🐕
Hugging Face peft(lora)まとめ
概要
の大事そうな部分のまとめです。
PeftConfig
PeftModelを生成する際のパラメータ。
子クラスとしてLoraConfigがある。
from peft import LoraConfig, TaskType
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
こんな感じで作成する。
- task_type
class TaskType(str, enum.Enum):
SEQ_CLS = "SEQ_CLS"
SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM"
CAUSAL_LM = "CAUSAL_LM"
TOKEN_CLS = "TOKEN_CLS"
QUESTION_ANS = "QUESTION_ANS"
FEATURE_EXTRACTION = "FEATURE_EXTRACTION"
こんなパラメータがある
-
inference_mode
推論だけするときはTrue。
重みがマージされる? -
r
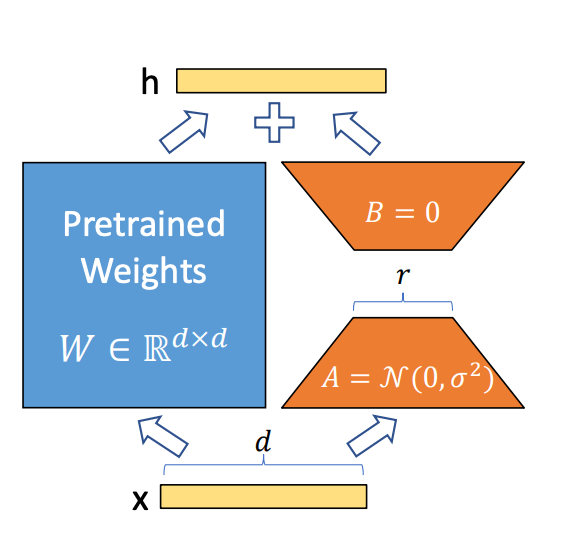
こちらのrの値。
小さくするほど使用するGPUを節約できる。
論文によるとかなり小さい値にしても性能は出るらしい。
-
lora_alpha

この式の内、∆Wx にはα / r をかけるらしい。
大きいほど学習の影響が強く出る。
一般的な学習の学習率みたいなものらしい。 -
lora_dropout
ドロップアウト。
PeftModel
model.save_pretrained("output_dir")
# if pushing to Hub
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("my_awesome_peft_model")
from peft import get_peft_model
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
普通のモデルをラップすることにより、訓練や推論を普段と同じように使うことができる。
学習可能なパラメータサイズが減っていることが分かる。
Save and load a model
model.save_pretrained("output_dir")
# if pushing to Hub
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("my_awesome_peft_model")
追加学習した部分だけhubにpush。
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
+ peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
+ config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
'complaint'
使う時。
- from peft import PeftConfig, PeftModel
- from transformers import AutoModelForCausalLM
+ from peft import AutoPeftModelForCausalLM
- peft_config = PeftConfig.from_pretrained("ybelkada/opt-350m-lora")
- base_model_path = peft_config.base_model_name_or_path
- transformers_model = AutoModelForCausalLM.from_pretrained(base_model_path)
- peft_model = PeftModel.from_pretrained(transformers_model, peft_config)
+ peft_model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
一気にロードすることも可能。
Discussion