Hugging Face NLP Course - 7. MAIN NLP TASKS 前編
概要
の要点纏め。
前編。
Token classification
「文章中の各トークンにラベルを付与する」タスク。
例えば以下のようなタスクがある。
Named entity recognition (NER): 文中のエンティティ(人物、場所、組織など)を見つける。
Part-of-speech tagging (POS): 文中の各単語を特定の品詞(名詞、動詞、形容詞など)に対応する。
Chunking: 同じエンティティに属するトークンを見つける。通常はチャンクの先頭のトークンにB-内側のトークンにI-それ以外のトークンにOをつける。POSまたはNERと組み合わせることもできる。
以下のチャプターではNER taskでBERTをファインチューニングし、以下のようなフォームを作成する。
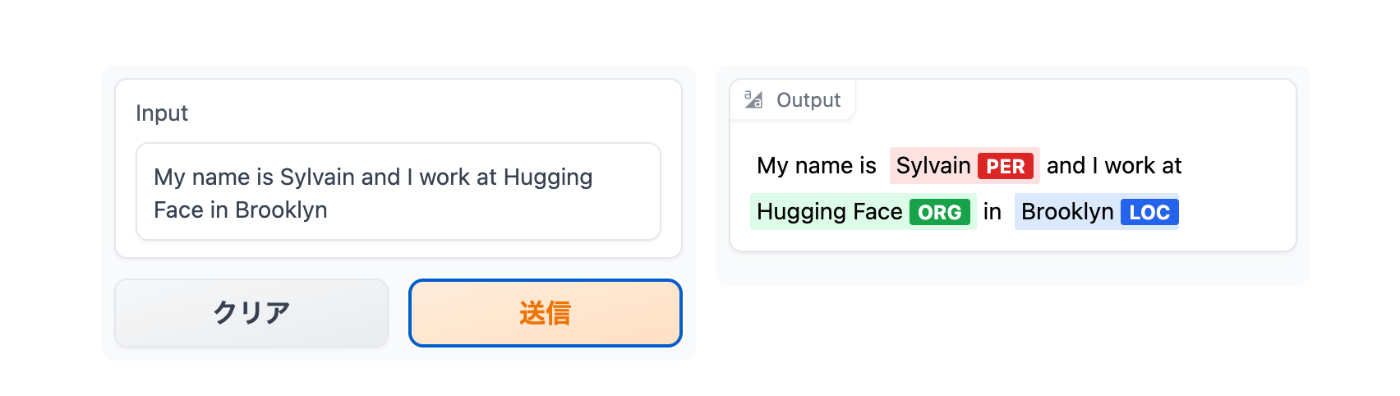
作成したモデルの例はこちら。
Preparing the data
ロイターのニュース記事を含むCoNLL-2003データセットを使用する。
The CoNLL-2003 dataset
データセットのロード。
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})
他のデータセットとの大きな違いは、入力テキストが文や文書としてではなく、単語のリストとして存在すること。
raw_datasets["train"][0]["tokens"]
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
NER タグを確認。
raw_datasets["train"][0]["ner_tags"]
[3, 0, 7, 0, 0, 0, 7, 0, 0]
ラベルとタグの対応を見てみる。
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_feature
Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
label_names = ner_feature.feature.names
label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
O means the word doesn’t correspond to any entity.
B-PER/I-PER means the word corresponds to the beginning of/is inside a person entity.
B-ORG/I-ORG means the word corresponds to the beginning of/is inside an organization entity.
B-LOC/I-LOC means the word corresponds to the beginning of/is inside a location entity.
B-MISC/I-MISC means the word corresponds to the beginning of/is inside a miscellaneous entity.
デコードして並べてみる。
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)
'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'
別の文の例。
“European Union” “Werner Zwingmann” にI-が入っている。
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
Processing the data
一般的な言語モデルではテキストをトークンIDに変換する必要があるが。token classificationの場合は予めトークンIDが準備されている。
tokenizer APIで対応できる。。
まずはtokenizerを作成する。
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
Tokenizers libraryによってバックアップされている物を使う必要がある。
その場合“fast”バージョンが利用可能になる。
is_fast属性を見て確認する。
tokenizer.is_fast
True
トークン化済みの入力をトーカナイズするには、is_split_into_words=Trueを指定する。
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()
['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
スペシャルトークンが追加されたとと、"lamb"が分割されたため、ラベルの個数とのミスマッチが生じる。
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
分割されたトークンにラベルを割り当てる関数。
※スペシャルトークンには-100を割り当てることで損失関数に無視させる。
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Start of a new word!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Special token
new_labels.append(-100)
else:
# Same word as previous token
label = labels[word_id]
# If the label is B-XXX we change it to I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labels
変換を行う。
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))
[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
1つの単語に対して1つのラベルしか付けず、与えられた単語内の他のサブトークンには-100を付けることを好む人もいる。
データセットのすべての入力をトークン化し、align_labels_with_tokensを適応する。
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputs
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)
Fine-tuning the model with the Trainer API
Data collation
labelsのパディングに対応していないため、今回はDataCollatorWithPaddingは使えない。
今回はDataCollatorForTokenClassificationを使用する。
またパディングは-100で行われる。
動作確認。
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]
tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
パディングしない場合も見てみる。
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]
Metrics
Trainerにエポックごとにメトリックを計算させる。
token classificationの評価に使われるseqevalライブラリを使用する。
!pip install seqeval
import evaluate
metric = evaluate.load("seqeval")
ラベルをstringにデコードする必要がある。
データセットのラベルを見てみる。
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels
['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
仮の予測値を作成し評価してみる。
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}
compute_metricsメソッド。
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}
Defining the model
AutoModelForTokenClassificationの作成。
ラベルの数としてnum_labelsを渡しても良いが、id2label、label2idのマッピングを渡す方が良い。
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)
モデルがラベル数を認識しているか確認。
model.config.num_labels
9
Fine-tuning the model
ログイン。
from huggingface_hub import notebook_login
notebook_login()
または
huggingface-cli login
TrainingArgumentsを作成。
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)
訓練する。
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()
トレーニングが完了したらpushする。
trainer.push_to_hub(commit_message="Training complete")
A custom training loop
全体のトレーニングループを見てみる。
Preparing everything for training
data_loaderの作成。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)
modelの作成。
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)
optimizerの設定。
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
Acceleratorの設定。
※TPUで学習する場合は若干コードが異なる。
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
学習スケジューラの設定。
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
modelをpushするためにRepositoryオブジェクトを作成する。
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name
'sgugger/bert-finetuned-ner-accelerate'
まだ無ければリポジトリをローカルにcloneする。
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
Training loop
メトリックを評価するためpostprocessを作成する。
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictions
トレーニングループの作成。
accelerator.pad_across_processes()
を使って予測とラベルを同じ形にする必要がある。
push_to_hubのblocking=Falseで非同期にpushすることができる。
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# Necessary to pad predictions and labels for being gathered
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)
以下の3行の解説。
# すべてのプロセスがその段階になるまで待っている。
accelerator.wait_for_everyone()
# 分散しているステップを元に戻す。
unwrapped_model = accelerator.unwrap_model(model)
# torch.save() のかわりにこちらを使う。
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
Using the fine-tuned model
訓練したモデルを使ってみる。
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
Fine-tuning a masked language model
事前に訓練された言語モデルのヘッドを訓練する前に、ドメイン内データでファインチューニングすることをdomain adaptationと呼ぶ。
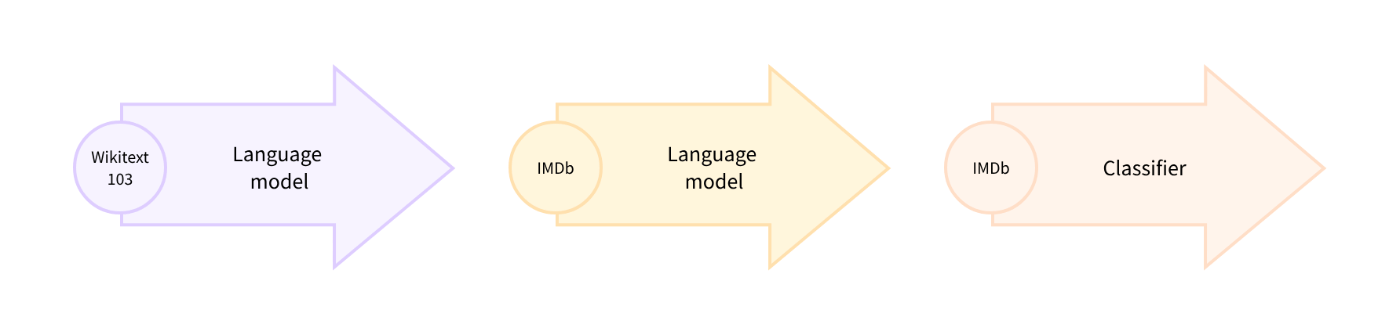
以下の様なタスクを行う。

Picking a pretrained model for masked language modeling
knowledge distillation(知識蒸留)によって訓練された少ないパラメータかつ高性能なモデル、DistilBERTを使用する。
from transformers import AutoModelForMaskedLM
model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
パラメータ数を見てみる。
BERTのパラメータの半分程度。学習速度は倍近くになる。
distilbert_num_parameters = model.num_parameters() / 1_000_000
print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
print(f"'>>> BERT number of parameters: 110M'")
'>>> DistilBERT number of parameters: 67M'
'>>> BERT number of parameters: 110M'
穴埋め問題のサンプル。
text = "This is a great [MASK]."
DistilBERTは
English Wikipedia
BookCorpus
データセットで訓練されている。
トーカナイザのロード。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
サンプルの穴埋めを予測してみる。
import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
# Find the location of [MASK] and extract its logits
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
# Pick the [MASK] candidates with the highest logits
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")
'>>> This is a great deal.'
'>>> This is a great success.'
'>>> This is a great adventure.'
'>>> This is a great idea.'
'>>> This is a great feat.'
The dataset
Large Movie Review Dataset(映画のレビューデータ)
データセットを使ってファインチューニングを行う。
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
imdb_dataset
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})
データの一部を確認。
Labelは
1:肯定
2:否定
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
for row in sample:
print(f"\n'>>> Review: {row['text']}'")
print(f"'>>> Label: {row['label']}'")
'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.<br /><br />Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
'>>> Label: 0'
'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.<br /><br />The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
'>>> Label: 0'
'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version. <br /><br />My 4 and 6 year old children love this movie and have been asking again and again to watch it. <br /><br />I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.<br /><br />I do not have older children so I do not know what they would think of it. <br /><br />The songs are very cute. My daughter keeps singing them over and over.<br /><br />Hope this helps.'
'>>> Label: 1'
Preprocessing the data
各テキストをトーカナイズする。
word_idsは分割されたトークンがワード単位のどのインデックスに属するか表すもの。
不要なカラムは削除する。
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Use batched=True to activate fast multithreading!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasets
DatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 50000
})
})
modelの最大コンテキストサイズを確認する。
※tokenizer_config.jsonから取得される。
tokenizer.model_max_length
512
Google Colabのメモリに収まるくらいのチャンクサイズに設定する。
chunk_size = 128
レビューごとのトークン数を確認する。
# Slicing produces a list of lists for each feature
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
print(f"'>>> Review {idx} length: {len(sample)}'")
'>>> Review 0 length: 200'
'>>> Review 1 length: 559'
'>>> Review 2 length: 192'
連結してみる。
concatenated_examples = {
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"])
print(f"'>>> Concatenated reviews length: {total_length}'")
'>>> Concatenated reviews length: 951'
chunk_sizeで分割してみる。
chunks = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]:
print(f"'>>> Chunk length: {len(chunk)}'")
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 55'
最後のチャンクは長さを揃えるために切り捨てるか、パディングを行う。
今回は切り捨てを行う。
これまでのロジックをまとめた関数。
labelsはマスクされたワードの正解としてのカラム。
def group_texts(examples):
# Concatenate all texts
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# Compute length of concatenated texts
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the last chunk if it's smaller than chunk_size
total_length = (total_length // chunk_size) * chunk_size
# Split by chunks of max_len
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# Create a new labels column
result["labels"] = result["input_ids"].copy()
return result
適応する。
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
lm_datasets
DatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 61289
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 59905
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 122963
})
})
チャンク化されたデータを確認する。
[SEP] [CLS]が1データの中にある事に注意する。
tokenizer.decode(lm_datasets["train"][1]["input_ids"])
".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
正解ラベルも見てみる。
input_idsと同じ。
input_idsは後でマスクする。
tokenizer.decode(lm_datasets["train"][1]["labels"])
Fine-tuning DistilBERT with the Trainer API
DataCollatorForLanguageModelingを使って文中の15%のトークンをマスクする。
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
data_collatorにいくつかデータを渡してみる。
ワードの中の複数トークンの内一部だけマスクされることもある。
samples = [lm_datasets["train"][i] for i in range(2)]
for sample in samples:
_ = sample.pop("word_ids")
for chunk in data_collator(samples)["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")
'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'
whole word maskingという単語単位でマスクする方法もある。
その場合collatorを自作する必要がある。
import collections
import numpy as np
from transformers import default_data_collator
wwm_probability = 0.2
def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
# Create a map between words and corresponding token indices
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# Randomly mask words
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels)
for word_id in np.where(mask)[0]:
word_id = word_id.item()
for idx in mapping[word_id]:
new_labels[idx] = labels[idx]
input_ids[idx] = tokenizer.mask_token_id
feature["labels"] = new_labels
return default_data_collator(features)
適応してみる。
samples = [lm_datasets["train"][i] for i in range(2)]
batch = whole_word_masking_data_collator(samples)
for chunk in batch["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")
'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'
時間がかかりすぎるのでデータセットをダウンサンプリングする。
train_size = 10_000
test_size = int(0.1 * train_size)
downsampled_dataset = lm_datasets["train"].train_test_split(
train_size=train_size, test_size=test_size, seed=42
)
downsampled_dataset
DatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 10000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 1000
})
})
ログイン。
from huggingface_hub import notebook_login
notebook_login()
コマンドからログインする場合。
huggingface-cli login
TrainingArgumentsの作成。
from transformers import TrainingArguments
batch_size = 64
# Show the training loss with every epoch
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb",
overwrite_output_dir=True,
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
push_to_hub=True,
fp16=True,
logging_steps=logging_steps,
)
Trainerの作成。
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=downsampled_dataset["train"],
eval_dataset=downsampled_dataset["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)
Perplexity for language models
テキスト分類や質問応答など、ラベル付きコーパスを与えられて学習する他のタスクとは異なり、言語モデリングでは明示的なラベルは無い。
テストセットのすべての文章で特定の単語に割り当てる確率を計算することで評価を行う。
ここではクロスエントロピー損失を使用する。
訓練前の評価。
import math
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 21.75
訓練する。
trainer.train()
再度評価する。
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 11.32
pushする。
trainer.push_to_hub()
Fine-tuning DistilBERT with 🤗 Accelerate
DataCollatorForLanguageModelingはランダムにマスクを行うので結果にばらつきが出る。
最初にデータセット全体にマスクをかけることで解決できる。
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
# Create a new "masked" column for each column in the dataset
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}
適応する。
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
eval_dataset = downsampled_dataset["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset["test"].column_names,
)
eval_dataset = eval_dataset.rename_columns(
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)
評価用データセットに適応する。
from torch.utils.data import DataLoader
from transformers import default_data_collator
batch_size = 64
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
eval_dataloader = DataLoader(
eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
)
Accelerateの有効化。
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
学習スケジューラーの設定。
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
リポジトリ名を作成。
from huggingface_hub import get_full_repo_name
model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name
'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'
リポジトリの作成。
from huggingface_hub import Repository
output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)
トレーニングループの作成。
from tqdm.auto import tqdm
import torch
import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size)))
losses = torch.cat(losses)
losses = losses[: len(eval_dataset)]
try:
perplexity = math.exp(torch.mean(losses))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)
Epoch 0: Perplexity: 11.397545307900472
Epoch 1: Perplexity: 10.904909330983092
Epoch 2: Perplexity: 10.729503505340409
Using our fine-tuned model
訓練済みモデルを使ってみる。
from transformers import pipeline
mask_filler = pipeline(
"fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
)
preds = mask_filler(text)
for pred in preds:
print(f">>> {pred['sequence']}")
'>>> this is a great movie.'
'>>> this is a great film.'
'>>> this is a great story.'
'>>> this is a great movies.'
'>>> this is a great character.'
Translation
文章を別の文章に変換するタスク全般。
Marian modelをKDE4 datasetを使用してファインチューニングする。
英語からフランス語への翻訳を強化する。
以下のようなモデルを作成する。

Preparing the data
The KDE4 dataset
データセットのロード。
from datasets import load_dataset
raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
raw_datasets
DatasetDict({
train: Dataset({
features: ['id', 'translation'],
num_rows: 210173
})
})
テストセットと分割。
split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
split_datasets
DatasetDict({
train: Dataset({
features: ['id', 'translation'],
num_rows: 189155
})
test: Dataset({
features: ['id', 'translation'],
num_rows: 21018
})
})
validationにリネーム。
split_datasets["validation"] = split_datasets.pop("test")
1行確認。
英語の単語をそのまま使うのではなく、しっかりフランス語に翻訳してあるデータセットであることがわかる。
split_datasets["train"][1]["translation"]
{'en': 'Default to expanded threads',
'fr': 'Par défaut, développer les fils de discussion'}
既存のモデルで翻訳してみる。
threadsという単語は英語のままになっている。
from transformers import pipeline
model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
translator = pipeline("translation", model=model_checkpoint)
translator("Default to expanded threads")
[{'translation_text': 'Par défaut pour les threads élargis'}]
pluginという英語がちゃんとフランス語に翻訳されている例。
split_datasets["train"][172]["translation"]
{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
英語がそのまま翻訳結果に入っていることを確認。
このモデルをちゃんとフランス語に翻訳されるようにファインチューニングする。
translator(
"Unable to import %1 using the OFX importer plugin. This file is not the correct format."
)
[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
Processing the data
トーカナイザのロード。
モデルのチェックポイントと合わせること。
from transformers import AutoTokenizer
model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="pt")
トーカナイズしてみる。
text_targetを指定する必要がある。
フランス語のトークンIDがlabelsの方含まれることに注意。
en_sentence = split_datasets["train"][1]["translation"]["en"]
fr_sentence = split_datasets["train"][1]["translation"]["fr"]
inputs = tokenizer(en_sentence, text_target=fr_sentence)
inputs
{'input_ids': [47591, 12, 9842, 19634, 9, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'labels': [577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]}
間違った例との比較。
トーカナイザはinputに対してフランス語を理解していない。
wrong_targets = tokenizer(fr_sentence)
print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
print(tokenizer.convert_ids_to_tokens(inputs["labels"]))
['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '</s>']
['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '</s>']
前処理関数を作成。
max_length = 128
def preprocess_function(examples):
inputs = [ex["en"] for ex in examples["translation"]]
targets = [ex["fr"] for ex in examples["translation"]]
model_inputs = tokenizer(
inputs, text_target=targets, max_length=max_length, truncation=True
)
return model_inputs
今後の処理で、attention maskは使わず、パディングトークンを-100にして処理することに注意。
前処理をデータセットに適応。
tokenized_datasets = split_datasets.map(
preprocess_function,
batched=True,
remove_columns=split_datasets["train"].column_names,
)
Fine-tuning the model with the Trainer API
TrainerのサブクラスであるSeq2SeqTrainerを使用する。
generate()メソッドを使って入力と出力を適切に評価することができる。
モデルを準備する。
※元々同様のタスクのために訓練されたモデルなのでヘッドを付け替えるときのワーニングが出ない。
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
Data collation
ラベルのパディングも行う必要があるため、DataCollatorForSeq2Seqを使用する。
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
何件かテストしてみる。
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
パディングも確認。
batch["labels"]
tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
-100, -100, -100, -100, -100, -100],
[ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
550, 7032, 5821, 7907, 12649, 0]])
decoder_input_idsを確認。
labelsが1つシフトしたもの。
batch["decoder_input_ids"]
tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
59513, 59513, 59513, 59513, 59513, 59513],
[59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
817, 550, 7032, 5821, 7907, 12649]])
データセットの確認。
for i in range(1, 3):
print(tokenized_datasets["train"][i]["labels"])
[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
Metrics
Seq2SeqTrainerのgenerate()メソッドについて。
アテンションマスク付きのdecoder_input_idsを使って、予測しようとしているトークンの後ろのトークンを使わないようにしている。
トークンを1つずつ予測することで推論を行う場合、predict_with_generate=Trueに設定する。
翻訳の指標にはBLEU scoreを使用する。
翻訳がラベルにどれだけ近いかを評価するもの。文法などは見ていない。
BLEUはテキストがすでにトークン化されていることを想定しているため、異なるトークナイザーを使用するモデル間でスコアを比較するのが難しい。
SacreBLEUを使うとトークン化のステップを標準化することができる。
!pip install sacrebleu
import evaluate
metric = evaluate.load("sacrebleu")
評価のサンプル。
うまくいった例。
predictions = [
"This plugin lets you translate web pages between several languages automatically."
]
references = [
[
"This plugin allows you to automatically translate web pages between several languages."
]
]
metric.compute(predictions=predictions, references=references)
{'score': 46.750469682990165,
'counts': [11, 6, 4, 3],
'totals': [12, 11, 10, 9],
'precisions': [91.67, 54.54, 40.0, 33.33],
'bp': 0.9200444146293233,
'sys_len': 12,
'ref_len': 13}
うまくいかなかった例。
(繰り返しが多い)
predictions = ["This This This This"]
references = [
[
"This plugin allows you to automatically translate web pages between several languages."
]
]
metric.compute(predictions=predictions, references=references)
{'score': 1.683602693167689,
'counts': [1, 0, 0, 0],
'totals': [4, 3, 2, 1],
'precisions': [25.0, 16.67, 12.5, 12.5],
'bp': 0.10539922456186433,
'sys_len': 4,
'ref_len': 13}
うまくいかなかった例。
(短すぎる)
predictions = ["This plugin"]
references = [
[
"This plugin allows you to automatically translate web pages between several languages."
]
]
metric.compute(predictions=predictions, references=references)
{'score': 0.0,
'counts': [2, 1, 0, 0],
'totals': [2, 1, 0, 0],
'precisions': [100.0, 100.0, 0.0, 0.0],
'bp': 0.004086771438464067,
'sys_len': 2,
'ref_len': 13}
compute_metricsを定義。
import numpy as np
def compute_metrics(eval_preds):
preds, labels = eval_preds
# In case the model returns more than the prediction logits
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100s in the labels as we can't decode them
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
return {"bleu": result["score"]}
Fine-tuning the model
ログイン。
from huggingface_hub import notebook_login
notebook_login()
コンソールからログインする場合。
huggingface-cli login
Seq2SeqTrainingArgumentsの作成。
predict_with_generate=True
from transformers import Seq2SeqTrainingArguments
args = Seq2SeqTrainingArguments(
f"marian-finetuned-kde4-en-to-fr",
evaluation_strategy="no",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=3,
predict_with_generate=True,
fp16=True,
push_to_hub=True,
)
Seq2SeqTrainerの作成。
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
訓練前の評価を確認。
trainer.evaluate(max_length=max_length)
{'eval_loss': 1.6964408159255981,
'eval_bleu': 39.26865061007616,
'eval_runtime': 965.8884,
'eval_samples_per_second': 21.76,
'eval_steps_per_second': 0.341}
訓練実行。
trainer.train()
訓練後のスコアを確認。
trainer.evaluate(max_length=max_length)
{'eval_loss': 0.8558505773544312,
'eval_bleu': 52.94161337775576,
'eval_runtime': 714.2576,
'eval_samples_per_second': 29.426,
'eval_steps_per_second': 0.461,
'epoch': 3.0}
pushする。
trainer.push_to_hub(tags="translation", commit_message="Training complete")
A custom training loop
Preparing everything for training
データセットの準備。
from torch.utils.data import DataLoader
tokenized_datasets.set_format("torch")
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)
モデルのロード。
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
オプティマイザの作成。
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
Acceleratorの作成。
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
学習スケジューラの設定。
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
リポジトリ名の作成。
from huggingface_hub import Repository, get_full_repo_name
model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name
'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
リポジトリの作成。
output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
Training loop
メトリックに渡すためのデータを作るpostprocess関数を作成。
def postprocess(predictions, labels):
predictions = predictions.cpu().numpy()
labels = labels.cpu().numpy()
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
return decoded_preds, decoded_labels
トレーニングループの作成。
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in tqdm(eval_dataloader):
with torch.no_grad():
generated_tokens = accelerator.unwrap_model(model).generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
max_length=128,
)
labels = batch["labels"]
# Necessary to pad predictions and labels for being gathered
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(generated_tokens)
labels_gathered = accelerator.gather(labels)
decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=decoded_preds, references=decoded_labels)
results = metric.compute()
print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)
epoch 0, BLEU score: 53.47
epoch 1, BLEU score: 54.24
epoch 2, BLEU score: 54.44
Using the fine-tuned model
訓練したモデルを使ってみる。
threadsがちゃんとフランス語になっている。
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
translator = pipeline("translation", model=model_checkpoint)
translator("Default to expanded threads")
[{'translation_text': 'Par défaut, développer les fils de discussion'}]
pluginもちゃんと翻訳されている。
translator(
"Unable to import %1 using the OFX importer plugin. This file is not the correct format."
)
[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
Summarization
英語のモデルを英語とスペイン語のバイリンガルモデルにトレーニングする。
顧客が商品レビューに記入したタイトルから学習されるため、簡潔になる。

Preparing a multilingual corpus
多言語Amazonレビューコーパスを使用する。
review_bodyを要約する文章として使用する。
review_titleを要約結果として使用する。
from datasets import load_dataset
spanish_dataset = load_dataset("amazon_reviews_multi", "es")
english_dataset = load_dataset("amazon_reviews_multi", "en")
english_dataset
DatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})
データの確認。
def show_samples(dataset, num_samples=3, seed=42):
sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
for example in sample:
print(f"\n'>> Title: {example['review_title']}'")
print(f"'>> Review: {example['review_body']}'")
show_samples(english_dataset)
'>> Title: Worked in front position, not rear'
'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
'>> Title: meh'
'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
'>> Title: Can\'t beat these for the money'
'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'
データが大きすぎるので特定のドメインのレビューのみを使用する。
どんなドメインがあるのか確認する。
english_dataset.set_format("pandas")
english_df = english_dataset["train"][:]
# Show counts for top 20 products
english_df["product_category"].value_counts()[:20]
home 17679
apparel 15951
wireless 15717
other 13418
beauty 12091
drugstore 11730
kitchen 10382
toy 8745
sports 8277
automotive 7506
lawn_and_garden 7327
home_improvement 7136
pet_products 7082
digital_ebook_purchase 6749
pc 6401
electronics 6186
office_product 5521
shoes 5197
grocery 4730
book 3756
Name: product_category, dtype: int64
book
digital_ebook_purchase
のみにフィルタする。
def filter_books(example):
return (
example["product_category"] == "book"
or example["product_category"] == "digital_ebook_purchase"
)
データのフォーマットを戻す。
english_dataset.reset_format()
フィルタを適応。
spanish_books = spanish_dataset.filter(filter_books)
english_books = english_dataset.filter(filter_books)
show_samples(english_books)
'>> Title: I\'m dissapointed.'
'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
'>> Title: Good art, good price, poor design'
'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
'>> Title: Helpful'
'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
英語とスペイン語のレビューを1つのDatasetDictオブジェクトとして結合する。
またデータに隔たりが起きないようにシャッフルする。
from datasets import concatenate_datasets, DatasetDict
books_dataset = DatasetDict()
for split in english_books.keys():
books_dataset[split] = concatenate_datasets(
[english_books[split], spanish_books[split]]
)
books_dataset[split] = books_dataset[split].shuffle(seed=42)
# Peek at a few examples
show_samples(books_dataset)
'>> Title: Easy to follow!!!!'
'>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'
'>> Title: PARCIALMENTE DAÑADO'
'>> Review: Me llegó el día que tocaba, junto a otros libros que pedí, pero la caja llegó en mal estado lo cual dañó las esquinas de los libros porque venían sin protección (forro).'
'>> Title: no lo he podido descargar'
'>> Review: igual que el anterior'
レビューとそのタイトルの単語の分布をチェック。
1,2単語のレビューが多い。
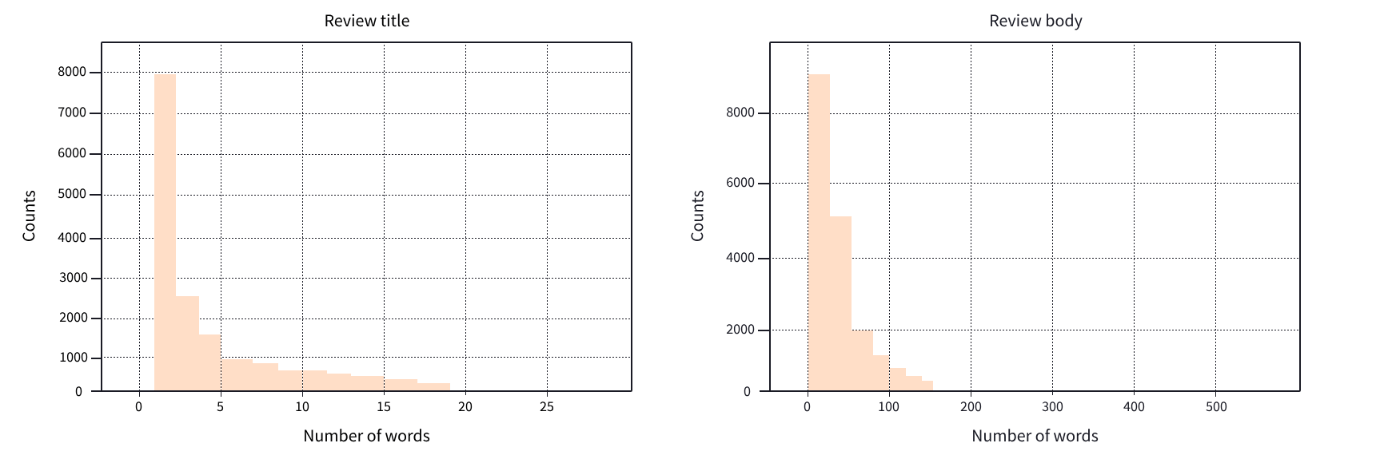
1,2単語のレビューを除外する。
books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
Models for text summarization
要約とテキスト翻訳は同じ様なタスク。
※短いバージョンに翻訳すると考えられる。
要約にはencoder-decoderモデルが良く使われる。
※GPTモデルを使うこともある。
事前学習モデルの候補。
多言語TransformerモデルのmT5を使用する。

T5ではすべての自然言語処理タスクに対応するため、
summarize:
の様な接頭辞でをつけることで汎用的にタスクに対応する。
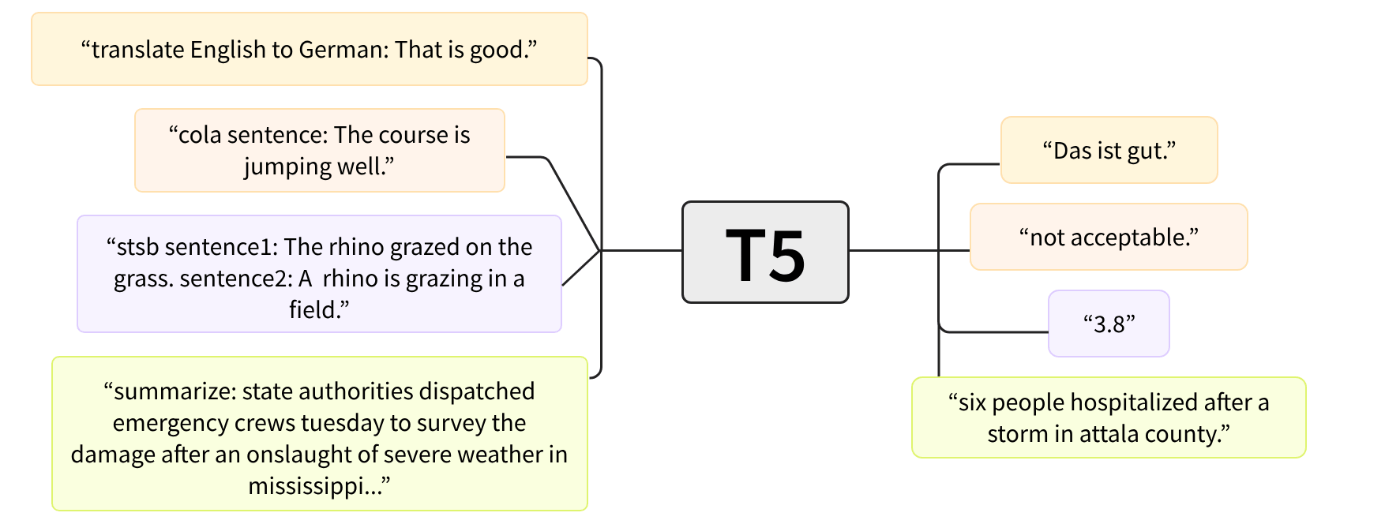
mT5は接頭辞には対応しないがT5と同じ様な特性がある。
Preprocessing the data
トーカナイザのロード。
from transformers import AutoTokenizer
model_checkpoint = "google/mt5-small"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
モデルをチューニングする際、まずは小さなモデルで試してみるのは良いプラクティス。
トーカナイズしてみる。
inputs = tokenizer("I loved reading the Hunger Games!")
inputs
{'input_ids': [336, 259, 28387, 11807, 287, 62893, 295, 12507, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
デコードしてみる。
Unigramセグメンテーションアルゴリズムに基づいたSentencePieceトークナイザーを使用している。
tokenizer.convert_ids_to_tokens(inputs.input_ids)
['▁I', '▁', 'loved', '▁reading', '▁the', '▁Hung', 'er', '▁Games', '</s>']
labelsもトーカナイズする必要がある。
text_targetを指定することでlabelsも並行してトーカナイズすることができる?
max_input_length = 512
max_target_length = 30
def preprocess_function(examples):
model_inputs = tokenizer(
examples["review_body"],
max_length=max_input_length,
truncation=True,
)
labels = tokenizer(
examples["review_title"], max_length=max_target_length, truncation=True
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
適応する。
tokenized_datasets = books_dataset.map(preprocess_function, batched=True)
Metrics for text summarization
要約の一般的な評価はROUGE scoreを使用する。
生成された要約を、通常人間が作成する参照要約のセットと比較する方法。
以下を比較してみる。
generated_summary = "I absolutely loved reading the Hunger Games"
reference_summary = "I loved reading the Hunger Games"
重複する単語のrecall、precisionを使用して評価する。
今回は
recall: 6/6 = 1
precision: 6/7 = 0.86
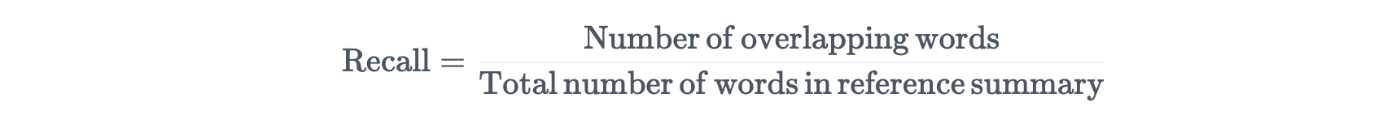

ライブラリで評価する事ができる。
!pip install rouge_score
import evaluate
rouge_score = evaluate.load("rouge")
rouge1がunigramsで評価されたもの。
rouge2はbigramsで評価されたもの。
rougeL、rougeLsumは共通する最長部分文字列を探して評価する。
scores = rouge_score.compute(
predictions=[generated_summary], references=[reference_summary]
)
scores
{'rouge1': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
'rouge2': AggregateScore(low=Score(precision=0.67, recall=0.8, fmeasure=0.73), mid=Score(precision=0.67, recall=0.8, fmeasure=0.73), high=Score(precision=0.67, recall=0.8, fmeasure=0.73)),
'rougeL': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
'rougeLsum': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92))}
rouge1を見てみる。
scores["rouge1"].mid
Score(precision=0.86, recall=1.0, fmeasure=0.92)
Creating a strong baseline
テキスト要約のための一般的なベースラインを作るため、記事の最初の3つのセンテンスを単純に取ってみる。
コロンで単純に分割するとうまくいかないケースがあるのでnltkライブラリを使用する。
!pip install nltk
import nltk
nltk.download("punkt")
最初の3センテンスを取る関数を作成。
from nltk.tokenize import sent_tokenize
def three_sentence_summary(text):
return "\n".join(sent_tokenize(text)[:3])
print(three_sentence_summary(books_dataset["train"][1]["review_body"]))
'I grew up reading Koontz, and years ago, I stopped,convinced i had "outgrown" him.'
'Still,when a friend was looking for something suspenseful too read, I suggested Koontz.'
'She found Strangers.'
ベースラインのROUGE scoreを取得する関数。
def evaluate_baseline(dataset, metric):
summaries = [three_sentence_summary(text) for text in dataset["review_body"]]
return metric.compute(predictions=summaries, references=dataset["review_title"])
import pandas as pd
score = evaluate_baseline(books_dataset["validation"], rouge_score)
rouge_names = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
rouge_dict = dict((rn, round(score[rn].mid.fmeasure * 100, 2)) for rn in rouge_names)
rouge_dict
{'rouge1': 16.74, 'rouge2': 8.83, 'rougeL': 15.6, 'rougeLsum': 15.96}
Fine-tuning mT5 with the Trainer API
モデルのロード。
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
ログイン。
from huggingface_hub import notebook_login
notebook_login()
コマンドからログインする場合。
huggingface-cli login
Seq2SeqTrainingArgumentsの作成。
from transformers import Seq2SeqTrainingArguments
batch_size = 8
num_train_epochs = 8
# Show the training loss with every epoch
logging_steps = len(tokenized_datasets["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
args = Seq2SeqTrainingArguments(
output_dir=f"{model_name}-finetuned-amazon-en-es",
evaluation_strategy="epoch",
learning_rate=5.6e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=num_train_epochs,
predict_with_generate=True,
logging_steps=logging_steps,
push_to_hub=True,
)
メトリクスを計算する関数。
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
# Decode generated summaries into text
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
# Decode reference summaries into text
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# ROUGE expects a newline after each sentence
decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels]
# Compute ROUGE scores
result = rouge_score.compute(
predictions=decoded_preds, references=decoded_labels, use_stemmer=True
)
# Extract the median scores
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
return {k: round(v, 4) for k, v in result.items()}
DataCollatorForSeq2Seqの作成。
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
テキスト形式のカラムを削除する。
tokenized_datasets = tokenized_datasets.remove_columns(
books_dataset["train"].column_names
)
少しdata_collatorに変換させてみる。
パディングやシフトに注意する。
features = [tokenized_datasets["train"][i] for i in range(2)]
data_collator(features)
{'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]), 'input_ids': tensor([[ 1494, 259, 8622, 390, 259, 262, 2316, 3435, 955,
772, 281, 772, 1617, 263, 305, 14701, 260, 1385,
3031, 259, 24146, 332, 1037, 259, 43906, 305, 336,
260, 1, 0, 0, 0, 0, 0, 0],
[ 259, 27531, 13483, 259, 7505, 260, 112240, 15192, 305,
53198, 276, 259, 74060, 263, 260, 459, 25640, 776,
2119, 336, 259, 2220, 259, 18896, 288, 4906, 288,
1037, 3931, 260, 7083, 101476, 1143, 260, 1]]), 'labels': tensor([[ 7483, 259, 2364, 15695, 1, -100],
[ 259, 27531, 13483, 259, 7505, 1]]), 'decoder_input_ids': tensor([[ 0, 7483, 259, 2364, 15695, 1],
[ 0, 259, 27531, 13483, 259, 7505]])}
Seq2SeqTrainerを作成。
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
トレーニングする。
trainer.train()
評価する。
ベースラインより良くなっていることが分かる。
trainer.train()
{'eval_loss': 3.028524398803711,
'eval_rouge1': 16.9728,
'eval_rouge2': 8.2969,
'eval_rougeL': 16.8366,
'eval_rougeLsum': 16.851,
'eval_gen_len': 10.1597,
'eval_runtime': 6.1054,
'eval_samples_per_second': 38.982,
'eval_steps_per_second': 4.914}
pushする。
trainer.push_to_hub(commit_message="Training complete", tags="summarization")
Fine-tuning mT5 with 🤗 Accelerate
Preparing everything for training
データセットのフォーマットを変更。
tokenized_datasets.set_format("torch")
モデルのロード。
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
データローダーの作成。
from torch.utils.data import DataLoader
batch_size = 8
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=batch_size,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=batch_size
)
オプティマイザの設定。
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
Acceleratorの設定。
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
学習スケジューラの設定。
from transformers import get_scheduler
num_train_epochs = 10
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
要約をROUGE metricが期待する形式に変換する。
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# ROUGE expects a newline after each sentence
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels
リポジトリ名の作成。
from huggingface_hub import get_full_repo_name
model_name = "test-bert-finetuned-squad-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name
'lewtun/mt5-finetuned-amazon-en-es-accelerate'
リポジトリの作成。
from huggingface_hub import Repository
output_dir = "results-mt5-finetuned-squad-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
Training loop
トレーニングループの作成。
from tqdm.auto import tqdm
import torch
import numpy as np
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for step, batch in enumerate(train_dataloader):
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
generated_tokens = accelerator.unwrap_model(model).generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
)
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
labels = batch["labels"]
# If we did not pad to max length, we need to pad the labels too
labels = accelerator.pad_across_processes(
batch["labels"], dim=1, pad_index=tokenizer.pad_token_id
)
generated_tokens = accelerator.gather(generated_tokens).cpu().numpy()
labels = accelerator.gather(labels).cpu().numpy()
# Replace -100 in the labels as we can't decode them
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
if isinstance(generated_tokens, tuple):
generated_tokens = generated_tokens[0]
decoded_preds = tokenizer.batch_decode(
generated_tokens, skip_special_tokens=True
)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(
decoded_preds, decoded_labels
)
rouge_score.add_batch(predictions=decoded_preds, references=decoded_labels)
# Compute metrics
result = rouge_score.compute()
# Extract the median ROUGE scores
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
result = {k: round(v, 4) for k, v in result.items()}
print(f"Epoch {epoch}:", result)
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)
Epoch 0: {'rouge1': 5.6351, 'rouge2': 1.1625, 'rougeL': 5.4866, 'rougeLsum': 5.5005}
Epoch 1: {'rouge1': 9.8646, 'rouge2': 3.4106, 'rougeL': 9.9439, 'rougeLsum': 9.9306}
Epoch 2: {'rouge1': 11.0872, 'rouge2': 3.3273, 'rougeL': 11.0508, 'rougeLsum': 10.9468}
Epoch 3: {'rouge1': 11.8587, 'rouge2': 4.8167, 'rougeL': 11.7986, 'rougeLsum': 11.7518}
Epoch 4: {'rouge1': 12.9842, 'rouge2': 5.5887, 'rougeL': 12.7546, 'rougeLsum': 12.7029}
Epoch 5: {'rouge1': 13.4628, 'rouge2': 6.4598, 'rougeL': 13.312, 'rougeLsum': 13.2913}
Epoch 6: {'rouge1': 12.9131, 'rouge2': 5.8914, 'rougeL': 12.6896, 'rougeLsum': 12.5701}
Epoch 7: {'rouge1': 13.3079, 'rouge2': 6.2994, 'rougeL': 13.1536, 'rougeLsum': 13.1194}
Epoch 8: {'rouge1': 13.96, 'rouge2': 6.5998, 'rougeL': 13.9123, 'rougeLsum': 13.7744}
Epoch 9: {'rouge1': 14.1192, 'rouge2': 7.0059, 'rougeL': 14.1172, 'rougeLsum': 13.9509}
Using your fine-tuned model
訓練済みモデルを使用する。
from transformers import pipeline
hub_model_id = "huggingface-course/mt5-small-finetuned-amazon-en-es"
summarizer = pipeline("summarization", model=hub_model_id)
def print_summary(idx):
review = books_dataset["test"][idx]["review_body"]
title = books_dataset["test"][idx]["review_title"]
summary = summarizer(books_dataset["test"][idx]["review_body"])[0]["summary_text"]
print(f"'>>> Review: {review}'")
print(f"\n'>>> Title: {title}'")
print(f"\n'>>> Summary: {summary}'")
print_summary(100)
'>>> Review: Nothing special at all about this product... the book is too small and stiff and hard to write in. The huge sticker on the back doesn’t come off and looks super tacky. I would not purchase this again. I could have just bought a journal from the dollar store and it would be basically the same thing. It’s also really expensive for what it is.'
'>>> Title: Not impressed at all... buy something else'
'>>> Summary: Nothing special at all about this product'
print_summary(0)
'>>> Review: Es una trilogia que se hace muy facil de leer. Me ha gustado, no me esperaba el final para nada'
'>>> Title: Buena literatura para adolescentes'
'>>> Summary: Muy facil de leer'
Discussion