1000万ユーザに耐えるサーバを作ってみた
概要
スケーラビリティが高く1000万ユーザに耐えるAPIサーバを作成しました。TwitterのようなSNSです。実装はGitHubで公開しています。
開発環境は次の通りです。
- Node 16.14
- Express 4.17.3
- DynamoDB 2012-08-10
機能要件は次の通りです。
- ツイート機能
- ツイートに対してコメント機能
- フォロー機能
- タイムライン機能
導入
Facebook、Amazon、Youtubeのような数億人のユーザを抱えるサービスでは大量のトラフィックを捌く必要があります。大量のトラフィックを捌くためのアプローチとして一般的に使われるのはスケールアップではなくスケールアウトです。スケールアップは性能の高い機器を使うためにコストが高いです。また、1つのサーバで運用するためにパフォーマンスの限界が存在します。
スケールアウトについて考えます。アプリケーションは大きく3つの層に分けることができます。
- クライアント層
- サーバ層
- データベース層
大量のトラフィックを捌く際に、負荷がかかるのはサーバ層とデータベース層です。サーバ層はデータを処理するのみで保存はしません。そのため、スケールアウトさせることは容易です。
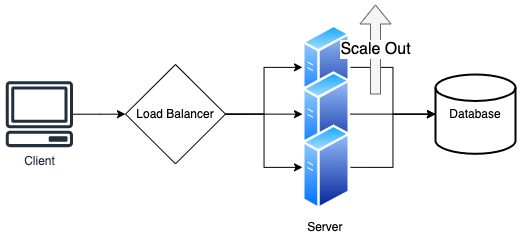
一方、データベース層はスケールアウトによりデータが分散すると、整合性と可用性を保つのが難しくなります。どのデータをどのノードに保存するかを決めるロジックも必要です。ノードの数を増減するときはデータの再配置が必要です。これらの機能ははRDBにはないので、NoSQLを使います。
スケールアウトをサポートしているデータベースの代表的なものとして、BigTable、HBase、DynamoDB、Cassandraなどがあります。
| データベース | 特徴 |
|---|---|
| BigTable、HBase | 整合性があり最新のデータを取得可能。一方、データ更新によりロックがかかっている最中はデータを取得できない。 |
| DynamoDB、Cassandra | データはいつでもアクセス可能。一方、データの同期中は古いデータを読み取る可能性がある。 |
今回、作成するのはSNSのAPIサーバであるため、整合性より可用性が重要です。そのため、DynamoDBを使います。
DynamoDBとは
DynamoDBはKey-Value型のデータベースです。テーブルを作成することができ、各テーブルにはアイテムが保存されます。各アイテムはキーと値を持ちます。
アイテムのキーにはパーティションキーとソートキーを指定することができます。パーティションキーはDynamoDBクラスタの中からノードを決定するために使われます。ソートキーはテーブルのインデックスのようなもので、ソートに使われます。
アイテムの値には属性と値のペアを複数保存することができます。属性はアイテムごとに異なるものを持つことができます。

DynamoDBのクエリは限定的で、基本的にパーティションキーとソートキーのみでアイテムを絞り込みます。それ以外の属性を使いクエリをする場合、全てのアイテムを調べる必要があるのでアイテム数の増加に伴い遅くなります。
他の属性をパーティションキーとして扱いたい場合はGSI(Global Secondaly Index)を使います。他の属性をソートキーとして扱いた場合はLSI(Local Secndary Index)を使います。
データベース設計
DynamoDBのデータベース設計はRDBとは異なります。RDBは柔軟にクエリが可能であるため、データへのアクセスパターンを考慮せずに、最初に正規化されたテーブルを設計します。一方、DynamoDBはクエリが限定的であるために、初めにデータへのアクセスパターンを決めて、それに基づいてテーブル設計を行います。具体的には次の流れで進めていきます。
- モデリング
- ユースケースリスト作成
- テーブル設計
- クエリ定義作成
モデリング
ER図は次のようになります。
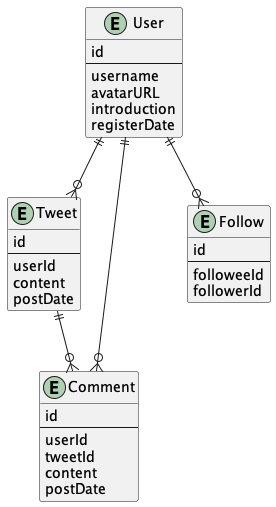
タイムラインではユーザがフォローしているユーザのツイートの一覧を表示します。SNSではタイムラインの表示速度はユーザビリティへの影響が大きいです。より早くタイムラインを表示できるような設計を考えます。
タイムラインのRead Heavy / Write Light
正規化されたテーブル設計の場合は、ツイート時のデータ書き込みにはTweetsテーブルのみにデータを書き込むため負荷が軽いです。一方、タイムラインにおけるデータ読み込みは負荷が重いです。タイムラインを読み込む際の大きな流れとしては次のようになります。
- フォローしているユーザのID一覧を取得
- フォローしている各ユーザの投稿を取得
- 取得した投稿をマージ
- マージした投稿をソートし直す
タイムライン取得のSQLイメージは次のようになります。
SELECT
*
FROM
tweets
WHERE
userId IN (
SELECT followeeId FROM follows WHERE followerId = 'user id'
)
ORDER BY
postDate DESC
このやり方ではフォロー数が多くなればなるほど、タイムラインの読み込み負荷が高くなります。Read Heavy / Write Light な手法と言えます。
タイムラインのRead Light / Write Heavy
Read Light / Write Heavyな手法を考えてみます。Timelineテーブルを作成して、タイムラインを読み込みたい場合はタイムラインテーブルにのみ問い合わせるのみにします。一方、ユーザがツイートをしたら、そのユーザのフォロワーのタイムラインにツイートを書き込むようにします。
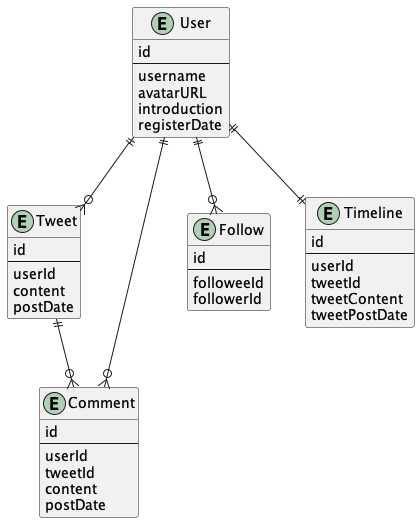
タイムライン取得のSQLイメージは次のようになります。
SELECT
*
FROM
timelines
WHERE
userId = 'user id'
ORDER BY
tweetPostDate
今回はこのRead Light / Write Heavyな方法を採用します。
ユースケースリスト作成
機能要件を元にデータのユースケースリストを作成して、データへのアクセス方法を整理します。
| エンティティ | ユースケース | 画面 |
|---|---|---|
| Tweet | getTimelineByUserId | ホーム画面 |
| User | getUserByUserName | ユーザ詳細画面 |
| Follow | getFolloweesByUserId | ユーザ詳細画面 |
| Follow | getFollowersByUserId | ユーザ詳細画面 |
| Follow | getCountFoloweeByUserId | ユーザ詳細画面 |
| Follow | getcountFollowerByUsreId | ユーザ詳細画面 |
| Tweet | getTweetsByUserId | ユーザ詳細画面 |
| Tweet | getTweetByTweetId | ツイート詳細画面 |
| Comment | getCommentsByTweetId | ツイート詳細画面 |
テーブルとインデックス設計
ユースケースリストをもとにテーブルとインデックス設計をしていきます。DynamoDBはクエリが限定的ですが、GSIオーバローディングという方法を使うと柔軟なクエリが可能になります。

ソートキーにはIDを含ませます。IDの大小関係とレコード作成時間の大小関係が一致するようにします。そうすると、LSIを使うことなく投稿を日付順でソートすることができます。
クエリ定義書
最後にクエリの条件を書き出していきます。これを元にデータベース周りの実装を行います。
| エンティティ | ユースケース | パラメータ | テーブル / インデックス | キー条件 |
|---|---|---|---|---|
| Tweet | getTimelineByUserId | {UserId} | Primary Key | GetItem (ID=UserId AND begins_with(DataType, timeline)) |
| User | getUserByUserName | {Username} | GSI-1 | Query (DataValue=Username AND DataType=usserProfile) |
| Follow | getFolloweesByUserId | {UserId} | Primary key | Query (ID=userId AND begins_with(DataType, followee) |
| Follow | getFollowersByUserId | {UserId} | Primary Key | Query (ID=userId AND begins_with(DataType, follower) |
| Follow | getCountFoloweeByUserId | {UserId} | Primary Key | Select COUNT / Query (ID=userId AND begins_with(DataType, followee) |
| Follow | getcountFollowerByUsreId | {UserId} | Primary Key | Select COUNT / Query (ID=userId AND begins_with(DataType, follower) |
| Tweet | getTweetsByUserId | {UserId} | Primary Key | Query(ID=userId AND begins_with(DataType, tweet) |
| Tweet | getTweetByTweetId | {TweetId} | GSI-1 | Query(DataValue=tweetId AND begins_with(DataType, tweet) |
| Comment | getCommentsByTweetId | {TweetId} | GSI-1 | Query(DataValue=tweetId AND begins_with(DataType, comment) |
APIサーバの設計
ソフトウェア設計
ドメイン駆動設計で設計します。レイヤーとディレクトリ名は一致するようにしています。
| ディレクトリ名 | DDD 層 | 構成要素 |
|---|---|---|
| src/domain | Domain Layer | Entity / Value Object / Repository Interface |
| src/application | Application Layer | Application Service / Serializer |
| src/infrastructure | Infrastructure Layer | Repository / AWS Config |
| src/presentation | Presentation Layer | API Server |
ID生成方法
IDの大小関係とレコード作成の順序が一致するようにします。採番テーブルによるID生成で対応できますが、スケーラビリティが欠けます。スケーラブルなID生成方法としてSnowflakeを使います。
この方法ではビット列を次の3つの区間に分けます。このビット列を10進数にしたものがIDとなります。
| 区間 | 説明 |
|---|---|
| 時間 | 特定の時刻からの差分の秒数です。 |
| 連番 | IDの生成ごとにカウントアップされ、1秒ごとにクリアされます。 |
| ノード番号 | ノードごとに割り当てる番号です。 |
Node.jsでSnowflakeを実装すると次のようになります。
import { config } from "@src/config";
import { dateToUnixTime } from "./time";
const workerIDBits = 10;
const sequenceBits = 12;
// Use snowflake
// See: https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake
export class IdGenerator {
private workerId: number;
private lastGenerateAt: number;
private sequence: number;
constructor(workerId?: number) {
this.workerId = config.snowflakeWorkerId;
this.lastGenerateAt = dateToUnixTime(new Date());
this.sequence = 0;
}
generate(): number {
const now = dateToUnixTime(new Date());
if (now == this.lastGenerateAt) {
this.sequence++;
} else {
this.sequence = 0;
}
this.lastGenerateAt = now;
// The bit operators ('<<' and '|' ) can handle numbers within
// the range of signed 32 bit integer.
return (
now * 2 ** (workerIDBits + sequenceBits) +
this.workerId * 2 ** sequenceBits +
this.sequence
);
}
}
FAQ
ユーザのプロフィール情報が重複してませんか?
はい、重複します。プロフィールが更新された際は、DynamoDB StreamでLambdaを起動して非同期で整合性を取るなどの工夫が必要です。
フォロワーが多いユーザのツイートは書き込み負荷が高くないですか?
はい、高いです。フォロワー数が多い場合のみフォロワーのタイムラインに書き込まずに、タイムライン取得時にマージするなどの工夫が必要です。
キャッシュはしないのですか?
是非、しましょう。監視をしてボトルネックを見つけてから判断しても、遅くはないでしょう。
まとめ
この記事ではスケーラビリティの高いサーバを作る方法を説明しました。ただパフォーマンスの問題が発生していない段階で、過度なパフォーマンス最適化は間違った方向に進む可能性があるので注意しましょう。
実装はGitHubで公開しているので、覗いてみてください。
Discussion
これは、たとえば、「フォロワー数の集計が数字としてパフォーマンスに影響してこない限りは、変にキャッシュとかせず、Count()で十分」的な話でしょうか?