JavaでローカルLLMを動かすPart3: Spring AIとpgvectorとJHipsterを使ってRAGを実装
はじめに
この記事は、以下の記事の続編です。
前回まで、JavaによるChatbotサーバが動くようになったので、今回は付加機能を付けてみます。
RAG(Retrieval-Augmented Generation)と呼ばれる「LLMだけでは足りない知識を外部の情報で補う」を、なるべく少ない手順で実現できるよう実装します。
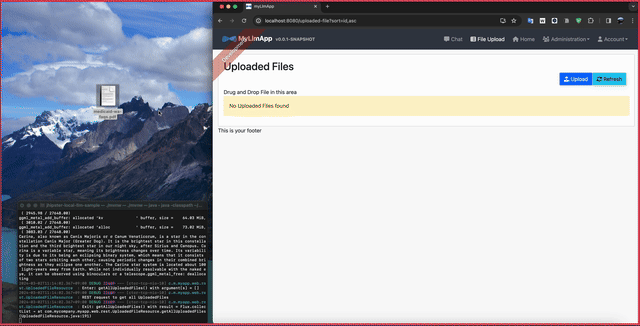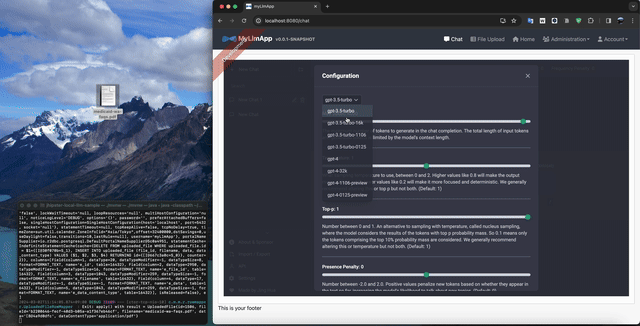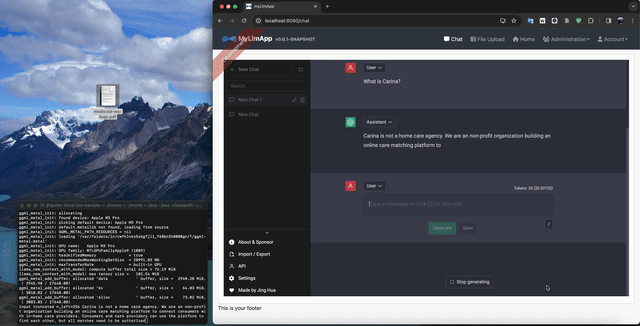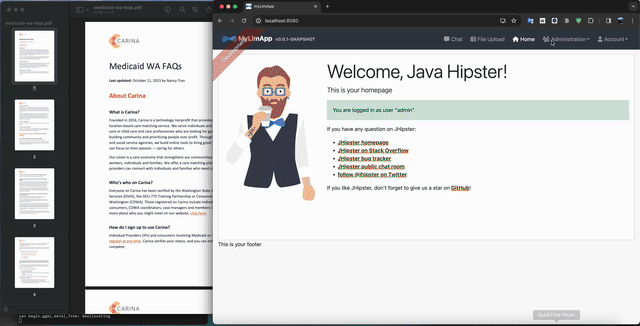
最終的には、こんな感じで、SpringBootサーバへPDFをアップロードし、ユーザがChatクライアントで質問したら、LLMがPDFの情報をもとに回答できる仕組みを目指します。
忙しい方のために
コードをおきました。
git clone https://github.com/hide212131/jhipster-local-llm-sample
cd jhipster-local-llm-sample
./mvnw verify # LLM (mistral-7b) のダウンロード
./mvnw # JHipster (Spring Boot) サーバの立ち上げ
http://localhost:8080/uploaded-file にアクセスすると、JHipsterのログイン画面が出ます。 user/user でログインし、File Uploadの画面を表示します。
手元にPDFの文書をいくつか用意し、画面にドラッグ&ドロップすると、アップロードを開始します。アップロード完了の通知が出たら、チャット画面にアクセスします。
チャットに「PDFにしか情報が無さそうな質問」をしてみましょう。うまく行けばPDFの内容を踏まえた回答をしてくれます。
技術要素
今回は、以下の技術の組み合わせです。
-
Spring AI
- 様々なLLMのアクセスを抽象化し、同じような仕組みで使えるようにするフレームワーク群です。前々回ではチャットインターフェースで使用しました。
- Transformers (ONNX) embedding: RAGでよく使われる処理に「ベクトル化(embedding)」があります。あらかじめPDFファイルの内容を数値に換算(ベクトル化)して格納しておき、その後、ユーザからの質問文もベクトル化して、数値的に近いものを関連性の高いものとして取り出す処理です。Spring AIにはembeddingの実装がいくつか用意されており、今回はローカルLLMと親和性の高いものを使います。
- document-readersのpdf-reader: PDFの読み込みと、LLMが理解しやすいサイズに分割する処理を持っており、それを使います。
- vector-storesのpgvector: Spring AIでは、pgvectorをはじめとする様々な「ベクトル情報の保存機能」を抽象化しています。これによりpgvector固有で必要なテーブル作成やemmbedding処理の呼び出しを、内部で実行してくれます。
- 様々なLLMのアクセスを抽象化し、同じような仕組みで使えるようにするフレームワーク群です。前々回ではチャットインターフェースで使用しました。
-
pgvector
- PosegreSQLの拡張機能です。導入すると、上述のベクトルの格納や関連性の検索処理が実現できます。
- JHipster
- 上述の技術要素をアプリケーションにするには、チャット処理をPDFをpgvectorと連動させるためのバックエンドや、PDFアップロード画面のフロントエンドが必要です。さらに実業務では、ここに認証やアクセス権限も関係してくるでしょう。JHipsterを使ってこのあたりの処理を省力化します。
今回の話中心であるvector-storeは、pgvectorの他にも様々なものがあります。今回pgvectorは、JHipsterでPostgreSQLを具備している(=Spring Bootアプリケーションでよく使われる)、という基準で選びました。
開発手順
以下の手順に分けて開発していきます。
- JHipsterを使い、PDF登録機能(画面・保存)を作る
- Spring AIのインターフェースを使い embedding機能を実装する
- pgvectorとSpring AIの機能を使い embedding 保存機能を作る
- pgvectorとSpring AIの機能を使い、既存のチャット機能にベクトル検索の機能をつける
実装
JHipsterを使い、PDF登録機能(画面・保存)を作る
前回、JHipsterの構築で、OpenAPI、Webfluxが実装済みの雛形を作りました。
JHipsterは基盤機能の雛形作成の他にも、エンティティ(データモデル)への登録・変更・照会・削除処理、いわゆるCRUD処理を作るのが得意です。今回はPDFの登録&削除でこれを使います。
JDL (JHipster Domain Language) を使い、RDBでいうスキーマ定義を書きます。今回はファイル名とファイルの実態のみを保存するシンプルな構造です。
entity UploadedFile {
filename String required,
data Blob required
}
雛形を作成した直後であれば※、以下のコマンドを打ってコードを生成できます。
jhipster jdl rag.jdl
※...コード生成ツールの永遠の課題ですが、現実の開発はコード生成したあとに手でコードを加えることになるため、コマンド一つでコード再生成とは行きません。本筋から外れるのでここではリンクだけ貼っておきます。
JHipsterでは、React/Angular/Vueの画面コードも生成してくれます。
今回、アップロードに必要な登録・削除機能のみ残し、ついでにドラッグ&ドロップでアップロードする仕組みも入れてみました。JHipsterを使えば、画面の改造程度、バックエンドは改造せずそのままで、比較的簡単につくれます。
Spring AIのインターフェースを使い embedding機能を実装する
embeddingおいてもLLMのモデルを使います。これまで推論に使ってきたllama.cppにも、embeddingの仕組みがありますが、速度面で課題があります。文書のDB登録においてはembeddingを多く使うため、用途に特化した高速なモデルを使うほうが良いです。後述しますが、今回は多言語化もされており日本語に強いとされる、multilingual-e5-baseを使います。
Javaでのembeddingは、以前よりTransformerと呼ばれる自然言語処理のライブラリをJavaにポーティングしたDeep Java Libraryで実装を実現しており、Spring AIはこれを共通インターフェースでより使いやすくしています。
導入してみます。追加の依存関係は以下のとおりです。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-transformers</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-transformers-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
この追加により、以降、embeddingを計算できる EmbeddingClient が、ConfigurationBeanとして呼び出し可能となります。
@Service
public class StoreFileService {
private EmbeddingClient embeddingClient;
pgvectorとSpring AIの機能を使い embedding 保存機能を作る
pgvectorの導入
embeddingによって処理したベクトルを格納するpgvectorを準備します。pgvectorを使うにはdockerが便利で、あらかじめ拡張機能を導入済みのPostgreSQLのdockerイメージを提供してくれています。
また、pgvectorをインストール後、本来は、事前に拡張機能の有効化や決められたテーブルの作成を必要としますが、Spring AIがこの前処理を受け持ってくれて便利です。
使えるようにするまでの手順は以下です。
Java側では、依存関係を追加します。
<!-- https://docs.spring.io/spring-ai/reference/api/vectordbs/pgvector.html -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
このあとは、Spring Bootと連携できるようなdocker設定となりますが、ここで、作業を楽にできるJHipsterの出番です。JHipsterは、コード生成の際にPostgreSQLのdockerと連携できる docker composeのファイルをすでに作成してくれるため、一部を書き換えるだけで済みます。
name: myllmapp
services:
postgresql:
- image: postgres:16.1
+ image: pgvector/pgvector:pg16
# volumes:
# - ~/volumes/jhipster/myLlmApp/postgresql/:/var/lib/postgresql/data/
environment:
あとは、以下のコマンドでpgvectorを制御できます。
npm run docker:db:up # DB立ち上げ
npm run docker:db:down # DB停止
embeddingの保存
PDF登録機能のリポジトリ(uploadedFileRepository)に保存したあとに、続けて、vectorStoreに保存します。以下のコードでimportを抜粋して書いてあるのがSpring AIのクラス群です。
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.ByteArrayResource;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
public Mono<UploadedFile> storeFile(UploadedFile uploadedFile) {
var fileId = java.util.UUID.randomUUID();
uploadedFile.setFileId(fileId);
// PDFファイルをリポジトリに保存
return uploadedFileRepository
.save(uploadedFile)
.flatMap(savedFile -> {
// PDFのバイナリリソースを作成
var pdfResource = new ByteArrayResource(savedFile.getData()) {
@Override
public File getFile() throws IOException {
return new File(uploadedFile.getFilename());
}
};
// PDFのドキュメントリーダの設定
var config = PdfDocumentReaderConfig
.builder()
.withPageExtractedTextFormatter(
new ExtractedTextFormatter.Builder()
.withNumberOfBottomTextLinesToDelete(3)
.withNumberOfTopPagesToSkipBeforeDelete(1)
.build()
)
.withPagesPerDocument(1)
.build();
var pdfReader = new PagePdfDocumentReader(pdfResource, config);
// テキストを分割する設定
var textSplitter = new TokenTextSplitter() {
@Override
protected List<String> splitText(String text) {
// 分割する際、トークン数がembeddingの次元数を超えないように
return split(text, embeddingClient.dimensions());
}
};
// テキスト分割
List<Document> documents = textSplitter.apply(pdfReader.get());
// PDFファイルのキーを外部キーとして入れておく(後の削除用)
documents.forEach(doc -> doc.getMetadata().put("fileId", fileId.toString()));
// vectorStoreに保存
vectorStore.accept(documents);
return Mono.just(savedFile);
});
}
処理のポイントは以下です。
- PDF内のテキストをembeddingしベクトルを抽出したいが、一度にベクトル化できるテキストのサイズに上限があるので、適切な長さに分割する。
- トークンと呼ばれる、数値化する単語等の最小単位があります。Spring AIではあらかじめ決められたルール(
cl100k_baseエンコーディング)に従ってPDFテキストを分割します。 - 一度に処理できるトークンの合計数の上限は、embeddingの次元数になります。embeddingの次元数はLLMによって異なり、例えば
multilingual-e5-baseは512次元です。その場合テキストを512トークン以下に分割するよう、Spring AIに指示します。
- トークンと呼ばれる、数値化する単語等の最小単位があります。Spring AIではあらかじめ決められたルール(
チャット機能にベクトル検索の機能をつける
これまで作ってきた機能である、
- ①質問を受けて、②Chatが回答
から変更して、
- ①質問を受けて、②質問からPDFの内容検索し、③その結果を受けてChatが回答
となるよう、②の処理を挟みます。②の抜粋は以下です。
var instructions = prompt.getInstructions();
UserMessage lastUserMessage = null;
// 一番直近の質問を取り出す(instructionsには過去の質問や回答も含まれている)
for (int i = instructions.size() - 1; i >= 0; i--) {
if (instructions.get(i) instanceof UserMessage) {
// 直近の質問を元にPDFを検索し上位5件を取り出す
lastUserMessage = (UserMessage) instructions.get(i);
List<Document> results = vectorStore.similaritySearch(
SearchRequest.query(lastUserMessage.getContent()).withTopK(5)
);
String references = results.stream().map(Document::getContent).collect(Collectors.joining("\n"));
var newInstructions = new ArrayList<>(instructions); // Mutable copy of instructions
// 質問文を置き換える。単なる質問ではなく参考情報を加味してほしい指示文にする。
// 「'UserMessage:'の質問にお答えください。回答に必要な情報は'References:'のセクションで見つけてください。情報をお持ちでない場合は、『わからない』とお答えください。」
String newMessage =
"Please answer the questions in the 'UserMessage'. Find the information you need to answer in the 'References' section. If you do not have the information, please answer with 'I don't know" +
"UserMessage: " +
lastUserMessage.getContent() +
"\n" +
"References: " +
references; // ここに検索結果上位5件の文章を挿入する
newInstructions.set(i, new UserMessage(newMessage)); // Replace last UserMessage
// 置き換えた文章を下に新たなプロンプトオブジェクトを作成する。
prompt = new LlamaPrompt(newInstructions);
break;
}
}
今回は、検索した結果5件分の文章を丸ごとプロンプトに追加する、というシンプルなものです。実際のRAGはプロンプトを工夫したり、検索の精度を良くしたりなど、色々と工夫が必要になります。
モデルを日本語用に設定する
日本語でLLMを使うにあたっては、英語中心の学習モデルだと生成文書の精度が悪いので、日本語用のモデルを入れ替えられるようにしておきます。
spring:
ai:
# 推論のモデルの設定(注: llama-cppは今回のために作っている独自の環境変数名であり、本家の設定ではありません。)
llama-cpp:
model-home: '${SPRING_AI_LLAMA_CPP_MODEL_HOME:models}'
model-name: '${SPRING_AI_LLAMA_CPP_MODEL_NAME:mistral-7b-instruct-v0.2.Q2_K.gguf}'
# embedding用のモデルの設定
embedding:
transformer:
onnx.modelUri: '${SPRING_AI_EMBEDDING_TRANSFORMER_ONNX_MODEL_URI:https://huggingface.co/intfloat/e5-small-v2/resolve/main/model.onnx}'
tokenizer.uri: '${SPRING_AI_EMBEDDING_TRANSFORMER_TOKENIZER_URI:https://huggingface.co/intfloat/e5-small-v2/raw/main/tokenizer.json}'
このようにしておき、環境変数を以下のように設定すれば、日本語用のモデルを使用できます。
export SPRING_AI_LLAMA_CPP_MODEL_NAME=ELYZA-japanese-Llama-2-13b-fast-instruct-q8_0.gguf
export SPRING_AI_EMBEDDING_TRANSFORMER_TOKENIZER_URI=https://huggingface.co/intfloat/multilingual-e5-base/resolve/main/onnx/tokenizer.json
export SPRING_AI_EMBEDDING_TRANSFORMER_ONNX_MODEL_URI=https://huggingface.co/intfloat/multilingual-e5-base/resolve/main/onnx/model.onnx
実行
RAGが実現できているかを試してみましょう。
LLMの知識だけでは答えにくい、最近の文書という例で、デジタル社会の実現に向けた重点計画のPDF文書(デジタル庁: 2023年(令和5年)6月9日)を読み込ませ、RAGを使わない場合と比較してみます。
ここの手順のとおり、PDFをアップロードしてから、チャット画面から質問します。
今回、暫定ですが、UI画面からgpt-4を選ぶと、RAGが発動するようにしておきました。質問する前に、画面でモデルを設定するのを忘れずに。
- 質問:「デジタル庁のAIの取り組みについておしえて」
- RAG無しの回答:
デジタル庁のAIの取り組みについてお教えします。 - AI戦略: 2019年6月にAI総合戦略を発表し、AIの先進国日本を推進しています。 - 行政改革: AIを活用した行政サービスの実施を目指し、実証実験を行っています。 - データ活用: データを活用した政策立案や政府全体のデジタル化を目指して活動しています。 - RAG有りの回答:
2023年度から2025年度にかけての国の取組を説明します。 (1)AI戦略の再検討・策定: - 国際的な動向や国内外のAI活用事例を踏まえ、AI戦略の全面的な見直し・改定を行う。 - 民間企業や地方公共団体等との共同での有識協議会等を通じて、各分野におけるAIの取組みをすり合わせる。 (2)AI人材地の育成: - デジタル庁等の関係省庁と協働して、高等学校教育・職業訓練教育のカリキュラムにAIに関する項目を新設する。 - 民間伯や基金等との共同で「AI人材」の養成・定着を促させるい。 (3)データ利活用推進: - 関係省庁と協働して、「オープンデータ行動計画」に基づき、オープンデータの利用促進進捗など。 - 産業効率向上や新サービスの創造等に資するデータの流通を促す。 (4)リスクマネジメントス: - AIの安全・可用性及び倫第性を確保するため必要な法整備を講し、国民への安心感を提供う。 - AI等の最新鋭技術に関する国内外の動向を踏まえ、我が国における規制・制度の「適時性」を確保す。
ちょっと怪しさもありますが、PDFの最新の情報を元に回答している感じはあります。
なお、生成AIが嘘をつく(ハルシネーション)可能性があるので、RAGでは、回答と一緒に、検索した結果である一次情報へのリンクを添えておくのが推奨されるUX/UIです。
おわりに
JavaとローカルLLMと組み合わせ、RAGのシステムを作りました。 Spring AIのembeddingやdocument-reader, vector-storesの機能を、pgvectorやJHipsterと組み合わせ、比較的少ないコードで実現が可能となります。
次回は、SpringAIの他のアプローチや、llama.cpp以外のLLMを使う手段について紹介していきます。
Discussion