SmoothQuant論文まとめ


概要
論文
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
のまとめ
精度を落とさずにアクティベーションと重みの8bit量子化を行う方法。
※アクティベーションとはレイヤに対する入力の意味
重みの量子化は簡単だが、アクティベーションの量子化は外れ値が出やすいため精度を落としてしまう。
SmoothQuantでは数学的にアクティベーションの外れ値を重みにマイグレートすることで精度を落とさずに量子化を行うことができる。
1.56倍の速度向上
1/2のメモリ消費を実現できる。

導入
通常のINT8量子化
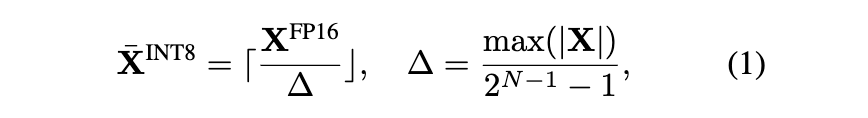
Δはステップサイズ
「」は整数に丸めることを表す
Nは量子化後のするbit数
単純のために行列の値は0を中心に対照に存在しているとする。
このような量子化はアクティベーションの外れ値を保持しようとするため、精度に影響することが分かっている。

quantizationの種類
static quantization: オフライン時にいくつかのサンプルを使って、アクティベーションのΔを計算すること。
dynamic quantization: 実行時の統計値を使って、アクティベーションのΔを計算すること。
SmoothQuantはstatic quantization
量子化の粒度

per-tensor quantization: 全体の行列に1つのステップサイズ
per-token quantization: トークンごとに1つのステップサイズ
per-channel quantization: チャンネルごとに1つのステップサイズ
group-wise quantization: チャンネルグループごとに1つのステップサイズ
量子化の難しさ

アクティベーションにおいて一番左のような外れ値があると上手く量子化出来ない。
外れ値がその他の値よりも100倍程度大きいケースなど。
あるチャンネルiの最大値をmiとし、テンソル全体の最大値をmとすると、チャンネルiの量子化レベルは
2^8 * mi / m
となる。
mが大きくなると量子化レベルが小さくなるため表現力が小さくなってしまう。
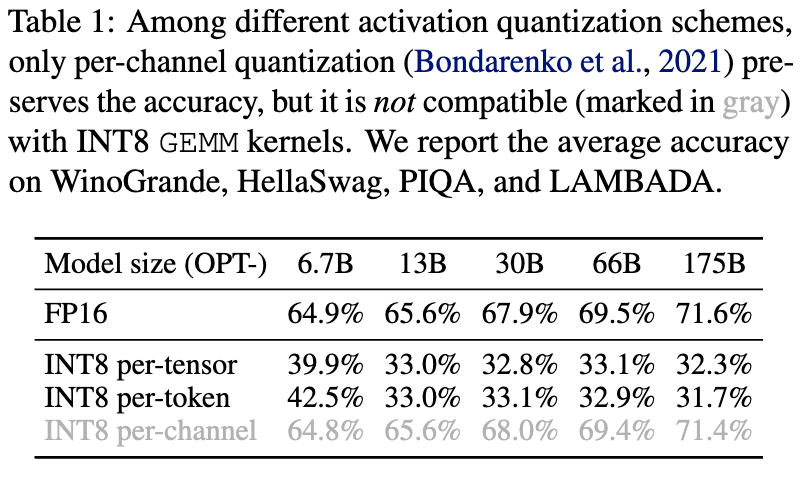
per-channelを行えば精度を犠牲にせずに量子化できることが分かっているが、現状ハードウェア的にサポートされていない。
SmoothQuant
per-channel quantizationの代わりにSmoothQuantを提案する。
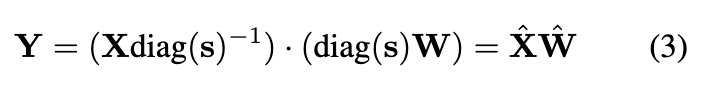


アクティベーションの外れ値を重みに移動する式。
αが多いほど外れ値を重みに移行する。
0.5がバランスが良いらしい。
サンプルをpytorchで再現
αが0.5の場合。
# アクティベーション
X = torch.tensor([
[1, -16, 2, 6],
[-2, 8, -1, 9]
])
# 重み
W = torch.tensor([
[2, 1, -2],
[1, -1, -1],
[2, -1, -2],
[-1, -1, 1]
])
# 素直に計算した結果
ret_1 = X @ W
print(f"{ret_1=}")
ret_1=tensor([[-16, 9, 16],
[ -7, -18, 7]])
# abs max X
X_max = X.abs().max(dim=0).values
print(f"{X_max=}")
# abs max W
W_max = W.abs().max(dim=1).values
print(f"{W_max=}")
X_max=tensor([ 2, 16, 2, 9])
W_max=tensor([2, 1, 2, 1])
# スケーリング係数を求める
s = (X_max // W_max).sqrt().to(torch.int64)
print(f"{s=}")
s=tensor([1, 4, 1, 3])
# 対角行列を作成
s_diag = s.diag()
print(f"{s_diag=}")
s_diag=tensor([[1, 0, 0, 0],
[0, 4, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 3]])
# 逆数の対角行列を作成
reciprocal_s_diag = (1 / s).diag()
print(f"{reciprocal_s_diag=}")
reciprocal_s_diag=tensor([[1.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.2500, 0.0000, 0.0000],
[0.0000, 0.0000, 1.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.3333]])
# X hat
X_hat = (X.float() @ reciprocal_s_diag).to(torch.int64)
print(f"{X_hat=}")
# W hat
W_hat = s.diag() @ W
print(f"{W_hat=}")
X_hat=tensor([[ 1, -4, 2, 2],
[-2, 2, -1, 3]])
W_hat=tensor([[ 2, 1, -2],
[ 4, -4, -4],
[ 2, -1, -2],
[-3, -3, 3]])
# 外れ値を移行した状態で内積を取る
ret_2 = X_hat @ W_hat
print(f"{ret_2=}")
# 計算結果が等しいことを確認
print(torch.equal(ret_1, ret_2))
ret_2=tensor([[-16, 9, 16],
[ -7, -18, 7]])
True
transformerブロックに適応する

緑のところにSmoothQuantを適応する。
主に計算量の多いLinearLayerやbatched matmulに適応する。
実験結果

精度は落ちていない。
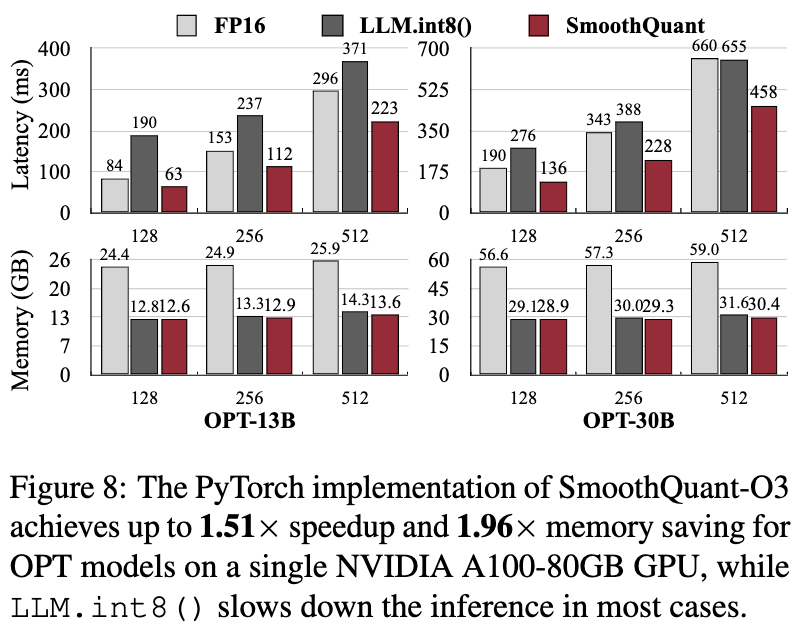
レイテンシや、メモリ消費量は改善されている。
その他
llama2に対する実装例
スケーリング係数の取得方法
実際は推論の度にアクティベーションと重みからスケーリング係数を出すわけではなく、 こちらのスクリプトを使って事前に推論を行い、スケーリング係数を見積もっておく。
重みのロード後に見積もられたスケーリング係数を重みに適応しておく。
また入力に対しても毎回スケーリング係数を適応するのではなく、1つ前のLayerNormレイヤ等にあらかじめ適応しておくことで、推論時のオーバーヘッドをなくす工夫をする。
備考
参考になった動画
Discussion