eBPF - 入門概要 編
本記事は、eBPFの全般を把握出来る入門者向けの記事になっています。以下、関連記事をいくつか書いていますので必要に応じて参照して下さい。
- eBPF - 入門概要 編(本記事)
- eBPF - 仮想マシン 編
- eBPF - BCCチュートリアル 編
- eBPF - bpftraceチュートリアル 編
- eBPF - XDP概要 編
1. eBPFとは?
eBPF(extended Berkeley Packet Filter)はLinuxカーネルが提供する機能の一つで、カーネル空間で動作する仮想マシン(Virtual Machine)で、主にネットワークパケットやシステム動作のトレーシング用途で提供されます。それ以外にも、システムのセキュリティ対策、そして近年では各種クラウドアプリケーションの高速化などでも利用されており、近年クラウド界隈を中心にホットな技術です。
より具体的には、カーネルモードで動作するサンドボックス化された仮想マシンにユーザが用意した任意のBPFバイトコードを流し込んでその仮想マシン上で実行し、カーネルのイベント(例えばカーネルの任意の関数が実行された、システムコール、特定のパケットを受信したなど)をフックしてそれらの情報をユーザランドのアプリケーションに通知およびデータ共有などが可能です。そのため、カーネルやカーネルモジュールを修正/ビルド/再実行せずに現在動作しているシステム環境下においてそのままトレーシングなどが可能です。また、パフォーマンス観点では、不要なパケットデータのコピーやカーネルとユーザモードのコンテキストスイッチを削減することが可能であるため、パフォーマンスを大幅に向上させることが可能です。さらに、eBPFからカーネルの関数を直接呼び出すことも部分的に許可されています。
もともとはUNIXでネットワークパケットをフィルタリングするためのアイディアが提案され、それがLinuxカーネルv2.1.75で追加されました。現在ではユーザのコードの安全性を保ったまま、より便利により良い高パフォーマンスで利用する流れになっており、より幅広い用途で使われ始めています。
cBPF
eBPFの前身である旧来のBPFは、eBPFとは互換性がなく意図的に対比するためにcBPF(classic BPF)と呼ばれることがあります。なお、eBPF登場後にcBPFは利用出来なくなるかというと実際には引き続きcBPFも利用可能です。ただし内部的にはcBPFのプログラムがeBPFに変換されて実行されるようです。
ドキュメント
Linux Socket Filtering aka Berkeley Packet Filter (BPF)が公式ドキュメントみたいです。ただ、テキストファイルのドキュメントよりもBPF Documentationの方が読み易いと思います。
さらに、Ciliumプロジェクト(後述)のドキュメントがとてもまとまっています。
BPFの歴史
| 西暦 | イベント |
|---|---|
| 1992 | 最初のアイディアがバークレー研究所のSteven McCannの論文で発表 |
| 1997 | Linuxカーネルv2.1.75でLinux Socket Filterという名称で初めてBPFが追加 |
| 2013 | Alexei StarovoitovがcBPFの拡張を提案 |
| 2014 | Linuxカーネルv3.18でeBPFが搭載 |
| 2015 | BPF Compiler Collection (BCC) が開発 |
| 2019 | Linuxカーネルv5.4でVerifierでforループが許可(ただしループ上限あり) |
| 2019 | CO-REプロジェクトの発表 |
| 2021 | WindowsでeBPFサポートプロジェクトが発表される(uBPFのアプローチ) |
bpfシステムコール
LinuxカーネルはeBPFのシステムコールのAPIを提供します。$ man bpfコマンドで仕様は確認することが出来ますが、linux/bpf.hにAPI仕様が定義されています。
linux/bpf.hに定義されているシステムコールを利用して、C言語からeBPFを利用することも可能ですが、ユーザアプリケーションが直接システムコールを扱うよりも、後述のlibbccやlibbpfのライブラリを利用することが一般的です。
2. eBPFアーキテクチャ概要
eBPFの内部的な仕組みの概要について説明します。
アーキテクチャ
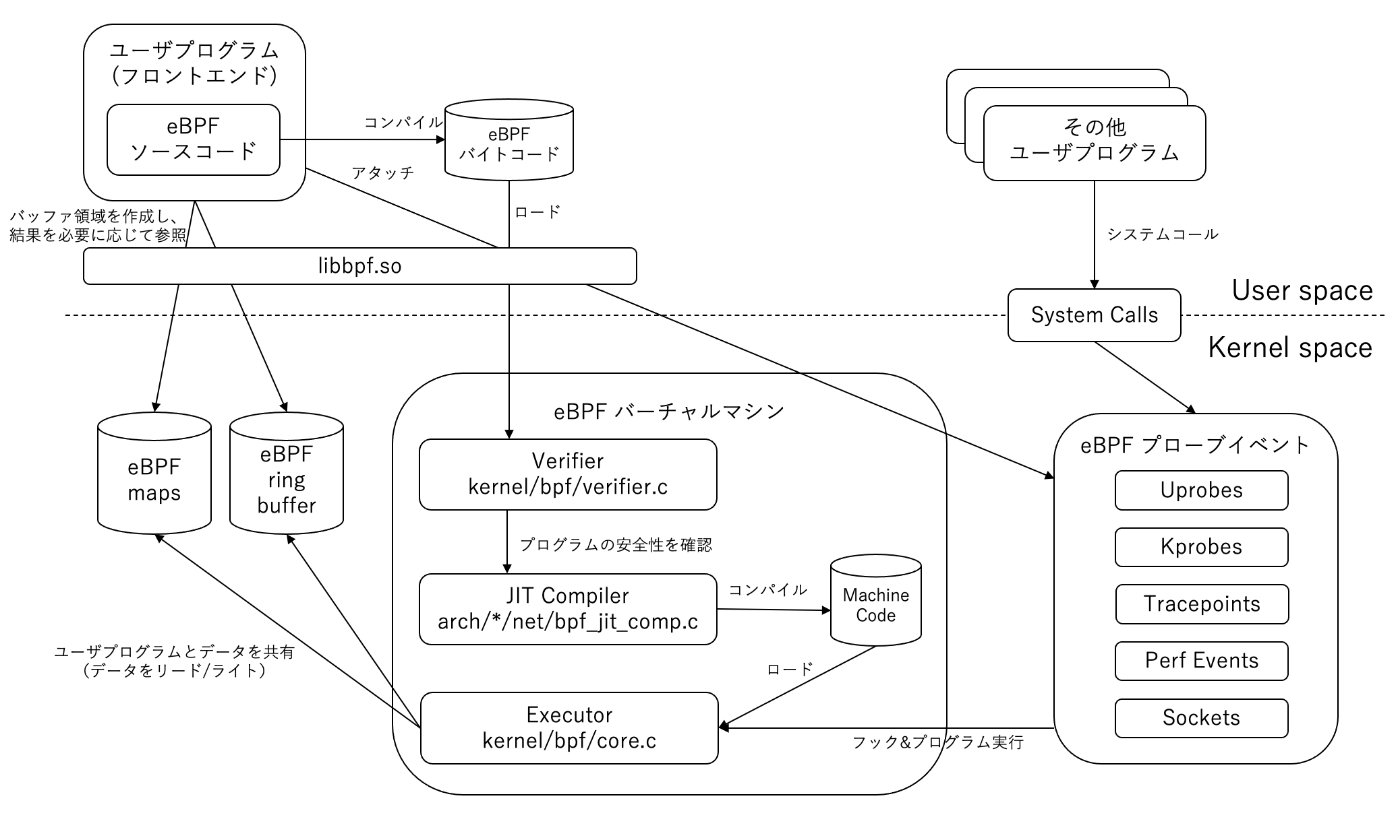
大まかな処理フロー
- eBPFのプログラムをコンパイルしてeBPFバイトコードに変換 (
libbccやlibbpfなどのライブラリの中でコンパイラを呼び出して利用している) - システムコールを利用してeBPFバイトコードをカーネルスペースにロード
- eBPF
VefifierがeBPFバイトコードの安全性をチェック - eBPFのバイトコードの安全性に問題がなければ、JITコンパイラで機械語にコンパイル
- フロントエンドのプログラムが目的(プローブ対象)のイベントにアタッチ
- 目的のイベントが発生するとその対象コードをExecutorが実行
- モニタリング結果をユーザプログラムとの共有スペース(map, ring buffer等)に格納
- ユーザプログラム側で必要に応じて結果を参照利用
仮想マシンのSpec
ソースコード:
命令セットのフォーマット
eBPFの命令セットは1命令あたり64bit固定長でとてもシンプルです。
| 63-32 bits (MSB) | 31-16 bits | 15-12 bits | 11-8 bits | 7-0 bits (LSB) |
|---|---|---|---|---|
| イミディエート | オフセット | ソースレジスタ | デスティネーションレジスタ | オペコード |
レジスタ
64bit x 11個の汎用レジスタ(R0 - R10)が用意されています。
| レジスタ名 | アクセス属性 | 用途 |
|---|---|---|
| R0 | RW | 汎用レジスタ(関数の戻り値を格納) |
| R1 - R5 | RW | 汎用レジスタ(関数コールのABIつまり引数を格納) |
| R6 - R9 | RW | 汎用レジスタ |
| R10 | RO | スタックポインタ |
スタックサイズ
512バイト固定です。少しずれたことをすると簡単にオーバーフローを起こしてしまいそうです。
その他
- アトミック命令やエンディアン変換命令等もサポート
- bpf_call命令で外部関数(カーネル内の関数)呼び出し命令をサポート
- ユーザアプリケーションとのデータ共有用途でmapやring buffer等のデータ構造をサポート
フックポイント
フック対象の種類はカーネルバージョンによって異なる(どんどん出来ることが増える方向)のと、多くのイベントがサポートされています。フック可能なイベントは以下の5つのグループに大きく分けることが出来ます。
- Socket
- 基本的にネットワークスタックの全てのレイヤのイベントをフック可能
- Trace Point
- カーネル空間の静的ポイント(決まった特定の箇所、特定のソースコードの位置に組み込む)をフック可能
- Kprobe
- カーネル空間の動的ポイント(指定した場所/アドレス)をフック可能
- Uprobe
- ユーザ空間の動的ポイント(指定した場所/アドレス)をフック可能
- Perf Event
- 従来からLinuxに存在するパフォーマンスモニタリングの機能でそのイベントをフック可能
詳しくはProgram Typesを参照して下さい。
libbpf
C言語標準のプログラムを使うなら、デファクトスタンダードのeBPFのライブラリです。詳しいドキュメント等はなさそうですが、ユーザが専門家で直接カーネルのシステムコールを利用する以外の方法においては、各OSSライブラリにおいても通常はこれが利用されていると思われます(なお、後述のBCCでは利用されていません)。
3. ツールチェーン
コンパイラ
gcc、Clang/LLVM共にeBPFをサポートしています。
BPF CO-RE(Compile Once - Run Everywhere)
eBPF のソースコードはカーネルバージョンに強く依存するため(ソースコードでカーネルヘッダを参照するため)、厳密にはビルドホストと実行環境のターゲットホストのカーネルバージョンを一致させる必要があります。このため、基本的に eBPF のソースコードは実行環境のターゲットホストで実行時にビルドすることになります。
しかし、これだと不便かつ無駄であるため、libbpfの開発チームがある環境でビルドされたものを異なるカーネルバージョン環境でも再ビルドなしで動かすようにする仕組み(対応)を考えたのがCO-REです。仕組み的には、ビルド済みの eBPF バイトコードをロードする前に、実行環境のカーネルのバージョンやコンフィギュレーションに併せてデータのオフセット等を直接変更する様子です。この eBPF のバイトコードを書き換えるために必要な情報を管理する仕組みがBTFと呼ばれており、コンパイル時にコンパイラが情報として、eBPF のバイトコードに埋め込みます。一方、ターゲットホストで実行する時には、/sys/kernel/btf/vmlinuxファイルから情報を取得します。
もう少し詳しい情報はここの説明が良さそうに感じました。
4. 代表的なフロントエンド/ツール
eBPFのソースコードはClang/LLVMを利用してビルドし、フロントエンドはユーザが好きな言語やツールを使うのが一般的です。と言っても、eBPFのソースコードをユーザが直接ビルドすることは基本的になく、後述する代表的なツールを利用します。
BPF Compiler Collection (BCC)
BCCはiovisorが開発し、eBPFのバイトコードを提供するコンパイラ、eBPFツールとして利用するときのフロントエンドの環境 (メインはPython、その他にC++, Luaをサポート) 、eBPFを利用してよく作られる便利なツール類をサンプルコマンドとしてまとめて提供しています。以下の図(よく目にするやつ)を見るとわかりますが、多くのコマンドが提供されています。

なお、内部的にはeBPFソースコードのコンパイルにはClang/LLVM、eBPFのAPIのコール(システムコール)には独自実装のlibbccを利用しています。
ソースコード
bpftrace / SystemTap
BCC同様、bpftrace(SystemTapの後継)はIO Visorが開発管理しています。
BCCのように一般的にeBPFを利用する場合には、eBPF本体のプログラムとトレーシング用のフロントエンドのユーザランド側の2つのプログラムを用意する必要があります。しかし、bpftraceでは独自のスクリプト言語 (DSL[1]) とコマンドラインツールを提供することで、カーネルサイドとユーザサイドを意識することなくより簡単に一つのプログラムでトレーシング処理を記述することが可能です。
内部的にはLLVMおよびBCCを利用してeBPFのバイトコードを生成しているようです。
$ sudo bpftrace -e 'kprobe:do_sys_open {printf("%s\n", str(arg1)); exit(); }'
Attaching 1 probe...
/etc/localtime
perf-tools
perfコマンドは有名だと思いますが、これもまた内部で個人レベルで開発されていますが、内部ではcBPFを利用している様子です。cBPF以外にはtracefs (debugfs) も利用していそうです。
ply
bpftraceと比較すると制約等がありそうですが、生成されるバイナリのサイズが小さくembedded向きとされています。内部的にはLLVM, BCC等は利用せずに直接eBPFのバイトコードを生成しているようです。
4. eBPFの用途
主に以下3つの観点で利用されることが多いように思います。
- オブザーバビリティ
カーネルのソースコードを修正もしくはプログラムを停止修正せず、任意(制約あり)の機能を実行出来るため、パケットキャプチャやシステムイベント等のトレーシング用途で利用することが可能です。実際、多くの有名ツールが内部的には eBPF を利用しています。 - パフォーマンス
カーネルのソースコードを修正もしくはプログラムを停止修正せず、任意(制約あり)の機能を実行出来るため、パケットキャプチャやシステムイベント等のトレーシング用途で利用することが可能です。実際、多くの有名ツールが内部的には eBPF を利用しています。 - セキュリティ
後述のseccompが代表例だと思いますが、サンドボックス用途でシステムコールを制限することが可能です。
汎用的な利用も可能にするように機能拡張が常に検討されている様子ですので、今後ますます応用例が出てくる可能性があります。
eBPFを利用した代表的なオープンソース
cilium
クラウドのコンテナオーケストレーションで利用されるk8sの通信はkube-proxyにて管理されますが、内部ではiptablesが利用されます。フィルタリング数が少なければまだ良いのですが、Podが増えて通信量も計算量も増えてくるとだんだん辛くなってきます。
そこで、ciliumはカーネルスペースとユーザスペースのオーバーヘッドを削減することでトータルのパフォーマンスを向上させるため、内部でeBPFを利用しています。またフロントエンドをGo言語で利用できるように自前のeBPF環境も構築しています。
bpfilter
BPFを利用することでFirewallを実現するというLinuxカーネルのプロジェクトです。BPF-Based Linux Firewall "bpfilter" Shows Impressive Performance Potentialによると、パフォーマンスがとても良く、可能性を感じさせるプロジェクトだと話題になっています。
seccomp
seccomp (SECure COMPuting with filters) はサンドボックスを実現するためにプロセスのシステムコールの発行を制限するための機能を実現します。内部ではシステムコールのフィルタリングにcBPFを利用しています。eBPFはシステムコールをフックは出来ても、エミュレーションは出来ません。しかし、eBPFのプログラムでシステムコールの結果だけ独自の値を返すことが可能で、これによりシステムコールの中断(失敗?)を実現しているようです。
5. ソフトウェアライセンス
ユーザが作成したeBPFのソースコードはGPL-2.0にしないとプログラムがロードされません。
6. eBPFプログラム制約
実際にeBPFのプログラムを書く場合、Linuxカーネルバージョンにより徐々に緩和する方向ではありますが、いろいろと制約があるため注意が必要です。
命令数の制限
後述の仮想マシンで扱える上限命令数がLinuxカーネルv5.4で1M個程度です。
ループ上限
Linuxカーネルv5.3以降から有限回数のループが許可されました。
7. カーネルコンフィグ
カーネルビルド時のコンフィグでは最低限以下を有効にしておく必要があります。
CONFIG_BPF=y
CONFIG_BPF_SYSCALL=y
CONFIG_BPF_JIT=y
CONFIG_HAVE_EBPF_JIT=y
8. 参考文献/書籍
-
domain-specific language ↩︎
Discussion