Pragmatic Functional Programming in TypeScript を理解する
モチベ
TSKaigi 2025のyasaichiさんの発表「Pragmatic Functional Programming in TypeScript」に出てくるキーワードを理解し、登壇を正しく理解する。
前情報
書籍
- なっとく!関数型プログラミング(2023)
- 関数型ドメインモデリング(2024)F#本
言語トレンド
- OOP言語でもFPの思想を取り入れた機能
- C# 9.0
- Java Project Amber
- 拾えたら拾う
フレームワークのトレンド
- ReactがFPの思想を取り入れている
FP関連書籍で出会う定番コンセプト
副作用の分離
- 純粋関数
- イミュータブルな値
関数構成
- 高階関数
- カリー化/部分適用
- 関数合成/コンビネータ
データ表現
- 代数的データ型(ADT)
- パターンマッチング
文脈付き計算
- 関手(Functor)
- アプリカティブ
- モナド
高階関数、カリー化の写経
const multiply = (a: number) => (b: number): number => a* b
const double = multiply(2)
const addTiming =
<T extends (...args: any[]) => any>(fn: T) =>
(...args: Parameters<T>): ReturnType<T> => {
const start = performance.now()
const result = fn(...args)
console.log(`Execution time: ${performance.now() = start} ms`)
return result
}
addTiming(double)(21)
const double = multiply(2) // (b: number) => 2 * b が展開される
addTiming(double)(21)が実行
↓
const start = performance.now()
const result = double(21) // (21) => 2* 21 → 42
console.log(Execution time: ${performance.now() = start} ms)
return result // 42が返る
実務にあたっての課題
- 新しいプログラミングパラダイムの導入に見合う成果が得られるか
- 一人だけが関数型をできても意味はなく、チーム開発に取り入れられるか
- クラスベースのOOP実装が主流のプログラミングを崩せるか
5つの原則から始める
- 純粋関数、イミュータブルな値、モナドの概念を具体的なコードに落とし込んでいくかが明確でない場合が多い
- Dmitrii Kovanikov氏の提唱する5つの原則を「契約による設計」の視点で再構成し、TSによる実装例と利点を解説
- Parse, don't validate
- Make illegal states unrepresentable
- Errors as values
- Functional core, imperative shell
- Smart constructor
Bertrand Meyer「契約による設計」
事前条件
事後条件:あるルーチンの実行から生じた状態の特性
不変表明:あるインスタンスのルーチン全てで維持される共通の特性
事後条件、不変表明の例
登壇内容の写経
// 不変表明 #itemsは常にT型の要素のみを持つ配列、null, undefinedを含まないこと
class Stack<T> {
readonly #items: T[] = []
// (事前条件:スタックが空でないこと)
// 事後条件:要素の数が実行前と比べて1つ減り、戻り値が実行前の末尾の要素であること
pop(): T {
assert(!this.isEmpty(), 'Stack must not be empty')
return this.#items.pop()!
}
// 事後条件:戻り値がtrueの場合、スタックが空、falseの場合、要素が残っていること
isEmpty(): boolean {
return this.#items.length === 0
}
}
Webフロントエンドで重視したい品質特性の話
Parse, don't validate
概要
入力値を検証し、booleanやvoidではなく、検証済みデータを表す専用型で結果を返す
分類
事後条件(検証済みであることを型に反映しているため)
利点
後続処理での不正な値の検出や分岐処理が不要になり、信頼性・保守性が向上する
やりがちなzod実装
zodのemailは文字列型を返すため、二度手間的な実装になる
const email = z.string().email().parse(req.body.email)
class User {
#email: string
set email(value string) {
if(!validate(value)) throw ...
// 追加ルールがあればここで検証
this.#email = value
}
}
FP的実装
// Branded types
export const EmailSchema = z.string().email().brand<'Email'>()
export type Email = z.infer<typeof EmailSchema>
class User {
constructor(
public readonly email: Email
) {}
}
Make illegal states unrepresentable
概要
型システムを活用し、不正なデータや状態をそもそも表現できないようにする
分類
不変表明(不正な状態を型で排除しているため)
利点
後続処理での不正な状態の検出や分岐処理が不要になり、信頼性・保守性が向上する
やりがちな実装(どちらもオプショナル)
const schema = z.object({
contactMethod: z.enum(['email', 'phone']),
email: EmailSchema.optional(),
phone: PhoneNumberSchema.optional(),
})
// エラーにならない
schema.parse({contactMethod: 'email'})
FP的な実装(判別可能なユニオン型)
const schema = z.discriminatedUnion(
'contactMethod',
[
z.object({
contactMethod: z.literal('email'),
email: EmailSchema
}),
z.object({
contactMethod: z.literal('phone'),
email: PhoneNumberSchema
})
]
)
// エラーになる
schema.parse({contactMethod: 'email'})
// 正しい使用法
schema.parse({
contactMethod: 'email',
email: 'user@example.com'
}) // OK
schema.parse({
contactMethod: 'phone',
phone: '+81-90-1234-5678'
}) // OK
こういうことが言いたい。タグ付きユニオン的な表現
// 悪い例:不正な状態が表現可能
type ContactBad = {
method: 'email' | 'phone'
email?: string
phone?: string
// emailもphoneも両方ない状態が可能 😱
}
// 良い例:不正な状態が表現不可能
type ContactGood =
| { method: 'email', email: string }
| { method: 'phone', phone: string }
// どちらかは必ず存在することが保証される ✅
Smart constructor
概要
ある型の値を制約を満たした場合にのみ生成可能にする
分類
不変表明(実行時検証で不正な値を排除し、有効な値のみ生成するため)
利点
値の検証と生成ロジックが一箇所に集約され、保守性が向上する
import {validate} from 'email-validator'
export class UserEmail {
readonly #value: string
private constructor(value: string) {
this.#value = value
}
// smart constructorはここ。本来のconstructorをreadonlyにし、create経由でしか値を利用できないようにする
static create(value: string): UserEmail {
if(!validate(value)) throw new InvalidEmailError(value)
if(FREE_DOMAINS.has(value.split('@')[1]))
throw new FreeMainDomainUsedError(value)
return new UserEmail(value)
}
}
Errors as values
概要
例外をスローするのではなく、値として返す
分類
事後条件(事後条件が満たされない可能性を型に反映しているため)
利点
事後条件が満たされない状態への対処を後続処理に矯正することで、信頼性が向上する
import {validate} from 'email-validator'
import {err, ok, type Result} from 'neverthrow'
export class UserEmail { // プロパティ・コンストラクタ定義略
static create(value: string): Result<UserEmail, InvalidEmailError | FreeMailDomainUsedError> {
if(!validate(value)) return err(new InvalidEmailError(value))
if(FREE_DOMAINS.has(value.split('@')[1]))
return err(new FreeMainDomainUsedError(value))
return ok(new UserEmail(value))
}
}
要点
- ここまでの4原則はいずれも「型」に着目している
- 4原則は、値・関数の不変表明・事後条件を型で厳密に表現する
- 本手法はクラスベースのOOPにも統合できる
型が厳密に表現されたコードを使用すると、それを利用するコード側の設計も改善してくる
後半10分が、クラスベース主流アーキテクチャへの統合について
- APIゲートウェイのリライト
- Deno, NestJS, Effect
Effect型は利用していない。
その辺りの発表がここ
ユーザー招待状態の遷移

戦術DDDに基づくレイヤードアーキテクチャ
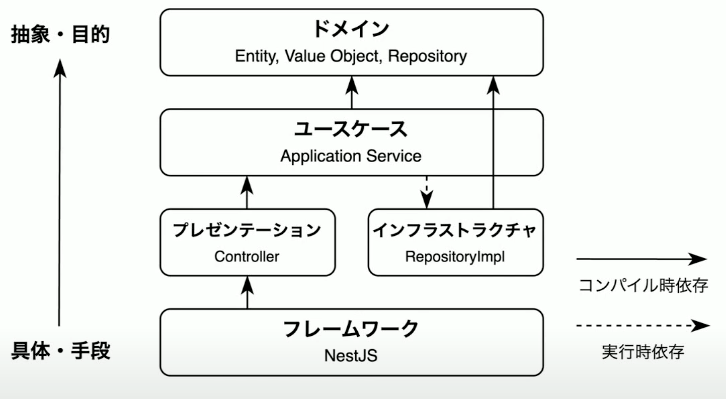
parse don't validate, smart constructor
バリデーションがBlanded Typesで表現されており、安全性が担保されているため、
それを利用する側のコードでは、シンプルな実装が実現できる。

Functional core, imperative shell
概要
アプリケーションを純粋関数で構成されたCoreと、副作用を担う最小限のShellに分離するアーキテクチャパターン
利点
- 純粋関数の増加により、テスト容易性が向上
- 副作用を伴う処理から分岐や状態遷移が減り、保守性が向上
副作用のありなしの混在

副作用のない処理をドメインサービスに切り出す

型駆動開発で、ドメインルールを型で表現するという表現
ドメインルールの把握が難しい
ドメインルールと言うより、不変表明、事後条件を考えるのが良いという意見
FP5原則は理論と実務のギャップを埋める実践的ガイドライン
実務でFPをやるために、まずこの5原則を型で表現するところから