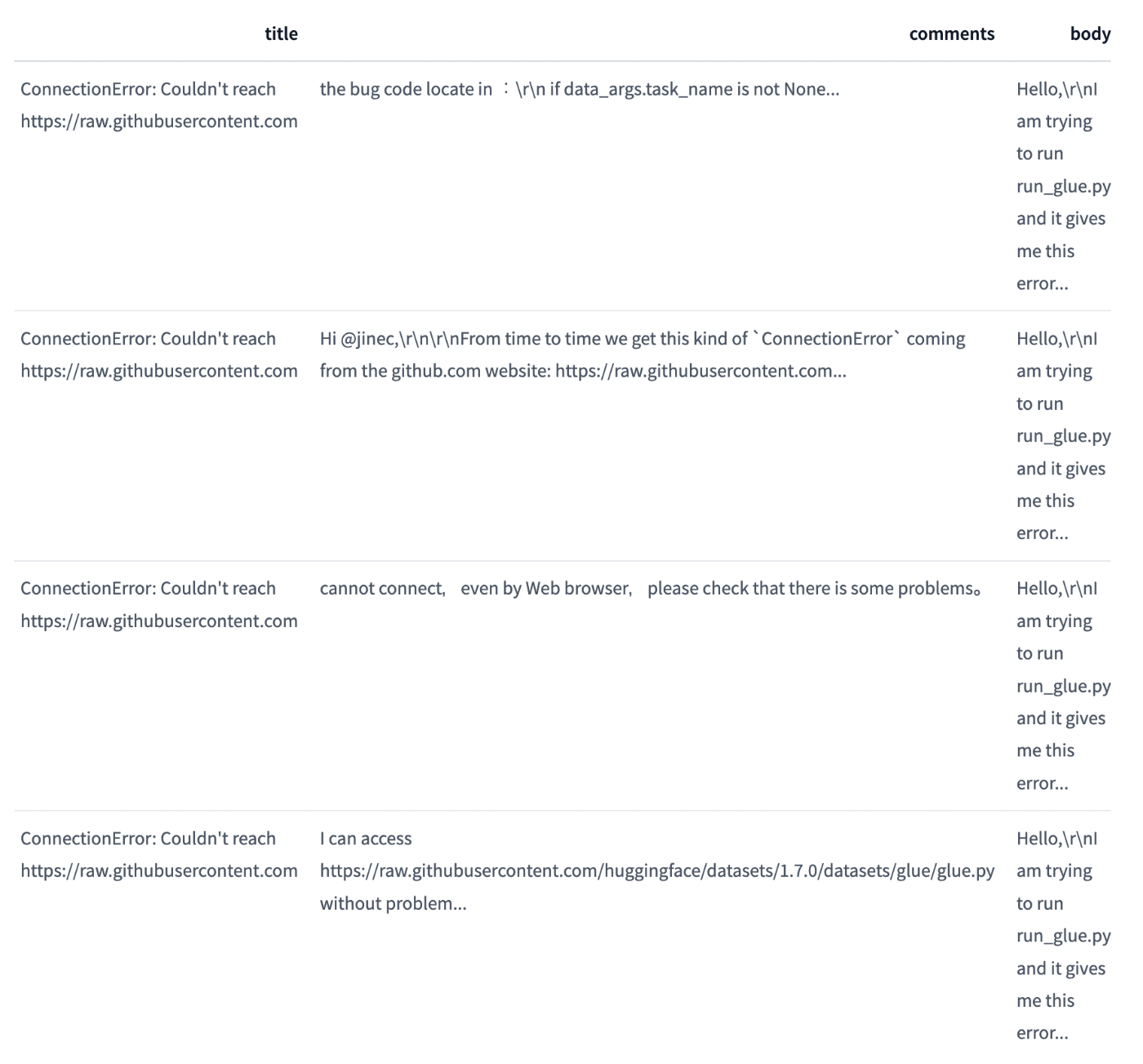
['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
'cannot connect,even by Web browser,please check that there is some problems。',
'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
comments配列を行に展開。
comments_df = df.explode("comments", ignore_index=True)
comments_df.head(4)
datasetに戻す。
from datasets import Dataset
comments_dataset = Dataset.from_pandas(comments_df)
comments_dataset
Dataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 2842
})
pandasにしなくてもDatasetのBatch mappingという機能を使ってもできるらしい。
comment_length列を追加。
comments_dataset = comments_dataset.map(
lambda x: {"comment_length": len(x["comments"].split())}
)
短いcommentの行を削除。
comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
comments_dataset
Dataset({
features: ['html_url', 'title', 'comments', 'body', 'comment_length'],
num_rows: 2098
})
3つの列を連結した新たな列を追加。
def concatenate_text(examples):
return {
"text": examples["title"]
+ " \n "
+ examples["body"]
+ " \n "
+ examples["comments"]
}
comments_dataset = comments_dataset.map(concatenate_text)
Creating text embeddings
エンべディングに特化したsentence-transformersを使う。
from transformers import AutoTokenizer, AutoModel
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
GPUで行う。
import torch
device = torch.device("cuda")
model.to(device)
[CLS] tokenの隠れ層の値を取る。
def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0]
関数定義。
def get_embeddings(text_list):
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="pt"
)
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output)
使い方の例。
embedding = get_embeddings(comments_dataset["text"][0])
embedding.shape
torch.Size([1, 768])
エンべディング列の追加。
FAISSのためにnumpy形式にしていることに注意。
embeddings_dataset = comments_dataset.map(
lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
)
Using FAISS for efficient similarity search
datasetにFAISSインデックスを作成する。
embeddings_dataset.add_faiss_index(column="embeddings")
質問のエンべディングを取得。
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).cpu().detach().numpy()
question_embedding.shape
torch.Size([1, 768])
最も近いドキュメントを取得する。
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)
確認。
for _, row in samples_df.iterrows():
print(f"COMMENT: {row.comments}")
print(f"SCORE: {row.scores}")
print(f"TITLE: {row.title}")
print(f"URL: {row.html_url}")
print("=" * 50)
print()
"""
COMMENT: Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.
@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
SCORE: 25.505046844482422
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)
You can now use them offline
\`\`\`python
datasets = load_dataset("text", data_files=data_files)
\`\`\`
We'll do a new release soon
SCORE: 24.555509567260742
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.
Let me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :)
I already note the "freeze" modules option, to prevent local modules updates. It would be a cool feature.
----------
> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
Indeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.
For example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do
\`\`\`python
load_dataset("./my_dataset")
\`\`\`
and the dataset script will generate your dataset once and for all.
----------
About I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.
cf #1724
SCORE: 24.14896583557129
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: > here is my way to load a dataset offline, but it **requires** an online machine
>
> 1. (online machine)
>
> ```
>
> import datasets
>
> data = datasets.load_dataset(...)
>
> data.save_to_disk(/YOUR/DATASET/DIR)
>
> ```
>
> 2. copy the dir from online to the offline machine
>
> 3. (offline machine)
>
> ```
>
> import datasets
>
> data = datasets.load_from_disk(/SAVED/DATA/DIR)
>
> ```
>
>
>
> HTH.
SCORE: 22.893993377685547
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: here is my way to load a dataset offline, but it **requires** an online machine
1. (online machine)
\`\`\`
import datasets
data = datasets.load_dataset(...)
data.save_to_disk(/YOUR/DATASET/DIR)
\`\`\`
2. copy the dir from online to the offline machine
3. (offline machine)
\`\`\`
import datasets
data = datasets.load_from_disk(/SAVED/DATA/DIR)
\`\`\`
HTH.
SCORE: 22.406635284423828
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
"""
Discussion