225行のコードでGPTの仕組みを理解する
概要
LLMに関心があり、ChatGPTやtransformerの仕組みを理解したいと思っていたところ、雰囲気を掴むのにこちらの動画がとても参考になりました。
動画の内容としては、以下のコーパスを学習して、直前の数文字から次の1文字(単語ではないことに注意)予測機を作成するというものです。
この動画で完成するコードは以下で、225行しかなくとても読みやすいです。
また短いですがtransformerのエッセンスが詰まっていて勉強になりそうです。
このコードを読み解くことでGPTやtransformerがどのように動いているのか、ざっくり理解してみようと思います。
ちなみに完成するとこんな感じの文字列が生成されます。ぱっと見文章っぽいですね。
first Scitizen:
He's enough; but he cannot give his friends.
MARCIUS:
Do you almost testiment dew--you, goddfish!
SICINIUS:
What peradvised
Bruised them?
MENENIUS:
Sir, they kneel,
That's a business of the stirs.
SICINIUS:
They we have lasted utmosters: but Marcius
Is a put on your table and form your eddesires;
But now yet yet I give,--you will teny against
will theirtestime yet.
First Senator:
They were twenty-jeant, solemns, saints like.
BRUTUS:
How!
SICINIUS:
Halt nemies their false o
コード解説
キャラクターのエンコード、デコード
テキスト内の全キャラクターをIDと対応付けています。
encode: 各キャラクターをIDに変換
decode: IDを各キャラクターに変換
出来るようにします。
一般的なLLMではトーカナイザーを使って各単語をIDに変換するのですが、今回は予測がキャラクター単位なのでIDもキャラクター単位で変換しています。
print(encode("hii there"))
print(decode(encode("hii there")))
[46, 47, 47, 1, 58, 46, 43, 56, 43]
hii there
1イテレーションの処理
1バッチ分の学習を実行している部分です。
get_batch
1パッチ分の教師データと正解データを取得しています。
どんな形式なのか見てみます。
print('--- xb.shape')
print(xb.shape)
print('--- yb.shape')
print(yb.shape)
--- xb.shape
torch.Size([64, 256])
--- yb.shape
torch.Size([64, 256])
入力データは学習データする文章の一部(256文字)を抜き出してトークンIDのリストにしたものなります。
正解データも同じ形式ですが、入力データから1文字分後ろにずれていることが分かります。
print('--- xb[0]')
print(xb[0])
print('--- yb[0]')
print(yb[0])
print('--- decode(xb[0].tolist())')
print(decode(xb[0].tolist()))
print('--- decode(yb[0].tolist())')
print(decode(yb[0].tolist()))
--- xb[0]
tensor([51, 43, 50, 58, 0, 13, 40, 53, 60, 43, 1, 58, 46, 43, 1, 51, 53, 53,
52, 10, 1, 61, 43, 1, 51, 59, 57, 58, 1, 40, 43, 1, 40, 59, 56, 52,
58, 1, 44, 53, 56, 1, 63, 53, 59, 8, 0, 0, 31, 21, 15, 21, 26, 21,
33, 31, 10, 0, 26, 39, 63, 6, 1, 54, 56, 39, 63, 6, 1, 40, 43, 1,
54, 39, 58, 47, 43, 52, 58, 10, 1, 47, 44, 1, 63, 53, 59, 1, 56, 43,
44, 59, 57, 43, 1, 63, 53, 59, 56, 1, 39, 47, 42, 0, 21, 52, 1, 58,
46, 47, 57, 1, 57, 53, 1, 52, 43, 60, 43, 56, 7, 52, 43, 43, 42, 43,
42, 1, 46, 43, 50, 54, 6, 1, 63, 43, 58, 1, 42, 53, 1, 52, 53, 58,
0, 33, 54, 40, 56, 39, 47, 42, 5, 57, 1, 61, 47, 58, 46, 1, 53, 59,
56, 1, 42, 47, 57, 58, 56, 43, 57, 57, 8, 1, 14, 59, 58, 6, 1, 57,
59, 56, 43, 6, 1, 47, 44, 1, 63, 53, 59, 0, 35, 53, 59, 50, 42, 1,
40, 43, 1, 63, 53, 59, 56, 1, 41, 53, 59, 52, 58, 56, 63, 5, 57, 1,
54, 50, 43, 39, 42, 43, 56, 6, 1, 63, 53, 59, 56, 1, 45, 53, 53, 42,
1, 58, 53, 52, 45, 59, 43, 6, 0, 25, 53, 56, 43, 1, 58, 46, 39, 52,
1, 58, 46, 43], device='cuda:0')
--- yb[0]
tensor([43, 50, 58, 0, 13, 40, 53, 60, 43, 1, 58, 46, 43, 1, 51, 53, 53, 52,
10, 1, 61, 43, 1, 51, 59, 57, 58, 1, 40, 43, 1, 40, 59, 56, 52, 58,
1, 44, 53, 56, 1, 63, 53, 59, 8, 0, 0, 31, 21, 15, 21, 26, 21, 33,
31, 10, 0, 26, 39, 63, 6, 1, 54, 56, 39, 63, 6, 1, 40, 43, 1, 54,
39, 58, 47, 43, 52, 58, 10, 1, 47, 44, 1, 63, 53, 59, 1, 56, 43, 44,
59, 57, 43, 1, 63, 53, 59, 56, 1, 39, 47, 42, 0, 21, 52, 1, 58, 46,
47, 57, 1, 57, 53, 1, 52, 43, 60, 43, 56, 7, 52, 43, 43, 42, 43, 42,
1, 46, 43, 50, 54, 6, 1, 63, 43, 58, 1, 42, 53, 1, 52, 53, 58, 0,
33, 54, 40, 56, 39, 47, 42, 5, 57, 1, 61, 47, 58, 46, 1, 53, 59, 56,
1, 42, 47, 57, 58, 56, 43, 57, 57, 8, 1, 14, 59, 58, 6, 1, 57, 59,
56, 43, 6, 1, 47, 44, 1, 63, 53, 59, 0, 35, 53, 59, 50, 42, 1, 40,
43, 1, 63, 53, 59, 56, 1, 41, 53, 59, 52, 58, 56, 63, 5, 57, 1, 54,
50, 43, 39, 42, 43, 56, 6, 1, 63, 53, 59, 56, 1, 45, 53, 53, 42, 1,
58, 53, 52, 45, 59, 43, 6, 0, 25, 53, 56, 43, 1, 58, 46, 39, 52, 1,
58, 46, 43, 1], device='cuda:0')
--- decode(xb[0].tolist())
melt
Above the moon: we must be burnt for you.
SICINIUS:
Nay, pray, be patient: if you refuse your aid
In this so never-needed help, yet do not
Upbraid's with our distress. But, sure, if you
Would be your country's pleader, your good tongue,
More than the
--- decode(yb[0].tolist())
elt
Above the moon: we must be burnt for you.
SICINIUS:
Nay, pray, be patient: if you refuse your aid
In this so never-needed help, yet do not
Upbraid's with our distress. But, sure, if you
Would be your country's pleader, your good tongue,
More than the
model(xb, yb)
モデルに学習データを食わせます。
ここは後ほど深掘りしていきます。
パラメータの更新
パラメータの更新部分です。
GPTLanguageModel.forward
logits, loss = model(xb, yb)
で呼び出されるのが上記のコードブロックになります。
ここでtransoformerの機構が使われていますので、細かく見ていきます。

有名なこちらの図と照らし合わせて見ていきたいと思います。
注意する点として、今回の実装ではこの図の右半分しか実装していません。
この図は元々翻訳タスク(英語 > ドイツ語等)を行うためのもので、左側は翻訳元(英語)の文章の意味を抽出するための仕組みになるためです。
その他、細かいところが異なると思いますが、概要を掴むのが目的なので気にせず読み進めていきます。
token_embedding_table

こちらは各トークンIDを384次元のベクトルに変換しています。
トークンID自体は意味を持たない数字でしかないので、それぞれに高次元のベクトルを割り当てています。
また割り当てられるベクトルは学習が進むごとに更新されていきます。
print('--- idx')
print(idx.shape)
print('--- tok_emb')
print(tok_emb.shape)
print('--- idx[0]')
print(idx[0])
print('--- tok_emb[0]')
print(tok_emb[0])
--- idx
torch.Size([64, 256])
--- tok_emb
torch.Size([64, 256, 384])
--- idx[0]
tensor([ 6, 1, 58, 46, 39, 58, 1, 61, 47, 58, 46, 1, 52, 53, 1, 51, 39, 52,
1, 46, 43, 56, 43, 1, 46, 43, 1, 47, 57, 1, 53, 44, 44, 43, 52, 42,
43, 42, 11, 0, 18, 53, 56, 6, 1, 61, 43, 56, 43, 1, 46, 43, 6, 1,
46, 43, 1, 46, 39, 42, 1, 57, 46, 53, 61, 52, 1, 47, 58, 1, 47, 52,
1, 46, 47, 57, 1, 50, 53, 53, 49, 57, 8, 0, 0, 16, 17, 30, 14, 37,
10, 0, 21, 1, 54, 56, 39, 63, 1, 19, 53, 42, 1, 46, 43, 1, 40, 43,
1, 52, 53, 58, 6, 1, 21, 1, 57, 39, 63, 8, 0, 0, 19, 24, 27, 33,
15, 17, 31, 32, 17, 30, 10, 0, 21, 1, 54, 56, 39, 63, 1, 63, 53, 59,
1, 39, 50, 50, 6, 1, 58, 43, 50, 50, 1, 51, 43, 1, 61, 46, 39, 58,
1, 58, 46, 43, 63, 1, 42, 43, 57, 43, 56, 60, 43, 0, 32, 46, 39, 58,
1, 42, 53, 1, 41, 53, 52, 57, 54, 47, 56, 43, 1, 51, 63, 1, 42, 43,
39, 58, 46, 1, 61, 47, 58, 46, 1, 42, 43, 60, 47, 50, 47, 57, 46, 1,
54, 50, 53, 58, 57, 0, 27, 44, 1, 42, 39, 51, 52, 43, 42, 1, 61, 47,
58, 41, 46, 41, 56, 39, 44, 58, 6, 1, 39, 52, 42, 1, 58, 46, 39, 58,
1, 46, 39, 60], device='cuda:0')
--- tok_emb[0]
tensor([[-0.0024, 0.0036, 0.0290, ..., -0.0079, -0.0202, -0.0204],
[ 0.0225, 0.0141, -0.0023, ..., -0.0121, -0.0025, 0.0082],
[-0.0141, -0.0081, 0.0103, ..., 0.0032, 0.0105, 0.0184],
...,
[ 0.0050, -0.0149, -0.0142, ..., 0.0073, -0.0135, 0.0106],
[ 0.0212, -0.0064, 0.0182, ..., 0.0088, -0.0050, -0.0086],
[-0.0241, -0.0017, -0.0048, ..., 0.0275, -0.0060, 0.0217]],
device='cuda:0', grad_fn=<SelectBackward0>)
position_embedding_table
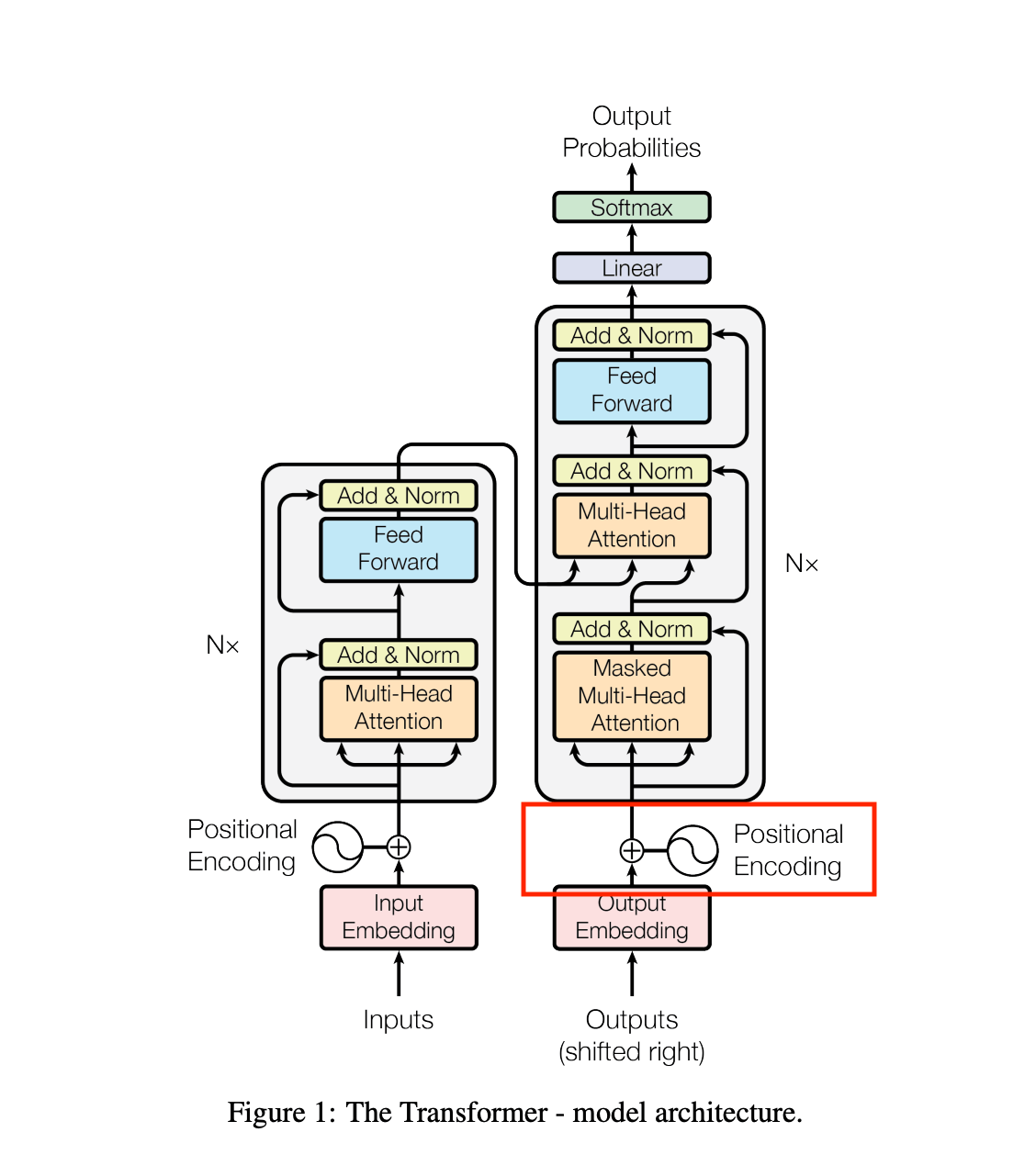
こちらは256文字の内、何文字目であるかのインデックス(0〜255)を384次元のベクトルに変換しています。
詳細はわかりませんが、ポジショナルエンコーディングは何文字目の情報を処理しているかを意識するために必要な処理だそうです。
print('--- torch.arange(T, device=device)')
print(torch.arange(T, device=device))
print('--- pos_emb.shape')
print(pos_emb.shape)
print('--- pos_emb')
print(pos_emb)
--- torch.arange(T, device=device)
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27,
28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41,
42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55,
56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69,
70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83,
84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97,
98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111,
112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125,
126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139,
140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153,
154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167,
168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181,
182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195,
196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209,
210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223,
224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237,
238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251,
252, 253, 254, 255], device='cuda:0')
--- pos_emb.shape
torch.Size([256, 384])
--- pos_emb
tensor([[-0.0072, 0.0685, -0.0572, ..., 0.0305, 0.0111, -0.0062],
[-0.0111, 0.0198, 0.0383, ..., 0.0420, 0.0067, 0.0042],
[ 0.0095, -0.0011, -0.0168, ..., 0.0379, 0.0031, 0.0298],
...,
[-0.0156, 0.0276, 0.0194, ..., -0.0112, -0.0139, -0.0145],
[ 0.0252, -0.0054, -0.0142, ..., 0.0090, -0.0353, 0.0151],
[ 0.0373, -0.0098, 0.0025, ..., -0.0237, -0.0104, 0.0180]],
device='cuda:0', grad_fn=<EmbeddingBackward0>)
x = tok_emb + pos_emb
各入力レコードに対してポジショナルエンコーディングを加算しています(ブロードキャストされます)
blocks
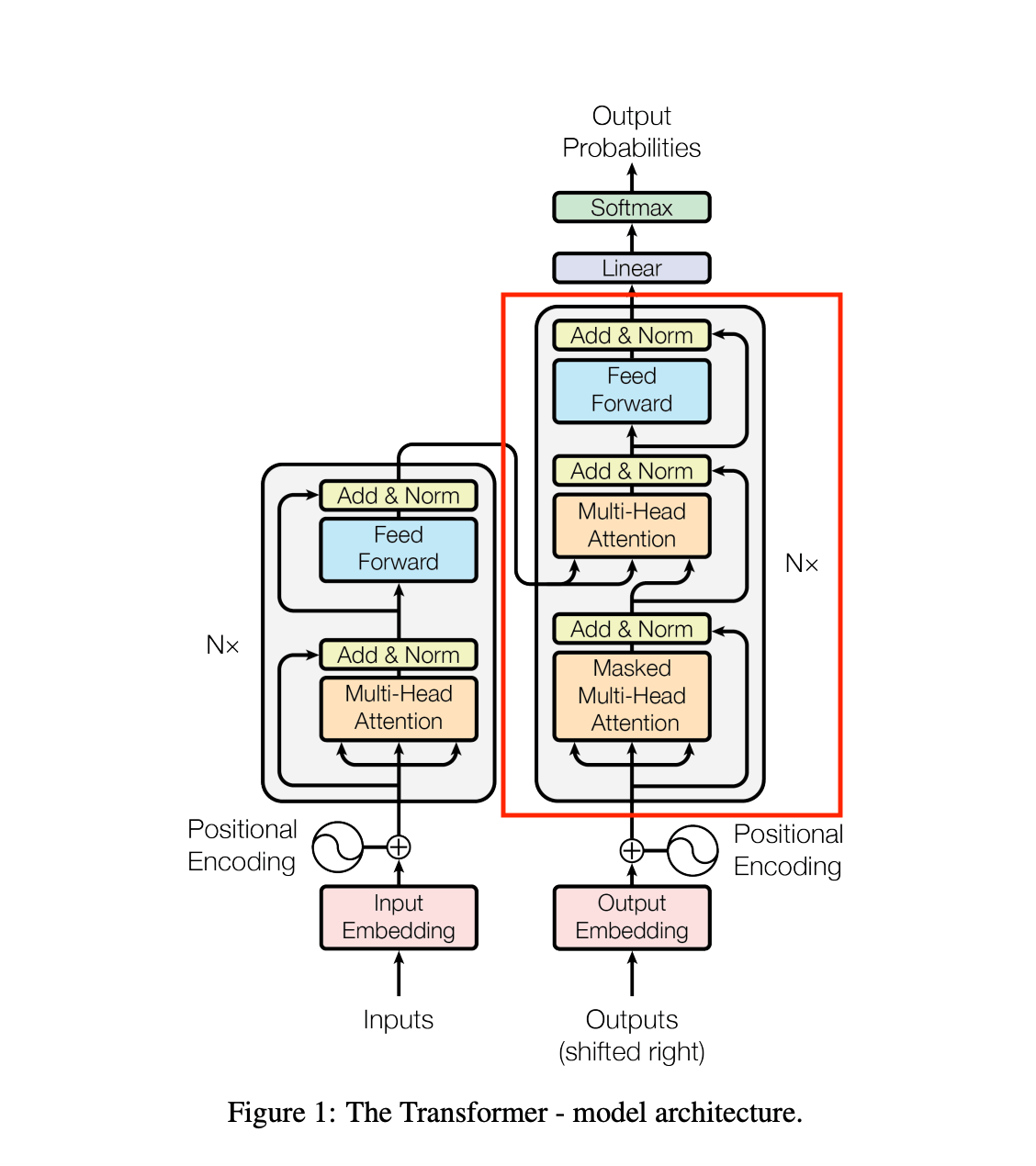
ここでBlockモジュールを6回通します。
ここも重要なので後ほど深掘りします。
ちなみにblocksは配列ここで定義されています。
ln_f
Blockモジュールに通した結果をLayerNormを通してベクトルを平均 0、分散 1 になるよう正規化します。
lm_head
384次元のベクトルを全キャラクター数(vocab_size(65))の次元に変換します。
65個がそれぞれの全キャラクターに対する予測の重みを意味しており、大きい値ほど選択され易くなります。
print('--- logits.shape')
print(logits.shape)
print('--- logits[0]')
print(logits[0])
--- logits.shape
torch.Size([64, 256, 65])
--- logits[0]
tensor([[ 0.3897, 0.1134, -0.5976, ..., -0.5016, 0.1591, -0.6334],
[ 0.2609, -0.1166, -0.8210, ..., 0.2169, -0.2785, -0.8169],
[ 0.3941, 0.4938, -0.5984, ..., 0.1972, -0.0942, -0.5661],
...,
[-0.0101, 0.9814, -0.6285, ..., 0.3076, 0.1975, 0.1760],
[-0.1761, -0.2355, -0.6425, ..., -0.4831, 0.2573, -0.2717],
[-0.0799, -0.2604, -1.2345, ..., -0.1206, -0.0410, 0.3234]],
device='cuda:0', grad_fn=<SelectBackward0>)
lossの算出
バッチ内の入力データと正解データをフラット化してクロスエントロピーで損失を計算します。
Block.forward
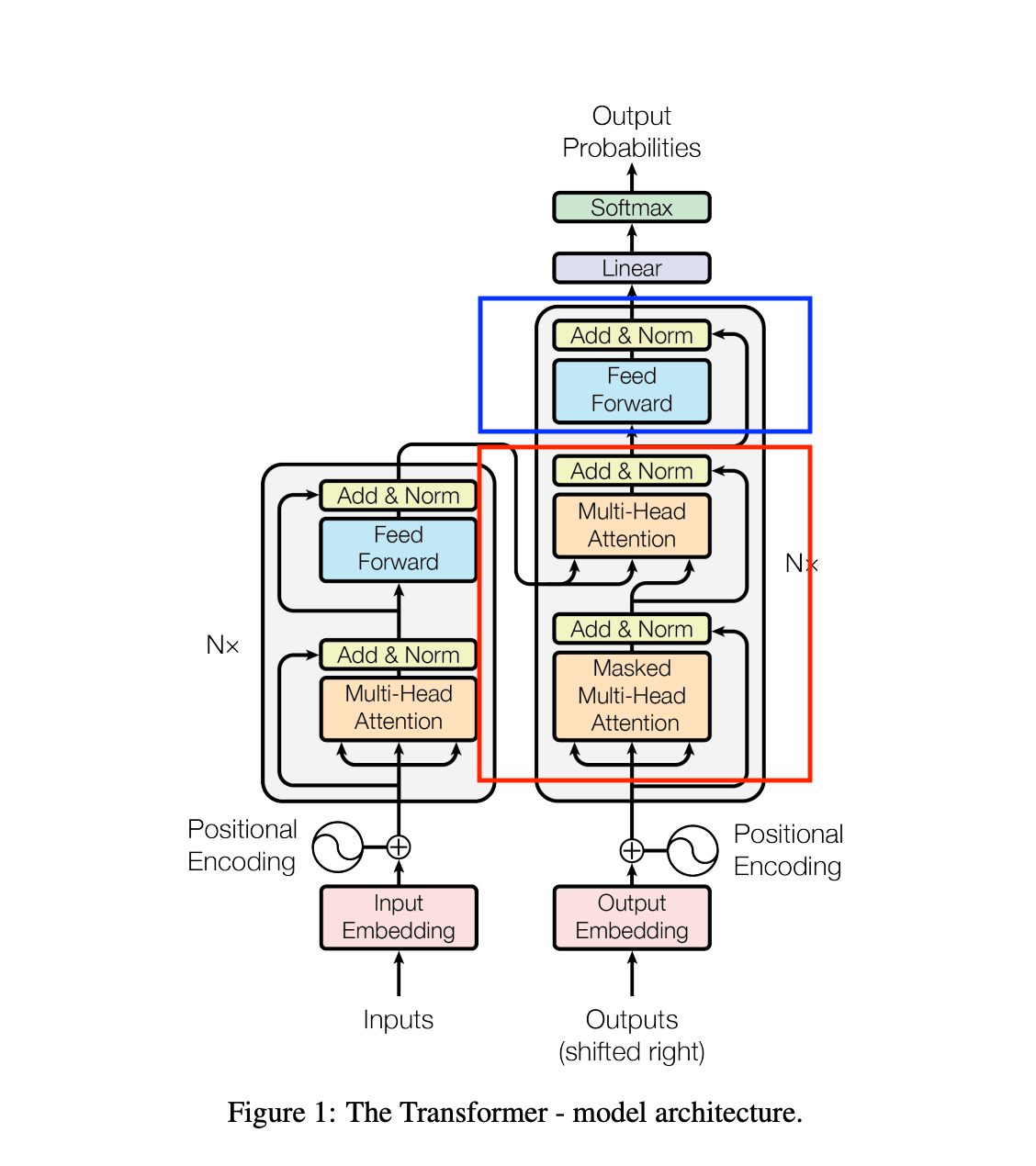
xは
torch.Size([64, 256, 384])
の、384次元にエンべディングされた各キャラクターです。
LayerNormを通してベクトルを平均 0、分散 1 になるよう正規化した後、MultiHeadAttentionモジュールに渡します。
※赤で囲った部分。
その後同様にLayerNormを通した後、FeedFowardモジュールに渡します。
※青で囲った部分。
FeedFowardモジュールは以下のモジュールを繋いだものです。
注意点として例の図とは異なる部分がいくつあります。
図では赤字の部分の中に2セットMultiHeadAttentionを通す処理が入っていますが、この実装では1セットだけ行っています。
また図では入力を最初にMultiHeadAttentionモジュール、FeedFowardモジュールに渡して、その後加算、ノーマライズしていますが、この実装ではそれぞれをノーマライズした後で各モジュールに渡してその後加算しています。
MultiHeadAttention.forward


ここからが重要そうなところです。
6つのHeadモジュールに対して、xを渡しそれらをconcatしています。
各Headは
で計算した、
384次元/ヘッド数6 => head_size64次元
のベクトルに圧縮して返してきます。
それをヘッド数6個分concatするので結局384次元に戻ります。
同じ仕組みの6このHeadモジュールに対して(直列ではなく)並列に推測させ、
それぞれが小さい次元数の結果を返し、最後に結果をガッチャンコして元の次元数に戻しています。
その後は線形結合してドロップアウトがかませてあります。
Head.forward


各ヘッドが何をやっているのか見ていきます。
query、key
xは
torch.Size([64, 256, 384])
ですが、それぞれ線形結合して各キャラクターの情報をhead_size 64次元のベクトルに変換します。
torch.Size([64, 256, 64])
動画内では
queryベクトル(q) 各キャラクターがどのキャラクターに注目しているかを表現します。
keyベクトル(k) 各キャラクターがどんな情報を含んでいるかを表現します。
と解説されていました。
q、転置kの内積とスケーリング

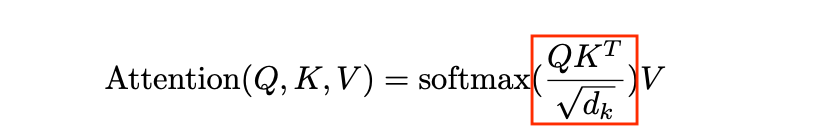
赤枠部分の実装です。
q @ k.transpose(-2,-1)
はバッチサイズを除くと
q([256, 64]) と kの転置行列([64, 256])の内積になります。
各キャラクターに対応する64次元ベクトルの類似度を表現しているものと考えると良いそうです。
※詳しくは下で紹介している参考動画を参照してください。
得られる配列は
wei([256, 256])
の行列となり、これが各キャラクターが他のどのキャラクターに注目しているかの重みを表す行列になります。
また、内積はスケールが大きくなりすぎるためhead_size 64次元の平方根で割るそうです。
wei.masked_fill
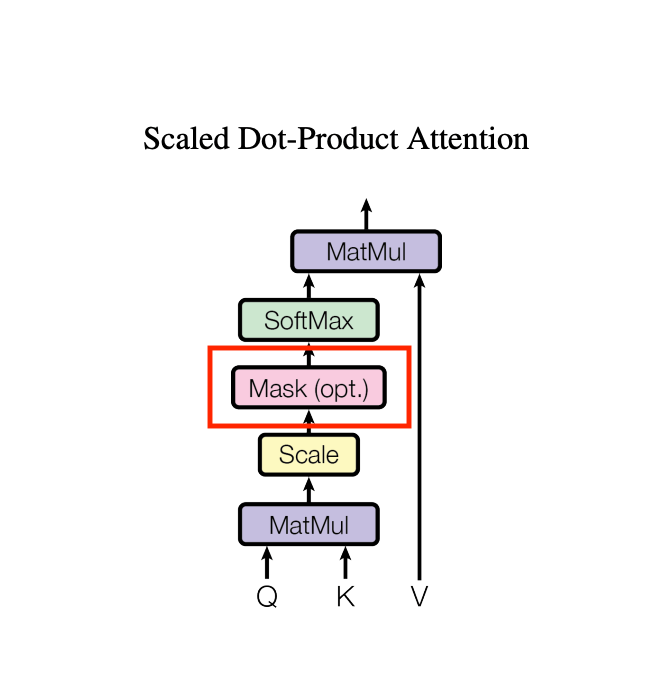 256×256で表現される各キャラクターごとの注目情報に対して、自分自身の後ろのキャラクターの情報を参照しないようにマスクをかけています。
256×256で表現される各キャラクターごとの注目情報に対して、自分自身の後ろのキャラクターの情報を参照しないようにマスクをかけています。
print('--- wei.shape')
print(wei.shape)
print('--- wei[0]')
print(wei[0])
--- wei.shape
torch.Size([64, 256, 256])
--- wei[0]
tensor([[-0.2827, -inf, -inf, ..., -inf, -inf, -inf],
[-0.3088, -0.1272, -inf, ..., -inf, -inf, -inf],
[-0.1293, 0.0330, 0.1038, ..., -inf, -inf, -inf],
...,
[-0.0974, 0.0767, 0.0441, ..., 0.0212, -inf, -inf],
[-0.2979, -0.1289, -0.1425, ..., -0.1636, -0.0733, -inf],
[-0.2993, -0.0510, -0.0373, ..., -0.1200, -0.0942, -0.0695]],
device='cuda:0', grad_fn=<SelectBackward0>)
F.softmax
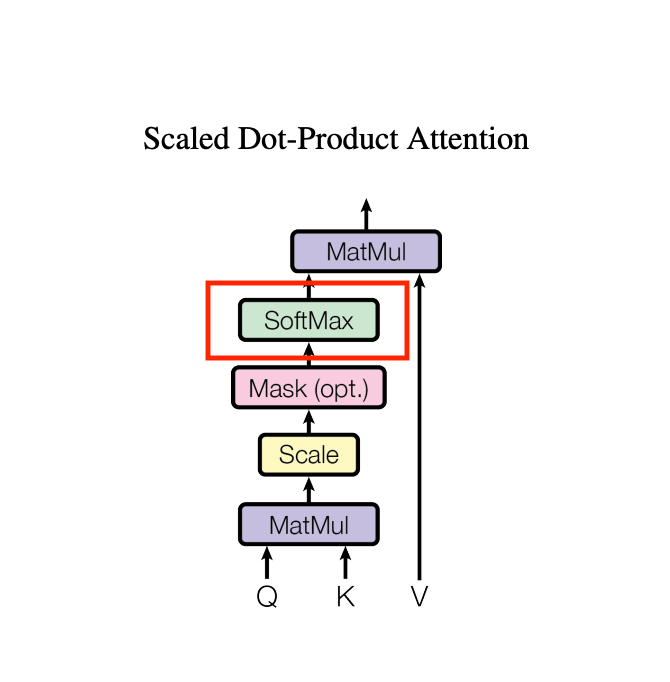 ここで重みをsoftmaxしてならします。
ここで重みをsoftmaxしてならします。
dropout
過学習防止のためだと思います。
valueとの内積を取る
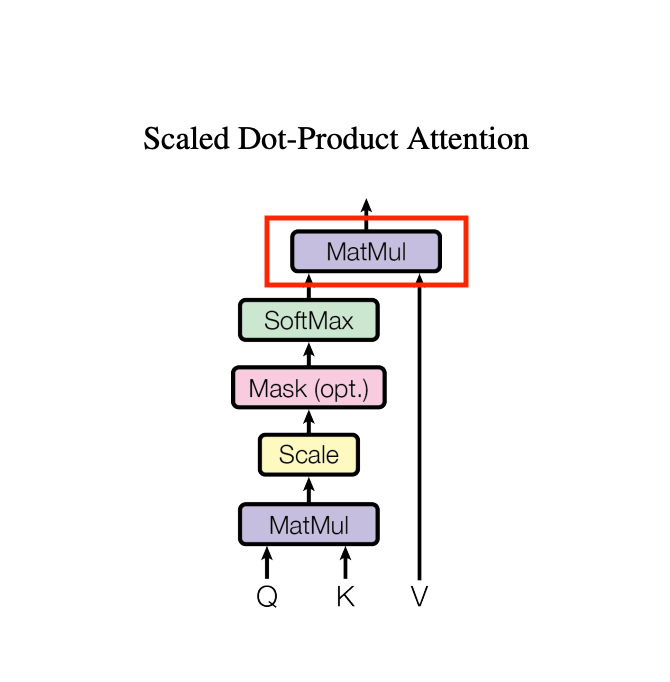
xを線形結合して各キャラクターの情報をhead_size 64次元のベクトルvに変換します。
torch.Size([64, 256, 64])
各キャラクターが他のキャラクターの成分を重みの割合で取得し合算します。
GPTLanguageModel.generate
実際に文字を指定文字数分予測していく処理になります。
max_new_tokens(予測したい文字数)分ループしています。
以下のように呼び出されます。
今回の呼ばれ方では最初の1文字だけが渡されます。
0はデコードしてみると改行文字となります。改行文字から続く500文字生成するという呼び出し方になります。
print('--- context')
print(context)
--- context
tensor([[0]], device='cuda:0')
idx_cond
現在生成中の文字列の末尾からバッチサイズ分抽出しています。
print('--- idx_cond.shape')
print(idx_cond.shape)
print('--- idx_cond')
print(idx_cond)
--- idx_cond.shape
torch.Size([1, 256])
--- idx_cond
tensor([[10, 57, 43, 58, 1, 43, 57, 33, 41, 6, 39, 61, 58, 39, 40, 4, 47, 46,
44, 58, 61, 45, 0, 6, 10, 51, 46, 19, 4, 50, 16, 0, 44, 39, 58, 1,
1, 63, 45, 15, 57, 36, 39, 27, 12, 44, 43, 52, 17, 1, 43, 38, 45, 43,
51, 56, 59, 64, 1, 57, 19, 15, 6, 25, 43, 40, 4, 0, 53, 45, 40, 51,
58, 38, 56, 9, 43, 46, 42, 43, 43, 49, 52, 1, 43, 46, 30, 43, 47, 59,
50, 39, 4, 47, 43, 43, 28, 6, 52, 53, 8, 43, 44, 58, 52, 50, 54, 1,
0, 6, 62, 47, 56, 41, 53, 7, 43, 53, 51, 28, 39, 57, 57, 8, 29, 48,
1, 56, 42, 34, 52, 53, 34, 43, 1, 47, 30, 7, 17, 44, 33, 24, 2, 1,
10, 40, 58, 45, 59, 43, 0, 27, 43, 43, 54, 46, 59, 37, 27, 42, 11, 39,
29, 49, 4, 58, 64, 57, 26, 32, 43, 18, 23, 35, 56, 53, 15, 59, 47, 56,
56, 1, 58, 1, 40, 42, 43, 53, 61, 51, 59, 48, 50, 0, 58, 26, 59, 1,
44, 57, 53, 47, 24, 43, 63, 25, 48, 29, 46, 43, 47, 43, 45, 57, 26, 33,
21, 13, 11, 43, 53, 43, 15, 3, 47, 34, 10, 17, 44, 57, 43, 16, 28, 34,
57, 46, 43, 56, 56, 1, 58, 56, 51, 63, 57, 31, 31, 26, 39, 43, 43, 38,
56, 56, 44, 43]], device='cuda:0')
self(idx_cond)
モデルの呼び出し。
logits[:, -1, :]
渡した文字列の最後の文字に対しての予測結果だけを抽出しています。
softmax
予測結果をソフトマックス関数にかけます。
torch.multinomial
予測結果の重みを見て1文字を抽選します。
chatgptなどで予測する際に使うtemperatureパラメータはこの辺りの処理に影響してきそうです。
例えばtemperature=0ならランダムに抽選するのではなく重みが最大のものを取得する処理になりそうです。
torch.cat
予測した文字を行列の最後に追加します。
まとめ
論文の数式を見ているとかなり難しく感じますが、コードで見ると意外と読めるんだなと感じました。
またなぜこのようにモデルが組まれているのか、少しだけ理解できた気もします。
transformerを学ぶに辺り、以下の動画もとてもためになりました。
めちゃくちゃわかりやすいのでおすすめです。
Discussion